
今天还是有请到我们的老朋友《从零开始学习网络爬虫》,相信愿意学习Python爬虫的小伙伴们都已经安装好了Python的社区版(当然Python专业版也行),基于本书前面第一、二章就不过多赘述。小编的讲解从第三章开始
#Python第三方库——Requests库
#引入Requests库的方法,如下
首先打开python里面的终端,在python的左下角,点击一下
或者快捷键alt+F12
然后在终端里面输入pip install requests
等待python自行下载
然后我们的准备工作完成了
#爬虫的原理
(1)模拟计算机对服务器发起Requests请求
(2)接受服务器端的Requests内容并解析、提取所需信息
#实现第一个网络爬虫
本次发布时间为2023.10.22(因为网站这个东西具有时效性)
import requests
#首先导入我们刚刚下载的requests请求模块
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36'
}
#headers表示请求头,一般我们要伪装起来,不要让网站机器人发现我们是爬虫
#'User-Agent','Cookie','Host'一般为常见的请求头,
#有些时候会出现秘钥,具体要看网站里面的来确定(秘钥比较少)
response=requests.get('https://www.xiaozhu.com/',headers=headers)
#表示从该网页发送请求,获得响应体对象
#response我们称作响应体对象
#requests.get(url,headers,data,params,proxies)一般可以放置这几个参数
#url是网站地址,headers是请求头,data表示请求参数,params表示查询参数
print(response.text)
#一定要打印.text才会出现html或者是json文件
#print(response)---->打印的是响应体对象<Response [200]>
#这个200表示状态码,表示成功获得请求
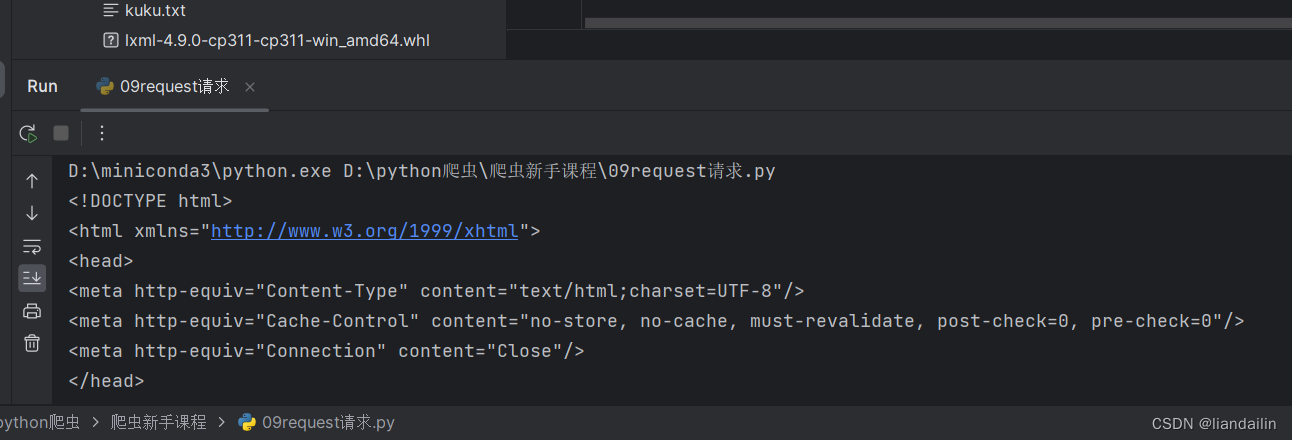
https://www.xiaozhu.com/小猪名宿网址
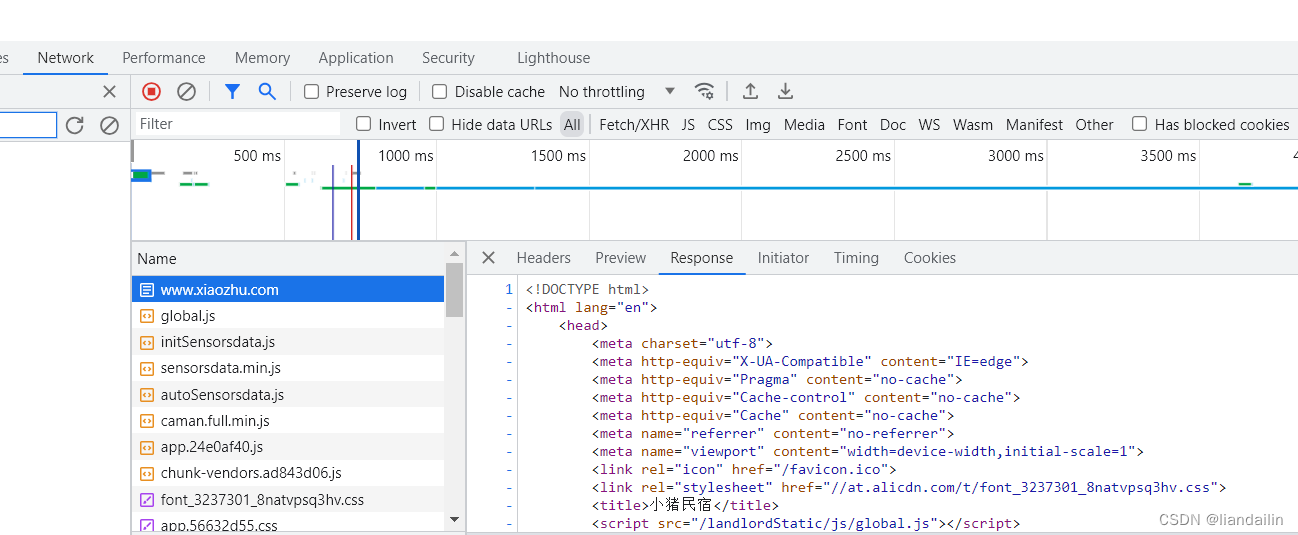
查看到第一个包www.xiaozhu.com,点击response查看到数据是和我们代码请求到数据是一样的
我们代码用的get方法:发现网页也是get方法,后续案例会有post方法,之后再讲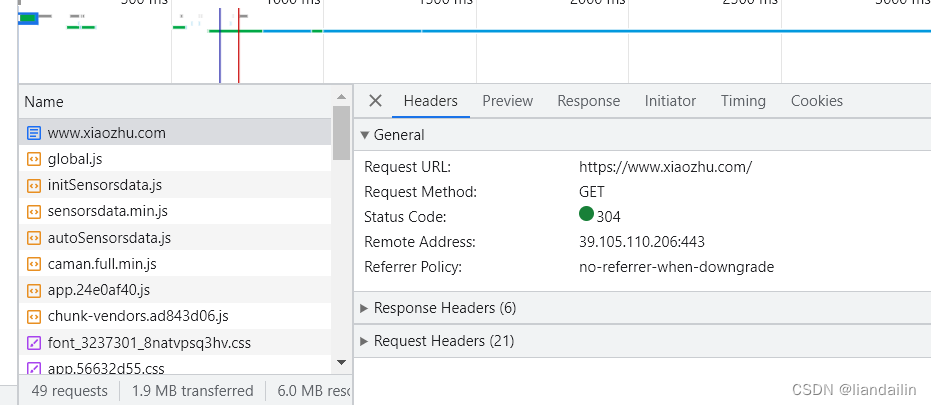
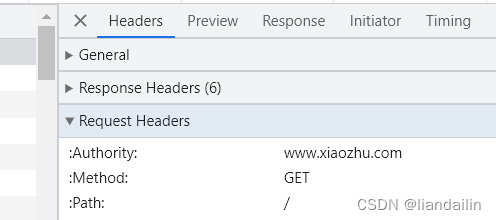
切记切记,一定要查看Request Headers请求头,而不是Response Headers响应头

关于开发者工具F12大家可以去CSDN其他博主那里看下如何操作@@@@@