基尼不纯度简介 - Gini Impurity - 吕汉鸿 - 博客园
先看上面这个博文!!!然后再看下面的,下面这个原博文有一点问题。已修正,修正后的完整内容如下
一、基尼指数的概念
基尼指数(Gini不纯度)表示在样本集合中一个随机选中的样本被分错的概率。
注意:Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。当集合中所有样本为一个类时,基尼指数为0.
二、基尼指数的计算公式
基尼指数的计算公式为:
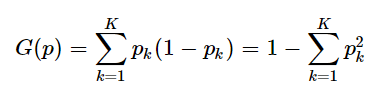
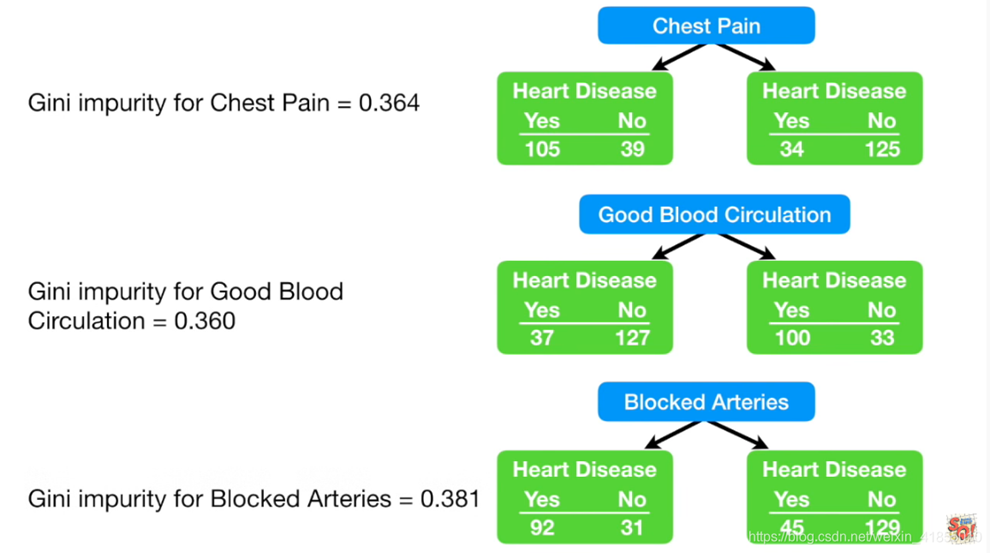
以下excel表格记录了Gini指数的计算过程。

以第一个Giniimpurity 0.364139008为例
Positive的gini:p*(1-p)+q*(1-q) = 0.729*(1-0.729) + 0.270 * (1-0.270) = 0.394 因为p+q=1,即p^2+q^2
Giniimpurity = 加权基尼
= [ positive数量/(positive+negative)数量 ] * 0.394 + [ negative数量/(positive+negative)数量 ] * 0.336
= 144/303* 0.394 + 159/303* 0.336 = 0.3635 约等于0.364数据精度
我们可以看到,GoodBloodCircle的基尼指数是最小的,也就是最不容易犯错误,因此我们应该把这个节点作为决策树的根节点。在机器学习中,CART分类树算法使用基尼指数来代替信息增益比,基尼指数代表了模型的不纯度,基尼指数越小,不纯度越低,特征越好。这和信息增益(比)相反。
基尼指数(Gini Impurity)的理解和计算-CSDN博客

这个图同样的原理。
28 【机器学习入门|5分钟理解决策树算法 - 躺平学ML | 小红书 - 你的生活指南】 😆 0SneRzSkoY8CzN5 😆