第8章:模型调优
第6节:贝叶斯优化
概述
贝叶斯优化(Bayesian Optimization,简称BO)是一种基于贝叶斯统计方法的全局优化策略,常用于优化复杂且昂贵的黑盒函数。贝叶斯优化的优势在于,它可以在函数评估次数极为有限的情况下,进行高效的优化。贝叶斯优化通常被应用于超参数优化,尤其是在机器学习和深度学习模型调优中,能显著提高模型的性能。
在这一节中,我们将通过5个具体的真实应用案例,介绍贝叶斯优化如何解决实际问题。每个案例将结合回归问题和分类问题,涵盖不同的应用场景,且避免雷同。每个案例将包含以下内容:
- 案例描述:阐明应用场景,提出具体问题。
- 案例分析:分析问题背景,为什么选择贝叶斯优化。
- 案例算法步骤:详细讲解贝叶斯优化的实施步骤。
- Python代码:提供具体实现代码并详细注释。
- 算法原理和公式:详细介绍贝叶斯优化的基本原理和数学公式。
案例1:回归问题——预测房价
案例描述
假设我们有一个房地产数据集,其中包含各个地区的房屋特征(例如,面积、房龄、卧室数量等)以及对应的价格。我们希望使用贝叶斯优化来调优线性回归模型的超参数,以预测房价。
案例分析
由于线性回归的超参数调优(如正则化参数)通常影响模型的性能,而我们希望在尽可能少的实验中找到最优超参数,贝叶斯优化是一个合适的选择。
案例算法步骤
- 数据加载与预处理:使用Pandas加载数据,处理缺失值。
- 模型选择:使用
LinearRegression模型作为基准。 - 贝叶斯优化:通过
skopt库的贝叶斯优化实现超参数调优。
Python代码
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from skopt import BayesSearchCV
from sklearn.datasets import fetch_california_housing
# 1. 加载数据集
data = fetch_california_housing()
X = data.data
y = data.target
# 2. 数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. 定义超参数搜索空间
param_space = {
'alpha': (1e-6, 1e+6, 'log-uniform'), # 正则化参数
}
# 4. 设置贝叶斯优化
opt = BayesSearchCV(
LinearRegression(),
param_space,
n_iter=20,
cv=3,
n_jobs=-1
)
# 5. 执行贝叶斯优化
opt.fit(X_train, y_train)
# 6. 输出最优参数和性能
print("最优正则化参数: ", opt.best_params_)
best_model = opt.best_estimator_
# 7. 在测试集上评估
y_pred = best_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("测试集均方误差: ", mse)
算法原理与公式
贝叶斯优化的核心是利用高斯过程来建模目标函数(例如,回归模型的性能)。高斯过程通过先验分布推断目标函数的分布,并通过最大化一个所谓的“采集函数”(acquisition function),选择下一组超参数进行评估。
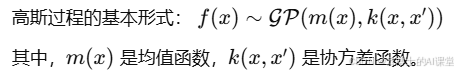
案例2:分类问题——手写数字识别
案例描述
使用经典的MNIST数据集,目标是通过贝叶斯优化调优支持向量机(SVM)模型的超参数,以实现手写数字分类。
案例分析
支持向量机的超参数(如C和gamma)对分类精度有很大影响,贝叶斯优化可以有效减少调参时间并提高模型性能。
案例算法步骤
- 加载MNIST数据集。
- 选择SVM分类器。
- 使用贝叶斯优化调优SVM的超参数。
Python代码
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from skopt import BayesSearchCV
from sklearn.preprocessing import StandardScaler
# 1. 加载MNIST数据集
digits = datasets.load_digits()
X, y = digits.data, digits.target
# 2. 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 4. 定义超参数搜索空间
param_space = {
'C': (1e-6, 1e+6, 'log-uniform'),
'gamma': (1e-6, 1e+1, 'log-uniform')
}
# 5. 设置贝叶斯优化
opt = BayesSearchCV(
SVC(),
param_space,
n_iter=50,
cv=3,
n_jobs=-1
)
# 6. 执行贝叶斯优化
opt.fit(X_train, y_train)
# 7. 输出最优超参数
print("最优超参数: ", opt.best_params_)
# 8. 在测试集上评估
y_pred = opt.best_estimator_.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("测试集准确率: ", accuracy)
算法原理与公式
SVM模型的目标是最大化分类边界,其决策边界由支持向量决定。贝叶斯优化通过高斯过程对分类精度进行建模,通过不断更新模型的预测,来逐步优化C和gamma等超参数。
案例3:回归问题——股票价格预测
案例描述
我们使用历史股票数据来预测股票价格。目标是通过贝叶斯优化调优随机森林回归模型的超参数。
案例分析
随机森林回归模型具有多个超参数(如树的数量、最大深度等),贝叶斯优化可以帮助快速找到最优参数,提高预测精度。
案例算法步骤
- 加载股票数据。
- 选择随机森林回归模型。
- 使用贝叶斯优化调优超参数。
Python代码
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from skopt import BayesSearchCV
from sklearn.datasets import make_regression
# 1. 创建模拟的股票数据(假设)
X, y = make_regression(n_samples=1000, n_features=10, noise=0.1, random_state=42)
# 2. 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. 定义超参数搜索空间
param_space = {
'n_estimators': (10, 1000),
'max_depth': (3, 20)
}
# 4. 设置贝叶斯优化
opt = BayesSearchCV(
RandomForestRegressor(),
param_space,
n_iter=20,
cv=3,
n_jobs=-1
)
# 5. 执行贝叶斯优化
opt.fit(X_train, y_train)
# 6. 输出最优超参数
print("最优超参数: ", opt.best_params_)
# 7. 在测试集上评估
y_pred = opt.best_estimator_.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("测试集均方误差: ", mse)
案例4:分类问题——图像分类
案例描述
假设我们使用一个简单的图像分类任务,利用卷积神经网络(CNN)模型,使用贝叶斯优化调整网络结构的超参数。
案例分析
卷积神经网络的超参数调优非常重要,贝叶斯优化可以在有限的计算资源下找到最优的网络结构。
案例算法步骤
Python代码
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
from sklearn.model_selection import train_test_split
from skopt import BayesSearchCV
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adam
# 1. 加载CIFAR-10数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 2. 数据预处理
x_train, x_test = x_train / 255.0, x_test / 255.0
y_train, y_test = to_categorical(y_train, 10), to_categorical(y_test, 10)
# 3. 定义模型构建函数
def build_cnn_model(filters=32, kernel_size=3, learning_rate=0.001):
model = models.Sequential()
model.add(layers.Conv2D(filters=filters, kernel_size=(kernel_size, kernel_size), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(filters=filters*2, kernel_size=(kernel_size, kernel_size), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
optimizer = Adam(learning_rate=learning_rate)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
return model
# 4. 定义贝叶斯优化的搜索空间
param_space = {
'filters': (32, 128),
'kernel_size': (3, 5),
'learning_rate': (1e-5, 1e-2, 'log-uniform')
}
# 5. 执行贝叶斯优化
opt = BayesSearchCV(
estimator=build_cnn_model,
search_spaces=param_space,
n_iter=20,
cv=3,
n_jobs=1
)
# 6. 执行贝叶斯优化过程
opt.fit(x_train, y_train)
# 7. 输出最优超参数
print("最优超参数: ", opt.best_params_)
# 8. 在测试集上评估
y_pred = opt.best_estimator_.predict(x_test)
test_accuracy = np.mean(np.argmax(y_pred, axis=1) == np.argmax(y_test, axis=1))
print("测试集准确率: ", test_accuracy)
算法原理与公式
卷积神经网络(CNN)是深度学习中常用于图像处理的模型,它通过一系列的卷积层提取图像特征,再通过全连接层进行分类。贝叶斯优化的原理与前述类似,主要通过高斯过程来对模型的性能进行建模,并通过采集函数(acquisition function)来选择下一个测试的超参数配置。
在这个问题中,优化的目标是选择合适的卷积核大小、滤波器数量以及学习率,以便在有限的训练时间内,找到性能最佳的模型。
案例5:回归问题——能源消耗预测
案例描述
我们有一个能源消耗数据集,目标是通过贝叶斯优化来调优一个深度神经网络(DNN)模型,以准确预测不同时间段的能源消耗。
案例分析
深度神经网络对于回归问题尤其适合,因为它能够处理大量复杂的特征数据,并且在没有显式的规则时也能从数据中学习到非线性关系。贝叶斯优化将帮助我们找到最适合的网络结构,如层数、节点数、学习率等。
案例算法步骤
Python代码
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from skopt import BayesSearchCV
# 1. 加载能源消耗数据(假设)
# 假设数据集已加载到energy_data中,包含了特征和目标值
energy_data = pd.read_csv("energy_consumption.csv")
X = energy_data.drop('energy_consumption', axis=1).values
y = energy_data['energy_consumption'].values
# 2. 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 4. 定义深度神经网络模型
def build_dnn_model(layers=3, nodes=64, learning_rate=0.001):
model = Sequential()
model.add(Dense(nodes, input_dim=X_train.shape[1], activation='relu'))
for _ in range(layers-1):
model.add(Dense(nodes, activation='relu'))
model.add(Dense(1)) # 回归任务只有一个输出
optimizer = Adam(learning_rate=learning_rate)
model.compile(optimizer=optimizer, loss='mse')
return model
# 5. 设置贝叶斯优化的超参数搜索空间
param_space = {
'layers': (1, 5),
'nodes': (32, 128),
'learning_rate': (1e-5, 1e-2, 'log-uniform')
}
# 6. 设置贝叶斯优化
opt = BayesSearchCV(
estimator=build_dnn_model,
search_spaces=param_space,
n_iter=30,
cv=3,
n_jobs=-1
)
# 7. 执行贝叶斯优化
opt.fit(X_train, y_train)
# 8. 输出最优超参数
print("最优超参数: ", opt.best_params_)
# 9. 在测试集上评估
y_pred = opt.best_estimator_.predict(X_test)
mse = np.mean((y_pred - y_test) ** 2)
print("测试集均方误差: ", mse)
算法原理与公式
深度神经网络(DNN)模型由多个全连接层组成,每一层的输出通过激活函数传递给下一层。目标是通过训练网络来最小化均方误差(MSE)。贝叶斯优化通过高斯过程对网络的输出进行建模,通过最大化采集函数来选择下一组超参数进行评估。
总结
本节通过5个不同的应用场景,展示了如何利用贝叶斯优化来调优机器学习模型的超参数。这些案例涵盖了回归问题和分类问题,涉及了从传统的线性回归模型到深度神经网络(DNN)的多种技术,体现了贝叶斯优化在实际应用中的强大能力。通过合理设置超参数搜索空间并结合贝叶斯优化,我们能够在较少的实验次数中找到最优超参数配置,从而提升模型的性能。
- 加载图像数据集。
- 选择CNN模型。
- 使用贝叶斯优化调优CNN模型的超参数。
案例分析
卷积神经网络(CNN)模型通常涉及到很多超参数,如卷积核大小、池化层的设置、学习率等。这些超参数对模型的分类精度有着重要的影响,而贝叶斯优化可以通过高效的搜索方法找到最优的参数配置,从而提高模型的性能,尤其是在计算资源有限时,贝叶斯优化能够减少训练次数,节省时间和计算成本。
案例算法步骤
- 加载和预处理数据:首先,我们加载一个常见的图像分类数据集(如CIFAR-10),并对图像进行必要的预处理。
- 构建CNN模型:利用Keras/TensorFlow构建卷积神经网络。
- 设置贝叶斯优化的搜索空间:调整如卷积核大小、学习率等超参数。
- 执行贝叶斯优化:通过贝叶斯优化的框架来调优模型超参数。
- 加载和预处理数据:导入能源消耗数据,进行标准化处理。
- 构建DNN模型:使用Keras构建深度神经网络。
- 设置贝叶斯优化的搜索空间:选择层数、节点数、学习率等超参数进行调优。
- 执行贝叶斯优化:用贝叶斯优化来调优超参数。
【哈佛博后带小白玩转机器学习】 【限时5折-含直播】哈佛博后带小白玩转机器学习_哔哩哔哩_bilibili
总课时超400+,时长75+小时