目录
一、背景描述
检索增强生成 (RAG) 已成为一种改变游戏规则的方法,可增强大型语言模型的功能。Kotaemon 是由 Cinnamon 开发的开源项目,它站在这项创新的最前沿,提供了一个简洁、可定制且功能丰富的基于 RAG 的用户界面,用于与文档聊天。
Kotaemon 的设计兼顾了最终用户和开发人员,为文档问答 (QA) 和 RAG 管道开发提供了一个多功能平台。该项目充当一个功能齐全的 RAG UI,允许用户通过自然语言查询与他们的文档进行交互,同时为开发人员提供了一个强大的框架来构建和定制他们自己的 RAG 管道。
项目地址:GitHub - Cinnamon/kotaemon: An open-source RAG-based tool for chatting with your documents.
二、简介
Kotaemon是一个RAG UI页面,主要面向DocQA的终端用户和构建自己RAG pipeline的开发者。
2.1 终端用户
1) 提供了一个基于RAG问答的简单且最小化的UI界面
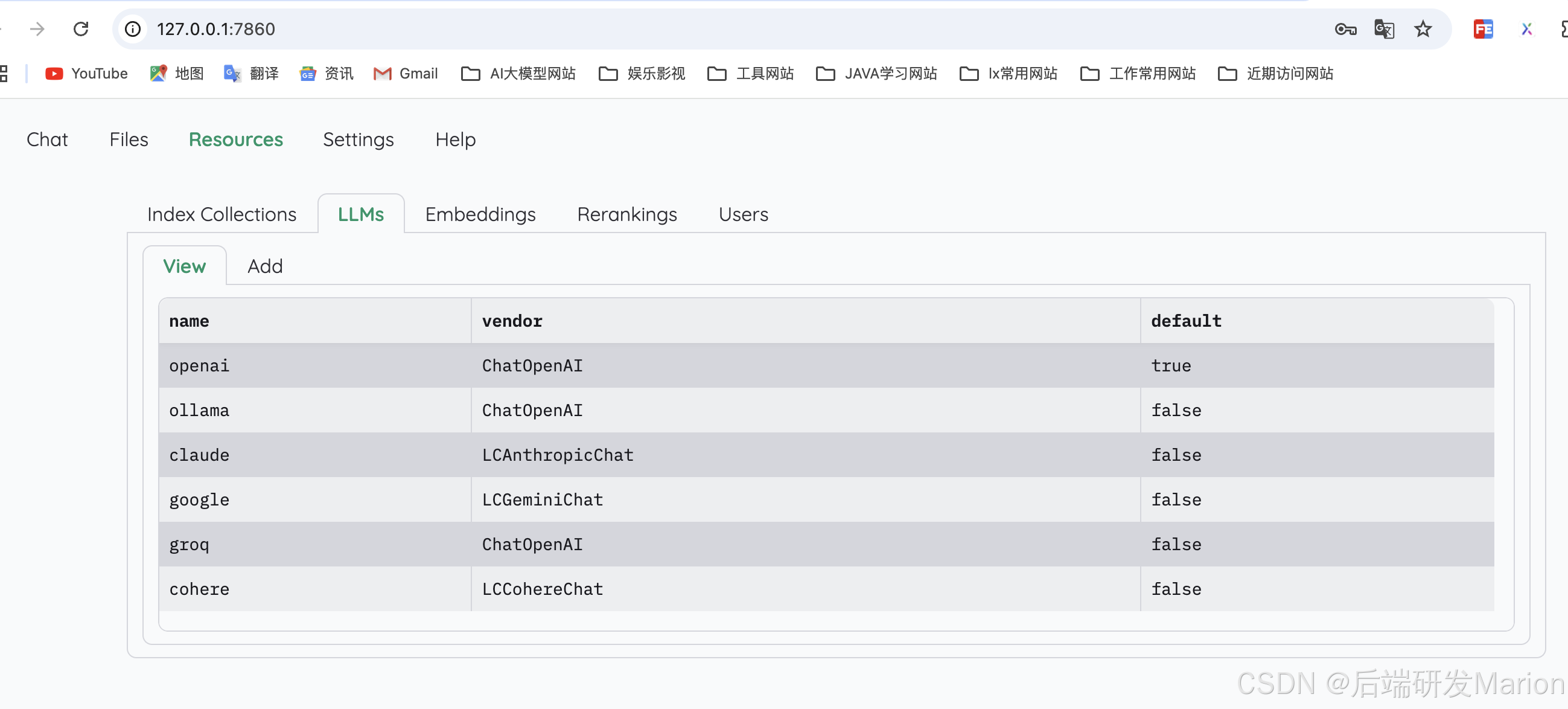
2) 支持诸多LLM API提供商(如OpenAI, Cohere)和本地部署的LLM(如ollama和llama-cpp-python)
2.2 开发者
1) 提供了一个构建RAG文档问答pipeline的框架
2) 使用Gradio开发,基于提供的UI可以自定义并查看RAG pipeline的运行过程
三、Kotaemon的主要功能
- 1) 托管自己的QA Web UI: 支持多用户登录,支持文件私有或公开,支持与他人协助分享
- 2) 管理LLM和Embedding模型: 支持本地LLM和流行的API提供商
- 3) 混合RAG pipeline: 支持全文本和向量的混合检索,以及re-ranking来保障检索质量
- 4) 支持多模态文档:支持对含有图片及表格的N多个文档进行问答,支持多模态文档解析
- 5) 带有高级引文的文档预览: 系统默认提供具体的引用信息,保障LLM回答的准确性。直接在浏览器内的PDF查阅器查看引文,并高亮显示。
- 6) 支持复杂推理方法:使用问题分解来回答复杂/多跳问题。支持使用ReAct、ReWoo及其他Agent进行推理
- 7) 可调节的设置UI:调整检索和生成过程的参数信息,包括检索过程和推理过程设置
- 简洁、极简的用户界面:Kotaemon 的一大特色是简洁、极简的用户界面。该用户界面基于 Gradio 框架构建,在简洁性和功能性之间实现了完美平衡。用户可以在深色和浅色模式之间切换,确保在各种照明条件和个人偏好下都能舒适使用。
- 多用户支持和协作:用户可以将文件组织到公共和私人收藏中,从而提供结构化的文档管理方法。此外,Kotaemon 还允许用户与他人分享聊天对话,促进团队内或跨部门的协作和知识共享。
- 高级 RAG 管道:RAG 管道采用重新排名机制,进一步优化搜索结果,向用户呈现最相关的信息。这种复杂的检索过程构成了 Kotaemon 为复杂查询提供准确且上下文感知响应的能力的基础。
- 增强的引用支持:系统对任何文档子集执行 QA,并提供来自 LLM 评委和矢量数据库的相关分数。这种评分机制可帮助用户判断所呈现信息的可靠性和相关性。此外,Kotaemon 还包含一个警告系统,当发现相关性较低的结果时会提醒用户,确保透明度并鼓励对响应进行批判性评估。
- 多模式 QA 功能:此功能在处理科学论文、技术文档或任何视觉元素在传达信息方面发挥关键作用的内容时特别有价值。Kotaemon 能够理解这些多模式元素并将其融入其 QA 流程,这使其有别于传统的纯文本 RAG 系统。
- 复杂推理方法:在处理需要复杂推理的复杂查询时,Kotaemon 表现出色。该平台提供了几种内置的“更智能的推理方法”,用户可以根据问题的性质快速切换。
- 其中一种方法是多跳 QA 的问题分解。这种方法将复杂的查询分解为更简单的子问题,使系统能够逐步解决复杂的问题。通过分解问题,Kotaemon 可以为多方面查询提供更准确、更全面的答案。
- 基于代理的推理是 Kotaemon 的另一个强大功能。该平台实现了流行的推理框架,例如 ReACT(推理和表演)和 ReWOO(对象网络推理),从而能够对用户查询做出更动态、更情境感知的响应。这些基于代理的方法允许 Kotaemon 浏览复杂的信息空间并绘制可能不会立即显现的连接。
- 对于希望突破 RAG 功能界限的用户,Kotaemon 还包括对 GraphRAG 索引的实验性支持。这种尖端技术旨在通过利用基于图形的知识表示来改进摘要响应,从而可能带来更连贯、更符合情境的答案。
- 可扩展性和定制性:Kotaemon 最大的优势之一是其可扩展性。该平台旨在成为一个灵活的基础,开发人员可以在其上构建和集成他们的自定义 RAG 管道。这种开放式架构允许快速设计原型并尝试不同的文档检索和问答方法。


四、与其他RAG开源框架的对比
4.1 Dify 和 Kotaemon 的详细对比
| 特性/指标 | Dify | Kotaemon |
|---|---|---|
| 主要功能 | 多模态对话系统,支持文本、图像、音频、视频等多种输入格式 | 智能对话管理系统,支持复杂对话的流程控制与知识库集成 |
| 对话管理能力 | - 适用于简单到中等复杂度的对话任务 | - 支持长时间的复杂对话和上下文保持 |
| - 具备基础的上下文追踪功能 | - 深入的对话管理能力,能处理多轮、多主题的对话 | |
| 多模态支持 | - 支持文本、图像、音频、视频等多种数据类型输入 | - 主要以文本输入为主,虽然可以集成多种数据源,但不是重点 |
| 知识库集成 | - 支持对话中的知识库检索,但依赖外部数据源 | - 强大的动态知识库集成能力,可以自动更新和完善知识库 |
| - 适用于处理跨模态的对话任务,如图像到文本的解释 | - 适用于技术支持类应用,能与企业现有知识库紧密结合 | |
| 系统复杂度 | - 相对简单,适合快速实现多模态交互 | - 较复杂,需要更多的系统集成与运维工作 |
| 灵活性与扩展性 | - 较高,能够适应不同类型的交互应用 | - 强大但有较高的定制化需求,适用于较为固定的知识体系 |
| 输入输出方式 | - 支持图像、音频、文本、视频等多种输入输出 | - 主要支持文本输入,输出文本较为精准,但对其他媒体格式支持较弱 |
| 系统负载与性能 | - 在处理复杂任务(如视频分析、图像识别等)时,可能会面临较高的性能瓶颈 | - 需要强大的服务器支持,尤其是动态知识库查询和多轮对话管理 |
| 计算资源需求 | - 相对中等,尤其是多模态处理时资源消耗较大 | - 较高,支持知识库管理和复杂对话场景时需要强大的计算资源 |
| 适用场景 | - 跨领域应用:智能客服、虚拟助手、产品推荐等多模态任务 | - 长期对话支持:技术支持、教育培训、IT服务、复杂产品支持等 |
| 知识库类型 | - 主要依赖外部静态知识库,适合较简单的信息查询 | - 动态知识库,支持实时信息更新,能应对复杂的技术和流程信息 |
| 企业级应用 | - 快速部署和原型开发,适合小型企业或快速迭代的项目 | - 适合需要高精度对话和大规模用户交互的中大型企业 |
| API 和集成能力 | - 提供丰富的API接口,支持第三方工具和服务的集成 | - 需要定制化集成,能够和现有企业级系统如ERP、CRM集成 |
| 学习曲线 | - 较低,适合快速上手和部署 | - 较高,需要一定的开发团队支持,适合有技术积累的企业 |
| 可定制化 | - 高度定制化,可以根据企业需求修改和扩展功能 | - 需要较多的开发和定制,但能精确满足企业的具体需求 |
| 部署与维护 | - 快速部署,基础维护需求较低 | - 需要较高的维护成本,适用于有专门运维团队的企业 |
Dify 适合的企业场景:
1. 适用于多模态任务的跨领域应用:
- 如果您的企业需要处理文本、图像、视频、音频等多种输入类型,并且希望这些不同类型的数据能够在同一个系统中交互,Dify 是一个很好的选择。例如,电商平台的虚拟助手可以通过图像识别帮助用户选择商品,视频通话中也可以通过AI助手提供相关支持。
2. 快速原型开发与部署:
- Dify 在构建多模态对话系统时,不仅支持多种输入方式,还能帮助企业快速部署和开发,尤其适合初创企业或快速测试原型的场景。例如,初期的智能客服系统能够较快上线并进行多模态交互。
3. 对话任务简单至中等复杂:
- Dify 适合处理常见的FAQ、在线咨询、产品推荐等任务。对于一个较为简单的客户支持系统,Dify 提供了足够的功能,而其支持图像、视频等输入的能力,让这些系统更加智能化。
4. 无需深入定制的系统:
- 如果您的企业并不依赖复杂的技术支持或定制化的对话管理功能,Dify 的简单易用和较低的维护成本是非常有优势的。对于初期的系统搭建,Dify 可以满足大多数企业的需求。
Kotaemon 适合的企业场景:
1. 长期且复杂的对话管理:
- Kotaemon 特别适合企业需要处理长时间、复杂的对话过程,比如技术支持、IT服务、客户服务等行业。这些场景中,客户与企业的对话通常涉及多轮、多话题的深入讨论,Kotaemon 能够提供精细的对话管理,确保每一轮对话的上下文和逻辑关联得当。
2. 集成企业知识库:
- 如果企业的运作依赖于大量的专业知识和复杂的文档资料,Kotaemon 可以与企业的知识库深度集成,自动提取和更新知识,支持实时查询。这对于需要动态更新信息的技术支持、产品维护等场景非常重要。
3. 高度定制化的需求:
- Kotaemon 能够根据企业的具体需求进行定制,特别适合那些需要高度定制化工作流的企业。例如,某些企业可能需要特别复杂的业务流程或需要与内部系统(如CRM、ERP等)进行深度集成,Kotaemon 提供了这样的灵活性。
4. 长期支持与复杂系统集成:
- 如果企业的需求是要通过 AI 提供多轮、高质量的客户支持,且希望将该系统与现有的企业级系统集成(如ERP、CRM系统),Kotaemon 的系统设计能够很好地适配这种复杂需求。
5. 高资源需求和持续优化:
- 如果企业准备投入大量资源在系统的精细化和优化上,Kotaemon 是一个长期投入、持续优化的理想选择。它的知识库管理和对话上下文处理非常适合大规模用户的支持和复杂业务场景。
总结:
-
Dify 更加适合中小企业,尤其是需要快速开发和部署多模态交互系统的场景。它的优点在于支持多种输入格式,适合处理简单到中等复杂度的对话任务。适合那些不需要深入的对话管理和定制化的企业,特别是需要多媒体交互的环境。
-
Kotaemon 更加适合需要精确对话管理和强大知识库集成的企业,尤其是在技术支持和复杂服务场景中。它适合大中型企业,尤其是那些对系统定制化、复杂业务流程和高性能要求较高的场景。
最终的选型应依据企业的规模、资源、业务复杂度以及对对话系统的需求来决定。
五、安装与部署
5.1终端用户
- 可在github的release页面下载最新的kotaemon-app.zip,并解压缩
- 进入scripts,根据系统安装,如windows系统双击run_windows.bat,linux系统bash run_linux.sh
- 安装后,程序要求启动ketem的UI,回答”继续”
- 如果启动,会自动在浏览器中打开,默认账户名和密码是admin/admin
5.2开发者
5.2.1 使用Docker安装推荐
# 运行
docker run -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:latest
# 访问ui地址:http://localhost:7860/5.2.2 源码安装
# 创建虚拟环境
conda create -n kotaemon python=3.10
conda activate kotaemon
# 下载源码
git clone https://github.com/Cinnamon/kotaemon
cd kotaemon
# 安装依赖
pip install -i https://mirrors.aliyun.com/pypi/simple/ -e "libs/kotaemon[all]"
pip install -i https://mirrors.aliyun.com/pypi/simple/ -e "libs/ktem"
# 更新环境变量文件.env,如API key
# (可选) 如果想浏览器内部展示PDF,可以下载PDF_JS viewer,解压到libs/ktem/ktem/assets/prebuilt目录
# 开启web服务,并使用admin/admin登录
python app.py
部署大约5分钟
pip install -i https://mirrors.aliyun.com/pypi/simple/ -e "libs/kotaemon[all]"
pip install -i https://mirrors.aliyun.com/pypi/simple/ -e "libs/ktem"


5.2.3 应用定制
应用数据默认保存在./ktem_app_data文件,如果想要迁移到新机器,只需将该文件夹拷贝即可。
为了高级用户或特殊用途,可以自定义.env和flowsetting.py文件
(1) flowsetting.py设置
# 设置文档存储引擎(该引擎支持全文检索)
KH_DOCSTORE=(Elasticsearch | LanceDB | SimpleFileDocumentStore)
# 设置向量存储引擎(支持向量检索)
KH_VECTORSTORE=(ChromaDB | LanceDB | InMemory)
# 是否启用多模态QA
KH_REASONINGS_USE_MULTIMODAL=True
# 添加新的推理pipeline或修改已有的
KH_REASONINGS = [
"ktem.reasoning.simple.FullQAPipeline",
"ktem.reasoning.simple.FullDecomposeQAPipeline",
"ktem.reasoning.react.ReactAgentPipeline",
"ktem.reasoning.rewoo.RewooAgentPipeline",
]
)(2) .env设置
该文件提供另一种方式来设置模型和凭据。
# 可以设置OpenAI的连接
OPENAI_API_BASE=https://api.openai.com/v1
OPENAI_API_KEY=<your OpenAI API key here>
OPENAI_CHAT_MODEL=gpt-3.5-turbo
OPENAI_EMBEDDINGS_MODEL=text-embedding-ada-0025.2.4 设置本地LLM及Embedding模型
(1) 推荐Ollama OpenAI兼容的服务
#安装ollama并启动程序,可参考https://github.com/ollama/ollama
#拉取模型
ollama pull llama3.1:8b
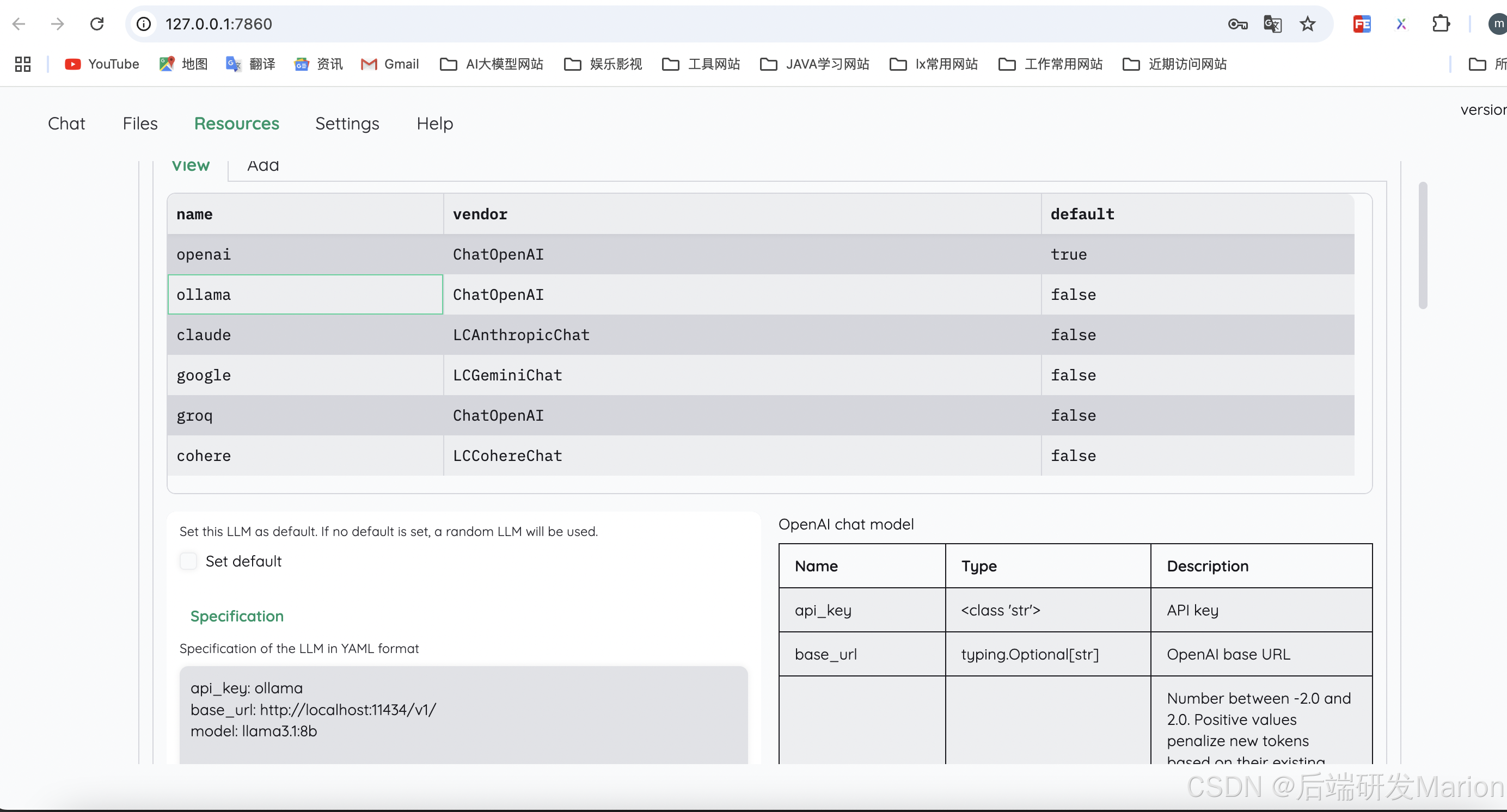
ollama pull nomic-embed-text(2) 在Resources页面中的LLMs和Embedding分别设置LLM和Embedding
api_key: ollama
base_url: http://localhost:11434/v1/
model: llama3.1:8b (for llm) | nomic-embed-text (for embedding)
(3)使用本地模型用于RAG
1) 将本地LLM和Embedding模型设置为default
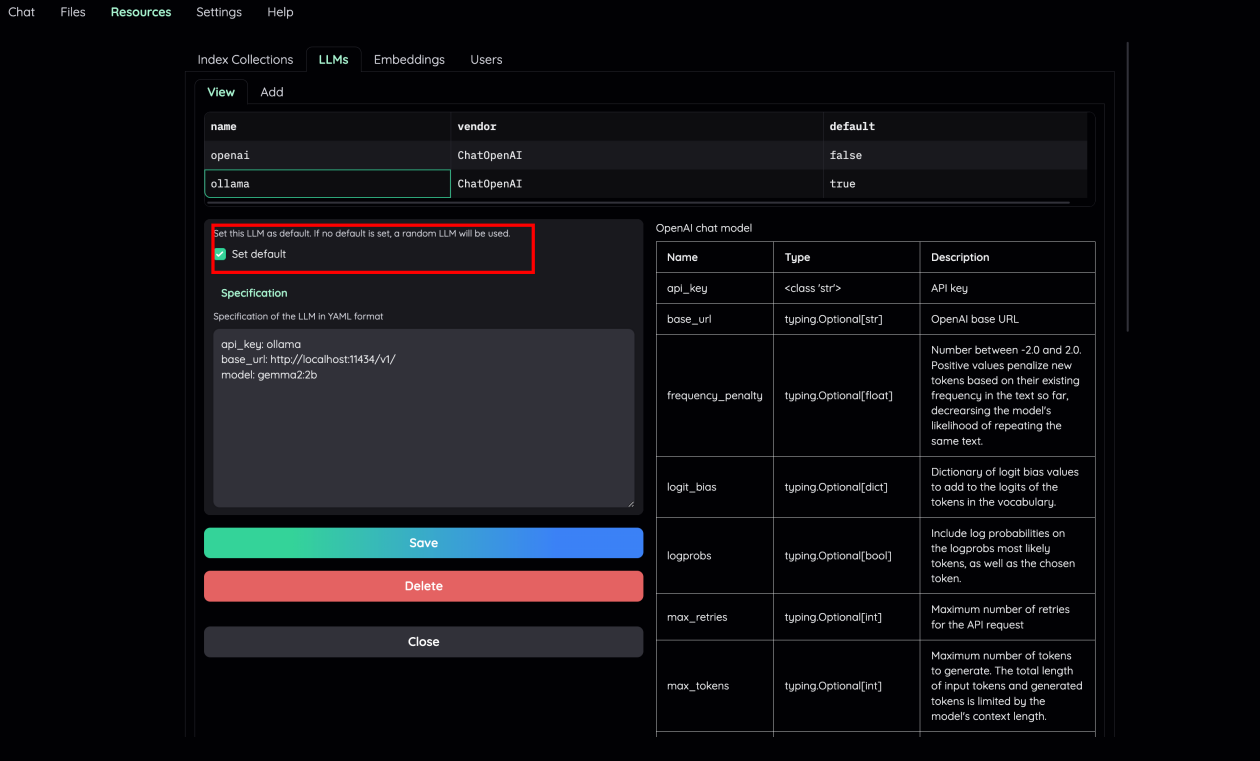
2) 将File Collection中的Embedding设置为本地模型(例如: ollama)

3) 在Retrieval Setting页面,选择本地模型作为LLM相关得分模型。如果你的机器无法同时处理大量的LLM并行请求,可以不选中”Use LLM relevant scoring”

4) 现在就可以上传文件进行文档问答体验了。
六、效果展示
本qiang~采用源码安装部署,使用openai的LLM模型gpt-4o-mini和Embedding模型text-embedding-3-small(如何使用免费版本的openai进行api体验,可以私信联系~)。其次,使用MindSearch的论文进行测试验证。
6.1 构建文档索引信息
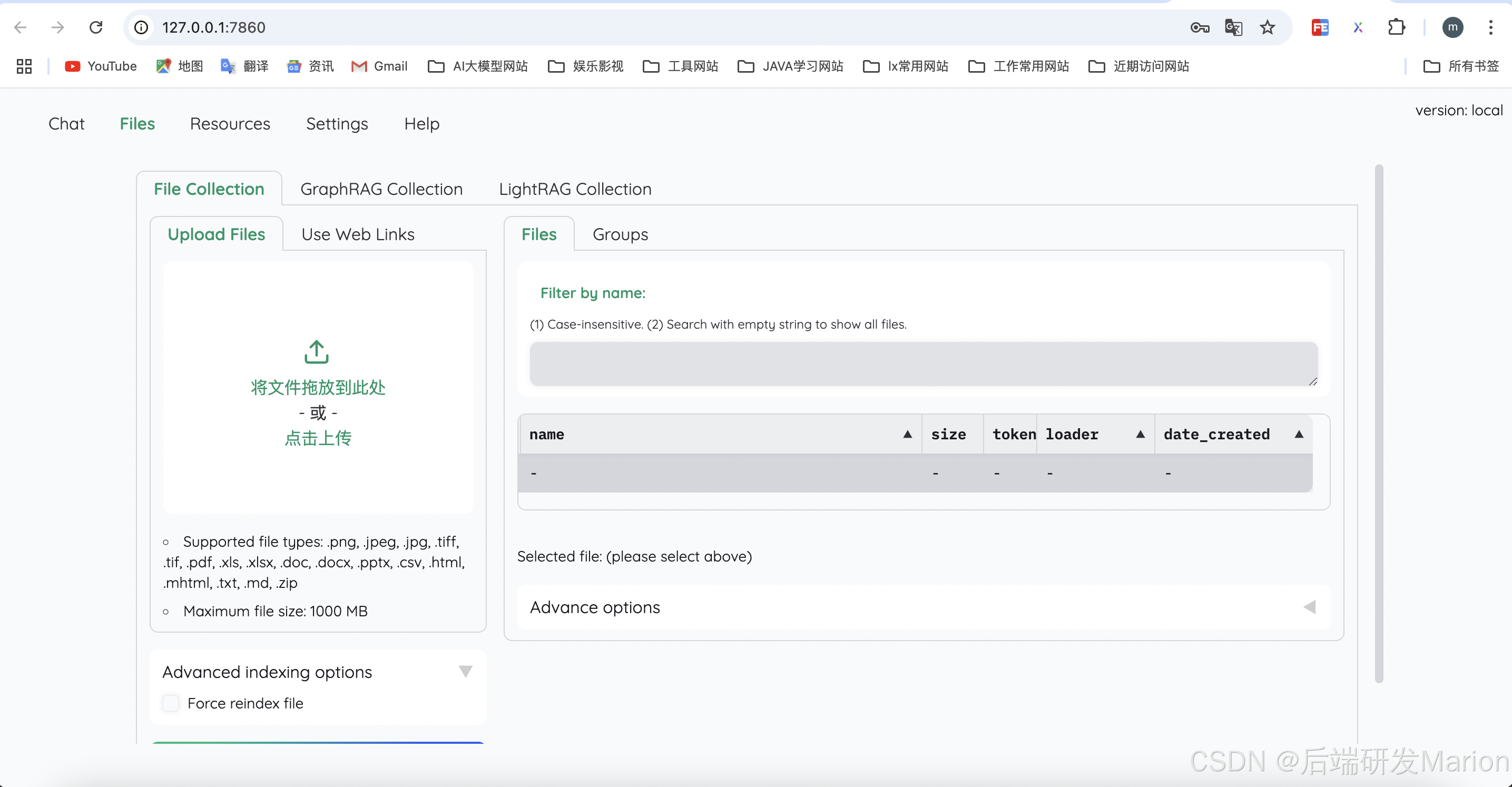
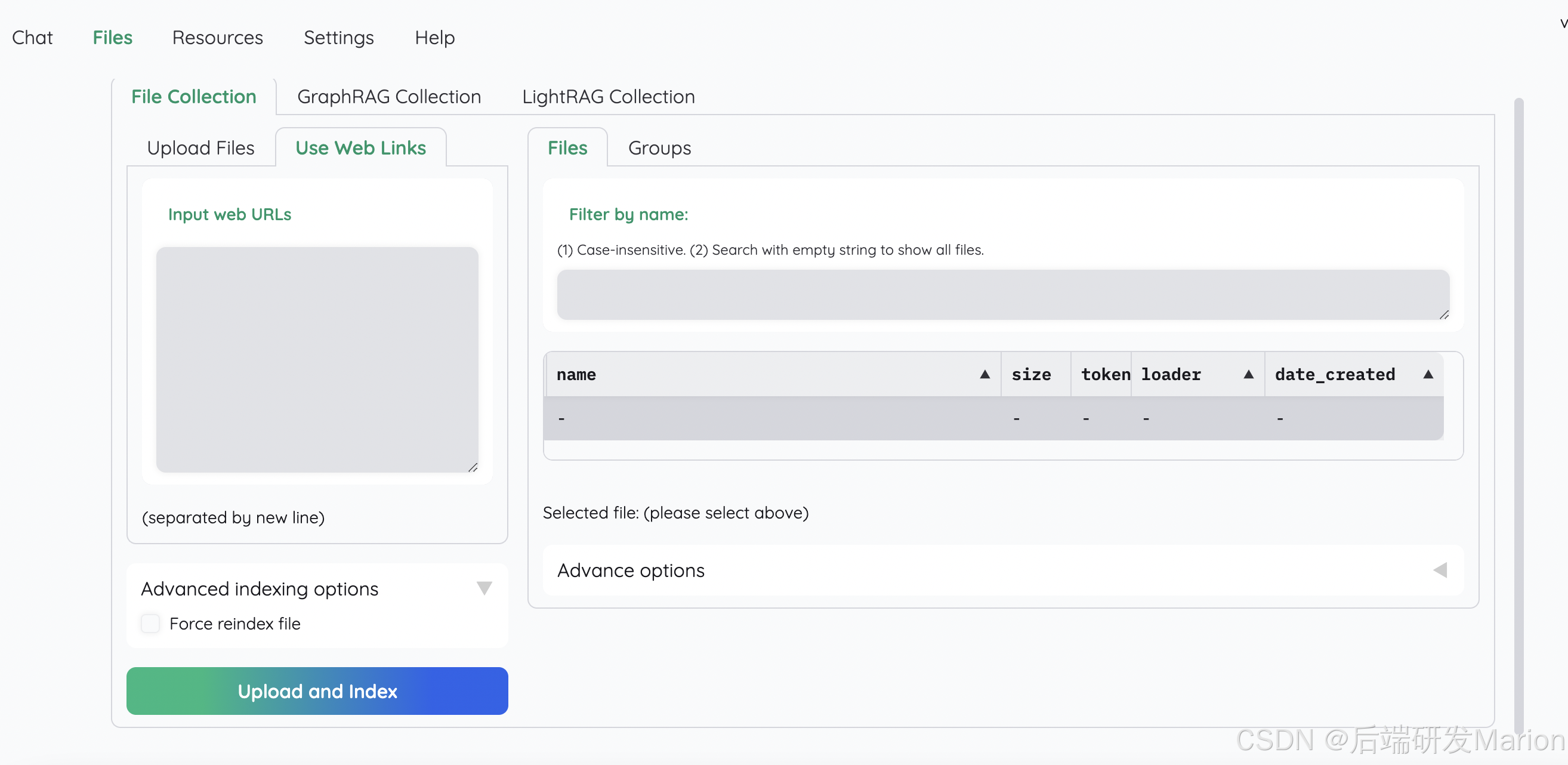
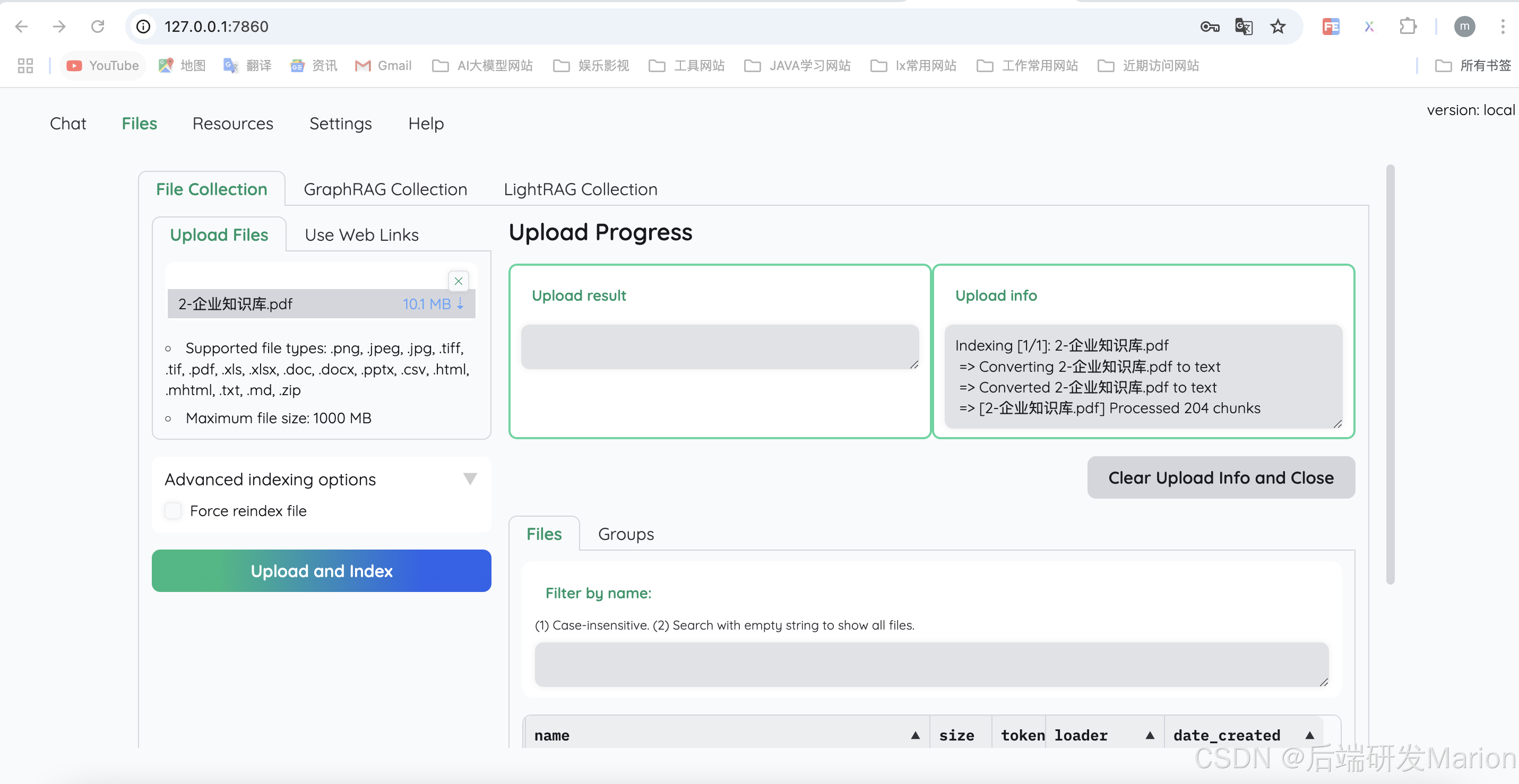
6.1.1 上传文档

6.1.2 使用simple推理策略
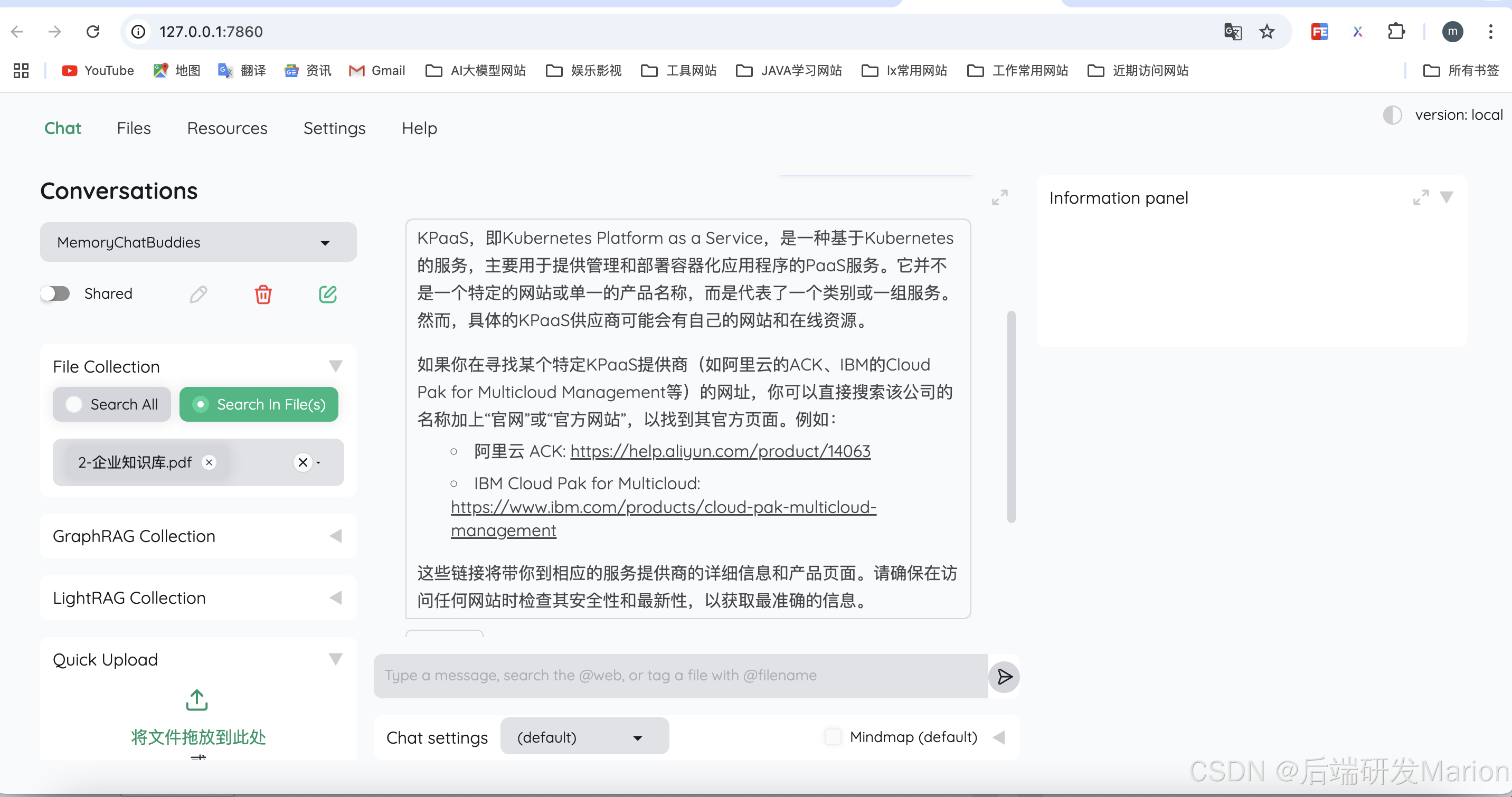
simple推理策略对应的flowsettings.py中的FullQAPipeline。问题: “what are the components of MindSearch?”,效果如下:

6.1.3 使用complex推理策略
complex推理策略对应的flowsettings.py中的FullDecomposeQAPipeline,即将复杂问题拆分为简单子问题。问题: “Please describe the performance of MindSearch on both open-source and closed-source datasets.?”

6.1.4 使用react推理策略
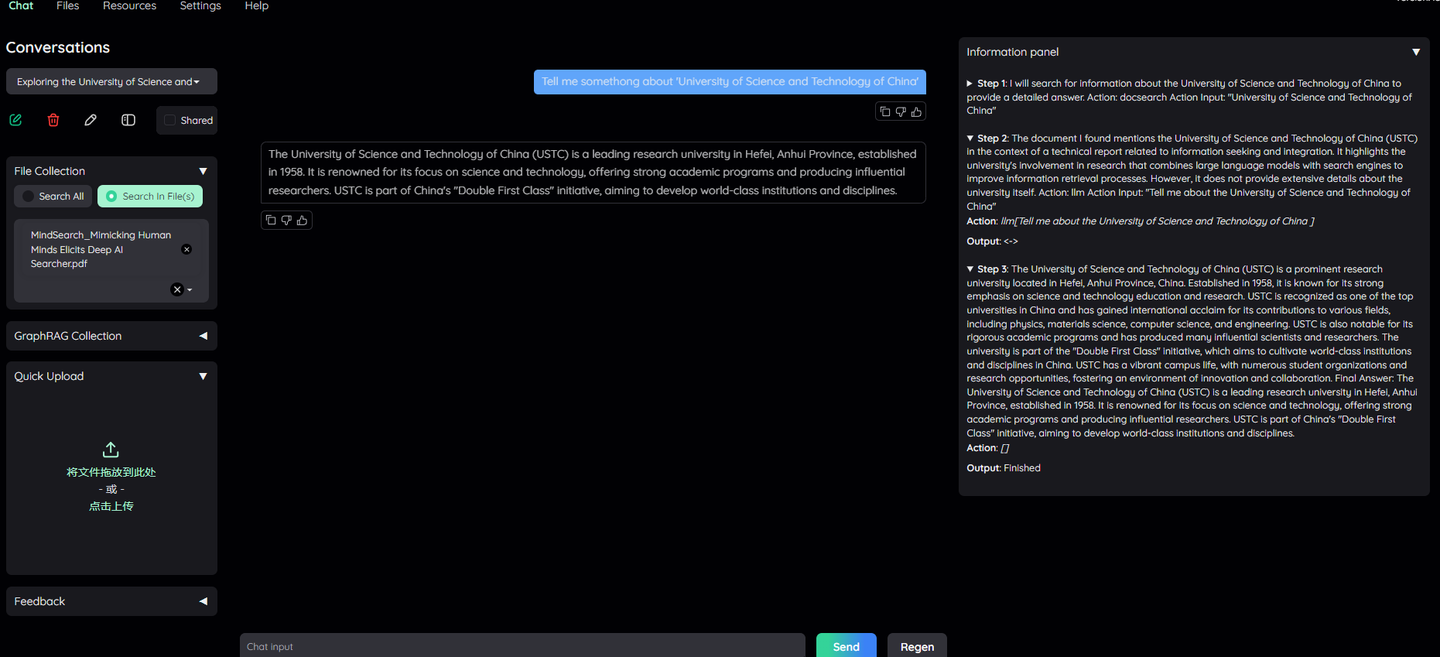
React是一种RAG Agent技术,将用户的问题进行计划设计,并迭代循环执行,满足特定结束调节。React可以结合工具进行调用,如搜索引擎、Wiki百科等。问题:”Tell me somethong about 'University of Science and Technology of China'”
6.1.5 使用ReWoo推理策略
ReWoo也是一种RAG Agent技术,第一阶段制订分步计划,第二阶段解决每个分步,也可以使用工具帮助推理过程,完成所有阶段后,ReWoo将总结答案。问题:”Tell me somethong about 'University of Science and Technology of China' and 'shanghai ai Laboratory '”

6.2 构建GraphRAG索引信息
Kotaemon集成了微软此前开源的GraphRAG框架,该框架包含图谱及索引构建、图谱检索等步骤。问题: “the author’s of this paper”

七、应用场景
Kotaemon可以用在很多领域,例如:
- 研究和学术:研究人员可以使用 Kotaemon 快速查询大量学术论文,提取相关信息并生成具有准确引文的摘要。
- 法律和合规:律师事务所和合规部门可以利用 Kotaemon 搜索大量法律文件、合同和法规,轻松找到相关条款和先例。
- 技术文档:软件公司可以实施 Kotaemon 来创建智能聊天机器人,帮助用户浏览复杂的技术文档,为特定查询提供准确的答案。
- 客户支持:企业可以通过使用 Kotaemon 构建可以用自然语言查询的知识库来增强客户支持,为客户查询提供快速准确的响应。
- 医学研究:医疗保健专业人员可以使用 Kotaemon 随时了解最新的医学研究,快速查找相关研究并从大量医学文献中提取关键发现。
- 财务分析:分析师可以使用 Kotaemon 筛选财务报告、新闻文章和市场数据,从而产生见解并回答有关市场趋势和公司业绩的复杂问题。
八、源码解读

Kotaemon 揭秘:RAG 文档 QA 框架的创新_kotaemon rag-CSDN博客
九、总结
本文主要针对开源文档问答系统Kotaemon的介绍,包括主要功能特点,与传统文档RAG的区别,部署教程以及效果体验等。
目前Kotaemon针对中文语言支持不友好,但既然可以通过ollama进行部署LLM和Embedding模型,因此支持中文语言也是相对容易开发集成的。
Kotaemon 是一款功能强大的基于文档的 QA 和推理工具,提供出色的功能,例如支持云和本地 LLM、多模式文档解析、GraphRAG 和基于代理的推理。这些功能对于需要深入的、以文档为中心的 AI 应用程序的组织来说非常有价值。
分析这个项目让我有了以下见解。
- 文档解析:虽然 Kotaemon 支持多种文档类型,但处理复杂图像、图形或高分辨率 PDF 等非结构化数据仍然具有挑战性。未来在集成高级模型或外部处理步骤方面的改进可以增强其从此类数据源中提取有意义信息的能力。
- GraphRAG 的潜力:GraphRAG 的集成是一项突出的功能,允许对实体和关系进行更结构化的推理。这种方法可以显著提升系统的知识密集型查询的性能。该领域的进一步发展可能会使 kotaemon 成为复杂文档推理任务的前沿工具。
- 性能优化:性能是潜在改进的领域之一。增强索引过程并实施更高效的查询优化方法可以提高响应质量。
- 现实世界的影响:虽然该项目在 GitHub 上越来越受欢迎,表明人们对此很感兴趣,但其真正的价值在于其技术方面如何有助于解决各个行业的实际问题。通过专注于优化和可扩展性,kotaemon 有可能成为依赖基于文档的 AI 应用程序的组织的首选工具。
参考资料
Kotaemon 揭秘:RAG 文档 QA 框架的创新_kotaemon rag-CSDN博客
LLM应用实战: 文档问答系统Kotaemon-1. 简介及部署实践 - 知乎
GitHub - Cinnamon/kotaemon: An open-source RAG-based tool for chatting with your documents.