参考:Databricks:并购巩固AI发展,估值翻倍到430亿美元 - 知乎 (zhihu.com)
Databricks的主要竞争力在于其平台的高度整合性和先进的技术。Databricks平台能够支持多种编程语言,如Scala、Python、R等,这大大降低了用户的使用门槛。同时,其在机器学习和人工智能领域的深厚积累,使其在提供高级分析方面具有显著优势。
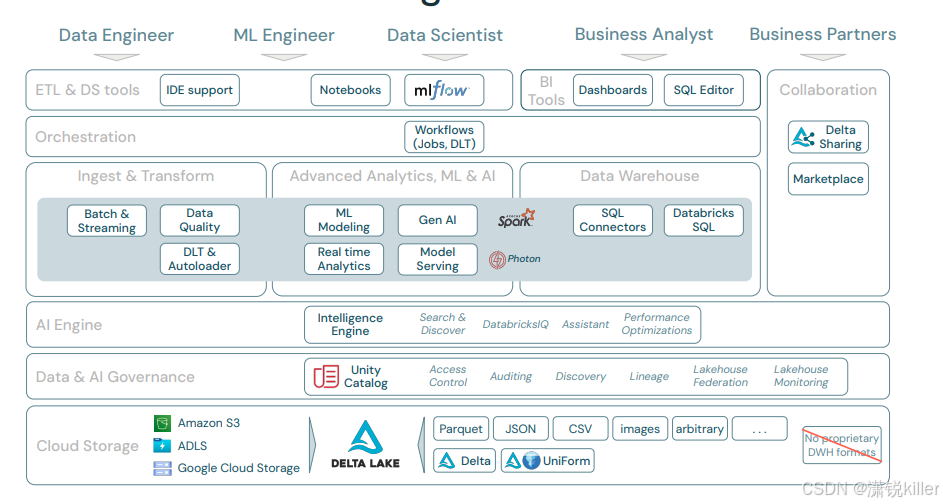
Databricks通过其云平台提供的数据分析和机器学习解决方案依托于几个核心技术和架构设计,这些设计使得企业能够从庞大且复杂的数据集中提取有价值的信息,并转化为可操作的业务洞察:
1. 统一数据分析平台(Unified Data Analytics Platform)
Databricks提供一个统一的数据分析平台,整合了数据湖、数据仓库和机器学习功能。这种统一性意味着用户可以在同一个平台上进行数据的摄取、存储、处理和分析,无需在不同的系统之间迁移数据,从而减少数据丢失和错误的可能性,并提高处理效率。
2. 基于Apache Spark的大数据处理
Databricks的平台建立在Apache Spark之上,Spark是一个开源的分布式计算系统,设计用于处理大规模数据集。Databricks优化了Spark的性能和可扩展性,使其能够快速处理PB级数据。通过Spark,Databricks能够支持批处理和实时数据处理,为机器学习和复杂的数据分析提供计算能力。
3. Lakehouse架构
Databricks推出的Lakehouse架构是数据湖和数据仓库的融合体。这种架构允许用户在同一个系统中存储结构化和非结构化数据,同时提供了传统数据仓库的管理功能和数据湖的灵活性和可扩展性。通过Lakehouse,企业可以实现高效的数据管理和先进的分析功能,如实时分析和机器学习。
4. MLflow:机器学习生命周期管理
Databricks开发了MLflow,这是一个开源平台,用于管理机器学习的整个生命周期,包括实验管理、模型训练、部署和监控。MLflow帮助数据科学家和工程师跟踪他们的实验、复制结果并管理生产模型。这种管理机器学习项目的方法提高了实验的效率和模型部署的可靠性。
5. Delta Lake
为了解决数据湖中数据质量和一致性的问题,Databricks创建了Delta Lake,一个开源的存储层,它提供ACID事务、可伸缩的元数据处理和数据版本控制。Delta Lake使得用户可以安全地读写大规模数据集,并确保数据的完整性,这对于执行复杂的数据分析和机器学习模型尤其重要。
通过这些技术原理和实现路径,Databricks帮助企业将复杂的数据转化为有价值的业务洞察,从而实现数据驱动的决策和创新。
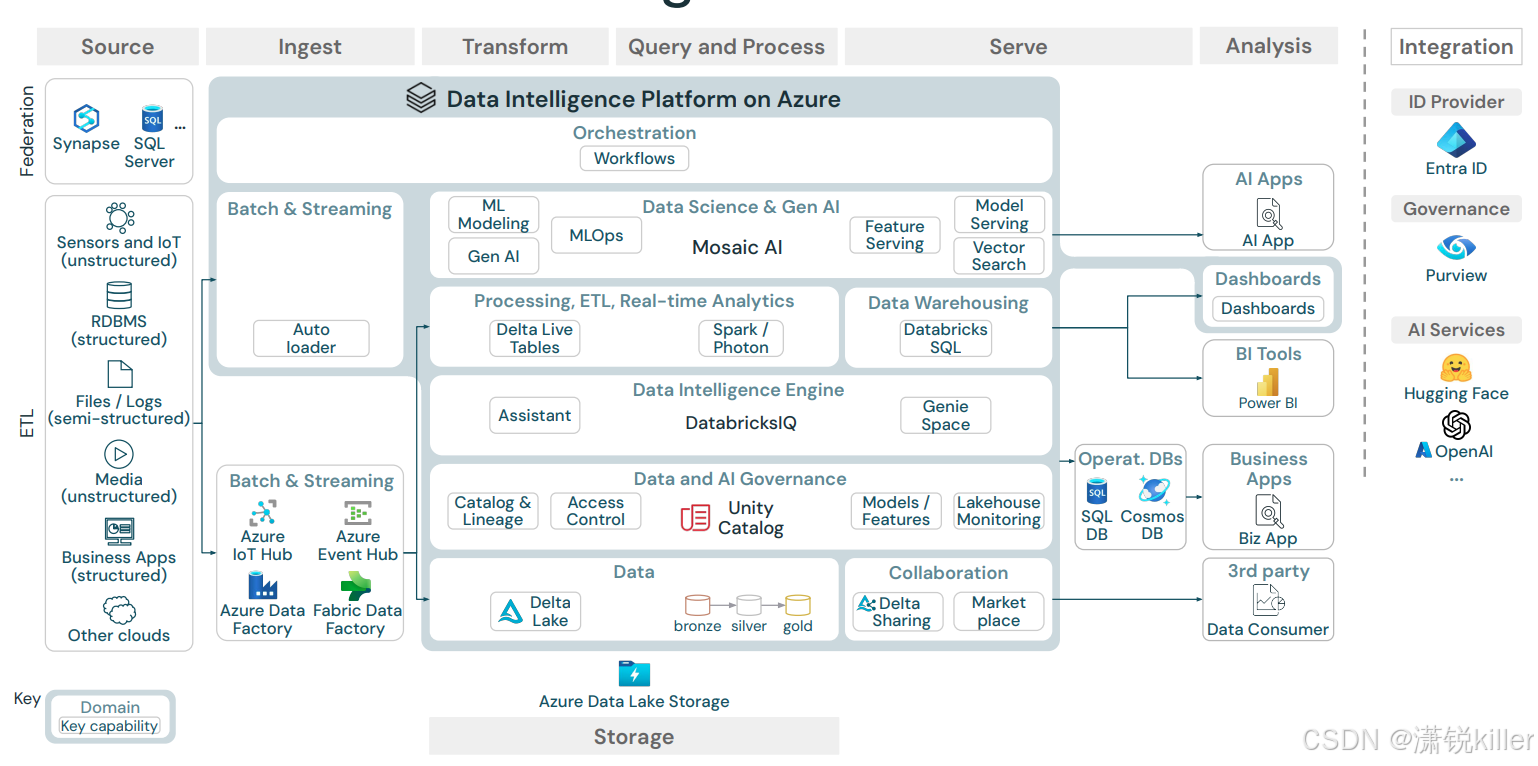
参考:https://learn.microsoft.com/zh-cn/azure/databricks/lakehouse-architecture/scope
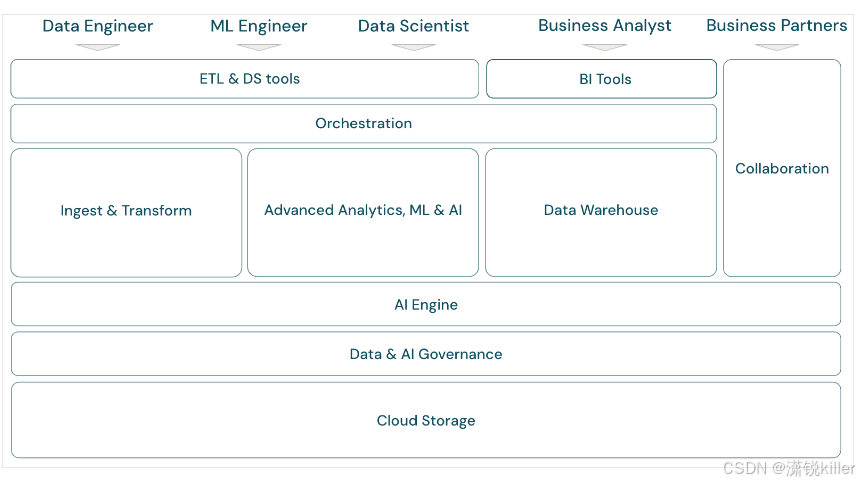
可通过以下方式将 Databricks Data Intelligence Platform 及其组件映射到框架: