20210127
当二分类只预测一种标签的时候比如只预测正样本的时候
假正率的分子分母都是零 ROC 画不出来的
负样本其实还是有用的,用于模拟真实环境
当二分类的时候 看模型是否可用 可以看ROC
调阈值 看模型是否可用
当多分类的时候 就调阈值 看所有类的平均F1
20201203
低势(一个有限集的元素个数是一个自然数)类别特征的处理方法是One-hot encoding
20200607
边缘分布律:两个随机变量一个固定一个值,另一个取遍所有值
在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。置信区间给出的是被测量参数的测量值的可信程度,即前面所要求的“一定概率”。这个概率被称为置信水平。
置信度
线性组合: 变量之间通过加减相互联系
常量和变量之间通过加减乘除相互联系
所谓模式识别的问题就是用计算的方法根据样本的特征将样本划分到一定的类别中去。 [1] 模式识别就是通过计算机用数学技术方法来研究模式的自动处理和判读,把环境与客体统称为“模式”
归纳和演绎(衍生出细节)是相反的过程
20200509
生成器:生成某些东西 比如对抗学习里面的一个模型负责生成一张图片
判别器:用来判断图片的真假
类别于GAN的判别器 但 electra 不是gan
20200427
贝叶斯
表征:显露于事物外部的迹象、征象
20200426
归纳就是指蕴涵
20200423
单调的意思:只朝一个方向变化
结构化自然语言:

- 由逻辑控制和自然语言组成
2.形式化语言 由符号组成 相当于编程语言
20200420
线性:成一条直线
20200419
micro 微观
score是评价函数 cv里面用的
Metrics 也是评价函数 别的情况下用的
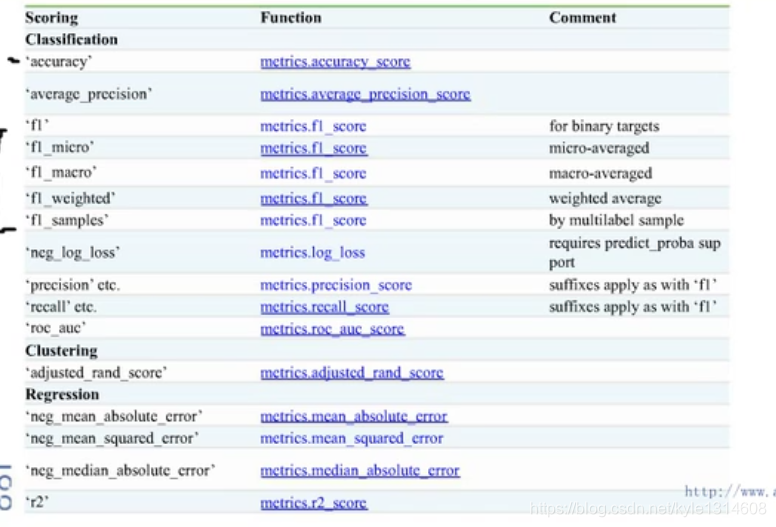


只看前面k个 而不是全部的
不用算整个PR 曲线下的面积
一页有10个
MAP 相当于不同的模型
越相关 排在越前面越好


AP
积分就是平均?
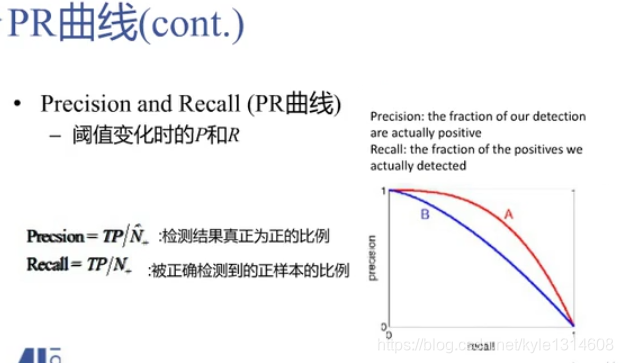
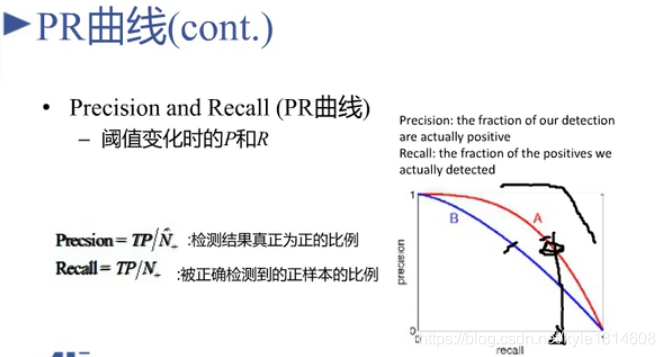
PR 曲线
只看正样本

越右上角越好
A 比B 好
相同recall下 精准率越高越好
准确率:预测对的值除以中的样本数
精准率不同:平常说的是精准率 预测对的值里面真正值的比例
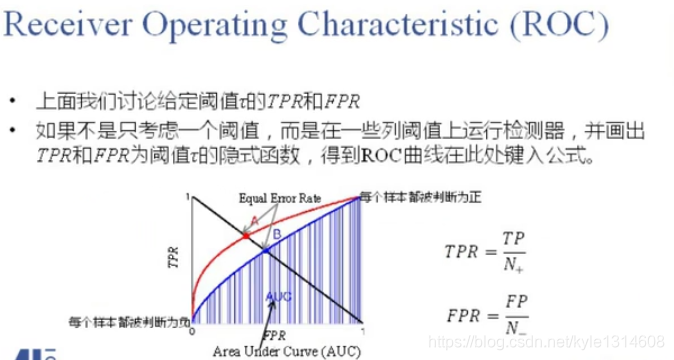
ROC 是真正率和和假正率画出来的
这里的阈值是指的logist 损失里面的阈值?
很多种阈值都可一下 多分类应该是没有的(可以看成多个二分类?) 只有二分类有这个图
刚开始把每个样本都判断为负 二者都低
越好的模型越往右上角
不同算法的曲线不同 可以看出好坏
AUC 曲线下的面积求积分
一个是感性图形 一个是数值
AUC 越大越好
log损失是0-1损失的上界,从概率来说 极大似然估计

评价指标
RMSE 数值的范围和原始数据可比
RMSLE y很大 先log变换

组合把先验也加进去了
先验概率
后验概率
因为某个x=k 的某个类别可能没有 组合成似然
详细看这个链接
参考文献
one hot 1 到k维
均值编码 1 到C 维
分支为联合概率
分母为边缘概率
回归也可以用
维度高 就叫高基数
降维 问题
这里是只对一列数据处理 还是多列进行处理
用的最多的是聚类?
均值编码 很实用 效果好





编完之后是连续的
labelencoder
类别型特征 xgboost
高阶相关
强相关 去掉,弱的 PCA 降维
奇异点
直方图尾巴 离总体分布远
散点图孤立的点
核密度估计看起来更平滑 移动平均?
特征选择





最后只用这5个特征训练模型就好了
和随机森林给出的重要性 相对值可以比较 绝对值没有可比性
上下 红色部分是差异
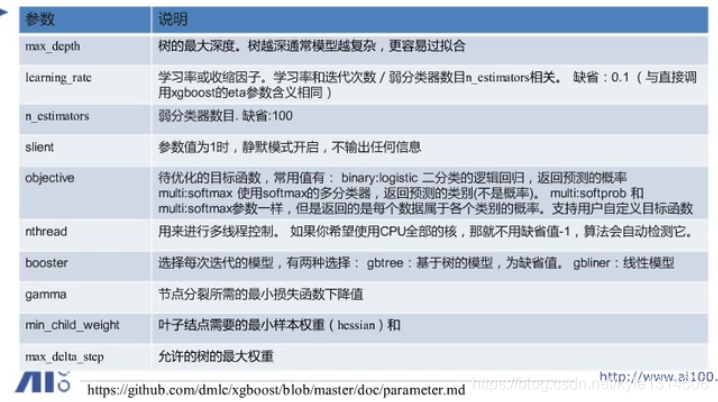
objective 是损失函数
线程 -1 cpu的核都用上
Gamma 什么时候分裂停止
Reg 正则
xgboost 参数
booster 基分类器 用线性模型 不足够用
gamma 要调整 不能设置为零 设置为零 为负的时候就停止了
叶子节点的样本权重就是二阶导数
max default step 用于不均衡数据 收敛更快 不用管?
subsample 训练的时候 用样本的比例
前面两个用心调
第三个一般设置为0.7 或者 0.8
正负样本平衡

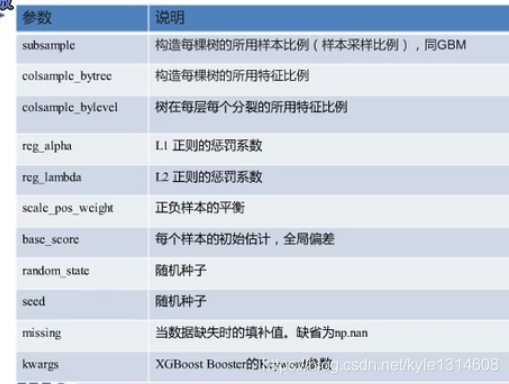
xgboost 重要的参数 样本个数 学习率 增益阈值
特征抽样个数 样本抽样个数 每层抽样个数
两个正则参数 叶子节点最小权重
把这些参数分成多个组来调 而不是一个一个调
xgboost精确搜索伪代码
xgboost近似搜索伪代码



局部近似 每次的候选数目没有那么多
近似搜素算法
全局近似
候选数目足够多 不管是全局还是局部都能达到精确搜索的精度
如何利用分布特征
复杂度 相当于的组合里面的分步
目标函数减小量 增益
增益最大的最好



可能性太多 用贪心算法来做
X 样本 红框叶子节点的分数为预测值
W 是某个叶子节点分数 q 是索引 表示是那个叶子节点
T个叶子节点
W 是个T维向量,每个叶子节点的分数是多少


第一个小孩的q=1 第一个叶子节点
高阶无穷小
德尔塔很小 是个邻域 那么 其3次方就很小了 不考虑了


二者有很强的耦合关系 也就是相关了
梯度提升


收缩因子 学习率


Gbdt Xgboost 同理 拟合每一步的残差
用一棵树来逼近残差 βm 调节 权重
指数损失对 离群值敏感 预测不对 指数增长是很快的增长
后面两种是改进
如果取softmax 就变成多分类了
损失函数可以决定最后输出的类别?
前向逐步递增
再加一个学习器 之前已经在模型中的学习器不再改变 只改变
要加入的


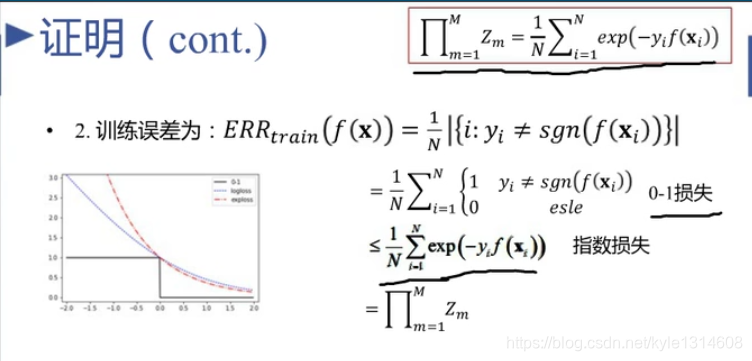
指数函数 红色 是 log损失 蓝色 的上界
0-1损失 黑色
归一化变成一个分布
求解问题 把不会的问题 转换为会的方案
由线性组合推广而来


gbm ,xgboost 都是基于树的模型 cart 为基分类器
cart gbdt xgboost
随机森林
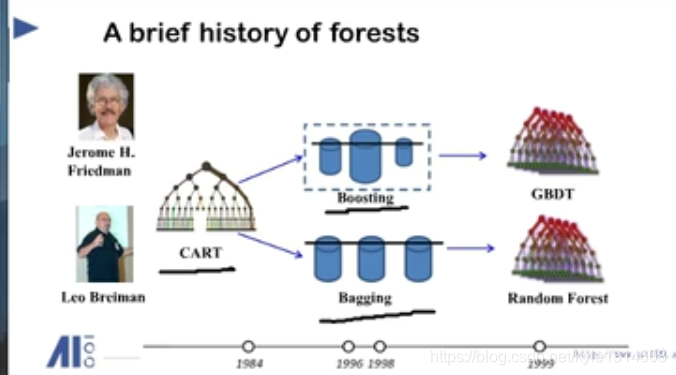
随机森林建树是并行的
xgboos gbm 是串行的
树的相关性


多个模型的平均 作为 结果 降低方差 提高参数的稳定性
bagging:有放回的抽样

class weight 类别权重
还有叶子节点权重?
完全树:比如第二层有四个结点,四个节点都生成
弱学习器:比随机猜测好一点就行了
贪心:只看每一层损失是否减小
随机森林减小模型方差
数模型优点
不敏感:不跟随变化
不做预处理
排序是指的对某个特征所有值进行排序 不是对每个特征名排序
没有选择的特征实际上是没有用的


树模型只是排序 在阈值处 和绝对值没有关系
而线性回归 需要归一化 特征
gini系数越到 贫富差距越大
差异越大 分的越纯净
数据量大,参数量可以增大一些
数据量少,参数量少些
经验损失就是在训练集上的损失
结构风险就是模型复杂度

Refit=true 把所有数据用最佳参数来训练的模型
交叉验证 均衡抽样 按全体样本的比例来的
eval metric
评估准则 错误率

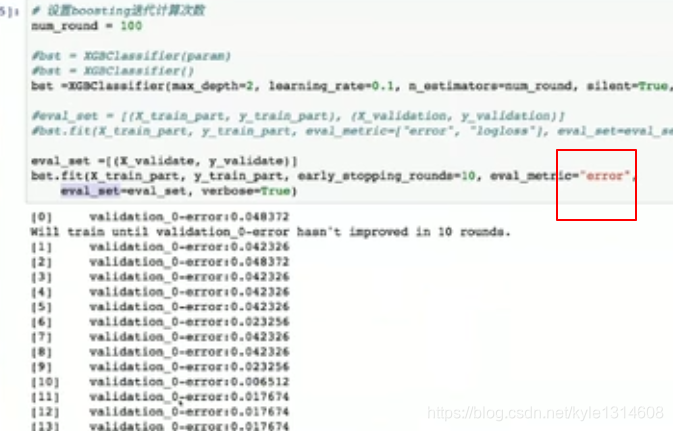
error 是错误率
学习曲线怎么画出来的

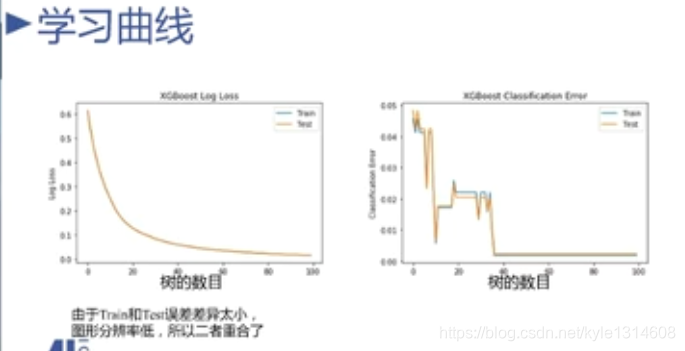
横轴是树的数目
纵轴是损失 右边是logloss 不平滑 抖动
右边的线条最后变平了 从开始变平的地方取值就可以了
后面都不用再增加了
eta 学习率
slient 输出运行中间结果报告
在线学习:模型训练到某个阶段的时候可以暂存起来,以后再有数据的时候再继续训练
20200417
非平凡是指它已经超越了一般封闭形式的数量计算,而将包括对结构、模式和参数的搜索.
20200416
https://blog.csdn.net/otengyue/article/details/89426004
F1值:
精确率越高越好,召回率越高越好。
下边式子(2)可以由式子(1)推导出来
从(1)看出,Recall不变时,Precision越大,1/Precision越小,从而F1越大。
同理: Precision不变时,Recall越大,1/Recall越小,从而F1越大。
f1_score中关于参数average的用法描述:
‘micro’:通过先计算总体的TP,FN和FP的数量,再计算F1
‘macro’:分别计算每个类别的F1,然后做平均(各类别F1的权重相同)

F1 得分
20231117
准确率的计算
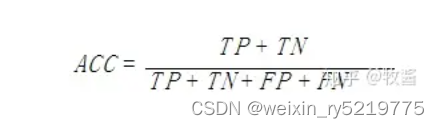
20211227
https://www.zhihu.com/question/332571344
https://mp.weixin.qq.com/s/VklHlJvTlADcRaKZNqT2hg
micro和macro区别应该选macro能较好的反映实际情况?
总结一下,正确的做法是用AUC评价模型能力,选取好的模型之后根据实际需求确定阈值,再用Macro F1计算性能指标
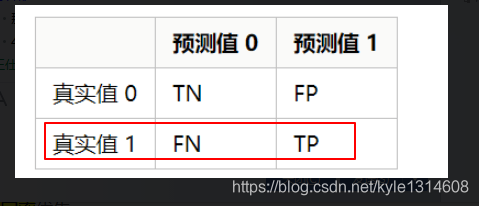
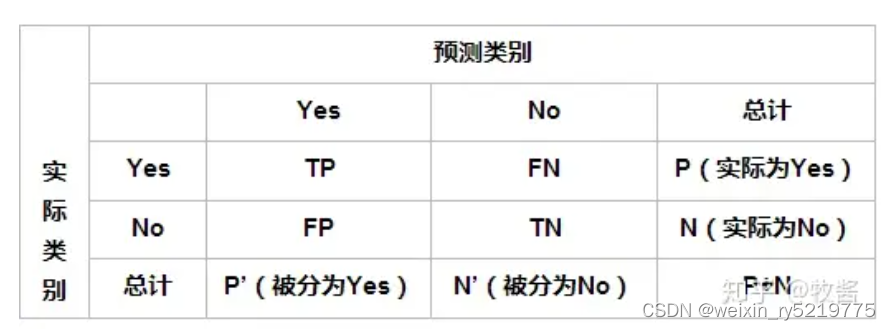
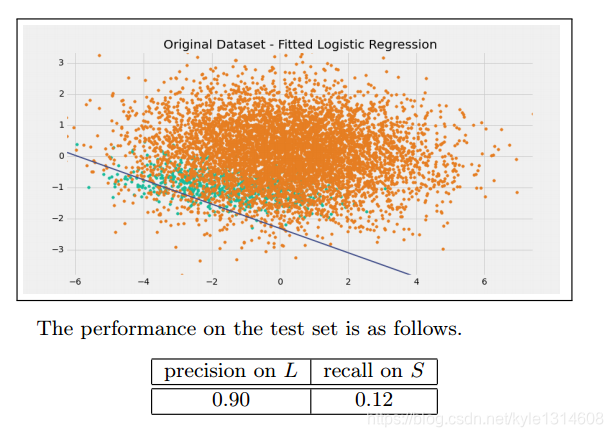
应用多分类问题,把每个类别单独视为”正“,所有其它类型视为”负“,考虑如下的混淆矩阵

精确率 精准率 查准率 为列,召回率为行(招行,真行)
召回率 覆盖率 查全率 :原来为正的被预测为正的比例
准确率: 比如1的准确率 为 TP/(FN+TP)
所以定精准率 60%
召回率90% 就可以用于实际 错应该是正确率和召回率都要80%或90%以上
召回率优先
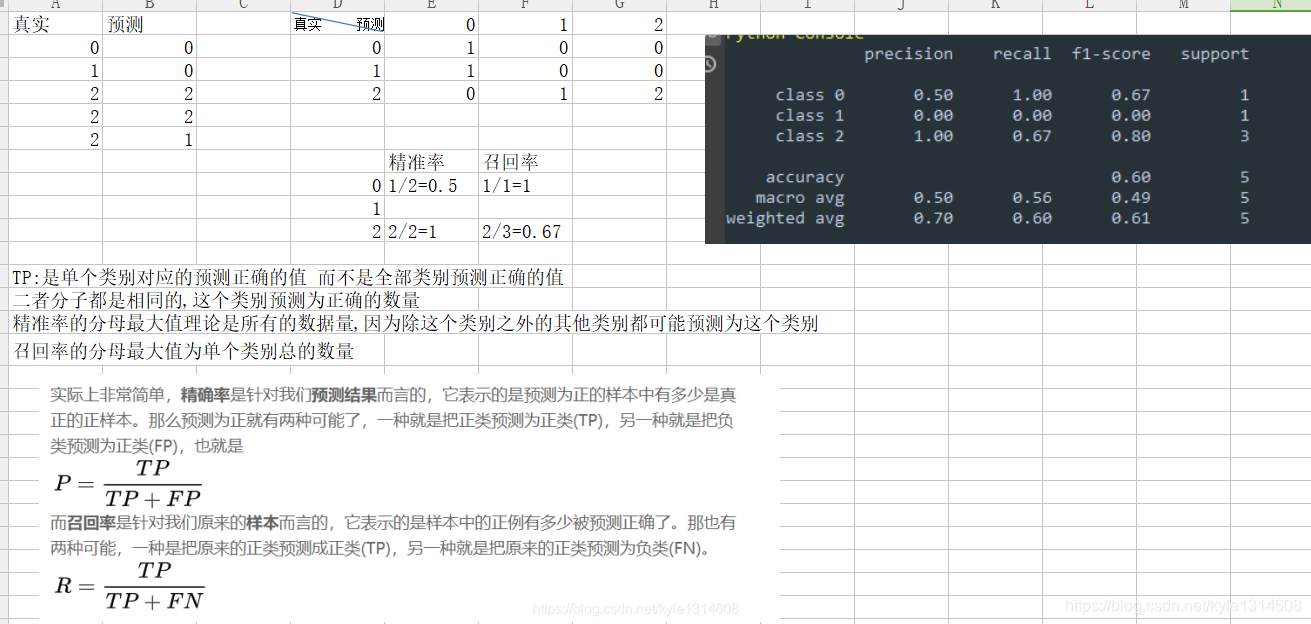
TPR 与 FPR
P表示“正”的,为预测为“好的”,即要从总体中挑出来的。
真正例率 TPR = TP / (TP + FN)
表示,预测为正例且真实情况为正例的,占所有真实情况中正例的比率。
假正例率 FPR = FP / (TN + FP)
表示的,预测为正例但真实情况为反例的,占所有真实情况中反例的比率。
这里还有问题 还的再理解
20210114
两个指标的分母的两部分是此消彼长的关系
两个指标之间没啥关系 分别对正负样本的
预测情况进行统计
看一列 为 0,1的值
TPR 高 说明 大部分 为1的位置预测对了
FPR 高 说明大部分 为0的位置预测错了
对混淆矩阵的分别两行进行统计
这是ROC的两个指标 精准率和召回率不是ROC的两个指标
精准率和召率 以右下角指标为中心 对其列和行进行
统计
还要再理解 两组指标之间的关系
https://www.jianshu.com/p/be2e037900a1
20201209
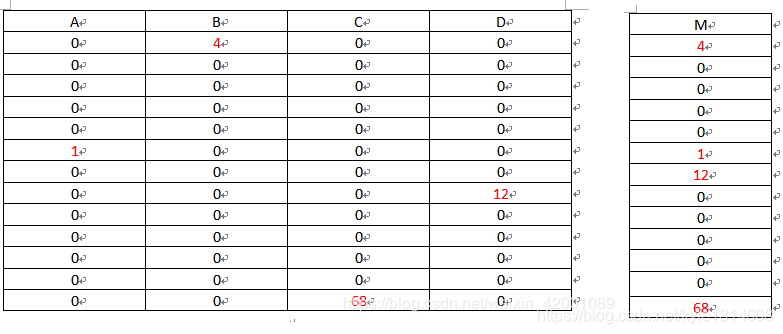
混淆矩阵
 说明这个类别很多被预测为其他类别了,另外负例占比很大,样本不均衡
二者都高 说明这个类别都预测为了自身,同时别的类别没有预测成为他
二者都低:说明这个类别很多预测成了其他类别,其他类别也有很多预测成了这个类别 而且这两个其他类别 可能不重合
这种情况下很可能 样本数据错了,或者这个模型根本不适合这样的数据

20220114
二分类还是需要精准率和召回率二者都高才行
20220331
https://zhuanlan.zhihu.com/p/32829048
n-gram
20200415
n-grams表示n个单词长度的词组集合
修正,惩罚的意思是 使情况向好的方向转变,就是和
优秀的指标对比 往优秀的指标靠拢
比如:翻译评估指标 如果只看1gram
但很明显 真是数据是只有只有两个the 那就想办法把分子
改成2,通过某种方法 训练的时候因为有预测结果和真是的数据
可以从这两方面想办法

20200414
训练的实质就是使模型预测的输出越来越接近真实的值
既然有这样的想法,就必须先将我们上面进行one-hot方式表示的单词,用一个稠密的向量进行表示,也就是进行一个映射。
这个映射过程,就被称作是嵌入(embedding),因为是单词的映射,所以被叫做词嵌入(word embedding),好,既然知道了要做这样的embedding,那具体该怎么去做呢?
查找表

20200413
mute :禁用断点
word2vec:如何应用 最终训练出一个m行n列的参数矩阵
m 相当于原来训练数据的词库大小,n 为要训练出来的目标向量的维度 也就是用n为的向量来表示一个词
应用的时候就是用这个词的one hot 向量乘以这个参数矩阵
得到这个词的n维向量表示 相当于考虑了这个词 与窗口内
的词的相关关系 n维向量的每个值 相当 这个词语窗口内词的
特征.n维度 就是n个特征值用来描述这个关系
这个好像不适合 字段的值为短文本的情况 短文本的前后关系
太少了 不过把值 组合成一个文本 应该还是可以用的
corpus:词库
就是判断 (x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语x和词语y放在一起,是不是人话。
词嵌入:每个one hot 向量 用公共的一些特征的取值来表示
把很高维度的词缩减为 低纬度的词向量
20200410
一个类别准确率高,另一个类别召回率低 那就是验证的样本不均衡
Tomek link:
我们认为,对于新产生的青色数据点与其他非青色样本点距离最近的点,构成一对Tomek link,如下图框中的青蓝两点
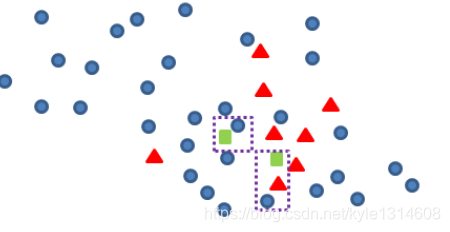
我们可以定义规则:
当以新产生点为中心,Tomek link的距离为范围半径,去框定一个空间,空间内的少数类的个数/多数类的个数<最低阀值的时候,认为新产生点为“垃圾点”,应该剔除或者再次进行smote训练;空间内的少数类的个数/多数类的个数>=最低阀值的时候,在进行保留并纳入smote训练的初始少类样本集合中去抽样
所以,剔除左侧的青色新增点,只保留右边的新增数据如下:
20200408
最近邻规则(edited nearest neighbor: ENN)
由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General)
网上关于数据不平衡处理的讨论有很多,大致来说,数据不平衡的处理方法有三种:一是欠采样,二是过采样,三是调整权重。
20200403
元学习,元数据
就是学习的学习,数据的数据
20200327
DAE:Denoising Autoencoder 去噪自编码
在ELMO/BERT出来之前,大家通常讲的语言模型其实是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词,这种类型的LM被称为自回归语言模型。
20200318
ROC:根据阈值来统计两个指标 并画图 其实就是一次跑的结果 不同阈值 两个指标不同
resampling: 重采样 就是重复抽样?
采样率:0.8 从集合中抽80%的数据?
RandomPick:随机抽取
抽样肯定还是要抽的,毕竟减少了样本减少了复杂度嘛!没有权值我们根据什么抽呢?其发现可以将一阶导数看做权重,一阶导数大的说明离最优解还远,这部分样本带来的增益大,或者说这部分样本还没有被好好训练,下一步我们应该重点训练他们。
multiply就是理论部分所说的对小梯度集合的补偿常数(1-a)/b
gradients_[idx] *= multiply;
hessians_[idx] *= multiply;
问题 是怎么对小梯度集合进行补偿的
这里的补偿是指对一阶导数和二阶导数的数字进行增大
根据公式1-a)/b
如果大梯度的抽取少,就把一些小梯度的值变成大梯度?
mp_gradients[i] += std::fabs(gradients_[idx] * hessians_[idx]);
会发现其和理论部分还有有点不一样,理论部分只是高度概括使用导数(一阶导数),实际上这里是是使用了一阶导数和二阶导数的乘积进行排序的。 二者共同作用来决定
特征的稀疏就说明很多特征是相互排斥的,例如它们不总是同时取非0值,所以我们可以很放心的将多个特征捆绑为一个特征
PCA适合特征有冗余性比如:动物类别,是否是狗(是笔者自己举的例子),很明显两个特征其实有冗余性
通过特征捆绑进行特征降维
排斥小,冲突大:两个特征的很多值都取非零
是不是感觉很眼熟,是的其逆过程即从右图到左图就是有种ont-hot的味道。
偏值,偏置:就是在原来的基础上再加上一个常数
高纬度的数据集:一般指的是特征多
Construct:构造
Sparsity-aware Split Finding稀疏感知算法,
所谓的直方图差加速概念,说白了就是我们只要得到比如左子树,那么右子树就直接可以使用总的减去左子树得到,是不是很快!是不是很巧妙!这就是差加速的概念。
问题
20200317
metric:损失函数的评估指标 比如 MSE 等
fraction: 比例
bagging:不重复抽样?
enum 枚举
alias:别名
trade off:权衡
sum_gradients:一阶导数和
sum_hessians:二阶导数和
导数和的意义是什么 把所有样本的加起来(综合结果)决定如何更新,而不是依靠单个样本来更新 理解的时候还是以
单梯度和以及单二阶导数来理解
one-hot形式和非one-hot形式,one-hot形式其实是一种one VS many的情况,而非one-hot是一种many VS many形式
那么不言而喻第二种在大数据的情况下,好处多多,起码考虑的情况更多,而且不至于树深度太大,还有一个直观的好处就是单一的分裂其实带来的增益通常较少,因为每次仅仅从一大推信息中区分出那么一丁点信息,带来的信息增益自然不会高,第二种则是不一样。
神经网络和机器学习的区别
神经网络,深度学习适合于特征特别多,或者图像,音频这种直接输入原始数据(数据量就很多了) 通过网络结构 抽取大量的特征,
从而能够比较精细的描述模型得到较好的结果,反之就最好用普通的机器学习方法来实现不依赖于在已有的特征上构建新特征
而是直接找寻现有特征和目标字段直接的关系
若整数b除以非零整数a,商为整数,且余数为零, 我们就说b能被a整除(或说a能整除b),b为被除数,a为除数,即a|b(“|”是整除符号),读作“a整除b”或“b能被a整除”。
小整除大
前整除后
小钱整出大猴
20200315
两者不存在区别之分,因为两者是包含与被包含的关系。微分方程包括常微分方程。
微分方程指含有未知函数及其导数的关系式。解微分方程就是找出未知函数。
未知函数是一元函数的,叫常微分方程;未知函数是多元函数的叫做偏微分方程。
含有未知函数的导数,如 的方程是微分方程。 一般的凡是表示未知函数、未知函数的导数与自变量之间的关系的方程,叫做微分方程。
20200312
贝叶斯公式解释
i.在某些前提下,结论发生的概率=>在结论已发生的情况下,前提发生的概率。
20200311
透明性有两种解释
1.看不见
2.完全看见
演绎推理
归结就是推理的意思
归谬法

20200309
若同态映射 f 是一个双射,则称 f 为 G 到 G’ 的同构映射,这时称群 G 和 G’ 同构。
20200308
不动点 输入值等于输出值
对偶:


20200307
封闭性:群 运算结果仍在群里面
结合律:忽略顺序
单位元:和别人相运算,结果仍是别人,不改变
逆元:a和另一个数运算得到单位元
以上所有运算都是一种
20200304
和函数
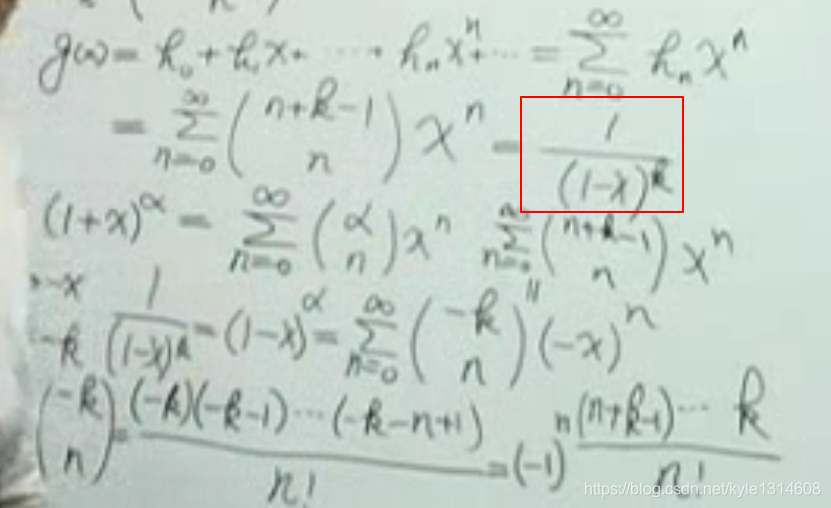
20200229
归一化:
把两个向量A、B分别归一化(就是分别除以自己的长度),得到
C = A/|A| ,D = B/|B| ,然后 C + D 就是原来 A和B的角平分线
向量点击和余弦相似度的区别
余弦相似度是向量点积归一化的结果 去掉量纲 在这里也就是
长度的影响
向量内积的意义
https://www.jianshu.com/p/54eea6b7856e
20200228
深度学习 特征图扫描的技术
输入数据为1 最终进入系统的格式为3
2为系统相乘相加的形式
4为最终输出结果
每次计算要加上偏执

20200228
深度学习中 linear 的作用是把所有信息集中转换到目标分类上
迭代:在上一次处理的基础上,再重头开始处理
20200223
球面上的一点 只有一个切面
μ读音:miu。σ读音:sigma
如果结果残差不是正态分布 说明用线性回归来拟合数据是不合适的
可能是非线性回归
这里的类是对应因变量的取值 如果是连续型的那就只有一类 销售量
如果是离散型的那就有几类就假设几类 黑白球
当总体只有一类的时候 我们假设符合正态分布
如果有两类假设符合二项分布
样本权重是对损失函数来说的对于类别少的样本 通过调节其对
损失函数的影响程度来达到提高预测精度
2、min_child_weight[默认1]
表示最小叶子节点样本权重的和。可用于避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。但是如果这个值过高,会导致欠拟合。这个参数需要使用CV来调整。
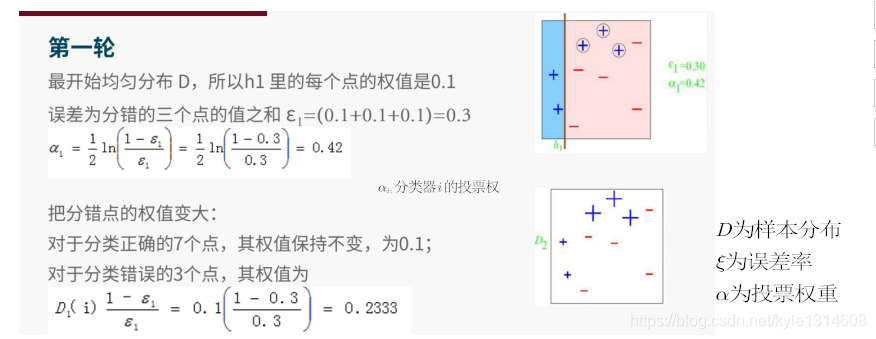
不管是投票权重还是样本权重更新 都是误差率越低 结果越大
样本权重的更新:越往后迭代 越难分对 所以分错样本的权重会
越来越大
维度:只针对特征的个数而言?而不是样本的个数
降维是机器学习中很重要的一种思想。在机器学习中经常会碰到一些高维的数据集,而在高维数据情形下会出现数据样本稀疏,距离计算等困难,这类问题是所有机器学习方法共同面临的严重问题,称之为“ 维度灾难 ”。另外在高维特征中容易出现特征之间的线性相关,这也就意味着有的特征是冗余存在的。基于这些问题,降维思想就出现了。
20200221
梯度下降的方向与等高线的切线方向垂直。
梯度是个向量 两个分量分别是两个坐标轴的切线方向
把起始位置设置为零点可以得到两个向量 两个向量的非原点的
两点相连就是梯度向量?
方向导数也是导数 就是斜率 在平面上 导数只有一个方向
但是在三维世界里 方向导数就有很多的方向 不同的方向的方向导数的值不一样 比如x,y,z 三个轴来看 在同一点 相对于x轴和y轴的导数值不同
也就是不同方向的方向导数的值
导数就是一个值 而不是向量
梯度的不同部分是相加的?
求导和投影是否是一回事,求导也是降维(降次)处理
如果不用多个epoch的话 直接让所有梯度等于零可以直接求出
对应参数最终的值 计算逆矩阵的时候 计算机资源不可用
因为有 学习率的存在所以需要多个epoch
为什么线性回归误差是正太分布假设
处理方便。
大多数误差经过测量被证实是服从高斯分布的。说明高斯分布对误差假设来说是一种很好的模型。
“中心极限定理” :是数理统计学和误差分析的理论基础。要注意的是在自然界与生产中,一些现象受到许多相互独立的随机因素的影响,如果每个因素所产生的影响都很微小时,总的影响可以看作是服从正态分布的。中心极限定理就是从数学上证明了这一现象 。
20200219
一阶导数为原始变量的变化率 单位时间 原始变量的差值为一阶导数 单位时间路程的变化差值
二阶导数为一阶导数的变化率 单位时间 一阶导数的差值为二阶导数 单位时间速度的变化差值
一阶导数大的说明离最优解还远
-
参数(parameters)/模型参数
由模型通过学习得到的变量,比如权重和偏置 -
超参数(hyperparameters)/算法参数
根据经验进行设定,影响到权重和偏置的大小,比如迭代次数、隐藏层的层数、每层神经元的个数、学习速率等
模型参数是模型内部的配置变量,可以用数据估计模型参数的值;
模型超参数是模型外部的配置,必须手动设置参数的值。
20200218
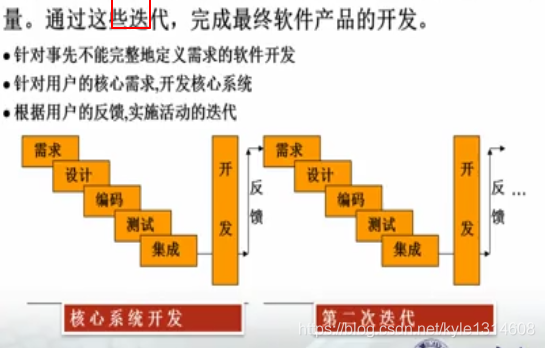
增量模型与演化模型的相同点是:基本思想都是非整体开发,以渐增方式开发系统。他们的目的基本相同:使用户尽早得到部分软件这样能听取用户反馈。不同点:增量模型再需求设计阶段是整体进行的,在编码测试阶段是渐增进行的。演化模型全部系统是增量开发,增量提交。
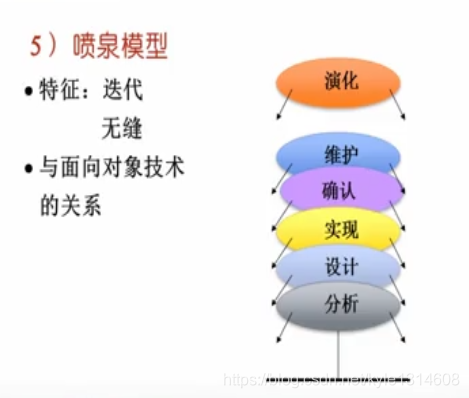
喷泉模型:是经过分析、设计、实现、确认、维护、演化等自下而上的迭代(形式就像喷泉)。这些软件活动之间没有明显的间隙,而且软件刻画活动需要多次重复。喷泉模型主要用于支持面向对象开发过程。
瀑布模型、演化模型、螺旋模型之间的联系:相同点是这三个模型都分为多个阶段,而瀑布模型一次完成软件,演化模型分为多次完成,每次迭代完成软件的一个部分,螺旋模型也分为多次完成,每次完成软件的一个新原型,并考虑风险分析。
螺旋模型将瀑布模型和演化模型结合起来,并且加入两种模型均忽略了的
风险分析
20200215
中心化:均值等于零


Slearn 同个类别 不同实现技术 接口都是一样的
当某个特征的标准差非常小 标准化 要除以标准差 如果标准差太小的话 结果不稳定 就不用标准化 用归一化
归一化能保留零条目 而标准化 零除完之后并不一定能保证还是零 标准差有可能是零?
归一化
空间:就是一个取值的集合
高阶相关:x一次幂以上

正态分布 大数定理 中心极限定理
线性回归 残差不符合正态分布 说明有极端值的影响
影响模型的效果 需要去掉极端值 改进模型效果
共线性的解决:用模型解决 岭回归 lasso回归(不确定那些特征是不可用的时候)
或者删除 或者 PCA 降维 逐步回归
交叉验证和模型容易用于评估模型的泛化性
出现模就表示是对向量的操作

梯度下降:决定最后对象的走向的是多个样本的合梯度方向
每个参数都需要所有样本的梯度合并
简单实现过程 参考新加坡龙的简单神经网络实现
最小二乘法
对数似然 可以写出解析解
可能矩阵非常大 对矩阵做SVD分解都很困难

梯度下降 样本数多 适用于 非解析解 没有解析式
一个yi 对应一个ε
根据均值和方差的运算法则而来 带入反而不好理解

损失函数:衡量的是单个观测值在当前系统下的一个损失情况。
代价函数:衡量所有样本在当前系统下的损失情况。
线性回归中
似然函数就是联合概率密度函数
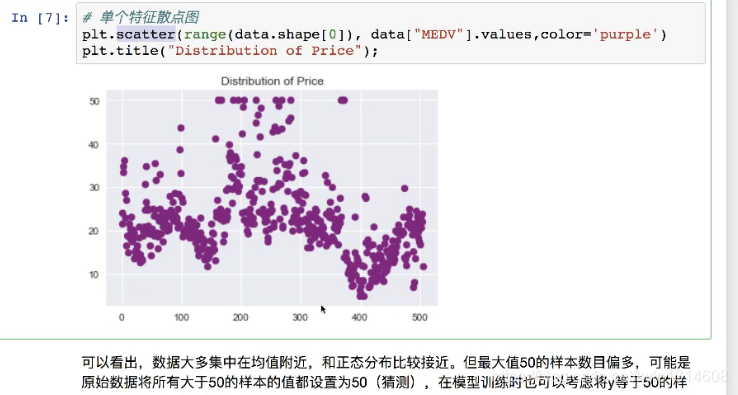
散点图 横轴为样本索引 纵轴为值
直方图 横轴为值 纵轴为概率
离群点处理 超过50 都算作50
概率密度函数就是概率
横轴为取值 纵轴为概率
核函数
把原来的x经过某种变换之后 作为核函数的x
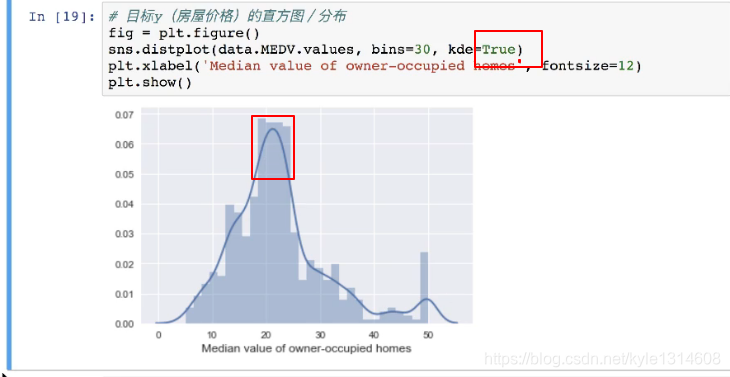


20200214
logistic损失
https://blog.csdn.net/kyle1314608/article/details/104312243
正则项:模型越复杂 惩罚越大 相当于任务加入噪音
不让模型模型的太好 模型越简单 正则项越小
最终求的模型是这个两个的平衡

20200213
半监督学习
当我们拥有标记的数据很少,但是未被标记的数据很多,但是人工标注又比较昂贵的时候。我们可以根据一些条件(查询算法)查询(query)一些数据,让专家进行标记。这是半监督学习与其他算法的本质的区别。所以说对主动学习的研究主要是设计一种框架模型,运用新的查询算法查询需要专家来认为标注的数据。最后用查询到的样本训练分类模型来提高模型的精确度.
在实验设计中,协变量是独立变量,实验者不能操纵,但仍影响实验结果。
举个例子,研究教学方法对学生成绩的影响,那么学生本身的成绩水平(入学成绩)就是协变量,研究时需要剔除或控制住协变量的作用,否则结果不一定可靠。
强化学习的定义。
假定一个智能体(agent),在一个未知的环境中(当前状态state),采取了一个行动(action),然后收获了一个回报(return),并进入了下一个状态。最终目的是求解一个策略让 agent的回报最大化。
所谓模式识别的问题就是用计算的方法根据样本的特征将样本划分到一定的类别中去。
物体识别实际上是通过模式识别来是实现的。举个简单的例子,要想识别刚生下来的婴儿是男孩还是女孩,生物书本上有记载,很简单,可以通过生殖器的不同来判别。这是两者的本质区别。但是长大后要想判断是男生还是女生,肯定不能直接扒光人家衣服来判断,这时候就会借助衣着,打扮,头发等特征来判断。这就说明了,有时候要区分两个东西,并不是靠最本质的区别来判定的,毕竟不方便或者很麻烦。这时候就得借助一些所谓的特征来判定。所以实际上,模式识别并不是根据物体本身来判断的,而是根据被感知到的某些性质,也就是物体特征来判别的。所以,也就引出了模式的定义—这些如物体的纹理、硬度、比重等的被感知到的物体特性,叫做模式。所以为了识别物体,也就是进行分类,一般会用分类器这个工具。故而分类器实际上识别的不是物体,而是物体的模式。而且物体识别精准与否与分类器有直接关联,就如上述这个例子,毕竟可以区分男女的特征有好多,但除了生殖器类似的本质特征外,其他的都是一般性适用的,并不是都会成立。就如中性人的存在一样,基本很难辨识是男还是女。所以设计一个好的分类器是物体识别的关键所在,而选择物体的什么特征来描述物体,则是直接相关的。
也就是说,模式识别和机器学习的区别在于:前者喂给机器的是各种特征描述,从而让机器对未知的事物进行判断;后者喂给机器的是某一事物的海量样本,让机器通过样本来自己发现特征,最后去判断某些未知的事物。
相当于和深度学习的区别
统计的作用
变异: 度量 分析 解释
相关性
统计学中的几种统计思想编辑
1.统计思想的形成折叠
统计思想不是天然形成的,需要经历统计观念、统计意识、统计理念等阶段。统计思想是根据人类社会需求的变化而开展各种统计实践、统计理论研究与概括,才能逐步形成系统的统计思想。
2.比较常用的几种统计思想折叠
所谓统计思想,就是统计实际工作、统计学理论及应用研究中必须遵循的基本理念和指导思想。统计思想主要包括:均值思想、变异思想、估计思想、相关思想、拟合思想、检验思想。现分述如下:
2.2.1均值思想折叠
均值是对所要研究对象的简明而重要的代表。均值概念几乎涉及所有统计学理论,是统计学的基本思想。均值思想也要求从总体上看问题,但要求观察其一般发展趋势,避免个别偶然现象的干扰,故也体现了总体观。
2.2.2变异思想折叠
统计研究同类现象的总体特征,它的前提则是总体各单位的特征存在着差异。统计方法就是要认识事物数量方面的差异。统计学反映变异情况较基本的概念是方差,是表示“变异”的“一般水平”的概念。平均与变异都是对同类事物特征的抽象和宏观度量。
2.2.3估计思想折叠
估计以样本推测总体,是对同类事物的由此及彼式的认识方法。使用估计方法有一个预设:样本与总体具有相同的性质。样本才能代表总体。但样本的代表性受偶然因素影响,在估计理论对置信程度的测量就是保持逻辑严谨的必要步骤。
2.2.4相关思想折叠
事物是普遍联系的,在变化中,经常出现一些事物相随共变或相随共现的情况,总体又是由许多个别事务所组成,这些个别事物是相互关联的,而我们所研究的事物总体又是在同质性的基础上形成。因而,总体中的个体之间、这一总体与另一总体之间总是相互关联的。
2.2.5拟合思想折叠
拟合是对不同类型事物之间关系之表象的抽象。任何一个单一的关系必须依赖其他关系而存在,所有实际事物的关系都表现得非常复杂,这种方法就是对规律或趋势的拟合。拟合的成果是模型,反映一般趋势。趋势表达的是“事物和关系的变化过程在数量上所体现的模式和基于此而预示的可能性”。
2.2.6检验思想折叠
统计方法总是归纳性的,其结论永远带有一定的或然性,基于局部特征和规律所推广出来的判断不可能完全可信,检验过程就是利用样本的实际资料来检验事先对总体某些数量特征的假设是否可信。
3对统计思想的一些思考折叠
20200211
1.二者定义不同: 目的比较抽象,是某种行为活动的普遍性的、统一性的、终极性的宗旨或方针。 目标则比较具体,是某种行为活动的特殊性的、个别化的、阶段性的追求或目标。
1.政策
政策强调的是有政治色彩的属于统治阶级的意志体现。要求对象执行的既可以是单个方案,也可以是单个问题对应的具体措施。
2、策略
计策或谋略,强调的是思维上的解决办法
3、措施
措施则是针对某种情况而采取的处理办法,强调的是具体实操性。
二、实施顺序不同
策略是根据形势发展而制定的行动方针和方法,比措施有前置地位;确定好策略之后方可实行具体措施。包含了措施的谋划和预定但不限于措施。而政策则是在措施成功解决问题之后而固化下来的模式或者方针政策。
20200210 形式参数 函数定义时候出现在函数中
实际参数 主调函数中调用一个函数时,函数名后面括号中的参数称为实际参数(简称实参),即实参出现在主调函数中
20200207 语境
结构化:即层次或延伸而不是一个孤立的点
挂起:保持状态不变
20200206 形式化是指分析、研究思维形式结构的方法。
构件是系统中实际存在的可更换部分,它实现特定的功能,符合一套接口标准并实现一组接口
状态机简写为FSM(Finite State Machine),主要分为2大类:第一类,若输出只和状态有关而与输入无关,则称为Moore状态机;第二类,输出不仅和状态有关而且和输入有关系,则称为Mealy状态机
20200205 原则:说话、行事所依据的准则
方法:战略层面
技术:战术层面
概念(Idea;Notion;Concept)是反映对象的本质属性的思维形式


原理:自然科学和社会科学中具有普遍意义的基本规律
特性:某事物所特有的性质
20200204 事务,一般是指要做的或所做的事情
例程的作用类似于函数,但含义更为丰富一些。例程是某个系统对外提供的功能接口或服务的集合
20200202 机制,指有机体的构造、功能及其相互关系
思维(人用头脑进行逻辑推导的属性、能力和过程)
导引和控制飞行器按一定规律飞向目标或预定轨道的技术和方法
数学、逻辑和计算机科学中,形式语言(英语:Formal language)是用精确的数学或机器可处理的公式定义的语言
解释型语言,是在运行的时候将程序翻译成机器语言。解释型语言的程序不需要在运行前编译,在运行程序的时候才翻译,专门的解释器负责在每个语句执行的时候解释程序代码
模式匹配是指将两个模式作为输入,计算模式元素之间语义上的对应关系的过程
模式(汉语词语)
某种事物的标准形式或使人可以照着做的标准样式
代数是研究数、数量、关系、结构与代数方程(组)的通用解法及其性质的数学分支
形式化是指分析、研究思维形式结构的方法
20200201 模式匹配:就是对变量的进行判断,针对不同的条件进行不同的处理
20200130 信念是一种心理动能,其行为上的作用在于通过士气激发人们潜在的精力、体力、智力和其它各种能力,以实现与基本需求和欲望和信仰相应的行为志向。
离散数学中├ 断定符 以及 ╞ 满足符
第一个┠ 是推理符号,推理的不一定正确,第二个是说这个推理正确
20200129 渐增的
模型是层次性的
在计算机科学中,是指“提供用户使用界面”的软件,通常指的是命令行界面的解析器。
Unix环境下在操作系统之上提供的一套命令解释程序叫做外壳程序(shell).
外壳程序是操作员与操作系统交互的界面,操作系统再负责完成与机器硬件的交互。
所以操作系统可成为机器硬件的外壳,shell命令解析程序可称为操作系统的外壳。


20200128 抽象和具体 集合的大小程度不同
抽象和泛化(理解为平均?) 相近
情境:当前周围的状态
偏置:偏差
由具体的、个别的扩大为一般的,比如“先生”也用于称呼女性,战场也用于称呼考场、赛场,就是词义泛化。
惰性学习和积极学习
常量,
变量


事务
重载 相同的操作名在同一个类中可以被定义多次
参数种类不同
多态是不同类中操作名相同

语义可以简单地看作是数据所对应的现实世界中的事物所代表的概念的含义,以及这些含义之间的关系,是数据在某个领域上的解释和逻辑表示。
语法是语言学的一个分支,研究按确定用法来运用的"词类"、"词"的屈折变化或表示相互关系的其他手段以及词在句中的功能和关系
句法是研究句子的个个组成部分和它们的排列顺序。 句法研究的对象是句子。
Soft Attention是所有的数据都会注意,都会计算出相应的注意力权值,不会设置筛选条件。Hard Attention会在生成注意力权重后筛选掉一部分不符合条件的注意力,让它的注意力权值为0,即可以理解为不再注意这些不符合条件的部分。
软件工程 事件
在这里插入图片描述
大幅度提升深度学习模型
一个CPU可以有多个内核,内核就是真正的物理核心,而往往处理器会使用超线程技术,其将每个内核又可以分为两个线程,而线程技术就是在单个内核基础上提供两个逻辑处理器,利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,所以两个物理核心就是四个线程,也就形成了四个逻辑处理器。现在一般说多少核一般都是指有多少逻辑处理器。
CPU的外频,通常为系统总线的工作频率(系统时钟频率),CPU与周边设备传输数据的频率,具体是指CPU到芯片组之间的总线速度。外频是CPU与主板之间同步运行的速度,在早期的绝大部分电脑系统中外频,也是内存与主板之间的同步运行的速度,在这种方式下,可以理解为CPU的外频直接与内存相连通,实现两者间的同步运行状态。
主频也是基准速度
CPU的主频就是CPU 的工作频率,也就是它的速度,单位是MHz。
CPU的外频是其外部时钟频率,由电脑主板提供,单位也是MHz。
CPU的倍频是主频为外频的倍数,故也叫倍频系数,它是没有单位的。
CPU的主频=外频×倍频,
Sefttest 自检
Active 活化
guard 监护

构件或是一个进程或者是个线程
交互三要素:交互各方 交互方式 交互内容
多态性:父类字母操作名字一样 但是实现逻辑不一样
编程里面的抽象类,抽象操作是指没有具体的实现,只有定义
数据的含义就是语义(semantic)。简单的说,数据就是符号。数据本身没有任何意义,只有被赋予含义的数据才能够被使用,这时候数据就转化为了信息,而数据的含义就是语义
提案:提交会议讨论决定的建议
机制,指有机体的构造、功能及其相互关系;机器的构造和工作原理。
完备:覆盖了所有情况
可靠性 :无故障使用的时间
@property
把方法变成属性调用
模块化
抽象



耦合
概括的说耦合就是指两个或两个以上的实体相互依赖于对方的一个量度
内聚
扇入 扇出
内聚(Cohesion)是一个模块内部各成分之间相关联程度的度量。



LSTM
BiLSTM
BILSTM是双向LSTM;将前向的LSTM与后向的LSTM结合成LSTM。视图举例如下:
双向LSTM
条件随机场 个人总结
命名实体识别现状及建议_20200603.doc 参看这个文件
1.分成两部分 一部分是为前面的标注 对现在标注的影响 转移 同一个系统 前对后 转移矩阵是固定的?
第二部分是当前词本身对 标注的影响 发射 不同系统 当前对当前
整体 一句话所有的发射和转移都加起来 只有一种对象标注是正确的 要使得其得分最高
有很多种对象标注方式 放在分母 最终形成概率
膨胀神经网络 就是构建好几个特征图 然后对几个特征图的结果进行综合 视野更大 更能解决长依赖的问题
https://www.zhihu.com/question/20136144
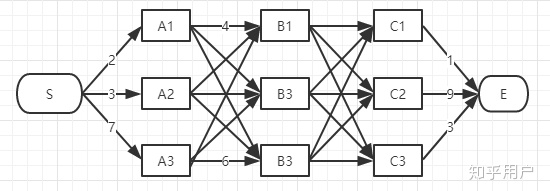
viterbi维特比算法解决的是篱笆型(只适合这种图解法)的图的最短路径问题,图的节点按列组织,每列的节点数量可以不一样,每一列的节点只能和相邻列的节点相连,不能跨列相连,节点之间有着不同的距离
维特比算法:每一步保留从头到这一步中每个节点最优的路径,以此类推可以得到最短路径
每一层不是保留一条路径,而是到这层的每个节点都保留一条最优路径
维特比是考虑了所有的情况,只不过考察之后删掉了一些情况
https://www.zhihu.com/question/20136144
A*算法
我每一步只走最好走的路。
二者的区别 维特比从第二层开始,每个结点都保留一条最优路径
而A星算法每一步只保留最优路径 可能得不到最优的解
集束搜索
我每一步只走最好走的前N条路。(其他剪掉)这里的N也叫Beam Width。
Beam Search与Viterbi算法Beam Search与Viterbi算法虽然都是解空间的剪枝算法,但它们的思路是不同的。Beam Search是对状态迁移的路径进行剪枝,而Viterbi算法是合并不同路径到达同一状态的概率值,用最大值作为对该状态的充分估计值,从而在后续计算中,忽略历史信息(这种以偏概全也就是所谓的Markov性),以达到剪枝的目的。从状态转移图的角度来说,Beam Search是空间剪枝,而Viterbi算法是时间剪枝。
https://blog.csdn.net/tommorrow12/article/details/80896331
词嵌入 代码还没仔细看 牵扯到padding
将LSTM的输出映射到标记空间 4 5
表示用标记空间的坐标系来表示了 属于标记空间的元素了
自然语言处理里面的pad
Numpy 的 ndarray 的打印 和 excel的对应
非归一化概率
函数参数的表示方式 就是列举并列关系
tup2 = (1, 2, 3, 4, 5 )
Python 元组 里面不只是两个元素
沉重数据 后端总线
Cpu 矢量化计算的能力
Tensor shape 1x2 的排列方式
真实排列应该是
1
1
2x1的排列方式
1 1
Tensor 的 维度 打印出来和直觉是相反的
维度是 size/shape的长度
Tensor 是里面具体元素的值
Size/shape 是指tensor 具体的形状
张量数据类型2
坐标系:直接数列表里面的元素个数
每个维度的大小:具体的数值
Tensor 里面的切片和pandas 差不多
A【1:12,2:20】
-1 其实是最后一个 要么是除了第一个维度之外剩下的所有维度
关键词 加 通俗 或者 原理 或者 白话 经典理解 推导 为例 举例 讲解 简单易懂 案例 解读
算法 代码
源码剖析 分析 理解 讲解 注释 重写 参数 详解(重点)
pytorch BiLSTM+CRF代码详解
注意力机制
高纬点积
矢量和张量
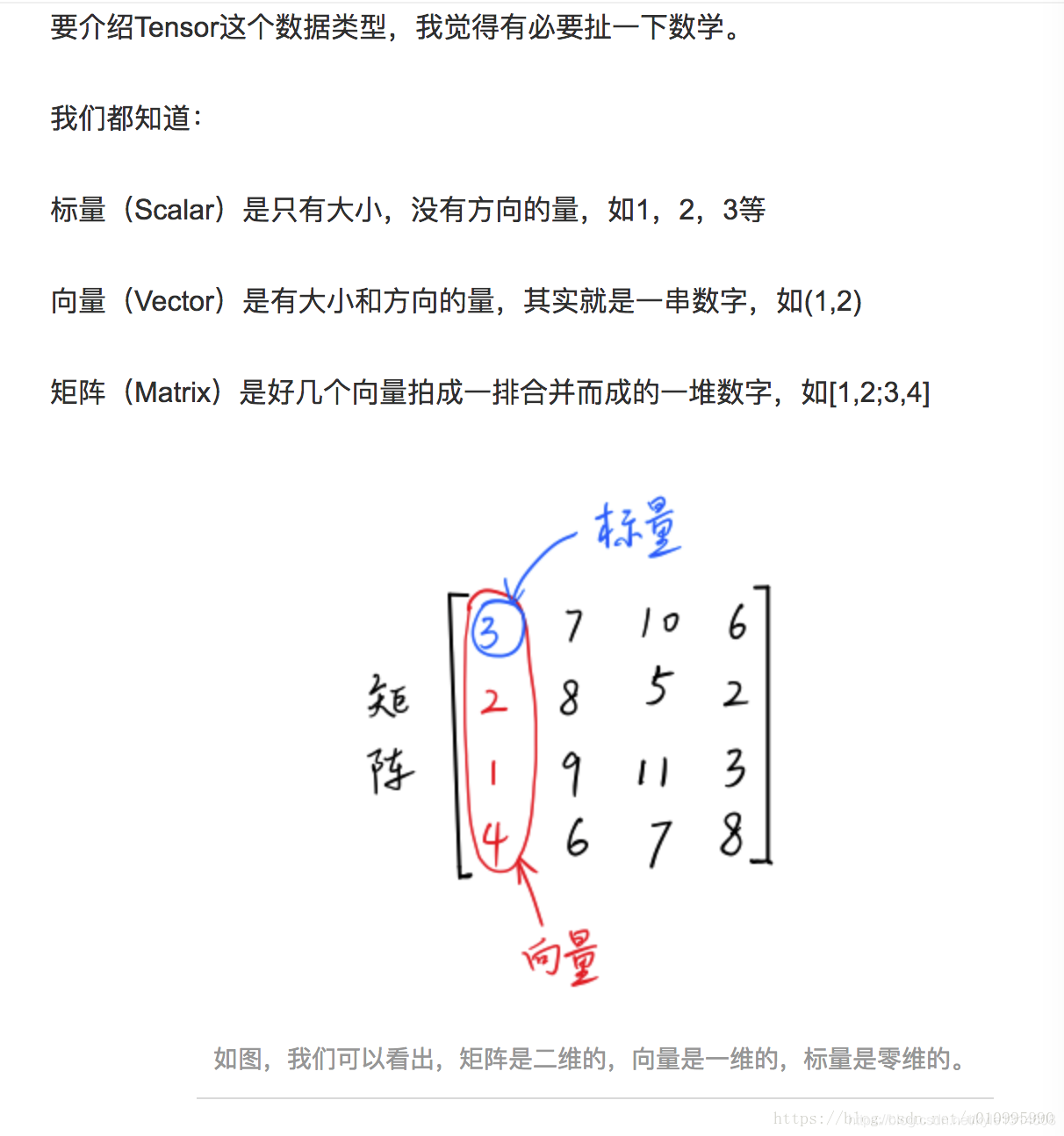
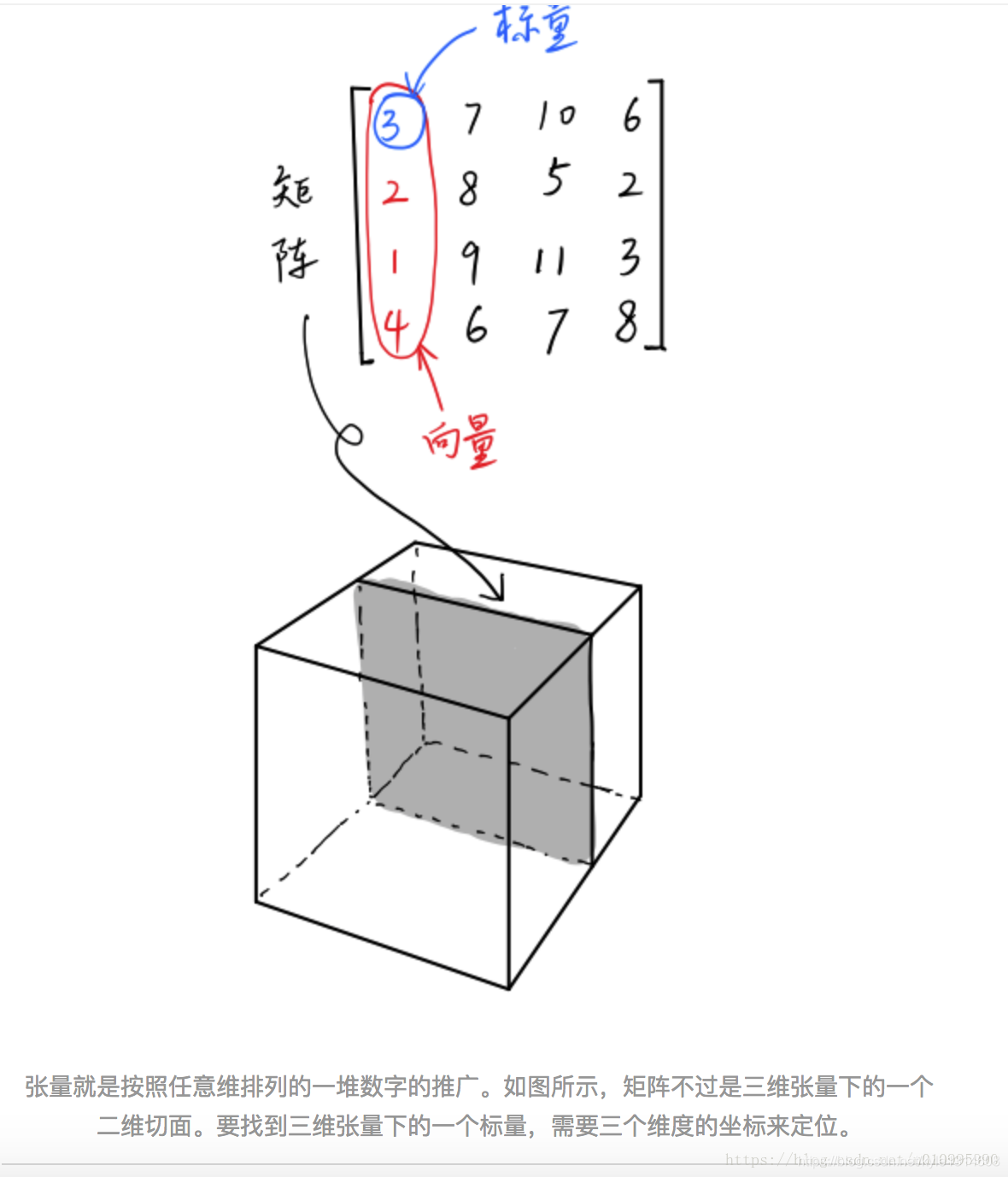
标量是0阶张量(一个数),是11的;
向量是一阶张量,是1n的;
张量可以给出所有坐标间的关系,是nn的。
所以通常有人说将张量(nn)reshape成向量(1*n),其实reshape过程中并没有发生大的变化。
除此之外,张量还可以是四维的、五维的。

前向传播网络:没有梯度向后传导的过程
人脑和算法
对于人脑很简单的动作 对于算法(电脑)来说就很难 那么即是是很不起眼的一点点创新改变 都可以 都可以尝试加入到算法里面 结果可能会大不一样
表示 值向量
Transformer
对多头注意机制的理解:因为可能被这个单词本身所支配 就选取8个 另外7个 会 关注到其他与这个单词最相关的7个单词 为什么选8 估计是 在一段文章里面 与这个
单词最相关的单词 不会超过七个把 应该是概率统计而来
这种位置编码 可以保证任意长的序列 其每个字的编码都是不一样的? 任意长的序列 都能达到一个 softmax 的效果?
对数几率
对数几率函数是sigmoid函数。
集束搜索
不只是解释 同时也是赋值
生成器比一般的容器更厉害 可以装入任何对象
普通容器只能装规定的类型对象
迭代器是对普通容器的包装?
Rpc 远程过程调用
自己设置的 命令行
参数输入格式
使用第二块GPU(从0开始)
一个 Epoch 所有的数据
Step 一个epoch数据 除以batch size 的数目
优化器参数调节
1.L2-正则化防止过拟合
weight decay(权值衰减),其最终目的是防止过拟合。在机器学习或者模式识别中,会出现overfitting,而当网络逐渐overfitting时网络权值逐渐变大,因此,为了避免出现overfitting,会给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。其用来惩罚大的权值。在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weight decay的作用是调节模型复杂度对损失函数的影响,若weight decay很大,则复杂的模型损失函数的值也就大。
这个在定义优化器的时候可以通过参数 【weight_decay,一般建议0.0005】来设置:
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99), eps=1e-06, weight_decay=0.0005)
LR 也可以指 学习率
各种框架下通用技术的学习 比如 优化器参数的设置
在 windows python 中 / 和 \ 等效
指数衰减学习率
https://blog.csdn.net/lyl771857509/article/details/79734107
余弦退火
https://zhuanlan.zhihu.com/p/41379279
- 带重启的SGD算法
在训练时,梯度下降算法可能陷入局部最小值,而不是全局最小值。
△ 陷入局部最小值的梯度下降算法
梯度下降算法可以通过突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径。这种方式称为带重启的随机梯度下降方法(stochastic gradient descent with restarts, SGDR),这个方法在Loshchilov和Hutter的ICLR论文中展示出了很好的效果。
递归,分治
递归:大范围到小范围的同样操作
从最小范围计算出结果再往回一步一步推出最终结果


差分学习率
自动调参的Adam方法已经非常给力了,不过这主要流行于工程界,在大多数科学实验室中,模型调参依然使用了传统的SGD方法,在SGD基础上增加各类学习率的主动控制,以达到对复杂模型的精细调参,以达到刷出最高的分数。
深度学习调参方法
正则化:使loss 比最小值更大一些 同时又要整体loss 最小 平方之后 重要度高的权重保留值大一些 重要度低的权重可能为零 消失了
简化了模型 同时 保证了模型的效果
http://www.spytensor.com/index.php/archives/32/
优化器调参设置 重点
Adam优化器调参总结
1.就是是学习率的调整
2.最好使用 SGD 加 学习率的调整
Adagrad
SGD、SGD-M 和 NAG 均是以相同的学习率去更新的各个分量。而深度学习模型中往往涉及大量的参数,不同参数的更新频率往往有所区别。对于更新不频繁的参数(典型例子:更新 word embedding 中的低频词),我们希望单次步长更大,多学习一些知识;对于更新频繁的参数,我们则希望步长较小,使得学习到的参数更稳定,不至于被单个样本影响太多。
深度学习 稳定的部分意义
RMSprop
圆里面一点符号的意义
向量的二次幂?
指数移动平均 把Vt-1 不停的带入 就会得出指数的含义
这里的一阶动量和二阶动量 可以简单的理解为 梯度第一次幂和二次幂
1.列表是动态数组,它们可变且可以重设长度(改变其内部元素的个数)。
2.元组是静态数组,它们不可变,且其内部数据一旦创建便无法改变。
动态就是可变
静态就是不可变
散列函数就是 hash函数
能得到这一效率是因为我们非 常聪明地使用散列函数将一个任意的键(如一个字符串或一个对象)转变成了一个 列表的索引。
掩码是为了保证一个可能是任意数字的散列值最终能落入分配
的桶中。
为了找到新的索引,我们用一个简单的线性函数计算出一个新的索引,这一方法 称为嗅探
数据分布的均匀程度被称为“负载因 素”,它跟散列函数的熵有关
① 掩码是一个二进制数,用来截断另一个数字。比如,0b1111101 & 0b111 = 0b101 = 5 意味着掩码
0b111 截断了数字 0b1111101。这一操作也可以被看作是获取一个数字的最低几位。
熵的作用
衡量“我的散列函数分布均匀程度”的标准被称为散列函数的熵。熵的定义是:
S = −∑ p(i) ⋅ log( p(i))
p(i)是散列函数给出散列值为 i 的概率。当所有的散列值都具有同样的被选中概 率时熵最大。一个令熵最大的散列函数被称为完美散列函数,因为它保证了最低的 碰撞次数。
当一个程序进入 I/O 等待时,暂停执行,这样内核就能执行 I/O 请求相关的低级操 作(这叫作一次上下文切换),直到 I/O 操作完成时才继续
对于低耦合,粗浅的理解是:一个完整的系统,模块与模块之间,尽可能的使其独立存在。也就是说,让每个模块,尽可能的独立完成某个特定的子功能。模块与模块之间的接口,尽量的少而简单。
高内聚,低耦合的系统有什么好处呢?事实上,短期来看,并没有很明显的好处,甚至短期内会影响系统的开发进度,因为高内聚,低耦合的系统对开发设计人员提出了更高的要求。长期来看,低耦合的模块便于进行单元测试,且便于维护。
独立的耦合 紧密地高内聚
这些操作是非阻塞 的,意味着如果我们用一个异步程序做一次网络写操作,它会立即返回,尽管 写操作还没有发生。当写操作完成时,会触发一个事件,所以我们的程序就得 以知晓了。
协程
https://www.liaoxuefeng.com/wiki/897692888725344/923057403198272
迭代器 send的理解,send的值会优先于yield 本身的值传出, send的值相当于一个插入的作用
如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:
(通过send实现)
def something():
result = []
for … in …:
result.append(x)
return result
都可以用生成器函数来替换:
def iter_something():
for … in …:
yield x
利用生成器 把数据一点点的加载到内存
同步立即 阻塞挂起
红黑树
Try except 的作用 是的程序不会中断 会一直执行 直到成功为止
Python高级编程异步io
在函数内部 引用全局变量
同步:按顺序执行?
下一个timestep
BN的主要思想就是:在每一层的每一批数据上进行归一化。
同步 不停止
异步 停止 再重启
遇到耗费IO 让cpu 等待的操作 用yield 来构建 把其弄出去
不能用 time.sleep
注册:把B注册到A的队列里面去
Tensorflow 老版本 基本无法调试
鸭子类型:主要是魔法函数的使用
静态方法:类初始化必须的步骤,类直接调用 而不是实例调用
用于进入类前必须处理的工作放到类里面(进入到类的命名空间 作用域?)
硬编码 相当于写死
类对象 相比静态对象 解决了硬编码问题
类名可以随便改了
静态方法的用处 不需要return一个对象 的时候
协议: 就是规则?
层 类别于魔法函数 是的传输具有这些所有的功能 应付处理每种情况
阻塞 挂起 不是关闭
\r 回车键
属于http协议的一部分
协议就是 规则 格式规定
编码解码 就是utf8 和 gbk 与byte 类型的转换
守护线程 主线程关闭 子线程也就关闭
没有必要等待完成 才返回 异步
接口:就是某个对象的调用
接口一致,切换平滑:差不多 类似 相同
逻辑实体
隐藏状态也是一个向量
迭代 在原来基础上再进行同样的操作 一般指结果越来越好
递归 也是在原来基础上再进行同样的操作 但是结果不是以越来越好为标准 而是正常
16 进制
1111 0000
0和任何值合取都是零
1 合取 不改变对应位置的值
右移 4位
抽象:是指很多东西的共性 而不是一个具体的东西
关系性质的保守性
保守性:运算之后是否还保持原来的关系
闭包
预训练模型和具体的任务无关
具体任务 增加新的实体对象是可以的
即使是完全不一样的对象也可以
必要和充分的关系
充分必要条件 箭头为必要 等价关系
堆内存的特点:不去释放他 就会一直存在内存
Embedding 嵌入
每个单词都被嵌入为512维的向量
就是转换的意思
命名实体识别
20字(行)的位置编码实例,词嵌入大小为512(列)。你可以看到它从中间分裂成两半。这是因为左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成。然后将它们拼在一起而得到每一个位置编码向量。
位置编码
残差:短接 避免自注意力的过拟合?
命名空间:变量只在这个范围内有效
开放性 不挑硬件
域的概念
面向字节流:处理对象为字节流 不管其他格式的规格
因为这个模型一次只产生一个输出,不妨假设这个模型只选择概率最高的单词,并把剩下的词抛弃。这是其中一种方法(叫贪心解码)。另一个完成这个任务的方法是留住概率最靠高的两个单词(例如I和a),那么在下一步里,跑模型两次:其中一次假设第一个位置输出是单词“I”,而另一次假设第一个位置输出是单词“me”,并且无论哪个版本产生更少的误差,都保留概率最高的两个翻译结果。然后我们为第二和第三个位置重复这一步骤。这个方法被称作集束搜索(beam search)。在我们的例子中,集束宽度是2(因为保留了2个集束的结果,如第一和第二个位置),并且最终也返回两个集束的结果(top_beams也是2)。这些都是可以提前设定的参数。
线性方程 没有含未知数的两项相乘 没有平方项 系数为常数
回调 当阻塞的时候 会卡在这里 程序不会一直阻塞在这里 其他请求会执行 当fetch 结果拿到之后 就会继续执行往下的代码
通过callback 来实现
ROC 的理解
更高一层的抽象类
把多种抽象成一种 归一化
消息处理模式 是推模式还是拉模式
是拉模式:指消费者 主动连接到主题上去 有消息过来 自己拉出来
如果本身处理能力不够 资源有限 会降低自己处理消息的能力 就需要加入更多的消费者来处理
直连就是推模式 增加消费者负担
左斜线 对应 斜杠
Broker 是个后台服务
发布订阅系统
Zookeeper 也是服务
Producer 和 cosumer 是SDK 可以集成到任何的外部工程当中 软件开发工具包 整体可以看成一个类 也插件
Push 模式 强塞
和pull 模式 自己决定
Partition 图
Segment 段 透明 用户感知不到
Hash的理解 就是 输入数据相同保证hash出来的值也是相同的 那根直接用元数据有什么区别 ?
看node2 是否存在node1 刚创建的结点 如果可以 就说明成功了
Zookeeper 在每台机子上就是一个服务进程 通过加端口号去访问
如何访问服务
操作原子性
持久化就是被写入磁盘
公平锁:释放之后 第二个进程拿到锁
非公平锁 :随机某个进程再次拿到锁
羊群效应 各自为政 很多同时操作 负担重
输出重定向
输出到指定目录
语法
语义
远程登录
归谬证明
非构造性证明
算术是数学中最古老、最基础和最初等的部分,它研究数的性质及其运算。把数和数的性质、数和数之间的四则运算在应用过程中的经验累积起来,并加以整理,就形成了最古老的一门数学——算术。
就是自然数和四则运算?
算术表达式和算术运算不引入所谓“代表数字的字母”;
代数表达式和代数运算引入了所谓“代表数字的字母”。
循环论证
用自己证明自己
数学归纳法
谓词逻辑和推理规则
推理规则 结论是结果
谓词逻辑 真值是结果
被谁整除 就是谁作为除数
质数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。
素数
质数
强形式归纳法 就多了一个 n0+1?
规则cp:就是把要证明的结论作为前提?
Cp 规则证明充要性的时候 前提和结论 分别加入 原来的前提 分两次来证明
证明技术
基本证明方法:1. 直接证明 2. 间接证明(逆否)
典型的证明技术:1. 空证明(蕴含式前件p为假,蕴含为真) 2.平凡证明(蕴含式后件为真,蕴含式为真)12 对立
3.归谬证明(蕴含式后件为假,只有前件为假,蕴含式为真 假设 为真 推出矛盾)
4.分情形证证明(多种情况并起来推出q,分开证明)
5.等价证明,
带量词的的证明技术:1.构造性存在性证明(任意找个特例,利用归谬)2.非构造性的存在性证明 不找特例,证明存在必然性
3.唯一性证明 3.1 存在性 3.2 唯一性
数学归纳法: 适用于递推式
按定义证明方法: 适用于蕴含式
循环论证
环上任意两个节点都是相互可达的 可以说明任何两个定义都是两两等价的
循环证明的适用条件: 多种等价的形式存在的时候
Abcd 为仓库 权值就是库存能力
神经网络: 权值 某种变量(位置等)的影响程度
神经网络和图
分子式(molecular formula)是用元素符号表示纯净物(单质、化合物)分子的组成及相对分子质量的化学组成式
同分异构体
组成元素及其对应的量词相同 但是 结构不同
图的结构决定图的本质特征
结构相同的图有类似的性质
必要条件:就是说 这些条件满足了 不一定能推出结论 但是如果不满足这些条件 那么一定不能推出结论
充分条件:满足这些条件一定能推出结论
矩阵乘法 本质就是一种遍历
必要条件 其逆否命题的实用性很大
所谓规范化,是希望转换后的数值满足一定的特性,至于对数值具体如何变换,跟规范化目标有关,也就是说f()函数的具体形式,不同的规范化目标导致具体方法中函数所采用的形式不同
隐藏层:除开输入层和输出层 中间层都叫隐藏层
其实采样层(pooling)非常好理解,我们这里特指maxpooling
什么是maxpooling 呢
所谓数据Re-Scaling(尺度变换),指的是把输入X乘上一个缩放因子
在熵的理解那部分提到了,熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大
使用某个特征A划分数据集D,计算划分后的数据子集的熵 entroy(后)
信息增益 = entroy(前) - entroy(后)
信息增益的理解:
对于待划分的数据集D,其 entroy(前)是一定的,但是划分之后的熵 entroy(后)是不定的,entroy(后)越小说明使用此特征划分得到的子集的不确定性越小(也就是纯度越高),因此 entroy(前) - entroy(后)差异越大,说明使用当前特征划分数据集D的话,其纯度上升的更快。而我们在构建最优的决策树的时候总希望能更快速到达纯度更高的集合,这一点可以参考优化算法中的梯度下降算法,每一步沿着负梯度方法最小化损失函数的原因就是负梯度方向是函数值减小最快的方向。同理:在决策树构建的过程中我们总是希望集合往最快到达纯度更高的子集合方向发展,因此我们总是选择使得信息增益最大的特征来划分当前数据集D。
非规范概率 就不是真正的概率 是跟真正的概率正相关
超参数 为子式子外部的参数 是描述整个子式子的 而参数是属于子式子内部的 内层和外层的区别
线性层的作用 维度空间的转换
似然函数的理解:当前以及发生的情况下,所有取值下发生的概率作为最大
并求使其满足的参数值
对数似然:就是加个log,转换成加的运算 方便计算
logit 函数
https://www.jianshu.com/p/31c7fe00d9de

隐藏层的作用:之前所有有效的作用的汇总
differentiate 区分
转义字符 就是说 转义字符后面的字符取其最原始的意思 而不作为特殊字符对待 和在特殊字符串前面加r的功能类似
At each step the model is auto-regressive [10], consuming the previously generated symbols as additional input when generating the next

自回归
偏心协方差矩阵(即没有减去均值的协方差矩阵)
本地过程调用,就好比你现在在家里,你要想洗碗,那你直接把碗放进洗碗机,打开洗碗机开关就可以洗了。这就叫本地过程调用。”
“远程嘛,那就是你现在不在家,跟姐妹们浪去了,突然发现碗还没洗,打了个电话过来,叫我去洗碗,这就是远程过程调用啦”,多么通俗易懂的解释,我真是天才!
因为在同一个地址空间,或者说在同一块内存,所以通过方法栈和参数栈就可以实现。
损失函数是对训练误差的惩罚 最小化损失函数 问题
误差越大 惩罚越大
冷启动:指app被后台杀死后,在这个状态打开app,这种启动方式叫做冷启动。
热启动:指app没有被后台杀死,仍然在后台运行,通常我们再次去打开这个app,这种启动方式叫热启动。
解释器 编译器 就是把人的语言翻译成机器语言
搜索算法 A算法 代价 启发函数

字长、字节、字、字位的区别:
(1)概念不一样
同一时间处理二进制数位数叫字长,字长是直接用二进制代码指令表达的计算机语言。
字节(Byte )是计算机信息技术用于计量存储容量的一种计量单位,通常情况下一字节等于八位,也在一些计算机编程语言中表示数据类型和语言字符。
在计算机领域, 对于某种特定的计算机设计而言,字是用于表示其自然的数据单位的术语。在这个特定计算机中,字是其用来一次性处理事务的一个固定长度的位(bit)组。
字位,计算机存储信息的最小单位,称之为字位(bit,又称比特)。
(2)储存单位大小不同
字位 :最小的存储单位(可以容纳0和1其中之一)
字节 :常用的计算机存储单位。1字节 = 8 位(这是字节的标准定义)
字 :即机器字长,是自然的存储单位。计算机是多少位的,一个字就又多少位。(如64位的机器,一个机器字长就是64位)
方针,是指引导事业前进的方向和目标。有方向,有针对性的指导的发展。
全连接网络:两层网络的每个结点相互直接都有连接
a⊕b = (¬a ∧ b) ∨ (a ∧¬b)
如果a、b两个值不相同,则异或结果为1。如果a、b两个值相同,异或结果为0。
异或
NP完全问题(NP-C问题),是世界七大数学难题之一。 NP的英文全称是Non-deterministic Polynomial的问题,即多项式复杂程度的非确定性问题。简单的写法是 NP=P?,问题就在这个问号上,到底是NP等于P,还是NP不等于P。

未登录词 :未录入词典的词
兼类词:具有两个或者两个以上词性的词
自顶向下:问题规模逐步降低
软件:规约 规范化的描述
问题空间,解空间 可以看成是集合
审计:确定遵照需求,计划合同的程度
评审:评价活动或者产品是否满足需求
联合评审和审计的区别:
评审:评审方和被评审方联合共同来审查 这里审查活动的状态和产品
审计:单独的审计部门来审查 审查合同
迭代:对自己的再处理,本身的完善 模型更新变化了
递归:本身的再调用 不存在更新 提升 只是自己的再使用 数据不同
只是作为工具
无缝:你中有我,我中有你?

耦合功能:可以集成其他软件,硬件 其他人员提供的服务于一体 粘合剂的作用
可靠性
存活性 鲁棒性
可维护性
用户友好性
安全性
可移植性

自悟:自己作为用户来考虑问题
死锁:你不能提出问题 对方不能很好的提供答案
完美蠕行
数据谭
1、序列化和反序列化的定义:
(1)Java序列化就是指把Java对象转换为字节序列的过程
Java反序列化就是指把字节序列恢复为Java对象的过程。
(2)序列化最重要的作用:在传递和保存对象时.保证对象的完整性和可传递性。对象转换为有序字节流,以便在网络上传输或者保存在本地文件中。
反序列化的最重要的作用:根据字节流中保存的对象状态及描述信息,通过反序列化重建对象。
总结:核心作用就是对象状态的保存和重建。(整个过程核心点就是字节流中所保存的对象状态及描述信息)


反重建:防虫吃煎饼
完成