文章目录
Redis集群与分区
集群的意义:
高可用: 集群的故障转移
高性能:多台计算能力、读写分离
高扩展:横向主机扩展
分区是将数据分布在多个Redis实例(Redis主机)上,以至于每个实例只包含一部分数据。
分区的意义
-
性能的提升
单机Redis的网络I/O能力和计算资源是有限的,将请求分散到多台机器,充分利用多台机器的计算能力
-
存储能力的横向扩展
即使Redis的服务能力能够满足应用需求,但是随着存储数据的增加,单台机器受限于机器本身的存储容量,
将数据分散到多台机器上存储使得Redis服务可以横向扩展。
分区的方式
范围分区和hash分区
范围分区
根据分区键(id)进行分区: 数字的范围比如1–10000、100001–20000…90001-100000,每个范围分到不同的Redis实例中
| id范围 | Redis实例 |
|---|---|
| 1–10000 | Redis01 |
| 100001–20000 | Redis02 |
| … | |
| 90001-100000 | Redis10 |
好处: 实现简单,方便迁移和扩展
缺陷:
-
热点数据分布不均,性能损失
-
非数字型key无法处理,需要保证key的唯一,也要保证key的规则在redis的id范围内
比如uuid可以保证唯一,但不能就能行排序,可采用雪花算法替代,是数字,且能排序,但key比较长
hash分区
利用简单的hash算法: Redis主机位置=hash(key)%N
key:要进行分区的键,比如user_id N:Redis实例个数(Redis主机)
好处:
支持任何类型的key
热点分布较均匀,性能较好
**缺陷: 迁移复杂,需要重新计算,扩展较差(利用一致性hash环) **
client端分区
对于一个给定的key,客户端(需要编程)直接选择正确的节点来进行读写。许多Redis客户端都实现了客户端分区 ( JedisPool),也可以自行编程实现。
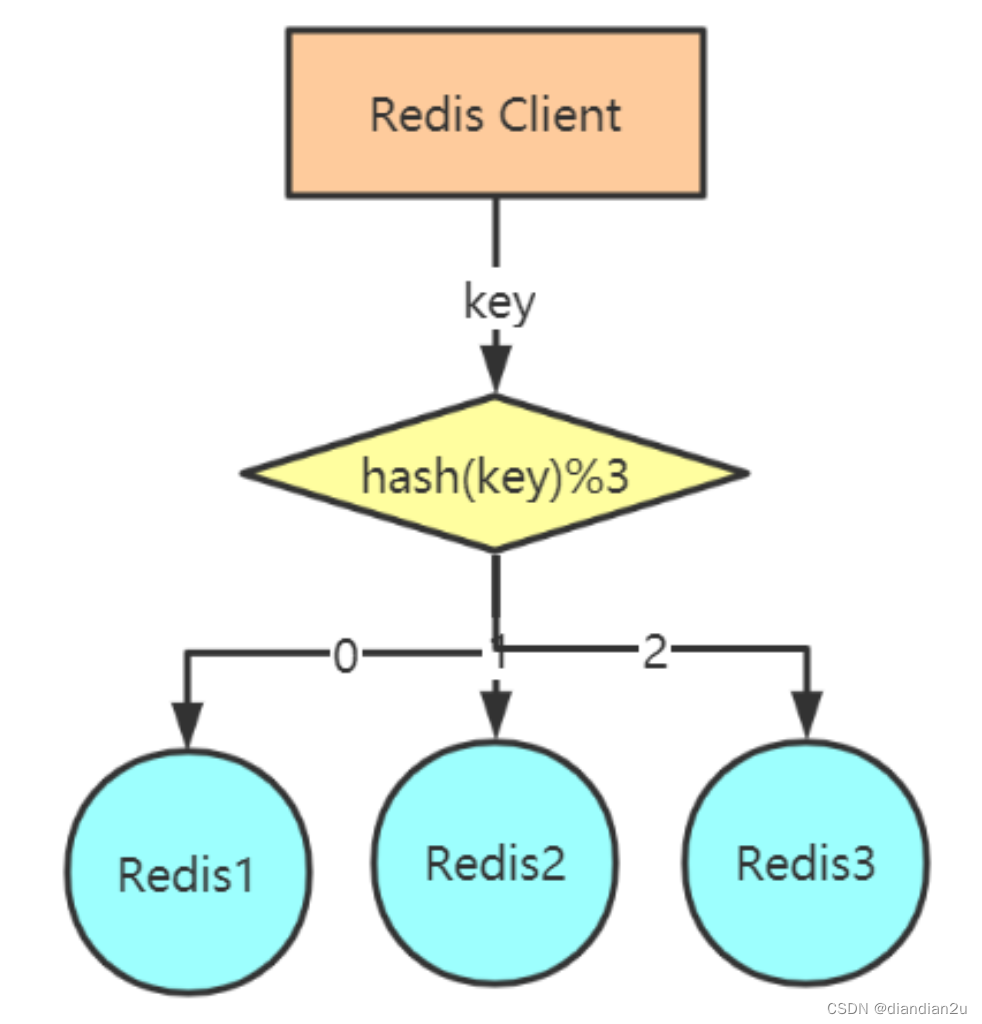
客户端选择算法
hash(普通hash)
hash(key)%N
hash:可以采用hash算法,比如CRC32、CRC16等
N:是Redis主机个数
比如:
user_id : u001
hash(u001) : 1844213068
Redis实例=1844213068%3
余数为2,所以选择Redis3。
普通Hash的优势: 实现简单,热点数据分布均匀
普通Hash的缺陷: 点数固定,扩容的话需要重新计算
查询时必须用分片的key来查,一旦key改变,数据就查不出了,所以要使用不易改变的key进行分片
一致性hash
基本概念
普通hash是对主机数量取模,扩容非常复杂,需要重新计算,那就把主机数量个数扩大些。
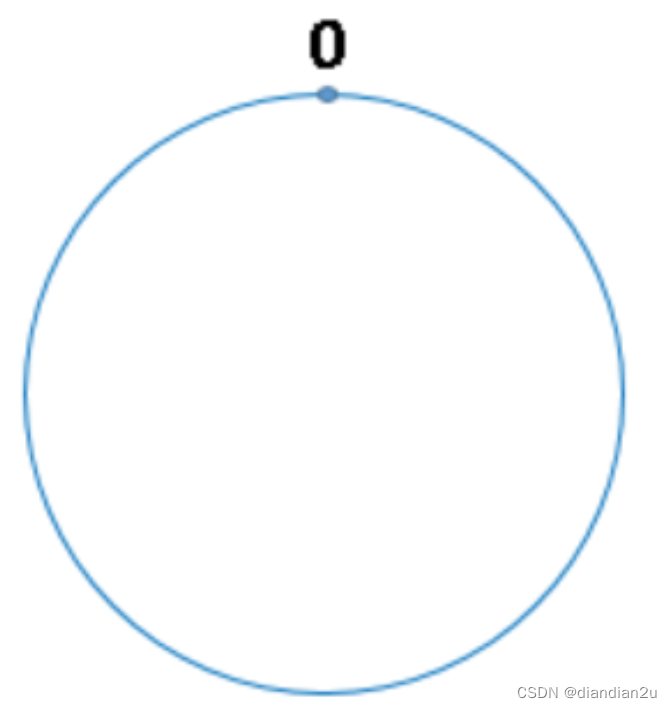
一致性hash是对2^32(4 294 967 296)取模。我们把232想象成一个圆,就像钟表一样,钟表的圆可以理解成由60个点组成的圆,而此处我们把这个圆想象成由232个点组成的圆,示意图如下:
圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6…直到232-1,也就是说0点左侧的第一个点代表232-1 。我们把这个由2的32次方个点组成的圆环称为hash环。
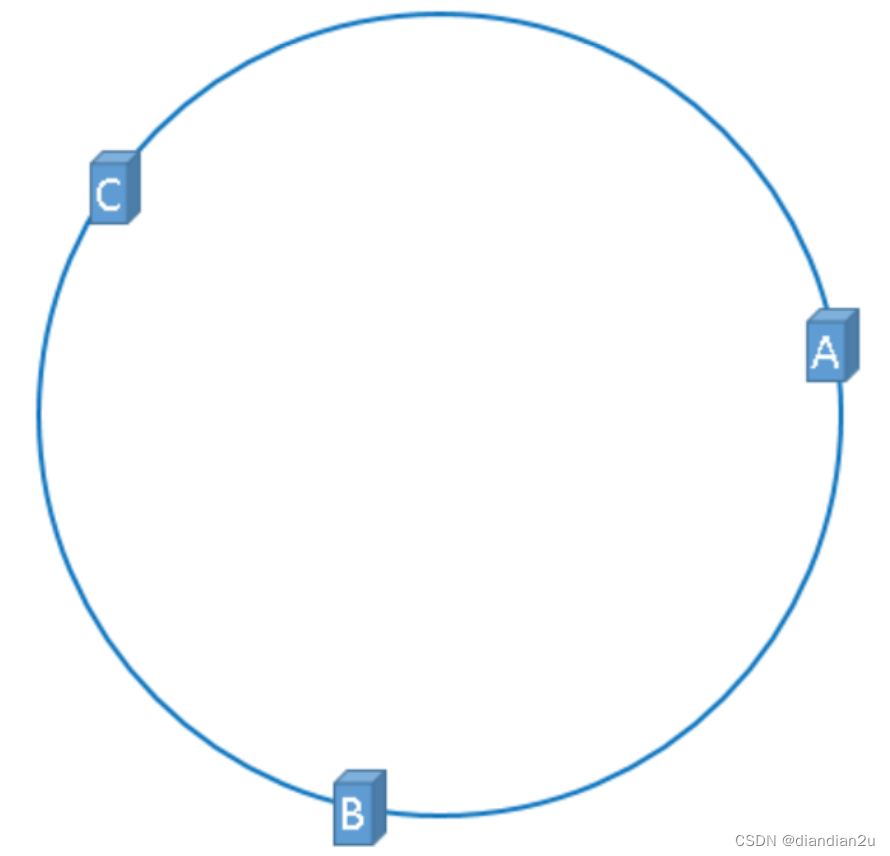
假设我们有3台缓存服务器,服务器A、服务器B、服务器C,那么,在生产环境中,这三台服务器肯定有自己的IP地址,我们使用它们各自的IP地址进行哈希计算,使用哈希后的结果对2^32取模,可以使用如下公式:
hash(服务器的IP地址) % 2^32
通过上述公式算出的结果一定是一个0到232-1之间的一个整数,我们就用算出的这个整数,代表服务器A、服务器B、服务器C,既然这个整数肯定处于0到232-1之间,那么,上图中的hash环上必定有一个点与这个整数对应,也就是服务器A、服务器B、服务C就可以映射到这个环上,如下图:
假设,我们需要使用Redis缓存数据,那么我们使用如下公式可以将数据映射到上图中的hash环上。
**hash(key) % 2^32
** 映射后的示意图如下,下图中的橘黄色圆形表示数据
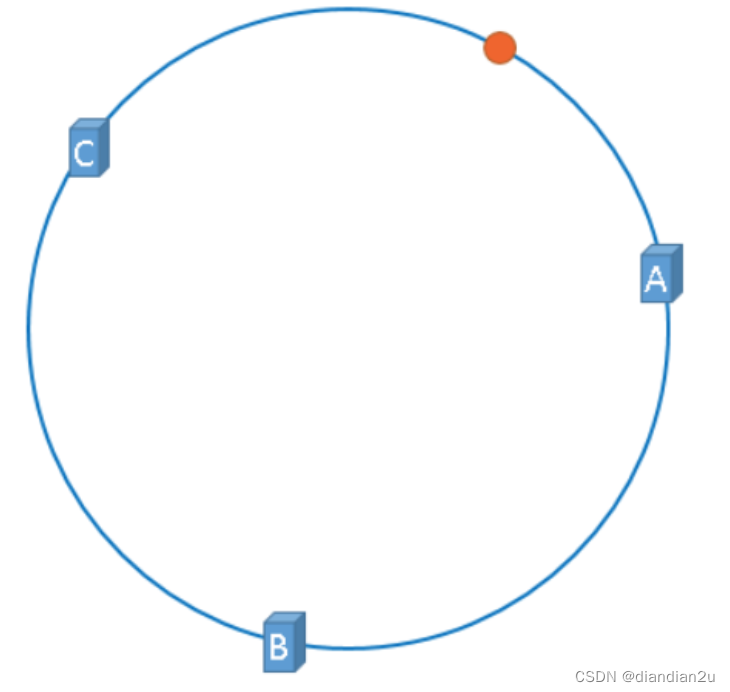
现在服务器与数据都被映射到了hash环上,上图中的数据将会被缓存到服务器A上,因为从数据的位置开始,沿顺时针方向遇到的第一个服务器就是A服务器,所以,上图中的数据将会被缓存到服务器A上。 如图:
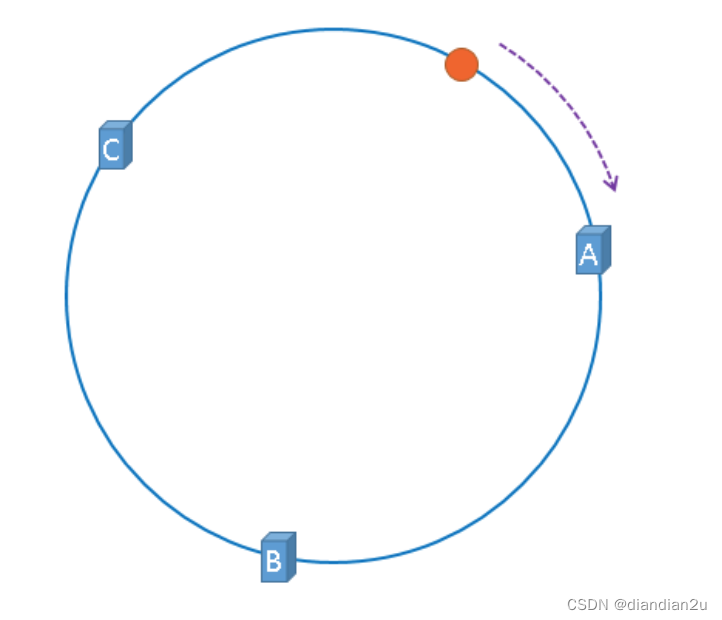
将缓存服务器与被缓存对象都映射到hash环上以后,从被缓存对象的位置出发,沿顺时针方向遇到的第一个服务器,就是当前对象将要缓存的服务器,由于被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的情况下,数据必定会被缓存到固定的服务器上,那么,当下次想要访问这个数据 时,只要再次使用相同的算法进行计算,即可算出这个数据被缓存在哪个服务器上,直接去对应的服务 器查找对应的数据即可。多条数据存储如下:
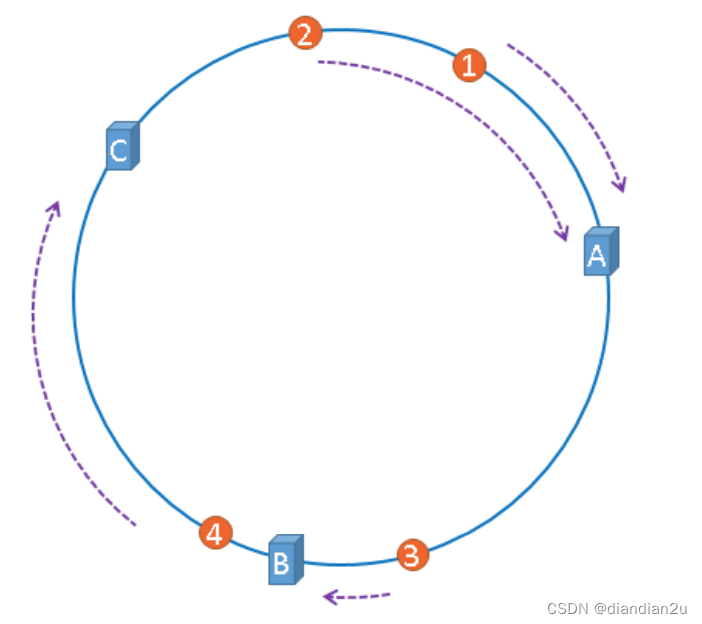
优点
添加或移除节点时,数据只需要做部分的迁移,比如上图中把C服务器移除,则数据4迁移到服务器A中,而其他的数据保持不变。添加效果是一样的。
hash环偏移
在介绍一致性哈希的概念时,我们理想化的将3台服务器均匀的映射到了hash环上。也就是说数据的范围是2^32/N。但实际情况往往不是这样的。有可能某个服务器的数据会很多,某个服务器的数据会很少,造成服务器性能不平均。这种现象称为hash环偏移。
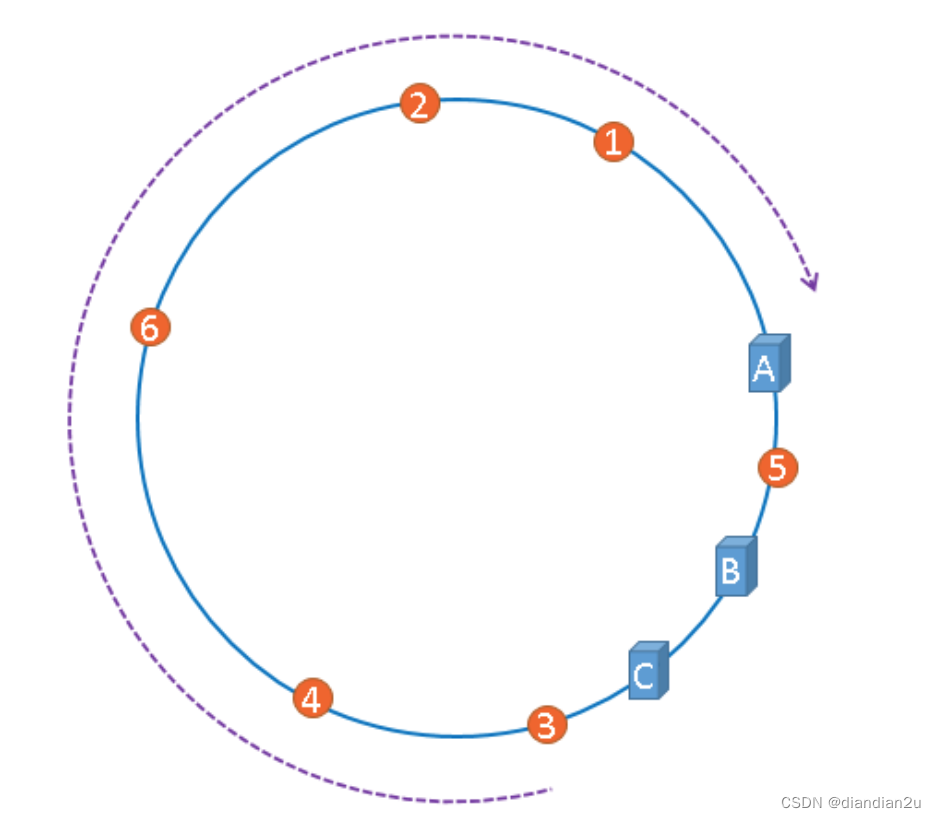
理论上我们可以通过增加服务器的方式来减少偏移,但这样成本较高,所以我们可以采用虚拟节点的方
式,也就是虚拟服务器,如图:
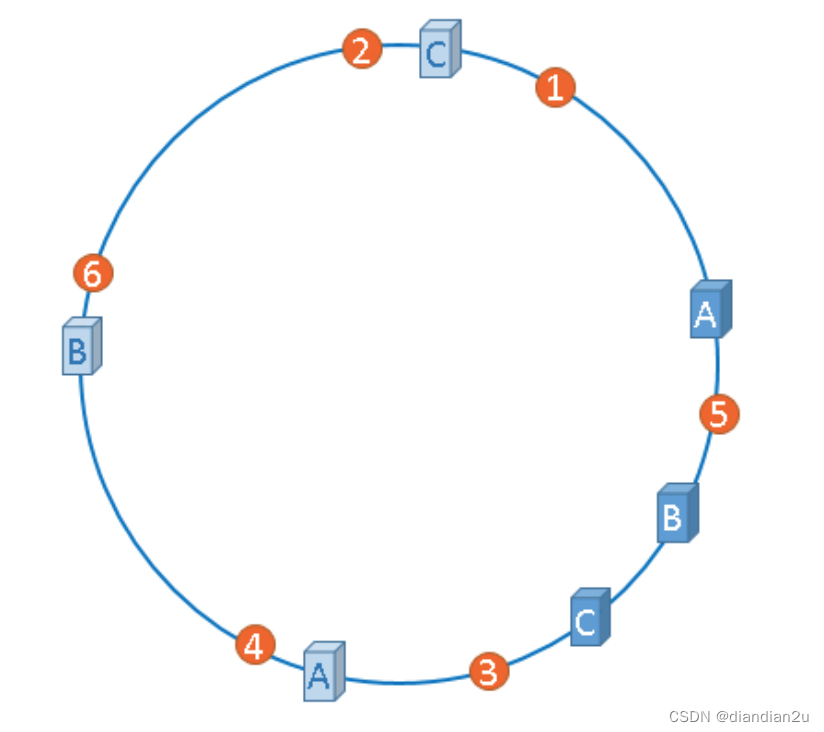
“虚拟节点"是"实际节点”(实际的物理服务器)在hash环上的复制品,一个实际节点可以对应多个虚拟节 点。
从上图可以看出,A、B、C三台服务器分别虚拟出了一个虚拟节点,当然,如果你需要,也可以虚拟出更多的虚拟节点。引入虚拟节点的概念后,缓存的分布就均衡多了,上图中,1号、3号数据被缓存在服务器A中,5号、4号数据被缓存在服务器B中,6号、2号数据被缓存在服务器C中,如果你还不放心,可以虚拟出更多的虚拟节点,以便减小hash环偏斜所带来的影响,虚拟节点越多,hash环上的节点就越 多,缓存被均匀分布的概率就越大。
客户端分区的缺点
复杂度高
客户端需要自己处理数据路由、高可用、故障转移等问题
使用分区数据的处理会变得复杂,不得不应对多个redis数据库和AOF文件,在多个实例和主机之间持久化数据。
不易扩展
普通hash,一旦节点的增或者删操作,都会导致key无法在redis命中,必须重新根据节点计算,并手动迁移全部或部分数据。
proxy端分区
在客户端和服务器端引入一个代理或代理集群,客户端将命令发送到代理上,由代理根据算法,将命令路由到相应的服务器上。常见的代理有Codis(豌豆荚,非原生)和Cluster集群。
目前Codis 不再更新了,所以就不多关注
cluster集群分区
Redis3.0之后,Redis官方提供了完整的集群解决方案。
RedisCluster方案采用去中心化的方式,包括:sharding(分区)、replication(复制)、failover(故障转移)。
Redis5.0前采用redis-trib进行集群的创建和管理,需要ruby支持
Redis5.0之后可以直接使用Redis-cli进行集群的创建和管理
架构
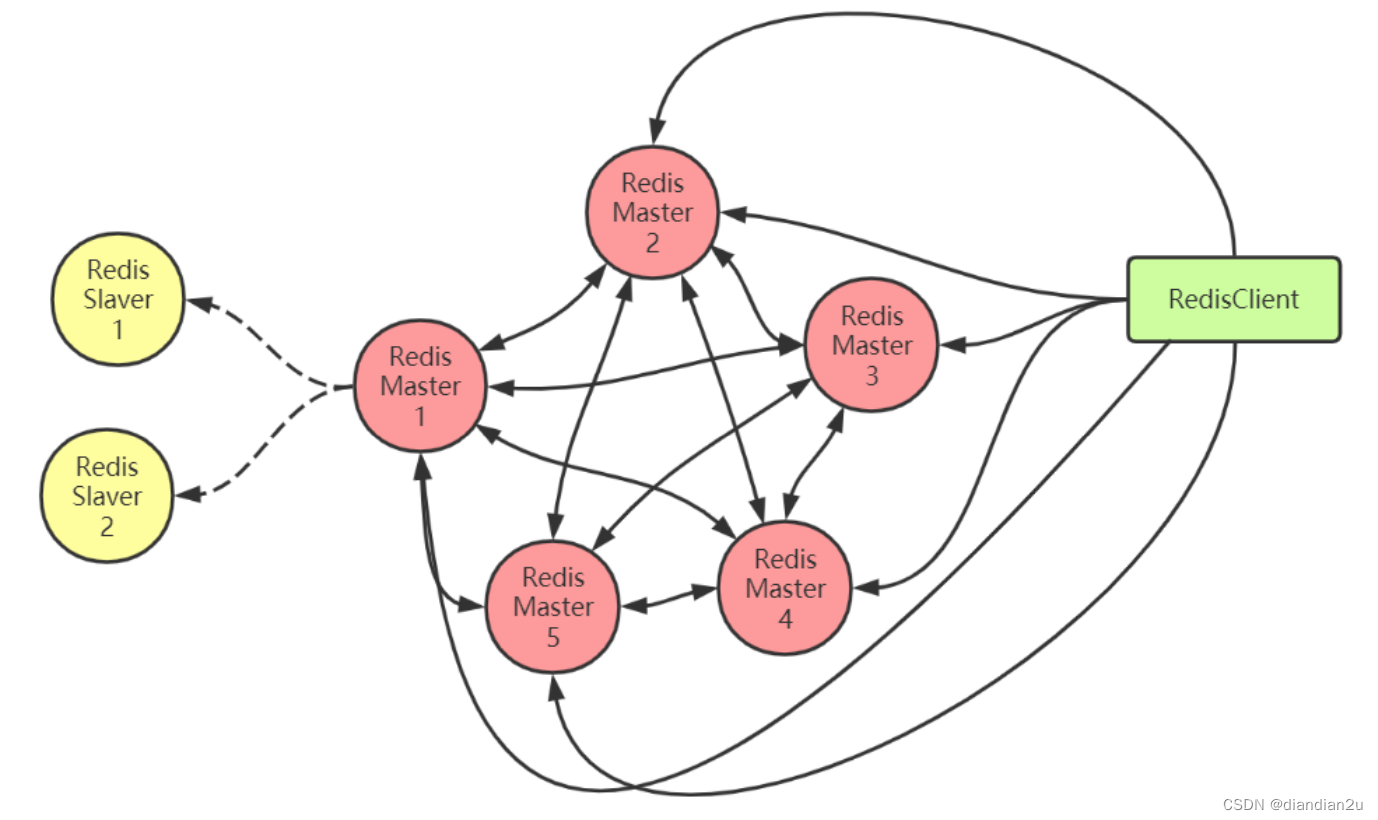
去中心化
RedisCluster由多个Redis节点构成,是一个P2P(点对点)无中心节点的集群架构,依靠Gossip协议传播的集群。
Gossip协议
Gossip协议是一个通信协议,一种传播消息的方式。起源于:病毒传播
Gossip协议基本思想就是:
一个节点周期性(每秒)随机选择一些节点,并把信息传递给这些节点。
这些收到信息的节点接下来会做同样的事情,即把这些信息传递给其他一些随机选择的节点。
信息会周期性的传递给N个目标节点,传递的动作被称为fanout(扇出)
gossip协议包含多种消息,包括meet、ping、pong、fail、publish等等。
| 命令 | 说明 |
|---|---|
| meet | sender向receiver发出,请求receiver加入sender的集群 |
| ping | 节点检测其他节点是否在线 |
| pong | receiver收到meet或ping后的回复信息;在failover后,新的Master也会广播pong |
| fail | 节点A判断节点B下线后,A节点广播B的fail信息,其他收到节点会将B节点标记为下线 |
| publish | 节点A收到publish命令,节点A执行该命令,并向集群广播publish命令,收到publish 命令的节点都会执行相同的publish命令 |
通过gossip协议,cluster可以提供集群间状态同步更新、选举自助failover等重要的集群功能。
分区槽(slot)
redis-cluster把所有的物理节点映射到[0-16383]个slot上,基本上采用平均分配和连续分配的方式。
比如上图中有5个主节点,这样在RedisCluster创建时,slot槽可按下表分配:
| 节点名称 | slot范围 | |
|---|---|---|
| Redis1 | 0-3270 | |
| Redis2 | 3271-6542 | |
| Redis3 | 6543-9814 | |
| Redis4 | 9815-13087 | |
| Redis5 | 13088-16383 |
当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
比如:
set name zhaoyun
hash(“name”)采用crc16算法,得到值:1324203551%16384=15903
根据上表15903在13088-16383之间,所以name被存储在Redis5节点。
slot槽必须在节点上连续分配,如果出现不连续的情况,则RedisCluster不能工作,详见容错。
cluster 负责维护节点和slot槽的对应关系 value------>slot-------->节点
RedisCluster的优势
-
高性能
Redis Cluster 的性能与单节点部署是同级别的。 多主节点、负载均衡、读写分离
-
高可用
Redis Cluster 支持标准的主从复制配置来保障高可用和高可靠。
failover— Redis Cluster 也实现了一个类似 Raft 的共识方式,来保障整个集群的可用性。
-
易扩展
向 Redis Cluster 中添加新节点,或者移除节点,都是透明的,不需要停机。
水平、垂直方向都非常容易扩展
数据分区,海量数据,数据存储
-
原生
部署 Redis Cluster 不需要其他的代理或者工具,而且 Redis Cluster 和单机 Redis 几乎完全兼容。
Redis集群搭建
RedisCluster最少需要三台主服务器,三台从服务器。
端口号分别为:7001~7006
mkdir redis-cluster/7001
make install PREFIX=/var/redis-cluster/7001
cp /var/redis-5.0.5/redis.conf /var/redis-cluster/7001/bin
-
第一步:创建7001实例,并编辑redis.conf文件,修改port为7001。
注意:创建实例,即拷贝单机版安装时,生成的bin目录,为7001目录。
-
第二步:修改redis.conf配置文件,打开cluster-enable yes
-
第三步:复制7001,创建7002~7006实例,注意端口修改。
cp -r /var/redis-cluster/7001/* /var/redis-cluster/7002 cp -r /var/redis-cluster/7001/* /var/redis-cluster/7003 cp -r /var/redis-cluster/7001/* /var/redis-cluster/7004 cp -r /var/redis-cluster/7001/* /var/redis-cluster/7005 cp -r /var/redis-cluster/7001/* /var/redis-cluster/7006 -
第四步:创建start.sh,启动所有的实例
cd 7001/bin ./redis-server redis.conf cd .. cd .. cd 7002/bin ./redis-server redis.conf cd .. cd .. cd 7003/bin ./redis-server redis.conf cd .. cd .. cd 7004/bin ./redis-server redis.conf cd .. cd .. cd 7005/bin ./redis-server redis.conf cd