目录
1. 什么是bug?
bug本意是“昆⾍”或“⾍⼦”,现在⼀般是指在电脑系统或程序中,隐藏着的⼀些未被发现的缺陷或
问题,简称程序漏洞。(有个有趣的小故事大家可以自己去搜索了解一下)
2. 什么是调试(debug)?
当我们发现程序中存在的问题的时候,那下⼀步就是找到问题,并修复问题。
这个找问题的过程叫称为调试,英⽂叫debug(消灭bug)的意思。
调试⼀个程序,⾸先是承认出现了问题,然后通过各种⼿段去定位问题的位置,可能是逐过程的调
试,也可能是隔离和屏蔽代码的⽅式,找到问题所的位置,然后确定错误产⽣的原因,再修复代码,重新测试。
3. debug和release
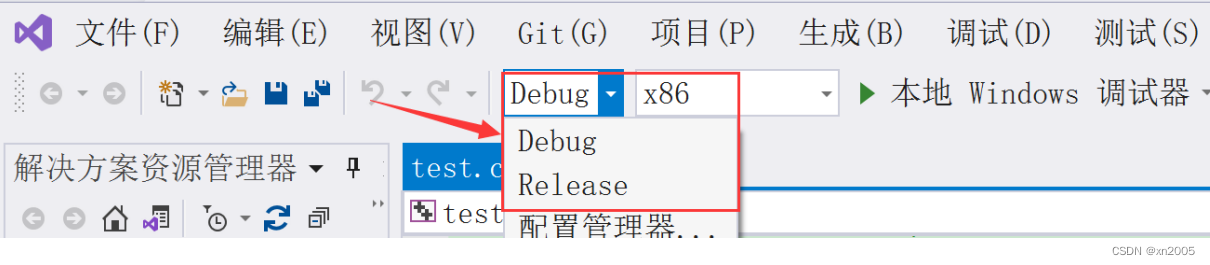
在VS上编写代码的时候,就能看到有
debug
和
release
两个选项.
Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序;
程序员在写代码的时候,需要经常性的调试代码,就将这⾥设置为
debug
,这样编译产⽣的是
debug
版本的可执⾏程序,其中包含调试信息,是可以直接调试的。
Release 称为发布版本,它往往是进⾏了各种优化,使得程序在代码⼤⼩和运⾏速度上都是最优的,以便⽤⼾很好地使⽤。当程序员写完代码,测试再对程序进⾏测试,直到程序的质量符合交付给⽤⼾使⽤的标准,这个时候就会设置为 release
,编译产⽣的就是
release
版本的可执⾏程序,这个版本是⽤⼾使⽤的,⽆需包含调试信息等。
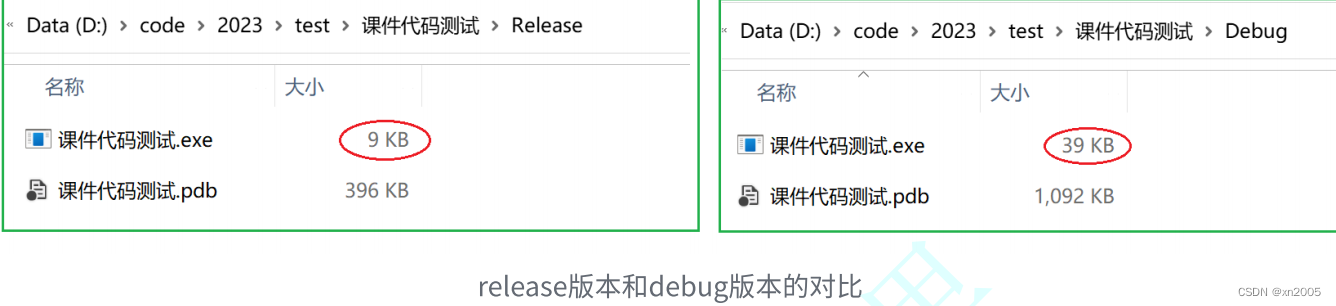
对⽐可以看到从同⼀段代码,编译⽣成的可执⾏⽂件的⼤⼩,release版本明显要⼩,⽽debug版本明显⼤。(以为debug版本要包含调试信息,release版本则是经过优化的,所以debug会比release版本文件大)
4. VS调试快捷键
程序员怎么调试代码呢?
环境准备
⾸先是环境的准备,需要⼀个⽀持调试的开发环境,我们上课使⽤VS,应该把VS上设置为Debug
调试快捷键
F9:创建断点和取消断点
断点的作⽤是可以在程序的任意位置设置断点,打上断点就可以使得程序执⾏到想要的位置暂定执
⾏,接下来我们就可以使⽤F10,F11这些快捷键,观察代码的执⾏细节。
条件断点:满⾜这个条件,才触发断点
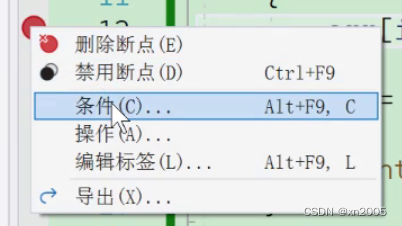
右击鼠标,点击断点的条件处,写下需要的条件

F5:启动调试,经常⽤来直接跳到下⼀个断点处,⼀般是和F9配合使⽤。
F10:逐过程,通常⽤来处理⼀个过程,⼀个过程可以是⼀次函数调⽤,或者是⼀条语句。
F11:逐语句,就是每次都执⾏⼀条语句,但是这个快捷键可以使我们的执⾏逻辑进⼊函数内部。
在函数调⽤的地⽅,想进⼊函数观察细节,必须使⽤F11,如果使⽤F10,会直接完成函数调⽤。
CTRL + F5:开始执⾏不调试,如果你想让程序直接运⾏起来⽽不调试就可以直接使⽤。
上述快捷键如果在你的电脑上没法使用,可能是因为用的是笔记本,需要配合Fn键使用“Fn+Fx”
5. 监视和内存观察
监视
在调试的过程中我们,如果要观察代码执⾏过程中,上下⽂环境中的变量的值,就可以用监视功能
这些观察的前提条件⼀定是开始调试,再然后才能观察!
⽐如:
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
int num = 100;
char c = 'w';
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = i;
}
return 0;
}
开始调试后,在菜单栏中【调试】->【窗⼝】->【监视】,打开任意⼀个监视窗⼝,输⼊想要观察的对象就⾏。
打开监视窗⼝:
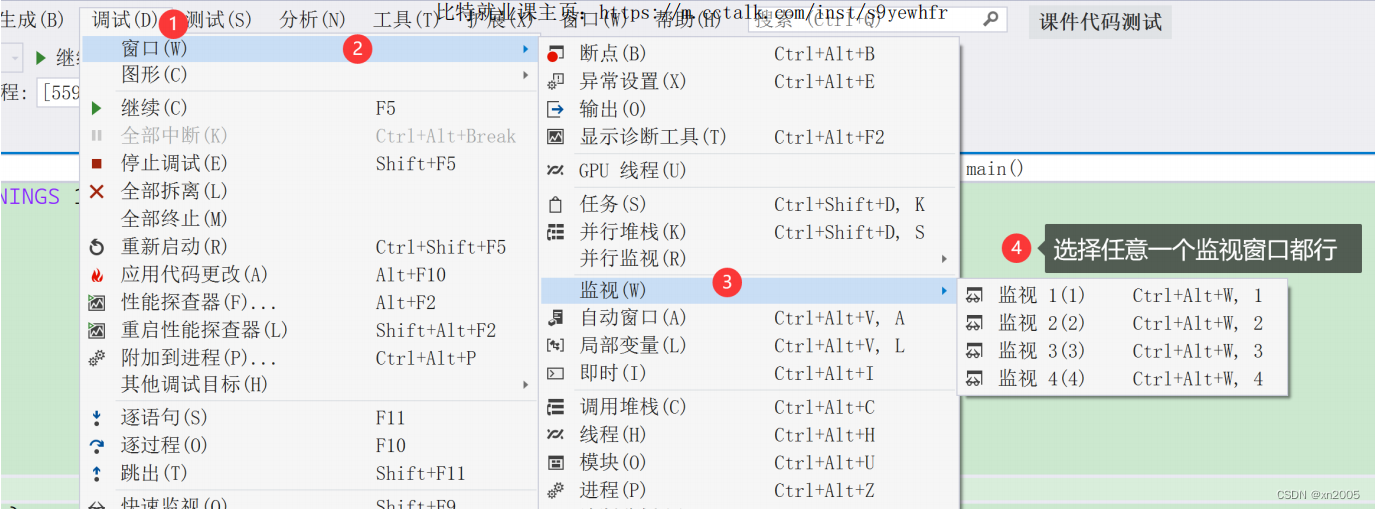
在监视窗口中观察
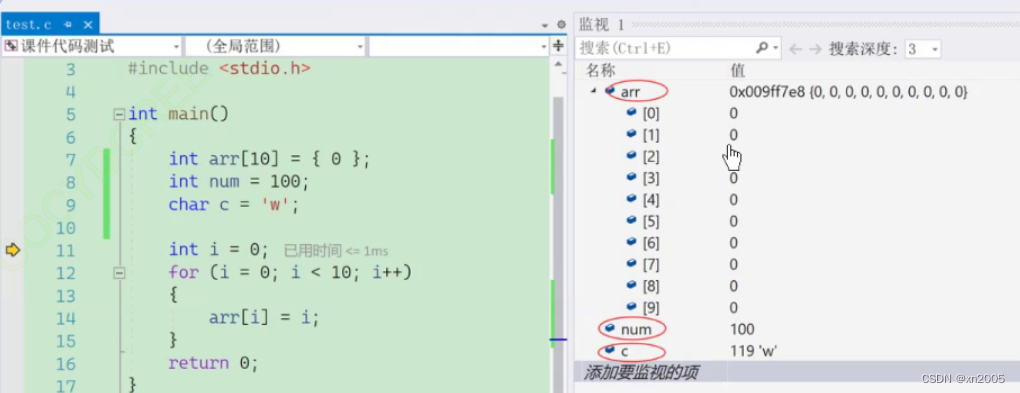
内存
如果监视窗⼝看的不够仔细,也是可以观察变量在内存中的存储情况,还是在【调试】->【窗⼝】-> 【内存】
打开内存窗⼝:
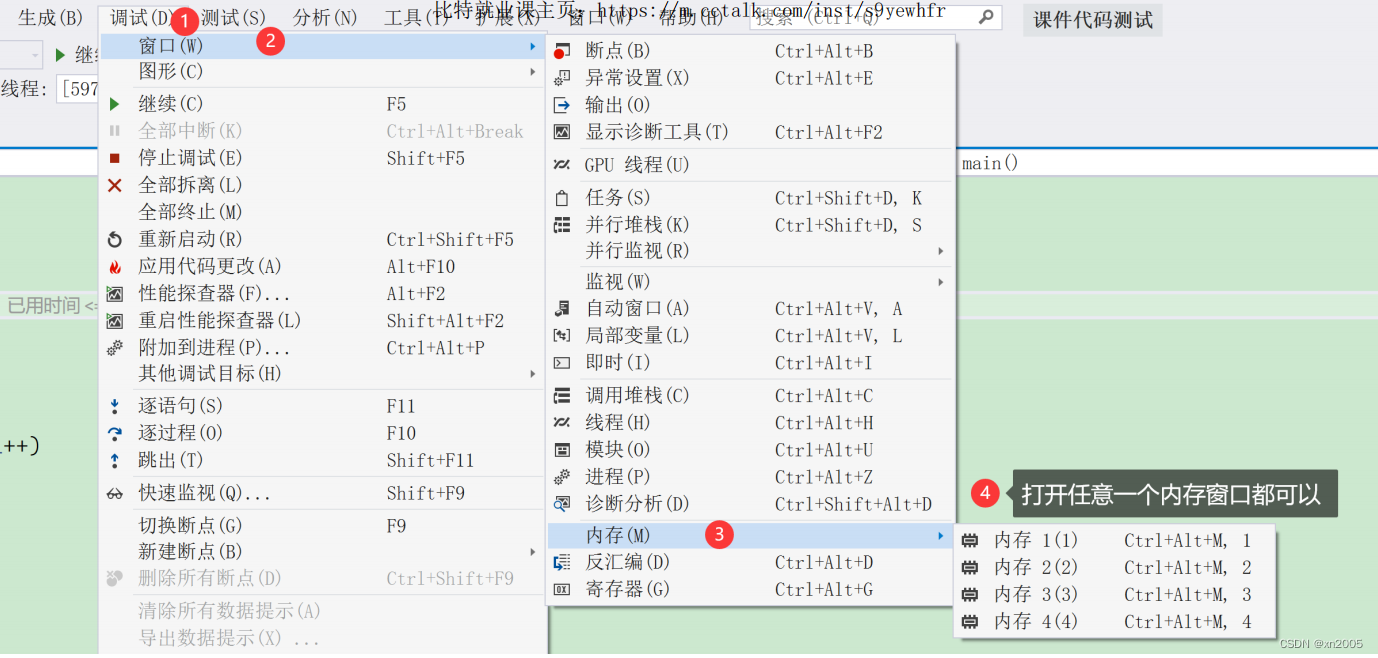
就可以看到
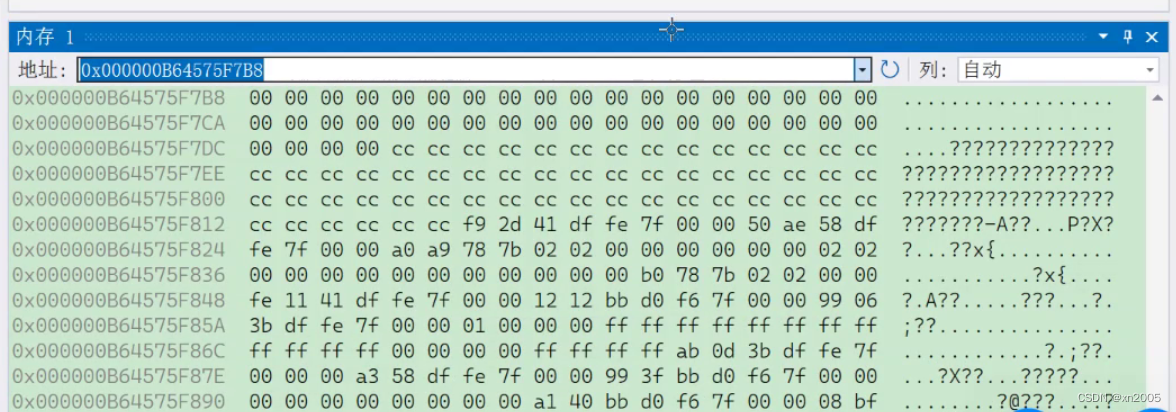
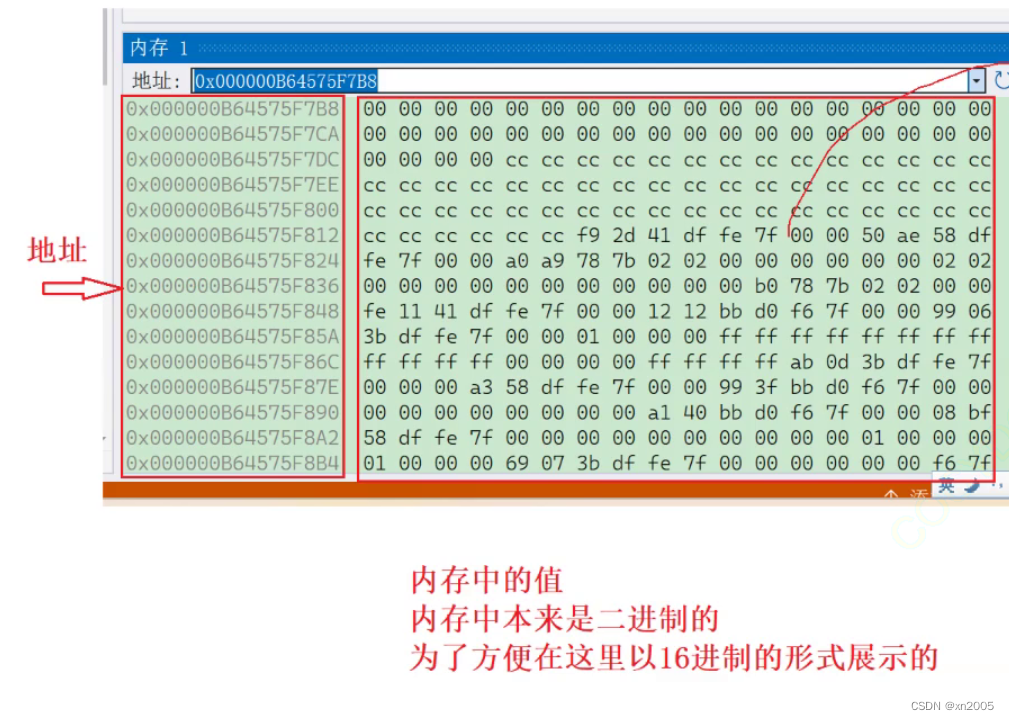
我们还可以设置列数
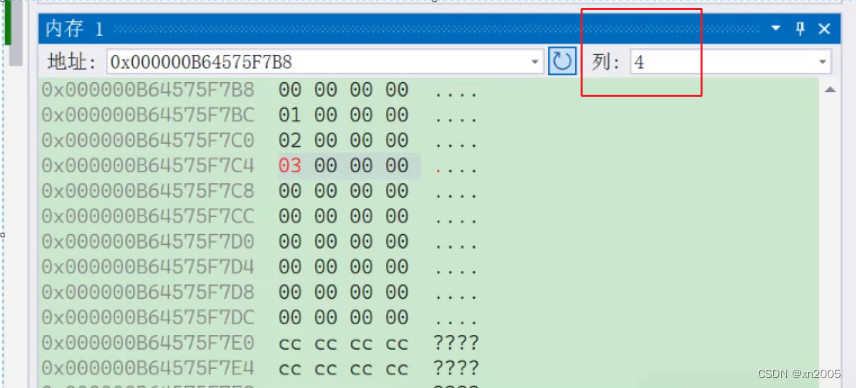
我们甚至还可以指定去查看某个地址,
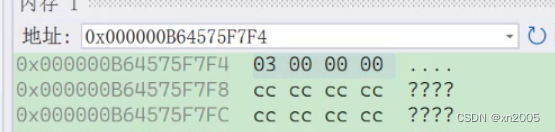
在打开内存窗⼝后,要在地址栏输⼊:arr,&num,&c,这类地址,就能观察到该地址处的数据。
比如这里我们想查看i的地址,输入取地址i,回车,就能得到结果。

除此之外,在调试的窗⼝中还有:⾃动窗⼝,局部变量,反汇编、寄存器等窗⼝,⾃⾏验证使⽤⼀
下。
6.
调试举例1
求 1!+2!+3!+4!+...10! 的和,请看下⾯的代码:
#include <stdio.h>
//写⼀个代码求n的阶乘
int main()
{
int n = 0;
scanf("%d", &n);
int i = 1;
int ret = 1;
for(i=1; i<=n; i++)
{
ret *= i;
}
printf("%d\n", ret);
return 0;
}
//如果n分别是1,2,3,4,5...10,求出每个数的阶乘,再求和就好了
//在上⾯的代码上改造
int main()
{
int n = 0;
int i = 1;
int sum = 0;
for(n=1; n<=10; n++)
{
for(i=1; i<=n; i++)
{
ret *= i;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
}
//运⾏结果应该是错的?这里我们根据监视一步一步看计算的结果就可以发现一个隐蔽的错误,那就是在内层循环第三次之后的每一次,由于我们ret的值没有重新初始化,带入的是上次旧的ret所以会使数阔大很多倍。
改后代码是这样的:
#include <stdio.h>
int main()
{
int n = 0;
int i = 1;
int sum = 0;
for(n=1; n<=10; n++)
{
for(i=1; i<=n; i++)
{
ret=1;
ret *= i;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
}
7.
调试举例2
在VS2022、X86、Debug 的环境下,编译器不做任何优化的话,下⾯代码执⾏的结果是啥?
#include <stdio.h>
int main()
{
int i = 0;
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
for(i=0; i<=12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}
程序运⾏,死循环了,调试看看为什么?

调试可以上⾯程序的内存布局如下:
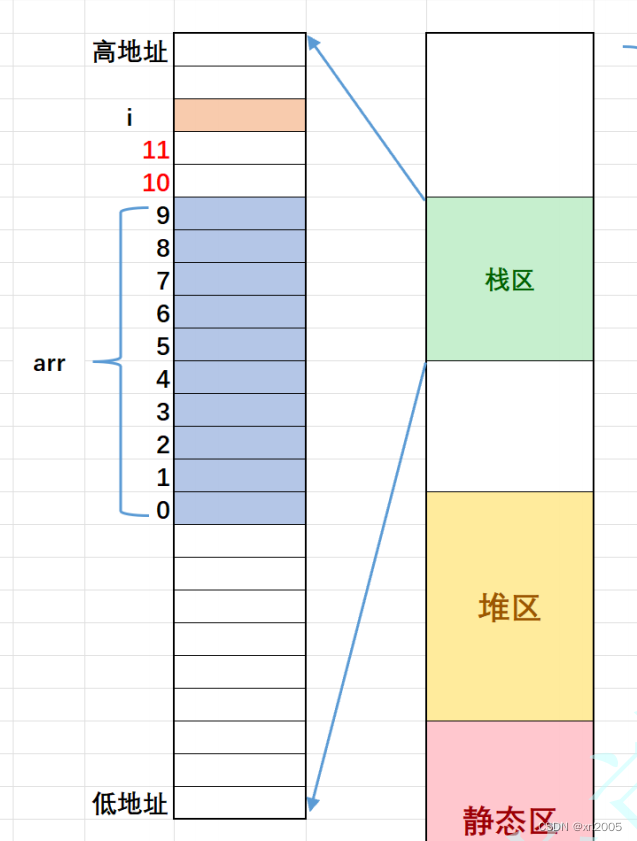
1.
栈区内存的使⽤习惯是从⾼地址向低地址使⽤的,所以变量i的地址是较⼤的。arr数组的地址整体是⼩于i的地址。
2.
数组在内存中的存放是:随着下标的增⻓,地址是由低到⾼变化的。所以根据代码,就能理解为什么是上面的代码布局了。
如果是上面的内存布局,那随着数组下标的增⻓,往后越界就有可能覆盖到i,这样就可能造成死循环的。
为什么i和arr数组之间恰好空出来2个整型的空间呢?
这⾥确实是巧合,在不同的编译 器下可能中间的空出的空间⼤⼩是不⼀样的,代码中这些变量内存的分配和地址分配是编译器指定的,所以的不同的编译器之间就有差异了。所以这个题⽬是和环境相关的。
注意:
栈区的默认的使⽤习惯是先使⽤⾼地址,再使⽤低地址的空间,但是这个具体还是要编译器的实现,⽐如:在VS上切换到X64,这个使⽤的顺序就是相反的,在Release版本的程序中,这个使⽤的顺序也是相反的。
编程常见错误归类
编译型错误
编译型错误⼀般都是语法错误,这类错误⼀般看错误信息就能找到⼀些蛛丝⻢迹的,双击错误信息也 能初步的跳转到代码错误的地⽅或者附近。编译错误,随着语⾔的熟练掌握,会越来越少,也容易解决。
链接型错误
看错误提示信息,主要在代码中找到错误信息中的标识符,然后定位问题所在。⼀般是因为
•
标识符名不存在
•
拼写错误
•
头⽂件没包含
•
引⽤的库不存在
链接型错误在双击时不会有反应。
运行时错误
运行时错误,是千变万化的,需要借助调试,逐步定位问题,调试解决的是运行时问题。
完