基础知识
1、多标签和多分类的区别
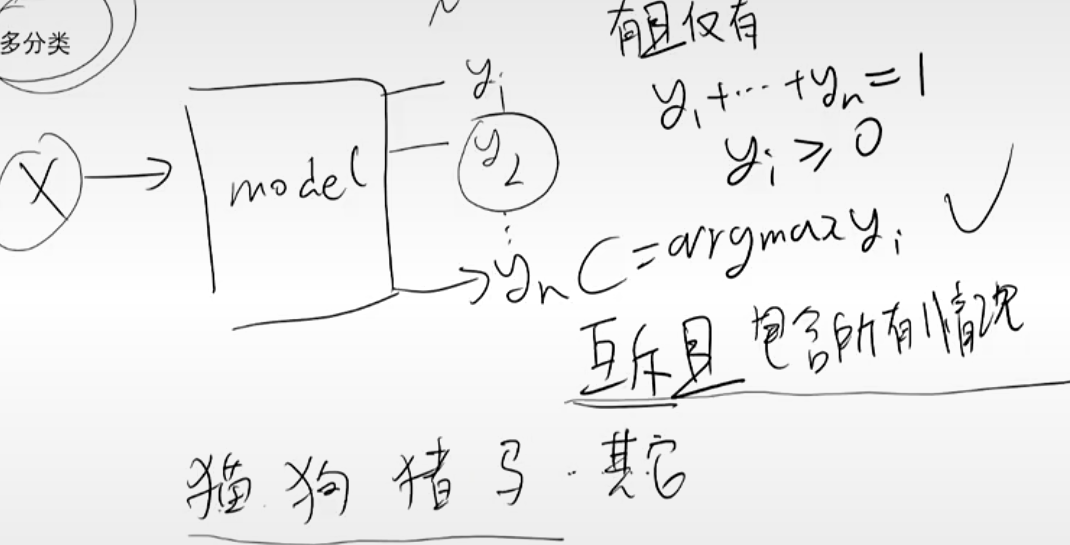
多分类
x有且仅有一个类别,输出y为属于类别的概率,最终类别为
y
i
y_i
yi最大的类别,特点为
y
i
y_i
yi互斥,且包含所有情况。
输出通常使用softmax,使
y
i
y_i
yi具有上述特点。
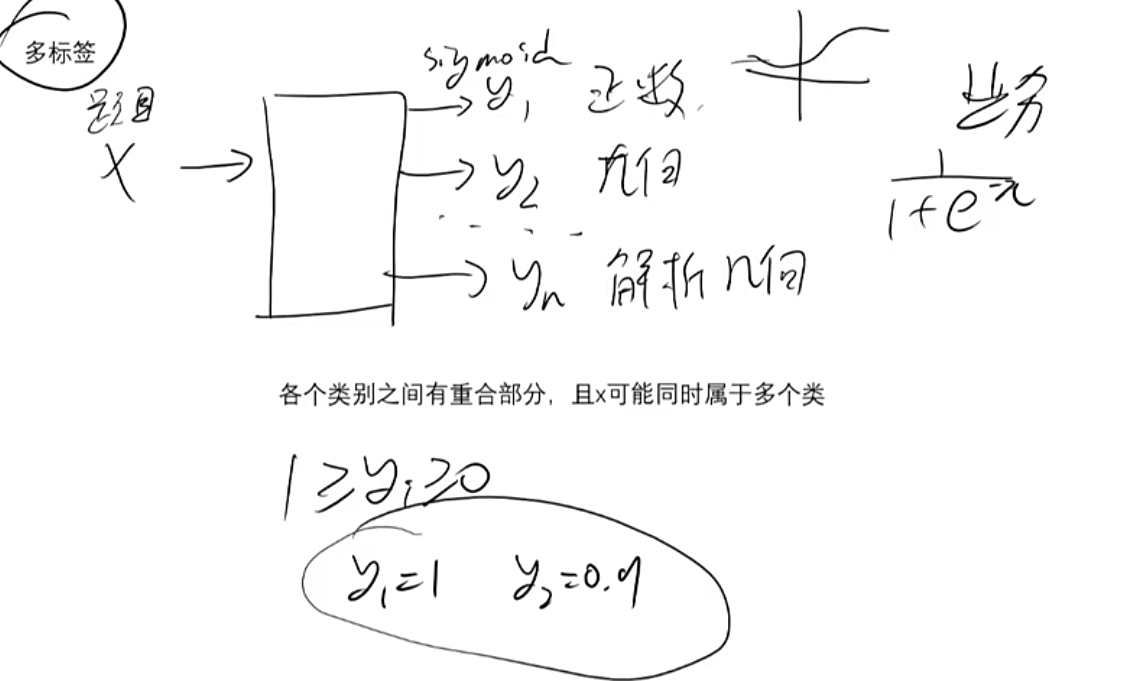
多标签
输出
y
i
y_i
yi各个类别之间有重合部分,且x可能同时属于多个类别,
1
>
=
y
i
>
=
0
1>=y_i>=0
1>=yi>=0,此时最后一层通常使用sigmoid函数。
2、在多分类中什么情况需要负采样,以及负采样方法
存在的问题:

- 类别过多,比如推荐系统中,预测类别y_i会很多,会导致上述运算量很大
基础知识网站
温度系数
https://zhuanlan.zhihu.com/p/666670367
temperature参数控制生成语言模型中生成文本的随机性和创造性,调整模型的softmax输出层中预测词的概率;

temperature越大,则预测词的概率的方差减大,即很多词被选择的可能性增大,利于文本多样化
举例:Prompt: “The quick brown fox”
Temperature = 0.1:
“The quick brown fox jumped over the lazy dog. The quick brown fox jumped over the lazy dog. The quick brown fox jumped over the lazy dog.
Temperature = 0.5:
“The quick brown fox jumped over the lazy dog. The lazy cat was not impressed. The quick brown fox ran away.”
Temperature = 1.0:
“The quick brown fox jumped over the lazy dog. Suddenly, a flock of birds flew overhead, causing the fox to stop in its tracks. It looked up at the sky, wondering where they were going.”
温度就是调整大模型生成随机性的一个参数,温度越高,大模型在相同输入下,多次推理的结果相差越大
beam search
https://zhuanlan.zhihu.com/p/82829880
k越大,LLM输出多样性越大

复读机问题
https://blog.csdn.net/weixin_46566149/article/details/134987196
在DPO时遇到复读机问题,增加SFT loss或者lora,基本思想是和ref model更像。
https://www.linsight.cn/93328a2a.html
在DPO阶段,会用在上一轮post-training得到的最佳模型收集偏好数据对,这样能使得偏好数据的分布和强化学习时的policy model更一致。
除了DPO以外,Meta也尝试了一些on-policy的方案,如PPO。但是相对来说,DPO消耗更少的计算资源,并且效果也更好,特别是在instruction following的能力上,所以还是选择在post-training使用DPO。
DPO训练中,使用lr=1e-5,beta=0.1。
此外,训练中还做了一些不同于标准做法的改动:
1、Masking out formatting tokens in DPO loss
把特殊token比如header和termination token屏蔽,不用于计算训练loss。因为使用这些token计算loss会使得模型在生成时,出现如复读机或者在不合适的地方截断的情况。这可能就是因为chosen repsponse和rejected response同时包含的这些特殊token,让模型在训练时要同时增大和较小它们的likelihood,导致冲突。
2、Regularization with NLL loss
除了DPO的常规loss,Meta额外加入了NLL损失项,这和《Iterative reasoning preference optimization》的做法类似。这也有点像PPO里加入next token prediction loss,能使训练更加稳定,并能保持SFT学到的生成格式,并保持chosen response的log probability不下降(《Smaug: Fixing failure modes of preference optimisation with dpo-positive》)。