1. 使用Hash
哈希作为Redis的一种基础数据结构,Redis底层维护的是一个开散列,会把不同的key值映射到哈希表 上,如果是遇到关键字冲突,那么就会拉出一个列表出来.
当一个用户访问时,如果用户登陆过,那么我们就使用用户的id,如果用户没有登陆过,那么也可以在前端页面随机生成一个key用来标识用户,当用户访问的时候,我们可以使用HSET命令,key可以选择URI与对应的日期进行拼凑,field则可以使用用户的id或者随机标识,value则可以简单设置为1。
当要访问一个网站某一天的访问量时,就可以直接使用HLEN来获取结果;
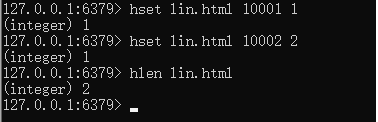
- 优点: 简单,易实现.查询方便,并且数据精准性非常好.
- 缺点: 内存占用过大.随着
key的增多,性能会随之下降.无法支撑大规模的访问量.
2. 使用Bitset
对于个int型的数来说,若用来记录id,则只能记录一个,而若转换为二进制存储,则可以表示32个,空间的利用率提升了32倍.对于海量数据的处理,这样的存储方式会节省很多内存空间.对于未登陆的用户,可以使用Hash算法,把对应的用户标识哈希为一个数字id.对于一亿个数据来说,我们也只需要1000000000/8/1024/1024大约12M空间左右.
而Redis