1.分类评价指标-单一值
借此机会,在此篇总结常用的分类评价指标。
1.1 从真假阴阳性聊起
在机器学习领域,经常遇到文献中出现TP\TN\FP\FN等,每次碰到都要再回忆一遍,还生怕记混了。于是,在此,一网打尽!
1. 真阳性 (True Positive, TP)
含义:模型预测结果为阳性,且,实际标签值也为阳性。预测正确。
通俗理解:Positive代表预测结果为阳性,True代表预测正确,即对应标签真值 (Ground Truth)也为阳性。代入医学领域,代表着此次诊断正确,患者 确实 患病。
2. 真阴性 (True Negative, TN)
含义:模型预测结果为阴性,且,实际标签值也为阴性。预测正确。
通俗理解:Negative代表预测结果为阴性,True代表预测正确,即对应标签真值也为阴性。代入医学领域,代表着此次诊断正确,患者 确实 未患病。
3. 假阳性 (False Positive, FP)
含义:模型预测结果为阳性,但,实际标签值却为阴性。预测错误。
通俗理解:Positive代表预测结果为阳性,False代表预测错误,即对应标签真值相反 为阴性。代入医学领域,代表着此次诊断错误,患者 并未患病。属于误诊。
4. 假阴性 (False Negative, FN)
含义:模型预测结果为阴性,但,实际标签值却为阳性。预测错误。
通俗理解:Negative代表预测结果为阴性,False代表预测错误,即对应标签真值相反 为阳性。代入医学领域,代表着此次诊断错误,患者 已经患病但没诊断出来。属于漏诊。
综上所述,我们可以得知拿到这组词,先看第二个词:positive or negative,第二个词决定了模型预测的结果;再看第一个词,true or false,第一个词决定了模型预测是否正确。连起来读一遍就得到了对应的含义哦。举个粒子:FP,第二个词是positive,模型预测阳性;第一个词是False,模型预测错误;于是,整体连起来就是,模型预测为阳性但预测错误,标签真值为阴性。
1.2 混淆矩阵的格子
在理解了1.1的基础上,我们将TP\TN\FP\FN合理的填进一个2x2的矩阵里,就得到了混淆矩阵 (Confusion Matrix)。
| Predicition-模型预测值 | |||
| Ground Truth 标签真值 | Positive | Negative | |
| Positive | TP | FN | |
| Negative | FP | TN | |
如果是多分类问题,只需在此基础上,加行加列即可。举个利兹:
| Predicition-模型预测值 | |||||
| Ground Truth 标签真值 | 类别1 | 类别2 | 类别3 | 类别4 | |
| 类别1 | 443 | 9 | 4 | 6 | |
| 类别2 | 6 | 153 | 1 | 8 | |
| 类别3 | 7 | 4 | 4 | 1 | |
| 类别4 | 10 | 15 | 0 | 41 | |
矩阵中每一列之和代表着测试集中模型预测为该类别的总样本数,每一行之和代表着测试集中标签真值为该类别的总样本数。
通过混淆矩阵,可以清晰地看出模型预测与标签真值在每一类上的呼应表现,便于直接观察出模型具体在哪一类上的表现更准或较差。
揭示了researcher表现较差的类别会被错误的分到其他哪一类上?
激发researcher思考为何该类会被分到其他类别?
是两类别之间相似还是当前类别没有显著的特征?
换个角度出发,能不能找到该类别更显著的特征?
从而调整模型优化策略,着重针对较差的类别进行提升。
2.分类评价指标-复合值
聊完了上面简单的单一值,下面开始介绍复合值。顾名思义,通过上面单一值各种加减乘除计算,得到的指标。先把上面的混淆矩阵贴下,方便观察。
| Predicition-模型预测值 | |||
| Ground Truth 标签真值 | Positive | Negative | |
| Positive | TP | FN | |
| Negative | FP | TN | |
2.1 Sensitivity 灵敏性 or Recall 召回率
含义:模型预测为阳性的样本占标签真值为阳性的样本比例。也被叫做召回率Recall或TPR, TP Ratio。通俗讲,测阳率。
2.2 Specificity 特异性
含义:模型预测为阴性的样本占标签真值为阴性的样本比例。也被叫做TNR, TN Ratio。通俗讲,测阴率。
2.3 Precision 正确率
含义:模型预测为阳性的预测正确样本占模型预测为阳性的总样本比例。通俗讲,阳性正确率。
2.4 Accuracy 准确率
含义:模型预测正确的样本占参与测试的总样本比例,代表着模型预测正确的比率,比例越高,模型分类效果越好。
2.5 F1 Score F1分数
含义:模型正确率和召回率的调和平均数。
3.分类评价指标的曲线
从一个李子讲起,假设测试集共100个,含有A类样本90个,B类样本10个;
1号分类器把所有样本都预测为了A类,此时分类准确率达到90%;
2号分类器在A类样本上预测对了70个,另外20个A样本预测为了B,在B类样本上预测对了8个,另外2个B样本预测为了A,此时分类准确率达到78%。
只从分类准确率上说,1号分类器表现更好,但往往2号分类器更实用,在两类上的表现更均衡。
不难看出,当各类别之间的样本数明显不均衡时,仅仅依靠上述指标无法综合评价分类器的分类表现。于是,产生了ROC曲线和AUC指标等。
3.1 ROC曲线
ROC的全名叫做Receiver Operating Characteristic,其主要分析工具是一个画在二维平面上的曲线——ROC curve。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。这样,此分类器就可以映射成ROC平面上的一个点。
回顾下TPR和FPR:
,
TPR关注的是分类器在识别阳性样本上的表现,TPR越高,识别阳性越准;
FPR体现的是分类器在识别阴性样本上的错误率,FPR越低,识别阴性越准。
当FPR达到最小值0,TPR达到最大值1时,该分类器分类最准。即为ROC曲线上最左上角的点(0, 1)。
TPR和FPR分别从阳性和阴性样本考察分类表现,避免了各类别样本数不均衡所带来的问题。因此,这也是为何被选做ROC坐标轴的原因。
如下如所示,ROC曲线距离左上角越近,表明分类器分类效果越好。
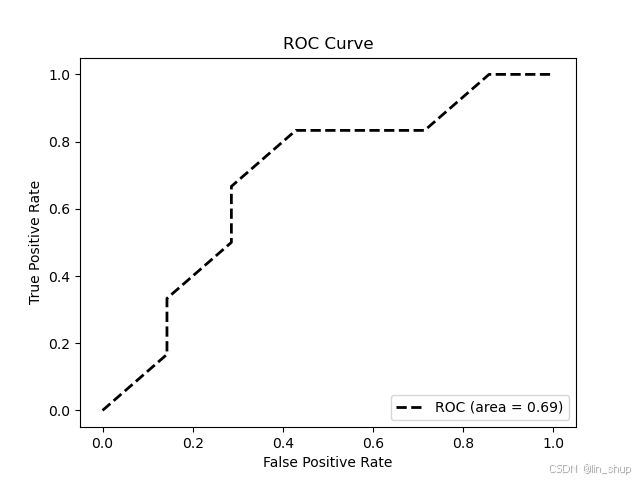
3.2 AUC值
AUC,Area Under Curve,ROC曲线下面积。取值范围在0-1之间。如果多个分类器的ROC曲线在同一幅图中无法明显的体现孰优孰劣,就需要计算AUC值了,AUC越大,分类效果越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测
下面是绘制ROC曲线和计算AUC的代码部分,其他代码可私聊获取。
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
y_label = ([1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2]) # 非二进制需要pos_label
y_pre = ([0.6, 0.7, 0.4, 0.5, 0.3, 0.5, 0.9, 0.8, 0.4, 0.6, 0.9, 0.7, 0.65])
fpr, tpr, thersholds = roc_curve(y_label, y_pre, pos_label=2)
for i, value in enumerate(thersholds):
print("%f %f %f" % (fpr[i], tpr[i], value))
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, 'k--', label='ROC (area = {0:.2f})'.format(roc_auc), lw=2)
plt.xlim([-0.05, 1.05]) # 设置x、y轴的上下限,以免和边缘重合,更好的观察图像的整体
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate') # 可以使用中文,但需要导入一些库即字体
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.show()
本文主要参考以下帖子,非常感谢!
Python下使用sklearn绘制ROC曲线(超详细)_sklearn 画roc图-CSDN博客