java中word导入数据库
前言 >
word导入到数据库主要是对word的解析,word分为2003版、2007版以上,还有xml格式的,2003和2007以上的主要是对单元格内容进行判断,进行获取;而xml格式的主要是对标签进行解析,根据标签去内容,进行判断;还有htm格式的,就是对html内容读取,然后对标签进行获取内容;下面四种的解析方法都有:
1.直接附代码了
//导入word
@RequestMapping("/wordImport")
public String importTprkxx(@RequestParam("file")MultipartFile file, Model model) throws Exception {
try {
WordBean wordBean = new WordBean();
InputStream inputStream = file.getInputStream();
FileTypeUtils flt = new FileTypeUtils();
String filetype = flt.getFileType(inputStream);//根据流获取文件的类型(解析文件头判断文件格式)
InputStream is = file.getInputStream();
if (is.available() != 0) { //判断输入流是否为空(文件是否为空)
//根据不同的文件类型,进行不同的解析
if ("doc".equals(filetype)) {
wordBean = WordLead.readWord2003(is);
} else if ("docx".equals(filetype)) {
wordBean = WordLead.readWord2007(is);
} else if ("xml".equals(filetype)) {
wordBean = WordLead.readXml(is);
} else if ("htm".equals(filetype)) {
wordBean = WordLead.readHtm(is);
}
}
}catch(IndexOutOfBoundsException e) {
e.printStackTrace();
}
model.addAttribute("msg","导入成功!");
return "views/success";
}
2.两个工具类WordLead(解析word)和FileTypeUtils(获取文件类型)
import com.jdl.entity.WordBean;
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.usermodel.*;
import org.apache.poi.xwpf.usermodel.*;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTTblPr;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import javax.xml.parsers.*;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.*;
import org.xml.sax.SAXException;
public class WordLead {
/**
* word2007以上版本
* @param is
* @return
* @throws IOException
*/
public static WordBean readWord2007(InputStream is) throws IOException {
WordBean wg = new WordBean();
XWPFDocument doc = new XWPFDocument(is);
List<XWPFParagraph> paras = doc.getParagraphs();
List<XWPFRun> runs = paras.get(0).getRuns();
for (int i = 0; i < runs.size(); i++) {
runs.get(i);
}
for (XWPFRun run : runs) {
String text = run.getText(0);
}
for (XWPFParagraph para : paras) {//当前段落的属性
String text = para.getText();
}
List tables = doc.getTables();
XWPFTable xwpf = (XWPFTable) tables.get(0);
String text = xwpf.getText();
CTTblPr pr = xwpf.getCTTbl().getTblPr();
List<XWPFTableRow> rows = xwpf.getRows();
for (XWPFTableRow row : rows) {
List<XWPFTableCell> tableCells = row.getTableCells();
for (int i = 0; i < tableCells.size(); i++) {
if (tableCells.get(i).getText().equals("事件编号")) {
wg.setSj_bh(tableCells.get(++i).getText());
} else if (tableCells.get(i).getText().equals("姓名")) {
wg.setRy_xm(tableCells.get(++i).getText());
} else if (tableCells.get(i).getText().equals("地址")) {
wg.setRy_dz(tableCells.get(++i).getText());
} else if (tableCells.get(i).getText().equals("事件类型")) {
wg.setSj_lx(tableCells.get(++i).getText());
} else if (tableCells.get(i).getText().equals("事件地点")) {
wg.setSj_dd(tableCells.get(++i).getText());
} else if (tableCells.get(i).getText().equals("事件内容")) {
wg.setSj_nr(tableCells.get(++i).getText());
}
}
}
return wg;
}
/**
* word2003版
* @param stream
* @return
* @throws IOException
*/
public static WordBean readWord2003(InputStream stream) throws IOException {
WordBean wg = new WordBean();
HWPFDocument hwpf = new HWPFDocument(stream);
Range range = hwpf.getRange();// 得到文档的读取范围
TableIterator it = new TableIterator(range);// 迭代文档中的表格
String info = "";
String cellString = "";
if (it.hasNext()) {
TableRow tr = null;
TableCell td = null;
Paragraph para = null;
Table tb = it.next();
for (int i = 0; i < tb.numRows(); i++) {
tr = tb.getRow(i);
for (int j = 0; j < tr.numCells(); j++) {
td = tr.getCell(j);// 取得单元格
// 取得单元格的内容
para = td.getParagraph(0);
cellString = para.text();
boolean flag = true;
if (cellString != null && cellString.compareTo("") != 0 && flag == true) {
// 如果不trim,取出的内容后会有一个乱码字符
cellString = cellString.trim();
}
if (cellString.equals("事件编号")) {
wg.setSj_bh(tr.getCell(++j).getParagraph(0).text());
} else if (cellString.equals("姓名")) {
wg.setRy_xm(tr.getCell(++j).getParagraph(0).text());
} else if (cellString.equals("地址")) {
wg.setRy_dz(tr.getCell(++j).getParagraph(0).text());
} else if (cellString.equals("事件类型")) {
wg.setSj_lx(tr.getCell(++j).getParagraph(0).text());
} else if (cellString.equals("事件地点")) {
wg.setSj_dd(tr.getCell(++j).getParagraph(0).text());
} else if (cellString.equals("事件内容")) {
wg.setSj_nr(tr.getCell(++j).getParagraph(0).text());
}
}
}
}
return wg;
}
/**
* xml格式word
* @param stream
* @return
* @throws IOException
* @throws ParserConfigurationException
* @throws SAXException
*/
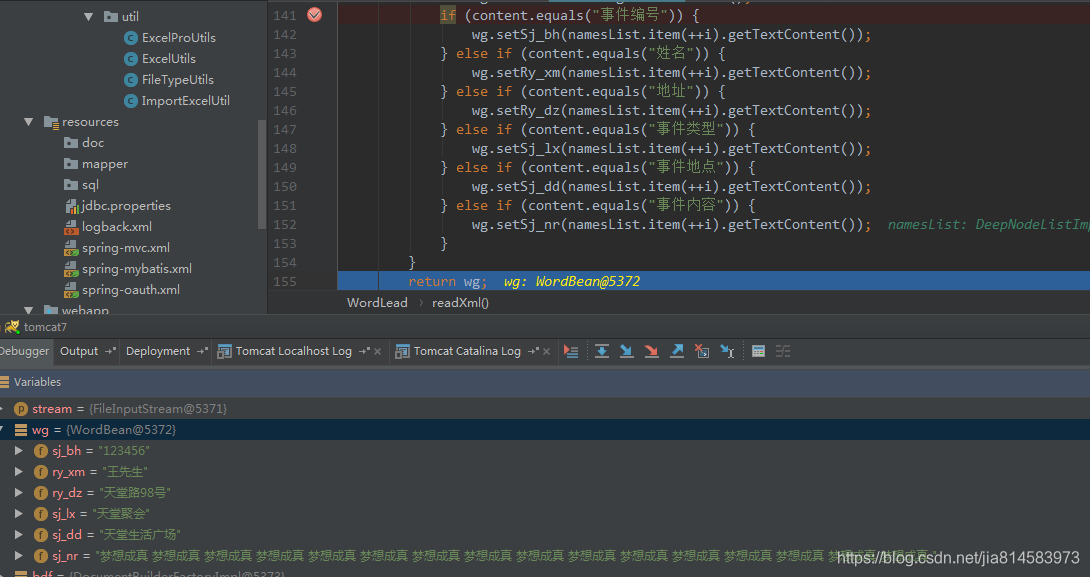
public static WordBean readXml(InputStream stream) throws IOException, ParserConfigurationException, SAXException {
WordBean wg = new WordBean();
DocumentBuilderFactory bdf = DocumentBuilderFactory.newInstance();
DocumentBuilder bd = bdf.newDocumentBuilder();
Document doc = bd.parse(stream);
doc.getDocumentElement().normalize();
Element root = doc.getDocumentElement();
String rootName = root.getNodeName();
NodeList namesList = doc.getElementsByTagName("w:tc");
int length = namesList.getLength();
for (int i = 0; i < length; i++) {
Node node = namesList.item(i);
String content = node.getTextContent();
if (content.equals("事件编号")) {
wg.setSj_bh(namesList.item(++i).getTextContent());
} else if (content.equals("姓名")) {
wg.setRy_xm(namesList.item(++i).getTextContent());
} else if (content.equals("地址")) {
wg.setRy_dz(namesList.item(++i).getTextContent());
} else if (content.equals("事件类型")) {
wg.setSj_lx(namesList.item(++i).getTextContent());
} else if (content.equals("事件地点")) {
wg.setSj_dd(namesList.item(++i).getTextContent());
} else if (content.equals("事件内容")) {
wg.setSj_nr(namesList.item(++i).getTextContent());
}
}
return wg;
}
/**
* htm格式word(因为一个class里会有jar冲突,解析方法单独写了一个类)
* @param stream
* @return
* @throws IOException
* @throws ParserConfigurationException
* @throws SAXException
*/
public static WgglFb readHtm(InputStream stream) {
HtmWordPro htmWord=new HtmWordPro();
WgglFb fb = htmWord.readHmt(stream);
return fb;
}
}
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class HtmWordPro {
public WgglFb readHmt(InputStream stream) {
WordBean wg = new WordBean();
String html = getFileContent(stream);//获取html内容
Document doc = Jsoup.parse(html);
Elements rows = doc.select("table").get(0).select("tr");
for(int i=0;i<rows.size();i++){
Element row = rows.get(i);
int tds = row.select("td").size();
for(int j=0;j<tds;j++){
String content = row.select("td").get(j).text().trim();
if (content.equals("事件编号")) {
wg.setSj_bh(row.select("td").get(++j).text().trim());
} else if (content.equals("姓名")) {
wg.setRy_xm(row.select("td").get(++j).text().trim());
} else if (content.equals("地址")) {
wg.setRy_dz(row.select("td").get(++j).text().trim());
} else if (content.equals("事件类型")) {
wg.setSj_lx(row.select("td").get(++j).text().trim());
} else if (content.equals("事件地点")) {
wg.setSj_dd(row.select("td").get(++j).text().trim());
} else if (content.equals("事件内容")) {
wg.setSj_nr(row.select("td").get(++j).text().trim());
}
}
}
return wg;
}
/**
* 获取html内容
* @param stream
* @return
*/
public static String getFileContent(InputStream stream) {
try {
BufferedReader bis = new BufferedReader(new InputStreamReader(stream,"GBK"));//写上文件格式,要不然会乱码
StringBuilder szContent = new StringBuilder();
String szTemp;
while ((szTemp = bis.readLine()) != null) {
szContent.append(szTemp);
}
bis.close();
return szContent.toString();
} catch (Exception e) {
return "";
}
}
}
import java.io.IOException;
import java.io.InputStream;
import java.util.HashMap;
public class FileTypeUtils {
// 缓存文件头信息-文件头信息
public static final HashMap<String, String> mFileTypes = new HashMap<String, String>();
static {
//文档
mFileTypes.put("D0CF11E0", "doc");
mFileTypes.put("504B0304", "docx");
mFileTypes.put("3C3F786D", "xml");
mFileTypes.put("3C68746D", "htm");
mFileTypes.put("3C21444F", "html");
}
/**
* 根据文件路径获取文件头信息
* @param is
* @return 文件头信息
*/
public static String getFileType(InputStream is) {
return mFileTypes.get(getFileHeader(is));
}
/**
* 根据文件路径获取文件头信息
* @param is 文件路径
* @return 文件头信息
*/
public static String getFileHeader(InputStream is) {
String value = null;
try {
byte[] b = new byte[4];
/*
* int read() 从此输入流中读取一个数据字节。 int read(byte[] b) 从此输入流中将最多 b.length
* 个字节的数据读入一个 byte 数组中。 int read(byte[] b, int off, int len)
* 从此输入流中将最多 len 个字节的数据读入一个 byte 数组中。
*/
is.read(b, 0, b.length);
value = bytesToHexString(b);
} catch (Exception e) {
} finally {
if (null != is) {
try {
is.close();
} catch (IOException e) {
}
}
}
return value;
}
/**
* 将要读取文件头信息的文件的byte数组转换成string类型表示
* @param src
* 要读取文件头信息的文件的byte数组
* @return 文件头信息
*/
private static String bytesToHexString(byte[] src) {
StringBuilder builder = new StringBuilder();
if (src == null || src.length <= 0) {
return null;
}
String hv;
for (int i = 0; i < src.length; i++) {
// 以十六进制(基数 16)无符号整数形式返回一个整数参数的字符串表示形式,并转换为大写
hv = Integer.toHexString(src[i] & 0xFF).toUpperCase();
if (hv.length() < 2) {
builder.append(0);
}
builder.append(hv);
}
return builder.toString();
}
}
3.WordBean
public class WordBean {
private String sj_bh;//事件编号
private String ry_xm;//人员姓名
private String ry_dz;//人员地址
private String sj_lx;//事件类型
private String sj_dd;//事件地点
private String sj_nr;//事件内容
public String getSj_bh() {
return sj_bh;
}
public void setSj_bh(String sj_bh) {
this.sj_bh = sj_bh;
}
public String getRy_xm() {
return ry_xm;
}
public void setRy_xm(String ry_xm) {
this.ry_xm = ry_xm;
}
public String getRy_dz() {
return ry_dz;
}
public void setRy_dz(String ry_dz) {
this.ry_dz = ry_dz;
}
public String getSj_lx() {
return sj_lx;
}
public void setSj_lx(String sj_lx) {
this.sj_lx = sj_lx;
}
public String getSj_dd() {
return sj_dd;
}
public void setSj_dd(String sj_dd) {
this.sj_dd = sj_dd;
}
public String getSj_nr() {
return sj_nr;
}
public void setSj_nr(String sj_nr) {
this.sj_nr = sj_nr;
}
}
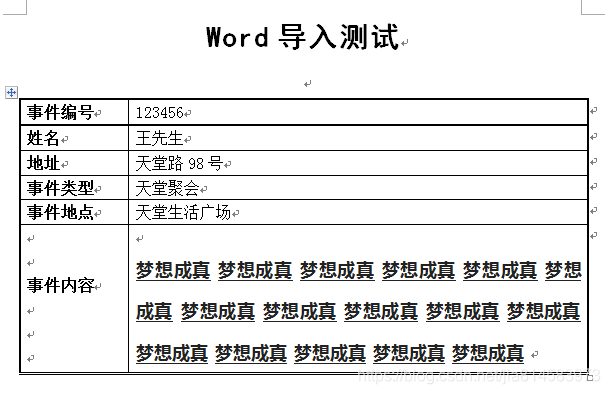
4.结果