文章目录
不要摆,没事干就刷题,只有好处,没有坏处,实在不行,看看竞赛题
面试经典 150 题 - 2
210. 课程表 II
- 一眼拓扑排序. 好久没写过拓扑排序了,写得特别糟糕
public int[] findOrder(int n, int[][] prerequisites) {
int[] order = new int[n];
if (prerequisites == null) {
for (int i = 0; i < n; i++) order[i] = i;
return order;
}
// 创建邻接表 和 入度数组
ArrayList<ArrayList<Integer>> adj = new ArrayList<>();
for (int i = 0; i < n; i++) {
adj.add(new ArrayList<>());
}
int[] inDegree = new int[n];
for (int[] prerequisite : prerequisites) {
adj.get(prerequisite[1]).add(prerequisite[0]);
inDegree[prerequisite[0]]++;
}
// 入度队列 (不需要栈)
Stack<Integer> s = new Stack<>();
for (int i = 0; i < inDegree.length; i++) {
if (inDegree[i] == 0) s.push(i);
}
// 拓扑排序
int cnt = 0;
for (int i = 0; i < n; i++) {
if (s.isEmpty()) break;
Integer pop = s.pop();
order[cnt++] = pop;
for (Integer x : adj.get(pop)) {
inDegree[x]--;
if (inDegree[x] == 0) {
s.push(x);
}
}
}
if (cnt < n) return new int[0];
return order;
}
- 看了下大佬的做法,发现确实有几处值得修改
主要就是度为0的不必非要用栈,用队列也行,队列直接作为拓扑排序的终止条件即可
没有前置关系时不需要要特判,全是度为0的节点,也可以照常执行
不要用statck,继承了Vector, 有很多锁,效率很低
修改后4ms,差不多了吧
public int[] findOrder(int n, int[][] prerequisites) {
// 创建邻接表 和 入度数组
ArrayList<ArrayList<Integer>> adj = new ArrayList<>();
for (int i = 0; i < n; i++) adj.add(new ArrayList<>());
int[] inDegree = new int[n];
for (int[] prerequisite : prerequisites) {
adj.get(prerequisite[1]).add(prerequisite[0]);
inDegree[prerequisite[0]]++;
}
// 入度队列 (不需要栈)
Deque<Integer> q = new LinkedList<>();
for (int i = 0; i < inDegree.length; i++) {
if (inDegree[i] == 0) q.offer(i);
}
// 拓扑排序
int[] order = new int[n];
int cnt = 0;
while (!q.isEmpty()){
Integer pop = q.poll();
order[cnt++] = pop;
for (Integer x : adj.get(pop)) {
inDegree[x]--;
if (inDegree[x] == 0) q.push(x);
}
}
if (cnt < n) return new int[0];
return order;
}
909. 蛇梯棋
一眼望去,D/BFS都行,BFS应该更加节省时间
先用BFS试试,就是每次维护下一层就是了,6叉树而已
自己做法,6ms, 感觉比较麻烦,依靠3个测试数据修改了3次错误
public int snakesAndLadders(int[][] board) {
int n = board.length;
Deque<Integer> q = new LinkedList<>();
q.offer(1);
int k = 0;
HashSet<Integer> set = new HashSet<>();//如果队的就不要重复入了 反正只会更长
set.add(1);
while (!q.isEmpty()) {
int size = q.size();
k++;
if (k > n * n / 6 + 1) return -1;//有可能到达不了
for (int i = 0; i < size; i++) {
int top = q.poll();
// 下层6个子结点
for (int j = top + 1; j <= top + 6; j++) {
int x = (n - 1) - (j - 1) / n;
int y = (j - 1) % n;//先假设从左往右
if((j - 1) / n % 2 == 1) y = (n - 1) - y; //结果是从右往左
int next = board[x][y] == -1 ? j : board[x][y];
if (!set.contains(next)) {
set.add(next);
q.offer(next);
if (next == n * n) {
return k;
}
}
}
}
}
return -1;
}
看了下官解,思路完全一样,唯一差别就是hashSet换成了Boolean[]数组,速度上快几毫秒,换过来之后才3ms了
public int snakesAndLadders(int[][] board) {
int n = board.length;
Deque<Integer> q = new LinkedList<>();
q.offer(1);
int k = 0;
boolean[] visited = new boolean[n * n + 1];//如果队的就不要重复入了 反正只会更长
visited[1] = true;
while (!q.isEmpty()) {
int size = q.size();
k++;
if (k > n * n / 6 + 1) return -1;//有可能到达不了
for (int i = 0; i < size; i++) {
int top = q.poll();
// 下层6个子结点
for (int j = top + 1; j <= top + 6; j++) {
int x = (n - 1) - (j - 1) / n;
int y = (j - 1) % n;//先假设从左往右
if ((j - 1) / n % 2 == 1) y = (n - 1) - (j - 1) % n; //结果是从右往左
int next = board[x][y] == -1 ? j : board[x][y];
if (!visited[next]){
visited[next] = true;
q.offer(next);
if (next == n * n) {
return k;
}
}
}
}
}
return -1;
}

433. 最小基因变化
第一感觉:DFS;第二感觉:BFS也行,所以就先D/BFS都试一下吧
被一个测试用例挡住才真正看懂题目:
- DFS 还挺快的
public int minMutation(String startGene, String endGene, String[] bank) {
if (startGene.equals(endGene)) return 0;
if (bank == null || bank.length == 0) return -1;
if (!Arrays.asList(bank).contains(endGene)) return -1;
visited.clear();
int ans = dfs(startGene, endGene, bank, 0);
return ans == Integer.MAX_VALUE ? -1 : ans;
}
HashSet<String> visited = new HashSet<>(); //预防打转
int dfs(String now, String end, String[] bank, int deep) {
if (now.equals(end)) return deep;
int ans = Integer.MAX_VALUE;
for (int i = 0; i < bank.length; i++) {
if (isNext(bank[i], now) && !visited.contains(bank[i])) {
visited.add(bank[i]);
ans = Math.min(dfs(bank[i], end, bank, deep + 1), ans);
visited.remove(bank[i]); // 回退
}
}
return ans;
}
// 判断s1和s2的距离是否是1
boolean isNext(String s1, String s2) {
int k = 0;
for (int i = 0; i < s1.length(); i++) {
if (s1.charAt(i) != s2.charAt(i)) k++;
if (k > 1) break;
}
return k == 1;
}

再用BFS试一下吧
public int minMutation(String startGene, String endGene, String[] bank) {
if (startGene.equals(endGene)) return 0;
if (bank == null || bank.length == 0) return -1;
if (!Arrays.asList(bank).contains(endGene)) return -1;
HashSet<String> visited = new HashSet<>();
LinkedList<String> q = new LinkedList<>();
q.offer(startGene);
int k = 0;
while (!q.isEmpty()){
int size = q.size();
k++;
for (int i = 0; i < size; i++) {
String top = q.poll();
for (String s : bank) {
if(isNext(s,top)&&!visited.contains(s)){
q.offer(s);
visited.add(s);
if(s.equals(endGene)) return k;
}
}
}
}
return -1;
}
// 判断s1和s2的距离是否是1
boolean isNext(String s1, String s2) {
int k = 0;
for (int i = 0; i < s1.length(); i++) {
if (s1.charAt(i) != s2.charAt(i)) k++;
if (k > 1) break;
}
return k == 1;
}

题解方式穷举各种状态变换了,bank明明不是很长,为啥不直接bank中搜索合法的next呢?
74. 搜索二维矩阵
public boolean searchMatrix(int[][] matrix, int target) {
int m = matrix.length, n = matrix[0].length;
int x = m - 1, y = 0;
while (x >= 0 && y < n) {
if (target == matrix[x][y]) return true;
else if (target < matrix[x][y]) x--;
else y++;
}
return false;
}
从左下角开始搜索即可,
二分好像也可以做
127. 单词接龙
- 暴力做法,DFS写了一下午,一直过不了
- 改用BFS,简单多了,一次过
// 看答案都是用的BFS 这里也试试吧
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
Deque<String> q = new LinkedList<String>();
q.offer(beginWord);
HashSet<String> visited = new HashSet<>();
int k=0;
while (!q.isEmpty()) {
int size = q.size();
k++;
for (int i = 0; i < size; i++) {
String top = q.poll();
for (String s : wordList) {
if (siNext(s, top) && !visited.contains(s)) {
visited.add(s);
q.offer(s);//前往注意不是push
if(s.equals(endWord)) return k+1; // 比dfs简单多了 先构思好 这种数组类型的题,BFS最好 还不用回溯,太方便了 // 理论上路径长度问题,D/BFS都能解决
}
}
}
}
return 0;
}
public boolean siNext(String str1, String str2) {
int d = 0;
for (int i = 0; i < str1.length(); i++) {
if (str1.charAt(i) != str2.charAt(i)) d++;
if (d > 1) break;
}
return d == 1;
}
但是速度很慢,看看题解咋做的吧
个人猜测,1 <= beginWord.length <= 10,枚举变化情况,10*25=250 每次也就250种情况,而枚举1 <= wordList.length <= 5000却有5000种情况
- 果然快了一丢丢,但只是一丢丢
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
Deque<String> q = new LinkedList<String>();
q.offer(beginWord);
HashSet<String> visited = new HashSet<>();
HashSet<String> words = new HashSet<>(wordList);
int k = 0;
while (!q.isEmpty()) {
int size = q.size();
k++;
for (int i = 0; i < size; i++) {
String top = q.poll();
for (String s : getNext(top, visited, words)) {
visited.add(s);
q.offer(s);//前往注意不是push
if (s.equals(endWord))
return k + 1; // 比dfs简单多了 先构思好 这种数组类型的题,BFS最好 还不用回溯,太方便了 // 理论上路径长度问题,D/BFS都能解决
}
}
}
return 0;
}
public List<String> getNext(String s, HashSet<String> visited, HashSet<String> words) {
ArrayList<String> ans = new ArrayList<>();
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
char t = chars[i];
for (char c = 'a'; c <= 'z'; c++) {
if (c != t) chars[i] = c;
String ss = String.valueOf(chars);
if (!visited.contains(ss) && words.contains(ss)) ans.add(ss);
}
chars[i] = t;
}
return ans;
}
- 双向BFS似乎更快 …
208. 实现 Trie (前缀树)
208. 实现 Trie (前缀树)
先用26叉树试一下
- 之前刷过,就是26叉树,一次过
class Trie {
Trie[] next;
boolean tail;// 结尾标记 26叉树 前缀相同 结尾应该是唯一的,不必害怕
public Trie() {
this.tail = false;
this.next = new Trie[26]; // 没有头节点,为当前节点开辟空间
// 直接new 并不会陷入死循环 // 因为并没有new对象,只是声明了长度为26的数组
//Trie trie = new Trie(); // 写这行就会抱错,循环音乐
}
public void insert(String word) {
Trie now = this;
for (int i = 0; i < word.length(); i++) {
int t = word.charAt(i) - 'a';
if (now.next[t] == null) now.next[t] = new Trie();//这是真正申请对象内存
now = now.next[t];
}
now.tail = true;
}
public boolean search(String word) {
Trie now = this;
for (int i = 0; i < word.length(); i++) {
int t = word.charAt(i) - 'a';
if (now.next[t] == null) return false;
now = now.next[t];
}
return now.tail;
}
public boolean startsWith(String prefix) {
Trie now = this;
for (int i = 0; i < prefix.length(); i++) {
int t = prefix.charAt(i) - 'a';
if (now.next[t] == null) return false;
now = now.next[t];
}
return true;
}
}
211. 添加与搜索单词 - 数据结构设计
211. 添加与搜索单词 - 数据结构设计
典型前缀树的应用
- 果然就是前缀树的应用,出了2次bug,2次才过
class WordDictionary {
WordDictionary[] next;
boolean end; // 是否是end
public WordDictionary() {
this.next = new WordDictionary[26];
this.end = false;
}
public void addWord(String word) {
WordDictionary node = this;
for (int i = 0; i < word.length(); i++) {
int t = word.charAt(i) - 'a'; // 插入的时候没有'.'
if (node.next[t] == null) node.next[t] = new WordDictionary();
node = node.next[t];
}
node.end = true;
}
public boolean search(String word) {
return dfs(this, word, 0);//循环不好写 用递归吧
}
public boolean dfs(WordDictionary t, String word, int k) {
if (k == word.length()) return t.end; // 这里k不要-1 就是最后一个字符的下一个next[c]里面
int i = word.charAt(k) - 'a';
if (i >= 0) {// 字符
if(t.next[i]==null) return false;
else return dfs(t.next[i], word, k + 1);
} else {// 通配符 '*'
for (int j = 0; j < 26; j++) {
if (t.next[j] != null && dfs(t.next[j], word, k + 1)) return true;
}
}
return false;
}
}
212. 单词搜索 II
说是字典树,但我想用DFS试一下1 <= m, n <= 12
- DFS 超时
public List<String> findWords(char[][] board, String[] words) {
ArrayList<String> ans = new ArrayList<>();
int m = board.length, n = board[0].length;
this.visited = new boolean[m][n];
for (String word : words) {
loop:for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if(board[i][j]==word.charAt(0)) {
for (boolean[] booleans : visited) Arrays.fill(booleans,false); // visited数组初始化
if(dfs(board,word,i,j,0)){
ans.add(word);
break loop;
}
}
}
}
}
return ans;
}
boolean[][] visited;
public boolean dfs(char[][] board, String word, int i,int j,int k) {
if(i<0||i>=board.length||j<0||j>=board[0].length||visited[i][j]||board[i][j]!=word.charAt(k)) return false;
//print(board[i][j]," ");
visited[i][j] = true;
if(k==word.length()-1) return true;
boolean b = dfs(board,word,i+1,j,k+1) ||
dfs(board,word,i-1,j,k+1) ||
dfs(board,word,i,j+1,k+1) ||
dfs(board,word,i,j-1,k+1);
visited[i][j] = false; // 回退的都改为false
return b;
}
果然不行,超时了:
- 写得时候就发觉不对,嵌套太多循环,感觉会超时,所以看来还是得老老实实字典树了,但是如何字典树捏
1.看到题解开头,就萌生一个想法,每个单元格为起点分别dfs一次,然后所有路径都插入一次,不标记end
2.题解和我的做法不一样,而是先都插入前缀树一次,然后利用前缀树帮助dfs剪枝叶
因为 1 < = w o r d s . l e n g t h < = 3 ∗ 1 0 4 1 <= words.length <= 3*10^4 1<=words.length<=3∗104 1 < = m , n < = 12 1 <= m, n <= 12 1<=m,n<=12 12*12矩阵DFS一共32288条不同路径,差不多吧
写法题解简单一点,所以直接用题解做法重写一下吧
前缀树有一点改版,不用记录end结尾,但是需要记录一下word,也就是以我为结尾的单词是多少?
26叉树,叶子网上,每个节点只有一个唯一父亲,可以找到唯一路径的
- 前缀树剪枝
class Trie {
String word; // 以我为结尾的单词是哪个
HashMap<Character, Trie> children; // 就是next
public Trie() {
this.children = new HashMap<>();
this.word = "";
}
public void insert(String s) {
Trie node = this;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (!node.children.containsKey(c)) {
node.children.put(c, new Trie());
}
node = node.children.get(c);
}
node.word = s;
}
}
public class Solution {
public List<String> findWords(char[][] board, String[] words) {
this.ans = new ArrayList<>();//自动去重
Trie trie = new Trie();
for (String word : words) {
trie.insert(word);
}
HashSet<String> wordsSet = new HashSet<>(Arrays.asList(words));//保证全局唯一实例
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[i].length; j++) { // 确定起点
dfs(board, wordsSet, trie, i, j);
}
}
return ans;
}
int[] dx = {1, -1, 0, 0};
int[] dy = {0, 0, 1, -1};
private void dfs(char[][] board, HashSet<String> words, Trie trie, int i, int j) {
if (i < 0 || i >= board.length || j < 0 || j >= board[0].length) return;
char c = board[i][j];
Trie next = trie.children.getOrDefault(c, null);
if (next == null) return;//靠前缀树来减枝叶
if (words.contains(next.word)) {
ans.add(next.word);//真正的word在next中
words.remove(next.word); // 防止重复
}
board[i][j] = '#';//标记为访问过了
for (int k = 0; k < 4; k++) {
dfs(board, words, next, i + dx[k], j + dy[k]);
}
board[i][j] = c;//访问完回溯 直接回溯当前节点,多省事儿
}
List<String> ans;
}
和官解大差不差:
class Trie {
String word; // 以我为结尾的单词是哪个
HashMap<Character, Trie> children; // 就是next
public Trie() {
this.children = new HashMap<>();
this.word = "";
}
public void insert(String s) {
Trie node = this;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (!node.children.containsKey(c)) {
node.children.put(c, new Trie());
}
node = node.children.get(c);
}
node.word = s;
}
}
public class LC212_2 extends Solution {
public List<String> findWords(char[][] board, String[] words) {
Trie trie = new Trie();
for (String word : words) {
trie.insert(word);
}
HashSet<String> ans = new HashSet<>(); // 自动去重
HashSet<String> wordsSet = new HashSet<>(Arrays.asList(words));//保证全局唯一实例
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[i].length; j++) { // 确定起点
dfs(board, wordsSet, trie, i, j,ans);
}
}
return new ArrayList<>(ans);
}
int[] dx = {1, -1, 0, 0};
int[] dy = {0, 0, 1, -1};
private void dfs(char[][] board, HashSet<String> words, Trie trie, int i, int j, HashSet<String> ans) {
if (i < 0 || i >= board.length || j < 0 || j >= board[0].length) return;
char c = board[i][j];
Trie next = trie.children.getOrDefault(c, null);
if (next == null) return;//靠前缀树来减枝叶
if (!"".equals(next.word)) { // 因为按照trie存在的路径走的,走到了肯定有
ans.add(next.word);//真正的word在next中 // ans自动去重
}
board[i][j] = '#';//标记为访问过了
for (int k = 0; k < 4; k++) {
dfs(board, words, next, i + dx[k], j + dy[k], ans);
}
board[i][j] = c;//访问完回溯 直接回溯当前节点,多省事儿
}
}
77. 组合
- 直接dfs,怎么好慢呢
public List<List<Integer>> combine(int n, int k) {
List<List<Integer>> ans = new ArrayList<>();
dfs(n, k, 1, new HashSet<Integer>(), ans);
return ans;
}
public void dfs(int n, int k, int now, Set<Integer> set, List<List<Integer>> ans) {
if (set.size() == k) {
ans.add(new ArrayList<>(set));
return;
}
for (int i = now; i <= n; i++) {//参数now防止重复
if (!set.contains(i)) {
set.add(i);
dfs(n, k, i, set, ans);
set.remove(i);
}
}
}
优化了还是很慢:
public List<List<Integer>> combine(int n, int k) {
List<List<Integer>> ans = new ArrayList<>();
dfs(n, k, 1, new HashSet<Integer>(), ans);
return ans;
}
public void dfs(int n, int k, int now, Set<Integer> set, List<List<Integer>> ans) {
if (set.size() == k) {
ans.add(new ArrayList<>(set));
return;
}
for (int i = now; i <= n - (k - set.size()) + 1; i++) {//参数now防止重复 上届也有(set.size+(剩下来~n)至少得有k个吧 妙处在于set.size())
if (!set.contains(i)) {
set.add(i);
dfs(n, k, i, set, ans);
set.remove(i);
}
}
}
46. 全排列
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> ans = new ArrayList<>();
dfs(nums, new ArrayList<>(), new HashSet<Integer>(), ans);
return ans;
}
public void dfs(int[] nums, List<Integer> curt, Set<Integer> visited, List<List<Integer>> ans) {
if (curt.size() == nums.length) {
ans.add(new ArrayList<>(curt));
}
for (int i = 0; i < nums.length; i++) {
if (!visited.contains(nums[i])) {
visited.add(nums[i]);
curt.add(nums[i]);
dfs(nums, curt, visited, ans);
curt.remove(curt.size() - 1);
visited.remove(nums[i]);
}
}
}
52. N 皇后 II
在国际象棋的规则中,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
N皇后很久没做了,先自己尝试写下,回忆一遍
- 不同行列就是全排列, 所以就是全排列加了一个不同斜线的限制
- 那么不同斜线怎么限制呢?就是过该点斜率为 ± 1 \pm1 ±1的直线啦,简单一点,和相等=》主对角线上,差相等=》次对角线上
- 暴力开3个set,一次过,这应该算不上难题
public int totalNQueens(int n) {
ArrayList<Integer> temp = new ArrayList<>();
HashSet<Integer> set1 = new HashSet<>(); // 和相等 次对角线
HashSet<Integer> set2 = new HashSet<>(); // 差相等 主对角线
HashSet<Integer> set3 = new HashSet<>(); // 行或列不能相同
dfs(n, 0, set1, set2, set3);
return ans;
}
int ans = 0;
public void dfs(int n, int k, Set<Integer> set1, Set<Integer> set2, Set<Integer> set3) {
if (k == n) ans++;
for (int i = 0; i < n; i++) {//(k,i)
if (!set1.contains(k + i) && !set2.contains(k - i) && !set3.contains(i)) {
set1.add(k + i);
set2.add(k - i);
set3.add(i);
dfs(n, k + 1, set1, set2, set3);
set1.remove(k + i);
set2.remove(k - i);
set3.remove(i);
}
}
}
108. 将有序数组转换为二叉搜索树
开始觉得应该是AVL的创建,左旋右旋啥的,但是一看简单题,不应该呀,注意题目说的是任意AVL, 且数组有序,那么我就可以确定插入顺序了,通过插入顺序避免RL操作,不就退化为BST的插入了么,这才是简单题。
以二分的顺序插入,就行了
简单kadane,换个方式我就不会了,唉,调一晚上也不能全过
- 我的做法,只能过107/112=95%
// 两轮最大连续子数组和 试一下
public int maxSubarraySumCircular(int[] nums) {
int begin = 0;
int[] dp = new int[nums.length];
int ans = nums[0];
for (int i = 0; i < nums.length * 2; i++) {
if (i == 0) dp[0] = nums[0];
else {
int k = (i + nums.length) % nums.length;
int pre = (i - 1 + nums.length) % nums.length; // 上一个
if (k == begin) {
begin++; // 前面收缩一下,多几种情况,可能会更好 // 头作尾,大小不变
while (begin < nums.length && nums[begin] <= 0) {
dp[pre] -= nums[begin];//这种情况会增大
begin++;
}
dp[k] = dp[pre];//头做尾,大小不变
ans = Math.max(ans,dp[k]);
continue;
}
if (dp[pre] > 0) {
dp[k] = dp[pre] + nums[k];
} else {
dp[k] = nums[k];
begin = k;
}
ans = Math.max(ans, dp[k]);
}
}
return ans;
}
直接看题解吧,唉
看完题解傻眼了,真的是太蠢了,不会学以致用啊,跨数组,那就求最小子数组和呗,再用sum(arr)减去它不就行了吗,跨越数组边界的子数组,其补集是连续的呀。
begin没起到作用,竟然直接就过了
// 两轮最大连续子数组和 试一下
public int maxSubarraySumCircular(int[] nums) {
int begin = 0;//minBegin
int n = nums.length;
int[] dpMax = new int[n];
int[] dpMin = new int[n];
int ans = nums[0];
int sum = Arrays.stream(nums).sum();
for (int i = 0; i < n; i++) {
if(i==0){
dpMax[i] = nums[i];
dpMax[i] = nums[i];
}else {
if(dpMax[i-1]>0){
dpMax[i] = dpMax[i-1]+nums[i];
}else {
dpMax[i] = nums[i];
}
if(dpMin[i-1]<0){
dpMin[i] = dpMin[i-1]+nums[i];
}else {
dpMin[i] = nums[i];
begin = i;//最小连续字数组和的起点
}
ans = Math.max(ans,dpMax[i]);
ans = Math.max(ans,sum-dpMin[i]);
}
}
return ans;
}
- 代码层面优化一下
public int maxSubarraySumCircular(int[] nums) {
int n = nums.length;
int[] dpMax = new int[n];
int[] dpMin = new int[n];
int ans = nums[0];
int sum = Arrays.stream(nums).sum();
for (int i = 0; i < n; i++) {
if(i==0){
dpMax[i] = nums[i];
dpMin[i] = nums[i];
}else {
dpMax[i] = Math.max(nums[i],dpMax[i-1]+nums[i]);
dpMin[i] = Math.min(nums[i],dpMin[i-1]+nums[i]);
ans = Math.max(ans,dpMax[i]);
if(sum!=dpMin[i]) ans = Math.max(ans,sum-dpMin[i]);//子数组不能为空,也就是补集不能为全集
}
}
return ans;
}
- 再改成一维滚动数组 ▲ 应该能直接写出来的,连续子数组和本来就可以滚动数组
public int maxSubarraySumCircular(int[] nums) {
int n = nums.length;
int max = 0;
int min = 0;
int sum = 0;
int maxA = nums[0], minA = nums[0];//全局最大和最小连续值
for (int i = 0; i < n; i++) {
max = Math.max(nums[i], nums[i] + max);//以num[i]结尾的连续子数组最大值
maxA = Math.max(maxA, max);
min = Math.min(nums[i], nums[i] + min);//以num[i]结尾的连续子数组最小值
minA = Math.min(minA, min);
sum += nums[i];
}
return sum == minA ? maxA : Math.max(maxA, sum - minA);
}
427. 建立四叉树
- 递归分治 1ms 还行
public Node construct(int[][] grid) {
if (grid.length == 1) return new Node(grid[0][0] == 1, true);
return combine(grid, 0, 0, grid.length - 1, grid[0].length - 1);
}
public Node combine(int[][] grid, int x1, int y1, int x2, int y2) {//左闭右闭吧
//prints(x1, y1, '\t', x2, y2);
Node root = new Node(false, false);//默认不是叶子
// 递归边界
if (x2 - x1 == 1) {
int v = grid[x1][y1];
root.topLeft = new Node(grid[x1][y1] == 1, true);
root.topRight = new Node(grid[x1][y2] == 1, true);
root.bottomLeft = new Node(grid[x2][y1] == 1, true);
root.bottomRight = new Node(grid[x2][y2] == 1, true);
} else {
int midX = (x1 + x2) / 2, midY = (y1 + y2) / 2;
root.topLeft = combine(grid, x1, y1, midX, midY);
root.topRight = combine(grid, x1, midY + 1, midX, y2);
root.bottomLeft = combine(grid, midX + 1, y1, x2, midY);
root.bottomRight = combine(grid, midX + 1, midY + 1, x2, y2);
}
// 判断是否合并
if (root.topLeft.isLeaf && root.topRight.isLeaf && root.bottomRight.isLeaf && root.bottomLeft.isLeaf) {
boolean val = root.topLeft.val;
if (root.topRight.val == val && root.bottomLeft.val == val && root.bottomRight.val == val) {
root.val = val;
root.isLeaf = true;
// else里面也会有这种情况 所以置为null是不可避免的
root.topLeft = null;
root.topRight = null;
root.bottomLeft = null;
root.bottomRight = null;
}
}
return root;
}
node打印
public void levelOrder() {
Queue<Node> q = new LinkedList<>();
q.offer(this);
System.out.print("[");
while (!q.isEmpty()) {
Node top = q.poll();
System.out.print(top);
if(top.isLeaf) continue;//很重要
if (top.topLeft != null) q.offer(top.topLeft);//一定记住是top.
if (top.topRight != null) q.offer(top.topRight);
if (top.bottomLeft != null) q.offer(top.bottomLeft);
if (top.bottomRight != null) q.offer(top.bottomRight);
}
System.out.println("]");
}
- 再看看题解怎么做的,果然我的代码有问题,修改一下,0ms了
public Node construct(int[][] grid) {
return combine(grid, 0, 0, grid.length - 1, grid[0].length - 1);
}
public Node combine(int[][] grid, int x1, int y1, int x2, int y2) {//左闭右闭吧
int v = grid[x1][y1];
boolean same = true;
loop:
for (int i = x1; i <= x2; i++) {
for (int j = y1; j <= y2; j++) {
if (v != grid[i][j]) {
same = false;
break loop;
}
}
}
if (same) return new Node(v==1, true);//其他直接默认是null
int midX = (x1 + x2) / 2, midY = (y1 + y2) / 2;
return new Node(true,false,
combine(grid, x1, y1, midX, midY),
combine(grid, x1, midY + 1, midX, y2),
combine(grid, midX + 1, y1, x2, midY),
combine(grid, midX + 1, midY + 1, x2, y2)
);//左闭右开就没有+1 -1了
}
todo: 前缀树优化
23. 合并 K 个升序链表
- 就是归并呀,挺简单的呀,就是自己写的时间有点慢
public ListNode mergeKLists(ListNode[] lists) {
ListNode root = new ListNode();
ListNode tail = root;
ListNode def = new ListNode(Integer.MAX_VALUE);
while (true) {
ListNode h = def;
int cnt = 0;
for (int i = 0; i < lists.length; i++) {
if (lists[i] != null && lists[i].val < h.val) {
h = lists[i];
cnt = i;
}
}
if (h == def) break;
tail.next = h;
tail = h;
lists[cnt]=lists[cnt].next;
}
return root.next;
}
- 看看题解咋写的,果然没有这么简单,最优解需要用到优先队列
新建数据结构
// 优先队列 也就是堆的单个元素
class Status implements Comparable<Status> {
int val;
ListNode ptr;
Status(int val, ListNode ptr) {
this.val = val;
this.ptr = ptr;
}
// 自定义类 必须实现比较依据
public int compareTo(Status status2) {
return this.val - status2.val;
}
}
// 维护优先队列 根据队首元素,建立的小根堆
PriorityQueue<Status> queue = new PriorityQueue<Status>();
- 优先队列维护最小队,果然快了不少
class Status implements Comparable<Status> {
int val;
ListNode list;
Status(int val, ListNode list) {
this.val = val;
this.list = list;
}
@Override
public int compareTo(Status status) {
return this.val - status.val;
}
}
public ListNode mergeKLists(ListNode[] lists) {
PriorityQueue<Status> pq = new PriorityQueue<>();
for (ListNode list : lists) {
if (list != null) {
pq.offer(new Status(list.val, list));//自动O(logN)维护最小
}
}
ListNode root = new ListNode();
ListNode tail = root;
while (!pq.isEmpty()) {
Status top = pq.poll();
tail.next = top.list;
tail = tail.next;
if (top.list.next != null) {
pq.offer(new Status(top.list.next.val, top.list.next));
}
}
return root.next;
}
4. 寻找两个正序数组的中位数
408真题类似,408中两个数组长度一样,其实不一样也可以做,取个平均即可。看下一样时王道书的讲解。
todo 最优解好难啊

373. 查找和最小的 K 对数字 ▲水题为何不会呢
先分析一下题意,搞懂如何多路归并,就简单了
public class LC373Test extends Solution {
public static void main(String[] args) {
printReg("[1,7,11]", "[2,4,6]");
printReg("[1,1,2]", "[1,2,3]");
printReg("[1,2,4,5,6]", "[3,5,7,9]");
}
private static void printReg(String strs, String strs1) {
int[] nums1 = HzaUtils.string2Ints(strs);
int[] nums2 = HzaUtils.string2Ints(strs1);
if (nums1.length > nums2.length) {
int[] t = nums1;
nums1 = nums2;
nums2 = t;
}
for (int i = 0; i < nums1.length; i++) {
for (int j = 0; j < nums2.length; j++) {
print(nums1[i] + nums2[j], "\t");
}
print();
}
print();
}
}
每一行看成一条链表
不就成了一个多条链表的多路归并问题了么
当然链表条数越少越好,可以取Math.min(m,n,k)也可以Math.min(m,k)或者Math.min(n,k) 后两种就不用操心哪条队列短了
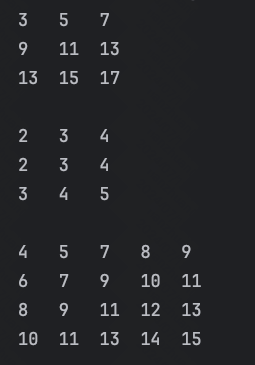
这样就知道怎么加入元素了,初始化加一列,也就是每条链的链头。然后哪个元素最小被选中了,就将该链下一个元素加入即可。多么简单
- 不考虑nums1是否小 (归并路数不最优)
public List<List<Integer>> kSmallestPairs(int[] nums1, int[] nums2, int k) {
ArrayList<List<Integer>> ans = new ArrayList<>();
int m = nums1.length, n = nums2.length;
PriorityQueue<int[]> heap = new PriorityQueue<>((a, b) -> (nums1[a[0]] + nums2[a[1]]) - (nums1[b[0]] + nums2[b[1]]));
for (int i = 0; i < Math.min(m, k); i++) {
heap.add(new int[]{i, 0}); // 队首都先进来
}
// 开始多路归并
while (ans.size() < k) {
int[] cur = heap.poll();
ans.add(Arrays.asList(nums1[cur[0]], nums2[cur[1]]));
if (cur[1] + 1 < n) {
heap.add(new int[]{cur[0], cur[1] + 1}); // cur[0] 条链表的下一个元素进来
}
}
return ans;
}
下面两种方法都不行:
// 确保nums1短
if (m > n) {
int[] t = nums2;
nums2 = nums1;
nums1 = t;
} // 编译不过
// 直接这么写答案会是反的
if (m > n) {
return kSmallestPairs(nums2, nums1, k);
}
也就快了那么一点点,作用其实不大:
boolean swap = false;
public List<List<Integer>> kSmallestPairs(int[] nums1, int[] nums2, int k) {
int m = nums1.length, n = nums2.length;
if (m > n) {
swap = true;
return kSmallestPairs(nums2, nums1, k);
}
ArrayList<List<Integer>> ans = new ArrayList<>();
PriorityQueue<int[]> heap = new PriorityQueue<>((a, b) -> (nums1[a[0]] + nums2[a[1]]) - (nums1[b[0]] + nums2[b[1]]));
for (int i = 0; i < Math.min(m, k); i++) {
heap.add(new int[]{i, 0}); // 队首都先进来
}
// 开始多路归并
while (ans.size() < k) {
int[] cur = heap.poll();
ans.add(swap ? Arrays.asList(nums2[cur[1]], nums1[cur[0]]) : Arrays.asList(nums1[cur[0]], nums2[cur[1]]));
if (cur[1] + 1 < n) {
heap.add(new int[]{cur[0], cur[1] + 1}); // cur[0] 条链表的下一个元素进来
}
}
return ans;
}
172. 阶乘后的零
- 方法1:尾数取余(多余的高位并不会影响末尾的0)
public int trailingZeroes(int n) {
int mul = 1;
int k = 0;
for (int i = 1; i <= n; i++) {
mul *= i;
while (mul % 10 == 0) {
mul /= 10;
k++;
}
mul %= 100000; // 防止溢出 多余的位数也起不到作用
}
return k;
}
- 方法2: 只用计算n!分解质因数后5的个数
public int trailingZeroes(int n) {
// 搞错了,不是n/5 而是log(n,5) n中质因子5的个数 1,2,3,4,5的顺序,每次出现一个尾数5,会提前出现3个2 因此2一定够用,找5即可
// 10=> 2*5 一个0一个5
// 100=> 2*5*2*5 2个0 2个5 正好
// 换底公式计算
int count = 0;
for (int i = 1; i <= n; i++) {
int N = i;
while (N % 5 == 0) {
N /= 5;
count++;
}
}
return count;
}
- 方法3: 优化计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 …
每隔5个数出现一个5
每隔25个数会多出现一个5 (2个5。55)
每隔125个数又会多出现一个5 (3个5. 55*5)
public int trailingZeroes(int n) {
int count = 0;
while (n > 0) { // n>5就有 不需要n%5==0。这里的n不是阶乘了
count += n / 5;
n /= 5;
}
return count;
}