—0—
RAG 简介
RAG(Retrieval Augmented Generation)结合知识库检索与大模型回答,确保信息可靠且精准,同时节省了微调成本。
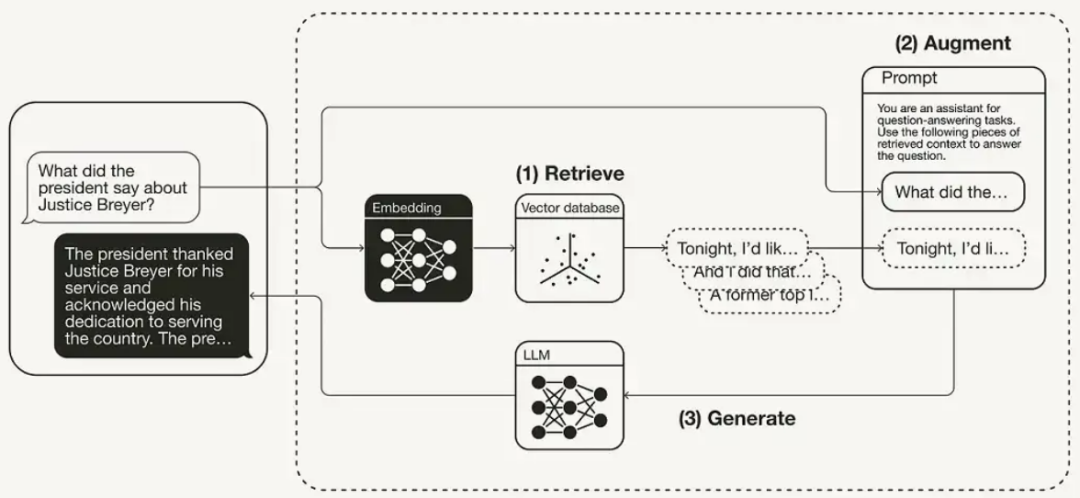
RAG 流程简要概括为3步,对应其名:
1、检索:借助 Embedding,将问题转化为向量,比对知识库,选取最相关的 Top K 知识。
2、增强:结合检索出的上下文和问题,构造 Prompt。
3. 生成:将 Prompt 输入大模型,产出答案。
从工程视角划分,RAG 实施分为两阶段:
阶段一:离线数据预处理:涵盖知识文件导入、文本切分、向量构建及数据库存储,完成知识的索引构建。
阶段二、在线应用推理执行:实时执行信息检索与大模型内容生成任务,实现交互式问答流程。
—1—
数据准备阶段的挑战一
挑战一:文本划分不当,影响检索内容的精确度与全面性。
文本块的划分尺寸直接关系到查询时与用户提问的贴合度:过小的区块可能无法涵盖问题所有相关内容;反之,过大则易引入冗余信息。
当前多种文本切分策略存在,但理想的切分方法需贴合特定领域文档特性,考虑因素包括文件格式、作者书写习惯及表述模式等。因此,选取最合适的切块策略需依据具体情况,并可能针对文档的不同类别采取定制化处理。核心在于确保分割逻辑遵循语义完整性,以实现内容的有效组织。
—2—
数据检索阶段的挑战二
挑战二:尽管向量检索作为主流方法依赖于相似度评估,但它亦面临多方面局限。
1、语义理解偏差:向量表示偶尔难以区分近义概念的细微差异,可能引起误解。
2、维度考量失衡:如余弦相似度侧重向量方向而非其规模,可能导致虽方向相近但在意义层面相去甚远的匹配。
3、信息粒度不协调:用户查询的精确向量可能指向具体信息点,而数据库条目若是宽泛主题,则检索结果易过度泛化。
4、上下文匹配不足:现有向量搜索技术偏向整体相似性判断,可能忽略局部或特定上下文中的更高相似度信息。
5、稀疏数据检索难:在大规模知识库中定位关键片段尤为困难,特别是当所需信息零散分布于多文档时,此挑战更为显著。
—3—
数据检索阶段的挑战三
挑战三:多个检索结果排名和优先级不合适,导致大模型的回答没有抓住重点。
准确评估并排序多个检索片段对于生成高质量回答极为关键,此过程需精密平衡各段落的相关性和重要性。这不仅考验着排序算法的有效性,还隐含了对领域知识深入理解的需求,以便在信息筛选与排序阶段实现智能化决策。
—4—
大模型生成阶段的挑战四
挑战四:提升 Prompt 设计以引导大模型依据既有知识库与提示词,输出更佳答案是一项重大任务。
Prompt 创作远超于问题与检索材料的直接整合,它要求根据生成模型的独特性,采取定制化的表述策略与附加指导。为了约束大模型潜在的泛化偏差,确立一个恒定的“角色框架”显得尤为关键,比如:明确指示大模型“扮演该领域的权威学者”,或“仅限于利用提问与关联素材进行精要概述与总结”,从而在各种情境下维持回答的精准度与相关性。
—5—
大模型生成阶段的挑战五
挑战五:确保大模型回应的连贯性与一致性,面临的信息整合难题尤为突出。
大模型需面对的挑战在于,整合源自多样文献的知识碎片,以及用户提问中多关键词触发的多样化内容。在此基础上,大模型必须展现出高度的整合能力,使得最终的输出结果不仅在逻辑链条上紧密相连,而且在观点与事实的呈现上保持高度一致,这一过程对大模型的综合推理与衔接能力提出了严峻考验。
—6—
大模型生成阶段的挑战六
挑战六:大模型如何更好地理解领域知识片段。
各个大模型在掌握特定领域知识及专业术语的深度不一,致使它们在解析检索到的信息及构造反馈时展现出差异性。缩小这一差距的关键,在于实施针对性的微调策略,旨在强化大模型对该领域的语言理解力及内容生成的精准度,从而促进其更深层次地融入与适应专业话语体系。
—7—
知识准备阶段的挑战七
挑战七:优化 RAG 的瓶颈:确保高效且可靠的问答对供给。
在追求 RAG 系统性能巅峰的过程中,大量高质量的问答对用作调优数据显得至关重要。尽管广泛认同丰富 QA 对的积累能极大促进调优效果,但手动创建这些资源无疑是一项耗时巨大的工程,而依赖自动化生成则可能牺牲内容的可靠性。因此,探索一种既能保证效率又能维护准确性的 QA 对生成机制,成为决定 RAG 系统最终成效的核心挑战。
—8—
意图识别阶段的挑战八
挑战八: 界定合理拒答的微妙平衡 。
面对用户提问,尤其当问题超越了现有文献资料范畴时,恰当时机的拒答成为一大考验。应当在无法给予确切信息时勇于说“不知道”,以免提供错误引导。实践中,虽常借助相似度阈值或场景语料库作为判断标尺,却依然难以实现百分之百的精准。过于频繁的拒答可能导致用户体验冷漠,而过度猜测回答又可能损害系统信誉。因此,拿捏拒答的恰当火候,成为维护问答系统信誉与用户信任的关键。
—9—
多模态 RAG 的挑战九
挑战九: 多模态的支持是必然趋势 。
在多模态 RAG 的研究中,针对不同的模态,包括:图像、代码、结构化知识、音频和视频,有不同的检索和合成程序、目标任务和挑战。比如:通过图像检索扩展文本生成的上下文,利用样例代码和相关文档增强代码生成等等。
—10—
RAG 评价的挑战十
挑战十: 科学衡量 RAG 在特定领域的实用性门槛 。
评估 RAG 在某一领域的应用成熟度,类似于采用 RAGAs 评估框架,需独立提供问题(question)与标准答案(ground_truth),这使得评估结果高度依赖于问题设计的合理性与标准答案的准确性。
此外,评估流程的复杂性—涉及大模型及嵌入模型的性能,进一步要求模型本身的稳定可靠,以及输入 Prompt 的精确无误,否则评估指标将失去可信度。因此,确保大模型与 Prompt 的质量,成为验证 RAG 应用效能的关键挑战。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;

第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓