NSGA-II算法
论文阅读笔记:A fast and elitist multiobjective genetic algorithm: NSGA-II
使用非支配排序和共享的多目标遗传算法几个受限点:
1.计算复杂度
O
(
M
N
3
)
O(MN^3)
O(MN3)。其中
M
M
M是目标数,
N
N
N是种群大小。
2.nonelitism approach
3.需要指定共享参数
NSGA-II减轻了上述三个问题
具体而言,NSGA-II的计算复杂度为
O
(
M
N
2
)
O(MN^2)
O(MN2)。并提出了一个选择算子
“支配的概念”
当多目标问题中多个目标存在冲突的时候,我们可以用“支配”的概念来决定解的好坏。
| Name | Height | Salary |
|---|---|---|
| A | 190 | 80K |
| B | 170 | 85K |
| C | 165 | 70K |
| D | 160 | 22K |
如上表所示,上面四个成员A,B,C和D,有两个特征:身高和工资。现在,如果我们同时比较它们的身高和薪水,我们发现这不是很直观,因为他们有多个目标。
既然这两个目标越多越好,我们可以简单地对它们进行比较。首先,我们观察到A和B都比C和D多,所以我们说A和B在身高和薪水上“支配”C和D。同理,C支配D,D可被A,B,C支配。
A和B呢?A比B高,但是工资低。相反,B面临着同样的情况。我们称这种情况为“非支配”。如果我们能找到一组解它们不互相支配,也不受其他解支配,我们称之为“帕累托最优”解。在上面的例子中,A和B都在帕累托最优前沿。
几个概念:
非支配解:假设任何二解S1及S2对所有目标而言,S1均优于S2,则我们称S1支配S2,若S1的解没有被其他解所支配,则S1称为非支配解,也称Pareto解。
支配解:若解S2的所有目标均劣于S1,则称S1优于S2,也称S1支配S2,S2为受支配解。
Pareto前沿面:找到所有Pareto解之后,这些解组成的平面叫做Pareto前沿面(Non-dominated front)。在目标函数较多时,前沿面通常为超曲面。
什么是非支配排序遗传算法
非支配遗传算法的英文名为(Non-dominated Sorting Genetic Algorithms)。NSGA在1995年由Srinivas和Deb提出。这是一种基于帕累托最优概念的遗传算法。
NSGA的基本原理
NSGA与简单的遗传算法的主要区别在于:该算法在选择算子执行之前根据个体之间的支配关系进行了分层。其选择算子、交叉算子和变异算子与简单遗传算法没有区别。
在选择操作执行之前,种群根据个体之间的支配与非支配关系进行排序:
首先,找出该种群中的所有非支配个体,并赋予他们一个共享的虚拟适应度值。得到第一个非支配最优层;
然后,忽略这组己分层的个体,对种群中的其它个体继续按照支配与非支配关系进行分层,并赋予它们一个新的虚拟适应度值,该值要小于上一层的值,对剩下的个体继续上述操作,直到种群中的所有个体都被分层。
算法根据适应度共享对虚拟适应值重新指定:
比如指定第一层个体的虚拟适应值为1,第二层个体的虚拟适应值应该相应减少,可取为0.9,依此类推。这样,可使虚拟适应值规范化。保持优良个体适应度的优势,以获得更多的复制机会,同时也维持了种群的多样性。
NSGA的算法缺陷
1.计算复杂度高
2.没有精英策略;精英策略可以加速算法的执行速度,而且也能在一定程度上确保已经找到的满意解不被丢失。
3.需要指定共享半径。
于是提出了NSGA-II,即带精英策略的非支配排序的遗传算法。
改进点:
1.提出了快速非支配排序法,降低了算法的计算复杂度。由原来的
O
(
M
N
3
)
O(MN^3)
O(MN3)降到
O
(
M
N
2
)
O(MN^2)
O(MN2),其中M为目标函数个数,N为种群大小。
2.提出了拥挤度和拥挤度比较算子,代替了需要指定共享半径的适应度共享策略,并在快速排序后的同级比较中作为胜出标准,使准Pareto域中的个体能扩展到整个Pareto域,并均匀分布,保持了种群的多样性。
3.引入精英策略,扩大采样空间。将父代种群与其产生的子代种群组合,共同竞争产生下一代种群,有利于保持父代中的优良个体进入下一代,并通过对种群中所有个体的分层存放,使得最佳个体不会丢失,迅速提高种群水平。
NSGA-II的基本原理
快速非支配排序法
NSGA-II对NSGA中的非支配排序方法进行了改进:对于每个个体 i i i都设有两个参数 n ( i ) n(i) n(i)和 s ( i ) s(i) s(i),其中 n ( i ) n(i) n(i)为在种群中支配个体 i i i的解个体的数量, s ( i ) s(i) s(i)为被个体 i i i所支配的解个体的集合。
1)首先,找到种群所有
n
(
i
)
=
0
n(i)=0
n(i)=0的个体(种群中所有不被其他个体支配的个体
i
i
i),将它们存入当前集合
F
(
1
)
F(1)
F(1);(找到种群中所有未被其他解支配的个体)
2)然后对于当前集合
F
(
1
)
F(1)
F(1)中的每个个体
j
j
j,考察它所支配的个体集
s
(
j
)
s(j)
s(j),将集合
s
(
j
)
s(j)
s(j)中的每个个体
k
k
k的
n
(
k
)
n(k)
n(k)减去1,即支配个体
k
k
k的解个体数减1(因为支配个体
k
k
k的个体
j
j
j已经存入当前集
F
(
1
)
F(1)
F(1));(对其他解除去被第一层支配的数量,即减1)
3)如
n
(
k
)
−
1
=
0
n(k)-1=0
n(k)−1=0则将个体
k
k
k存入另一个集
H
H
H。最后,将
F
(
1
)
F(1)
F(1)作为第一级非支配个体集合,并赋予该集合内个体一个相同的非支配序
i
(
r
a
n
k
)
i(rank)
i(rank),然后继续对
H
H
H作上述分级操作并赋予相应的非支配序,直到所有的个体都被分级。其计算复杂度为
O
(
M
N
2
)
O(MN^2)
O(MN2),M为目标函数个数,N为种群大小。(按照1)、2)的方法完成所有分级)
确定拥挤度
在原来的NSGA中,我们采用共享函数以确保种群的多样性,但这需要由决策者指定共享半径的值。为了解决这个问题,我们提出了拥挤度概念:在种群中的给定点的周围个体的密度,用
i
d
i_{d}
id 表示,它指出了在个体 i 周围包含个体 i 本身但不包含其他个体的长方形(以同一支配层的最近邻点作为顶点的长方形)
拥挤度比较算子:
从图中我们可以看出
i
d
i_{d}
id值较小时表示该个体周围比较拥挤。为了维持种群的多样性,我们需要一个比较拥挤度的算子以确保算法能够收敛到一个均匀分布的帕累托面上。
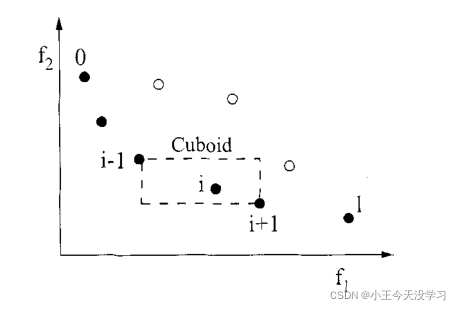
由于经过了排序和拥挤度的计算,群体中每个个体i都得到两个属性:非支配序 i ( r a n k ) i(rank) i(rank)和拥挤度 i d i_{d} id,则定义偏序关系 ≺ n \prec _{n} ≺n:当满足条件 i ( r a n k ) < i d i(rank) < i_{d} i(rank)<id,或满足 i ( r a n k ) = i d i(rank) = i_{d} i(rank)=id且 i d > j d i_{d}> j_{d} id>jd。时,定义 i ≺ n j i\prec _{n}j i≺nj,。也就是说:如果两个个体的非支配排序不同,取排序号较小的个体(分层排序时,先被分离出来的个体);如果两个个体在同一级,取周围较不拥挤的个体。
对于前面的例子,我们可以得到:
| Name | Height | Salary | Pareto Optimal | Front Level | n p n_{p} np | s p s_{p} sp |
|---|---|---|---|---|---|---|
| A | 190 | 80K | 是 | 1 | 0 | C,D |
| B | 170 | 85K | 是 | 1 | 0 | C,D |
| C | 165 | 70K | - | 2 | 1 | D |
| D | 160 | 22K | - | 3 | 2 |
n p n_{p} np的意思是“有多少人支配你?”, s p s_{p} sp的意思是“你在控制谁?”,因为A和B不受任何解的支配,也不互相支配,所以它们的 n p n_{p} np=0, s p s_{p} sp包含C和D。C受A和B的支配,它们的 n p n_{p} np=1。C也支配D,所以 s p s_{p} sp包含D。
非支配解排序(Non-dominated Sorting)
1.设所有解的集合为S,现从中找出非支配解集合,记为F1
2.令S=S-F1,从S中再找出非支配解集合,记为F2
3.重复第二步,直到S为空集
将每次找出的非支配解进行排序如下:{F1,F2,…,Fn}
拥挤距离
为了估计总体中某一特定解周围的解的密度,作者计算了该点两边沿每个目标的平均距离。如上图所示,第i个解在其前端的拥挤距离(用实线圆圈标记)是长方体的平均边长(用虚线框表示)。
算法:
1.为所有个体的拥挤距离初始化为0。
2.审视所有的个人和目标值。通过Inf值分配绑定解决方案来选择它们。
3.计算每个目标的第m个最大值和最小值,得到归一化的分母。
4.对第i个个体的m个目标的拥挤距离求和
计算拥挤度是为了保存下来相似程度较低的解,保持解空间的多样性。
改进点
改进点一:种群自适应交叉和变异
种群个体的交叉和变异是产生新个体的重要来源,但是,盲目的进行交叉和变异可能导致最优解的破坏,迭代结果陷入局部最优。NSGA-II主要通过拥挤距离来判断种群的离散程度。
改进点:将个体拥挤距离与该个体所在Pareto前沿的个体平均拥挤距离进行对比,并引入带迭代因子i,确定交叉变异概率的大小,实现种群自适应进化,加强算法的搜索能力以及收敛方向的准确性。交叉概率
p
c
p_{c}
pc和变异概率
p
m
p_{m}
pm分别表示为[1]:
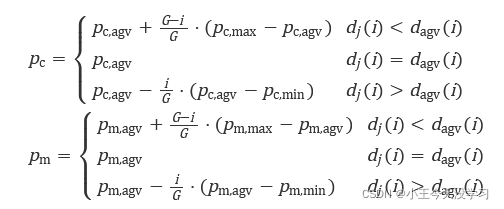
在种群迭代更新前期,进化个体具有较大的交叉和变异概率,满足种群个体多样性的要求,加强了算法的全局搜索能力;更新后期,进化个体的交叉和变异概率趋于平均值,算法着重于局部搜索,得到最终解。
改进点二:选择操作
锦标赛选择法:
1.确定每次选择的个体数量N。(二元锦标赛选择即选择2个个体)
2.从种群中随机选择N个个体(每个个体选择的概率相同),根据每个个体的适应度值,选择其中适应度值最好的个体进入下一代种群。
3.重复步骤(2)多次(重复次数为种群的大小),直到新的种群规模达到原来的种群规模。
NSGA-II算法通过经典二元锦标赛选择法进行种群中优质个体的选择。
改进点:首先,剔除生成的种群中不满足自身性能约束的解,然后再对剩余的解使用二元锦标赛选择法[1]:
a.若两解均满足协同约束,则先比较Pareto等级,选择等级更优者;若Pareto等级相同,则比较拥挤距离,选择拥挤距离较大的一方。
b.若有一解不满足协同约束条件,则选择满足协同约束条件的一方。
c.若均不满足协同约束条件,则进行协同系数比较,先比较空间协同系数,择优录取;若相同,再比较时间协同系数,择优录取。反复执行多次二元锦标赛选择法,直至所筛选个体数目与原种群个体数目相等。
从帕累托前沿中决策出最优方案的方法有很多,其中最流行的就是归一加权法,该方法具有简单性和高效探索能力,常用于生产调度多目标决策问题。具有t个目标归一化加权法定义为[2]:
U ( k ) = w 1 f 1 ′ ( k ) + w 2 f 2 ′ ( k ) + . . . + w t f t ′ ( k ) U(k)=w_{1}f_{1}^{'}(k)+w_2f_{2}^{'}(k)+...+w_{t}f_{t}^{'}(k) U(k)=w1f1′(k)+w2f2′(k)+...+wtft′(k)
其中, w s ( s = 1 , 2 , . . , t ) w_{s}(s=1,2,..,t) ws(s=1,2,..,t)为各目标的权重系数; f s ′ ( k ) f_{s}^{'}(k) fs′(k)是第 s s s个目标值 f s ( k ) f_{s}(k) fs(k)在 s = 1 , 2 , . . , t s=1,2,..,t s=1,2,..,t的归一化值,可由下式计算:
f s ′ ( k ) = f s , m a x − f s ( k ) f s , m a x − f s , m i n f_{s}^{'}(k)=\frac{f_{s,max}-f_{s}(k)}{f_{s,max}-f_{s,min}} fs′(k)=fs,max−fs,minfs,max−fs(k)
其中 f s , m a x f_{s,max} fs,max与 f s , m i n f_{s,min} fs,min分别为目标 f s f_{s} fs的最大值和最小值。
引入学习机制
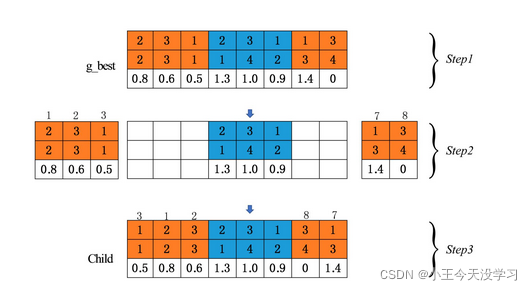
NSGA-II随机生成染色体、交叉、变异都有一定盲目性,大多情况下陷入局部最优解不能跳出,为解决该问题。引入学习机制改进NSGA-II。学习机制是子代学习前代最优解染色体优良基因,提升子代个体的良率。最优解在工序编码、机器编码均属于较优基因,后代对最优解的学习,继承了最优解的这些信息,加快算法求得全局最优解的速度。学习机制执行过程如下[2]:
Step1:从最优解染色体长度范围内随机选择两个位置。
Step2:将两个位置之间的基因段直接复制给子代对应染色体位置。
Step3:剩余左侧的基因段打乱顺序后赋值给子代左侧基因段,剩余右侧基因段打乱顺序后赋值给子代右侧基因段,根据工件在机器之间的运输时间,调整运输时间编码层生成新的子代染色体。
import math
# 非支配快速排序
def fast_non_dominated_sort(values1, values2):
S=[[] for i in range(0,len(values1))]
front = [[]]
n=[0 for i in range(0,len(values1))]
rank = [0 for i in range(0, len(values1))]
for p in range(0,len(values1)):
S[p]=[]
n[p]=0
for q in range(0, len(values1)):
if (values1[p] > values1[q] and values2[p] > values2[q]) or (values1[p] >= values1[q] and values2[p] > values2[q]) or (values1[p] > values1[q] and values2[p] >= values2[q]):
if q not in S[p]:
S[p].append(q)
elif (values1[q] > values1[p] and values2[q] > values2[p]) or (values1[q] >= values1[p] and values2[q] > values2[p]) or (values1[q] > values1[p] and values2[q] >= values2[p]):
n[p] = n[p] + 1
if n[p]==0:
rank[p] = 0
if p not in front[0]:
front[0].append(p)
i = 0
while(front[i] != []):
Q=[]
for p in front[i]:
for q in S[p]:
n[q] =n[q] - 1
if( n[q]==0):
rank[q]=i+1
if q not in Q:
Q.append(q)
i = i+1
front.append(Q)
del front[len(front)-1]
return front
# 返回a值在list中的索引
def index_of(a,list):
for i in range(0,len(list)):
if list[i]==a
return i
return -1
# 对values中的值按从小到大排序,返回索引的列表
def sort_by_values(list1,values):
sorted_list = []
while len(sorted_list)!=len(list1)
if index_of(min(values),values) in list1:
sorted_list.append(index_of(min(values),values))
values[index_of(min(values),values)]=math.inf
return sorted_list
# 拥挤距离计算
def crowding_distance(values1, values2, front):
distance = [0 for i in range(0,len(front))]
sorted1 = sort_by_values(front, values1[:])
sorted2 = sort_by_values(front, values2[:])
distance[0] = 4444444444444444
distance[len(front) - 1] = 4444444444444444
for k in range(1,len(front)-1):
distance[k] = distance[k]+ (values1[sorted1[k+1]] - values2[sorted1[k-1]])/(max(values1)-min(values1))
for k in range(1,len(front)-1):
distance[k] = distance[k]+ (values1[sorted2[k+1]] - values2[sorted2[k-1]])/(max(values2)-min(values2))
return distance
参考文献:
[1]王猛,王道波,王博航,周晨昶,姜燕.基于改进NSGA-II的多无人机三维空间协同航迹规划研究[J].机械与电子,2021,39(11):73-80.
[2]王亚昆,刘应波,吴永明,李少波,宗文泽.改进NSGA-II算法求解考虑运输约束的柔性作业车间节能调度问题[J/OL].计算机集成制造系统:1-22[2022-01-27].http://kns.cnki.net/kcms/detail/11.5946.tp.20210912.2002.004.html.
[3] Deb K , Pratap A , Agarwal S , et al. A fast and elitist multiobjective genetic algorithm: NSGA-II[J]. IEEE Transactions on Evolutionary Computation, 2002, 6(2):182-197.