共享变量
解决方案一-广播变量
将本地列表标记成广播变量
可以实现降低内存占用和减少网络IO传输,提高性能
boradcast = sc.boardcast(stu_info_list)
value = broadcast.value
解决方案二-累加器
acmlt = sc.accumulator(0)
可以收集执行器的执行结果并作用在自己的身上
Spark内核调度
DAG:有向五环图
一个action会产生一个DAG
一个DAG运行会产生一个job
一个代码运行起来包含叫做Application,包含多job
DAG和分区关联后,可以得到有分区关系的DAG图
DAG的宽窄依赖和阶段划分
窄依赖:父RDD的一个分区,将全部数据发给子RDD的一个分区
宽依赖: 父RDD的一个分区会将数据发给子RDD的多个分区
宽依赖还有一个别名shuffle
对于Spark过程,会按照宽依赖划分不同的DAG阶段,从后向前,遇到一个宽依赖就换分出一个阶段,成为stage,二每个stage的内部一定都是窄依赖
面试题1
spark怎么做内存计算的?DAG的作用?stage阶段划分的作用?
spark会使用DAG图进行内存计算,DAG图会根据分区和宽窄依赖划分阶段,每一个阶段饿的内部都是窄依赖,这些内存迭代计算的管道形成一个个具体的执行任务,一个任务对应一个线程,任务在线程中运行,就是在进行内存计算。
面试题2
spark为什么mapreduce计算效率快?
spark的算子丰富,mapreduce算子匮乏,很多复杂的人物需要多个mapreduc进行串联,通过磁盘交互数据
spark可以执行内存迭代,听过形成DAG并基于依赖划分阶段后,在阶段内可以形成内存迭代管道,但是map使用硬盘进行交互的,spark可以使用更多的内存计算而不是磁盘迭代
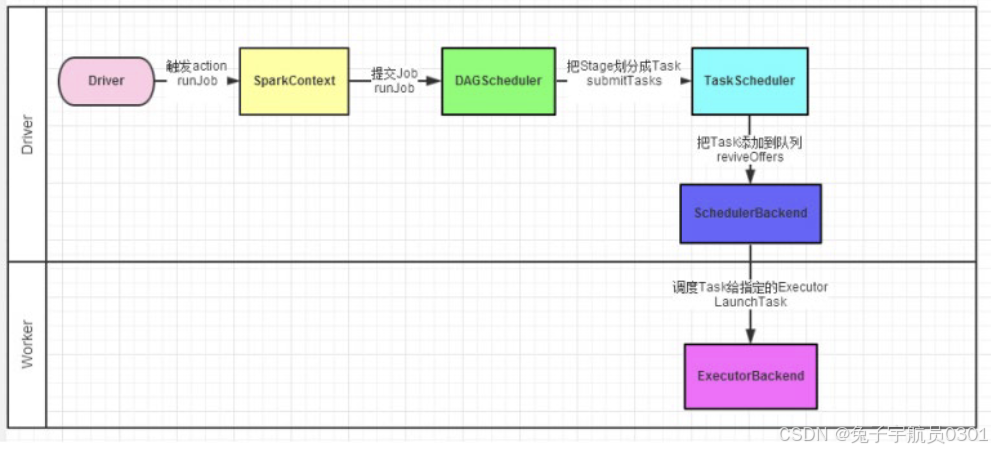
spark程序的调度流程如图所示
1.driver被构建出来
2.构建spark Context:执行环境入口对象
3.基于DAG调度器构建逻辑任务分配
4.基于任务调度器将逻辑任务分配到各个执行器上干活,并监控他们
5.执行器被任务调度器监控,听从他们的指令工作,并定期汇报工作进度
driver的两个重要组件:DAG调度器和task调度器