1、首先找到以.ttf结尾的字体文件,下载下来,以我的字体文件sfont.ttf为例
sont.ttf下载地址https://download.csdn.net/download/lingyingdon/89534953
目前只测试了.ttf文件。如果想使用woff字体文件,请自行测试
2、下载分割字体文件的软件fontforge, 安装后将安装路径添加到环境变量中去,该软件结合python脚本分割字体文件为单个字体图片及其对应的编码作为文件名
-
官网地址如下
https://fontforge.org/en-US/ -
python脚本如下
split_font.pyimport os import argparse import sys import fontforge def main(font_path, folder): # 字体文件分割脚本,需要配合fontforge使用 # font_path = r"F:\download\sfont.ttf" # 字体文件路径 # folder = "img" # 字体文件分割后保存的目录 F = fontforge.open(font_path) for name in F: filename = name + ".png" export_path = os.path.join(folder, filename) F[name].export(export_path) if __name__ == '__main__': parser = argparse.ArgumentParser(description='字体分割.....') parser.add_argument('-f', '--file_path', type=str, help='字体文件路径,字体文件为.ttf结尾') parser.add_argument('-d', '--dir', type=str, help='输出字体文件目录') args = parser.parse_args() if args.file_path and args.dir: main(args.file_path, args.dir) else: print("请输入字体文件路径和输出字体文件目录") sys.exit(1) -
通过执行以下命令脚本分割字体文件(前提是将fontforge添加到环境变量)
fontforge split_font.py
-
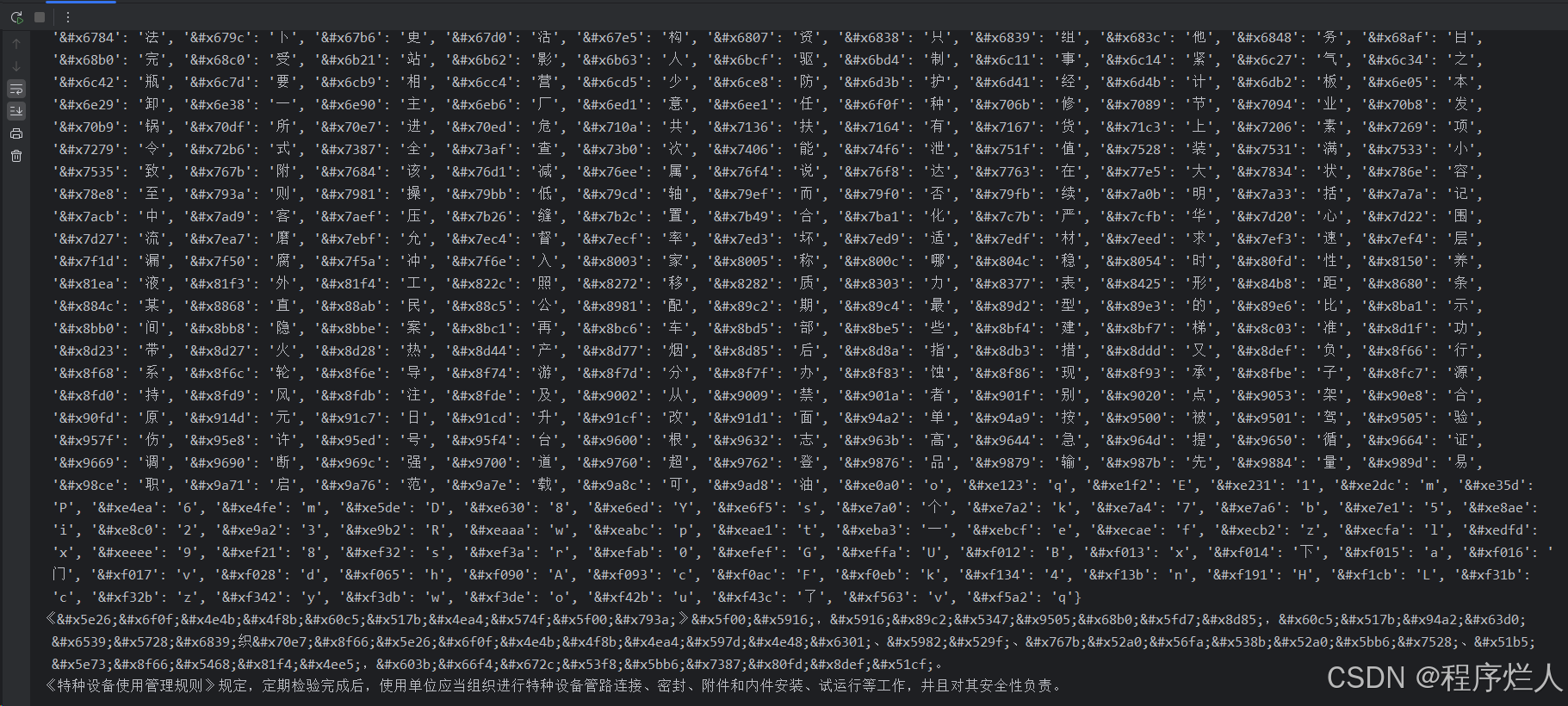
处理后的图片如下

3、由于分割后的字体文件相对比较模糊,通过使用pillow模块扩张字体图片大小来增加图片的清晰度
def strength_pic(pic_path):
"""
图片增强
猜想是,在进行卷积处理的时候,选择的算子在边界处理上更倾向于重新计算,而实际上我们的边界是不需要计算的,所以这里手动将边界扩张
"""
old_im = Image.open(pic_path)
old_size = old_im.size
new_size = (300, 300)
new_im = Image.new("RGB", new_size, color='white') ## luckily, this is already black!
new_im.paste(old_im, (int((new_size[0] - old_size[0]) / 2),
int((new_size[1] - old_size[1]) / 2)))
new_im.save(pic_path.replace('img', 'img_output'))
-
经过处理后的图片如下

4、使用ddddocr模块来识别字体图片
def ocr_img(ocr, file_path):
"""
使用ddddocr模块识别
:param ocr: ddddocr实例化对象
:param file_path: 图片文件路径
:return: 识别结果
"""
image = open(file_path, "rb").read()
result = ocr.classification(image)
return result