prometheus介绍

Prometheus 是一款基于时序数据库的开源监控告警系统,非常适合Kubernetes集群的监控。Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
环境说明:
操作系统:Rocky Linux 8.6
Prometheus服务器IP:192.168.1.5
被监控端web1: 192.168.1.100
被监控端mysql: 192.168.1.200
步骤:
1. 配置时间:
(1) 查看时区:
[root@prometheus ~] timedatectlLocal time: Sun 2023-01-01 11:15:11 CST # 本地时间
Universal time: Sun 2023-01-01 03:15:11 UTC # 世界协调时间
RTC time: Sun 2023-01-01 03:15:11 # 系统时间
Time zone: Asia/Shanghai (CST, +0800) # 时区(东八区)
System clock synchronized: no # 系统时钟是否与其他时间源同步
NTP service: inactive # 网络时间协议(NTP)服务的状态(未激活)
RTC in local TZ: no # 实时时钟是否设置为本地时区
(2) 设置时区:
[root@prometheus ~] timedatectl set-timezone Asia/Shanghai2. 安装prometheus
源码包为 prometheus-2.37.5.linux-amd64.tar.gz (解压即可运行)
[root@prometheus ~] tar -xf prometheus-2.37.5.linux-amd64.tar.gz
[root@prometheus ~] mv prometheus-2.37.5.linux-amd64 /usr/local/prometheus(1). 修改主配置文件
[root@prometheus ~] vim /usr/local/prometheus/prometheus.ymlglobal: # 服务器全局配置
scrape_interval: 15s # 数据抓取时间间隔evaluation_interval: 15s # 规则评估时间间隔
alerting: # 报警配置
alertmanagers: # altermanager服务地址
- static_configs:
- targets:rule_files: # 规则文件列表,可以指定多个文件
scrape_configs: # 监控资源配置
- job_name: "prometheus" #资源名称
static_configs:
- targets: ["localhost:9090"] # 监控本地9090端口
(2). 编写服务启动文件并启动服务
[root@prometheus ~] vim /usr/lib/systemd/system/prometheus.service[Unit] # 描述服务的元数据
Description=Prometheus Monitoring System # 服务的描述信息
After=network.target # 依赖关系:在网络服务启动之后启动
[Service] # 服务运行参数
ExecStart=/usr/local/prometheus/prometheus \ # 服务启动命令路径
--config.file=/usr/local/prometheus/prometheus.yml \ # 配置文件路径
--storage.tsdb.path=/usr/local/prometheus/data/ # 数据存储路径
[Install] # 服务安装参数
WantedBy=multi-user.target # 服务所属的目标(multi-user.target表示多用户命令行模式)
[root@prometheus ~] systemctl daemon-reload
[root@prometheus ~] systemctl enable prometheus.service --now
[root@prometheus ~] ss -tlnp | grep :9090LISTEN 0 128 *:9090 *:* users:(("prometheus",pid=4396,fd=7))
此时9090端口已经被启动,可以用浏览器访问 http://192.168.1.5:9090/,在prometheus网页主页/Status/Target中可以看到prometheus主服务资源对象。
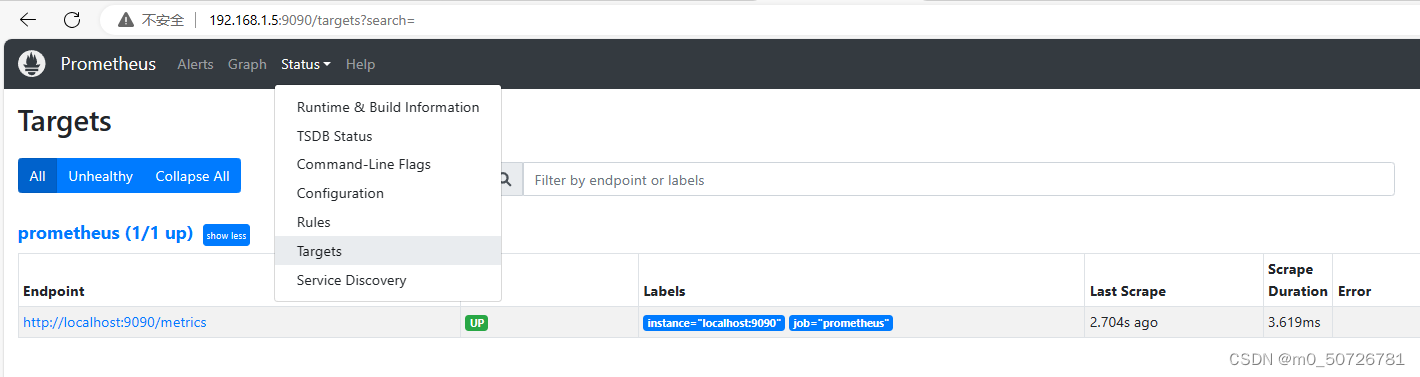
同时,在Prometheus主页,可以看到服务本身的资源信息,如分配置给Prometheus运行的内存数量:
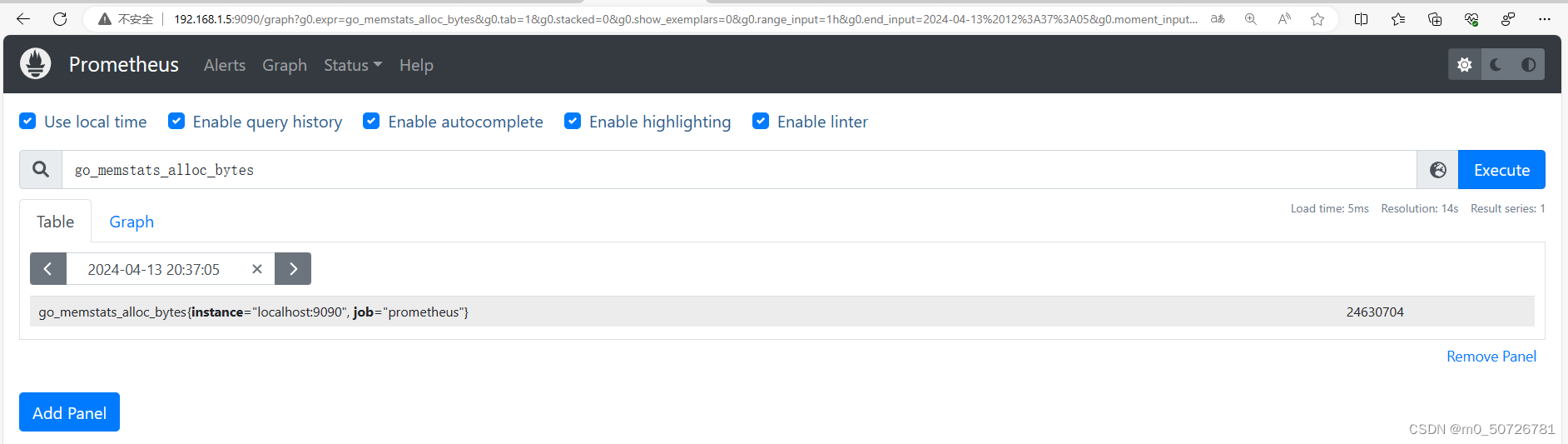
注意,prometheus没有时区概念,使用的时间为UTC世界时间,如果使用的是北京时间,需要+8小时。
3. 添加被监控对象:web1主机 (在被监控机安装)
(1) 安装包为源码包node_exporter-1.5.0.linux-amd64.tar.gz
[root@web1 ~] tar -xf node_exporter-1.5.0.linux-amd64.tar.gz
[root@web1 ~] mv node_exporter-1.5.0.linux-amd64 /usr/local/node_exporter(2) 创建服务文件,并启动服务
[root@web1 ~] vim /usr/lib/systemd/system/node_exporter.service[Unit] # 描述服务的元数据
Description=node_exporter # 服务的描述信息
After=network.target # 依赖关系:在网络服务启动之后启动
[Service] # 服务运行参数
Type=simple # 表示服务的类型为简单类型,即服务进程将直接运行并在主机上监听。
ExecStart=/usr/local/node_exporter/node_exporter # 服务启动命令路径
[Install] # 安装参数
WantedBy=multi-user.target # 服务所属的目标(multi-user.target表示多用户命令行模式)
[root@web1 ~] systemctl daemon-reload
[root@web1 ~] systemctl enable node_exporter.service --now
[root@web1 ~] ss -tlnp | grep :9100LISTEN 0 128 *:9100 *:* users:(("node_exporter",pid=7371,fd=3))
此时9100端口已经启动。
(3) 在Prometheus服务器上添加监控节点
[root@prometheus ~] vim /usr/local/prometheus/prometheus.yml ...略...
- job_name: "web1" # 资源名称
static_configs:
- targets: ["192.168.88.100:9100"] # 资源地址及端口
[root@prometheus ~] systemctl restart prometheus.service 访问Prometheus主页 http://192.168.1.5:9090/ 在prometheus网页主页/Status/Target中可以看到新添加的web1资源对象。
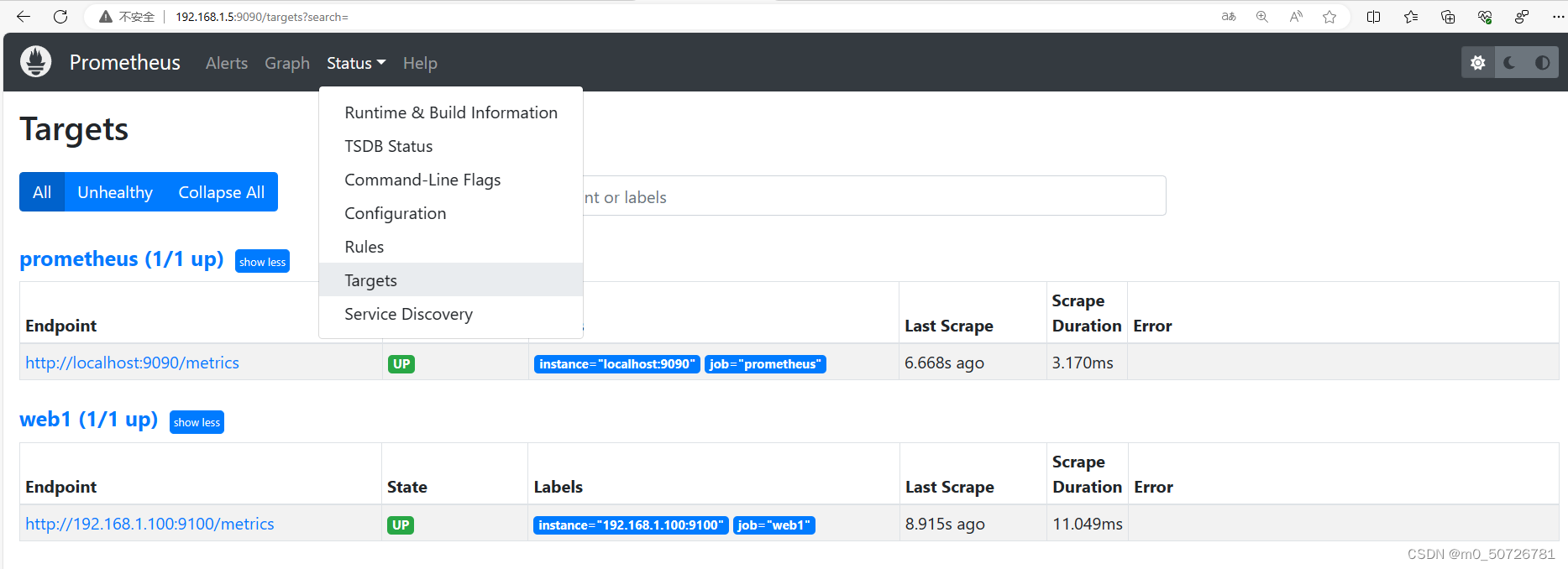
4. 添加被监控对象:mysql数据库
(1) 安装mysql并创建用于监控数据库的mysql用户
[root@mysql ~] yum install -y mysql-server
[root@mysql ~] systemctl enable mysqld --now
[root@mysql ~] mysqlmysql> create user dbuser1@localhost identified by '123456'; # 创建本地用户dbuser1 密码:123456
mysql> grant all privileges on *.* to dbuser1@localhost; # 授予该用户所有库所有权限
mysql> quit
(2) 安装包为源码包node_exporter-1.5.0.linux-amd64.tar.gz
[root@mysql ~] tar -xf mysqld_exporter-0.14.0.linux-amd64.tar.gz
[root@mysql ~] mv mysqld_exporter-0.14.0.linux-amd64 /usr/local/mysqld_exporter(3) 编写用于连接mysql服务的配置文件
[root@mysql ~] vim /usr/local/mysqld_exporter/.my.cnf[client]
host=127.0.0.1 # 指定mysql主机
port=3306 # 指定mysql端口
user=dbuser1 # 指定mysql用户
password=123456 # 指定mysql用户密码
(4) 创建服务文件,并启动服务
[root@mysql ~] vim /usr/lib/systemd/system/mysqld_exporter.service[Unit] # 描述服务的元数据
Description=mysqld_exporter # 服务的描述信息
After=network.target # 依赖关系:在网络服务启动之后启动
[Service] # 服务运行参数
ExecStart=/usr/local/mysqld_exporter/mysqld_exporter \ # 服务启动命令路径
--config.my-cnf=/usr/local/mysqld_exporter/.my.cnf # mysql-exporter配置文件
[Install] # 安装参数
WantedBy=multi-user.target # 服务所属的目标(multi-user.target表示多用户命令行模式)
[root@mysql ~] systemctl daemon-reload
[root@mysql ~] systemctl enable mysqld_exporter.service --now
[root@mysql ~] ss -tlnp | grep :9104LISTEN 0 128 *:9104 *:* users:(("mysqld_exporter",pid=12671,fd=3))
此时9104端口已经启动。
(5) 在Prometheus服务器上添加监控节点
[root@prometheus ~] vim /usr/local/prometheus/prometheus.yml ...略...
- job_name: "mysql" # 资源对象名称
static_configs:
- targets: ["192.168.88.100:9104"] # 资源地址及端口
[root@prometheus ~] systemctl restart prometheus.service 访问Prometheus主页 http://192.168.1.5:9090/ 在prometheus网页主页/Status/Target中可以看到新添加的web1资源对象。
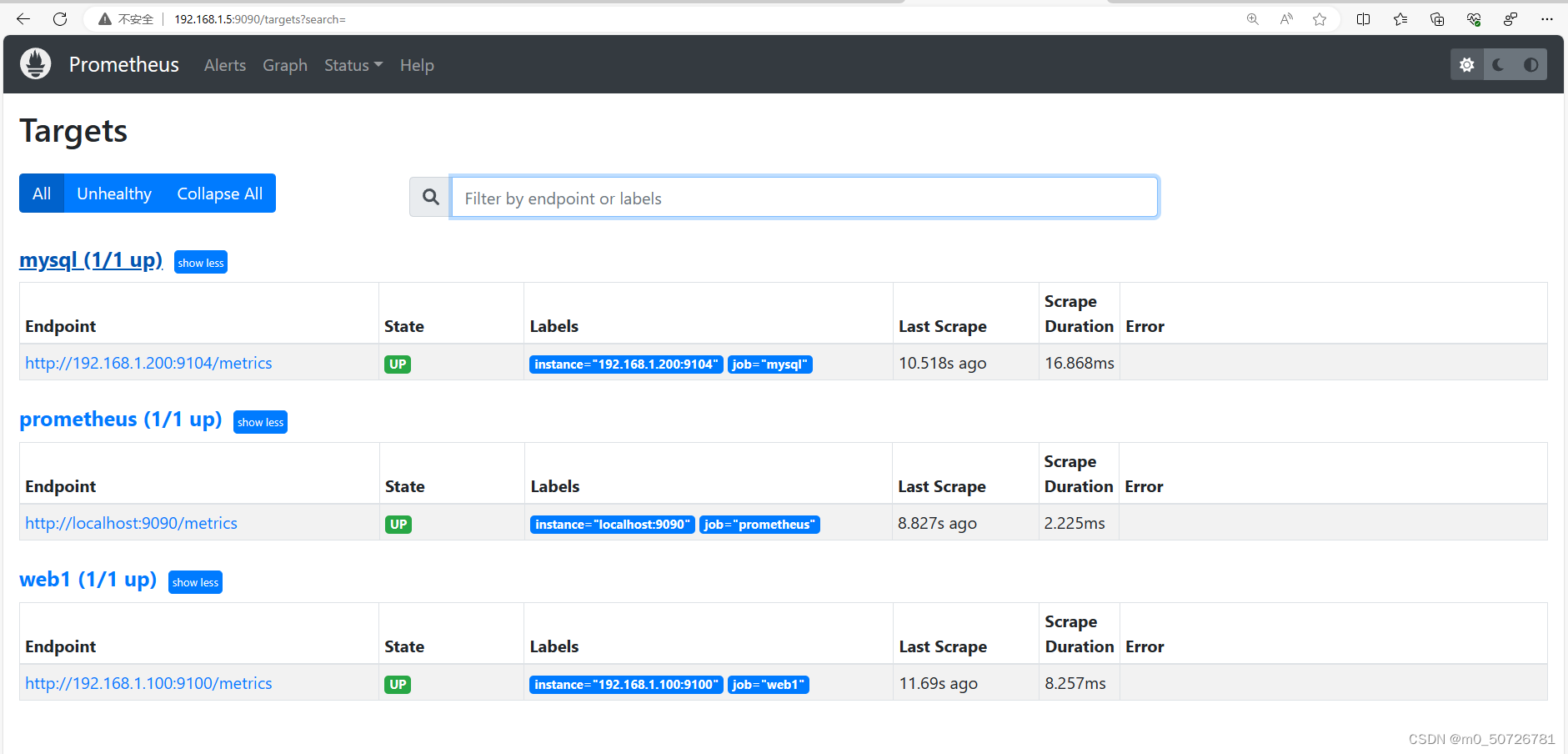
此时,主机已经添加完毕,如果还想监控更多主机及服务,自行添加即可。但访问每个资源的metrics时,数据太多,不直观,这时就需要安装图形化界面插件。
5. 添加grafana图形化插件
(1) 安装grafana
[root@prometheus ~] yum -y install grafana-enterprise-9.3.2-1.x86_64.rpm
[root@prometheus ~] systemctl enable grafana-server.service --now(2) 登录 http://192.168.1.5:3000/初始化,初始用户:admin 初始密码:admin。(需修改密码)

修改语言: 在preferencs中可以设置主题与语言
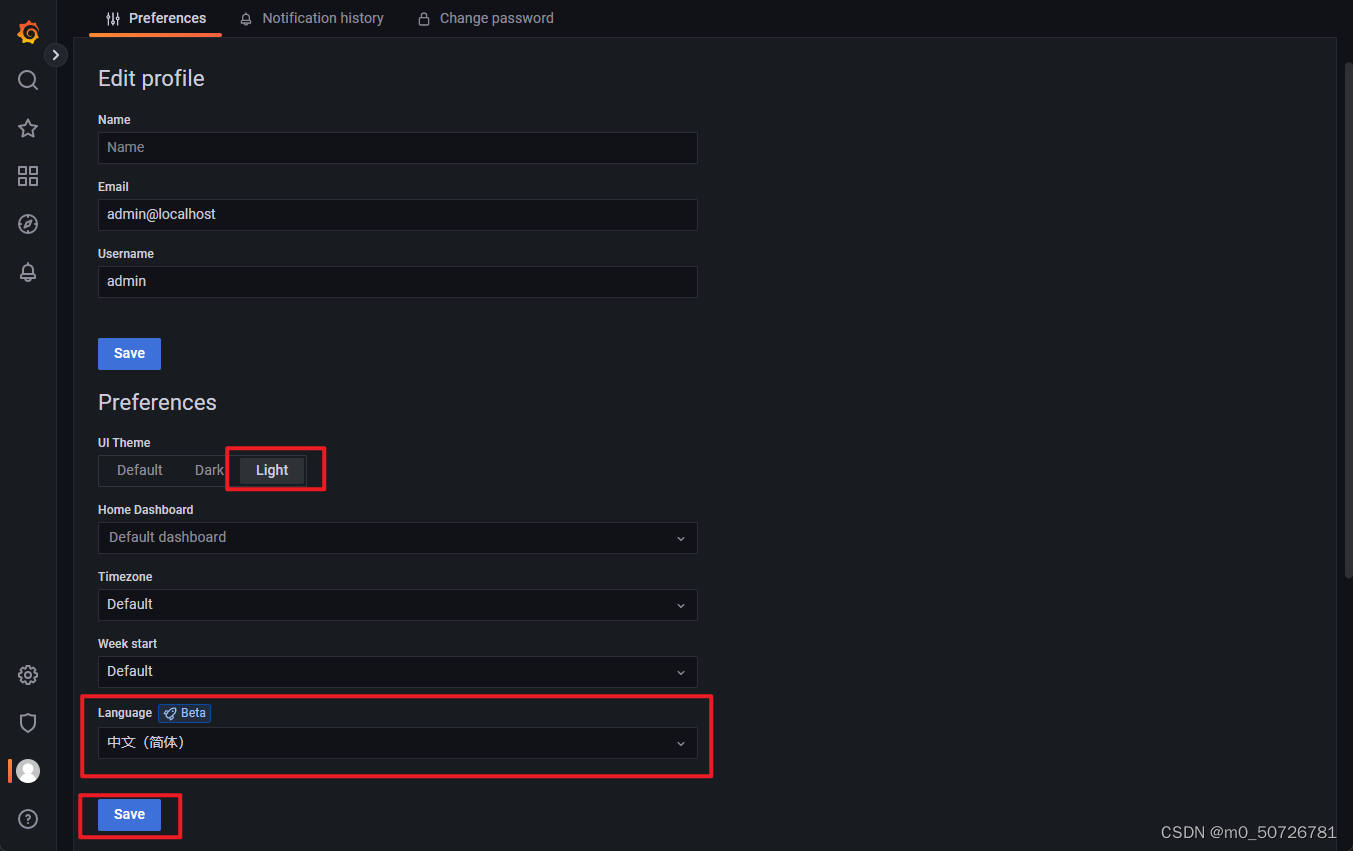
(3) 选择数据源
点击第三个图框Add your first data source
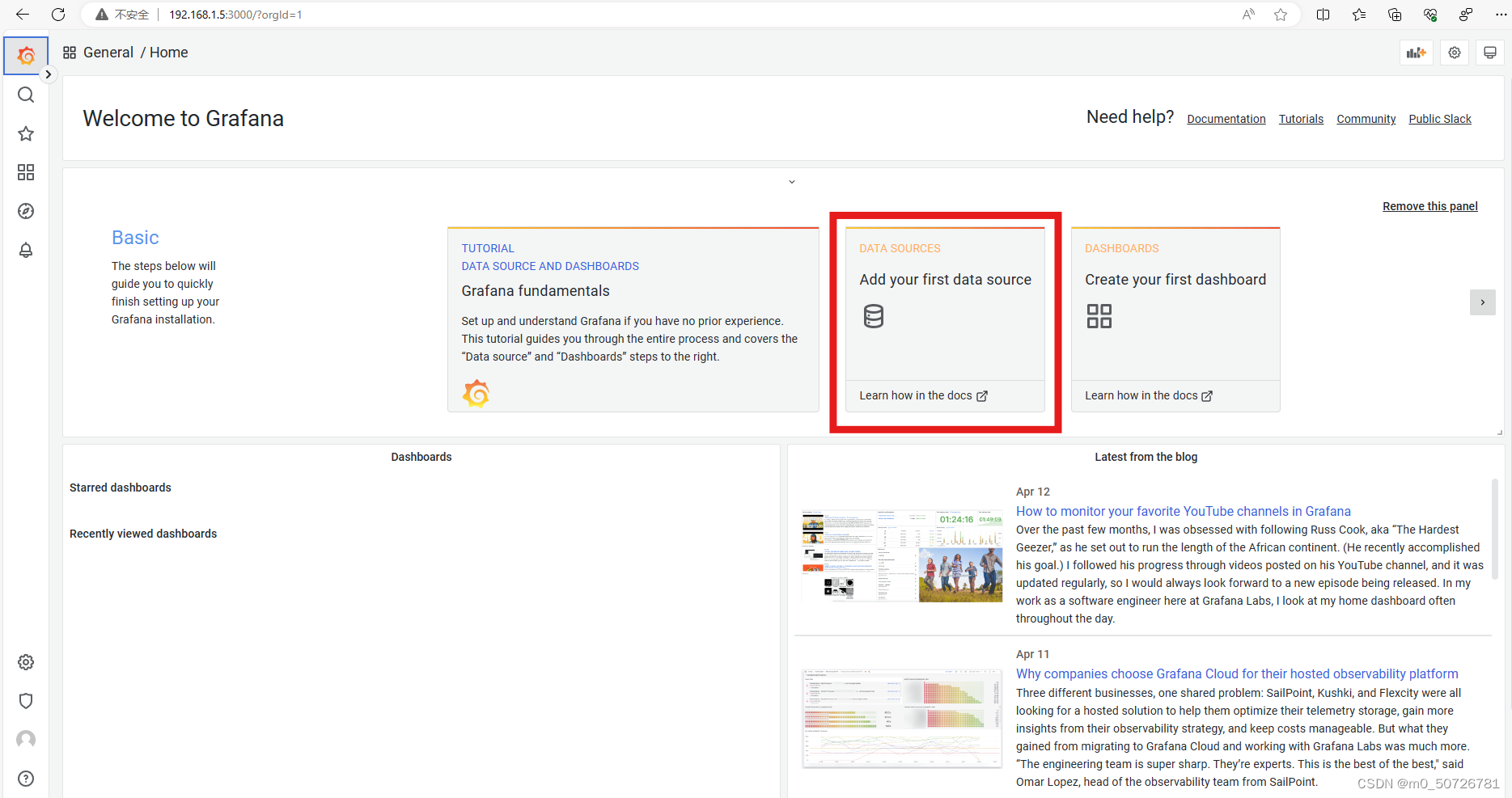
选择Prometheus服务资源
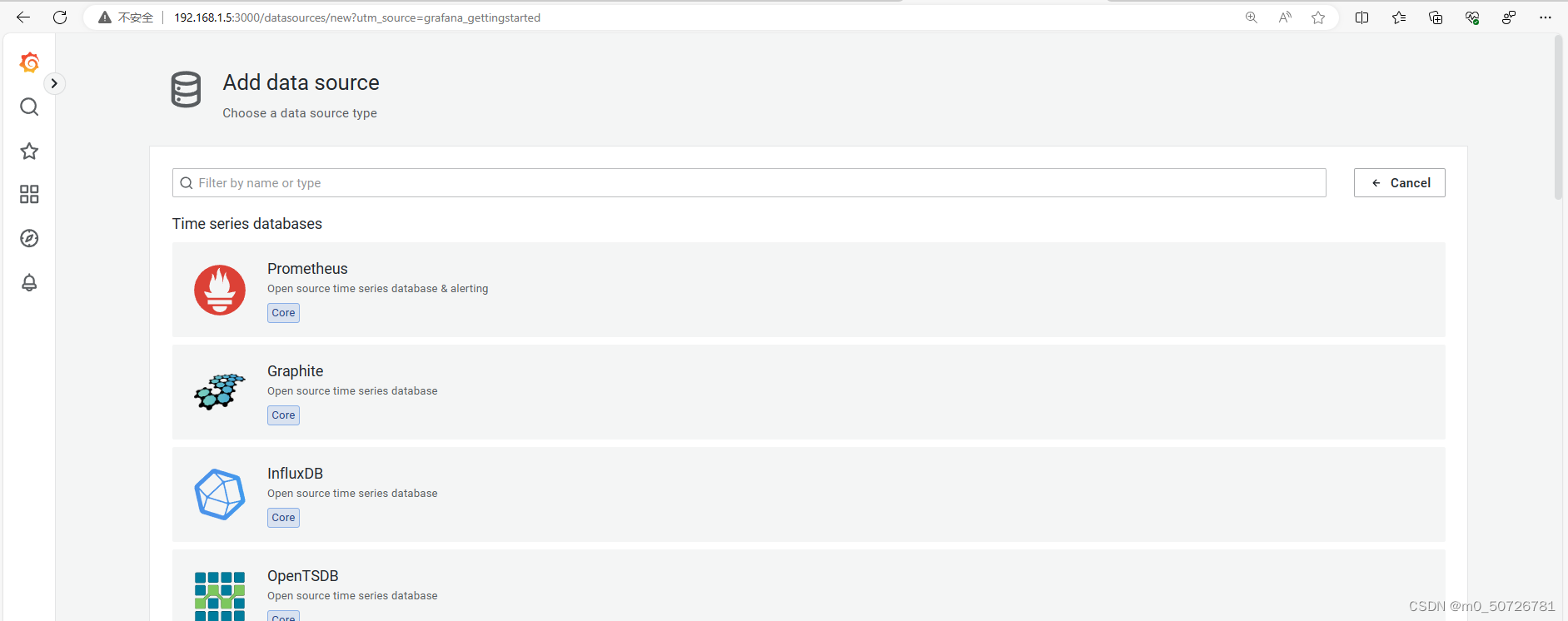
填写name与URL地址,然后点击最下面保存和测试
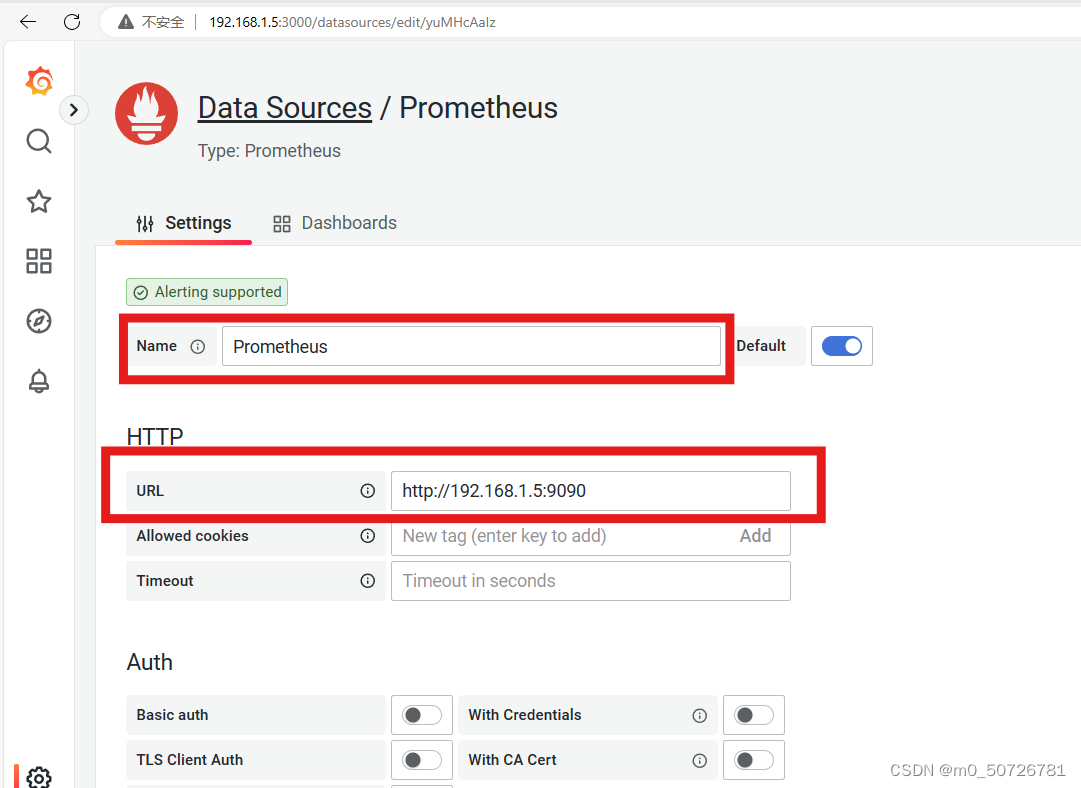
如果有如下提示是正常现象,因为我们的prometheus服务还未设置Ruler API规则
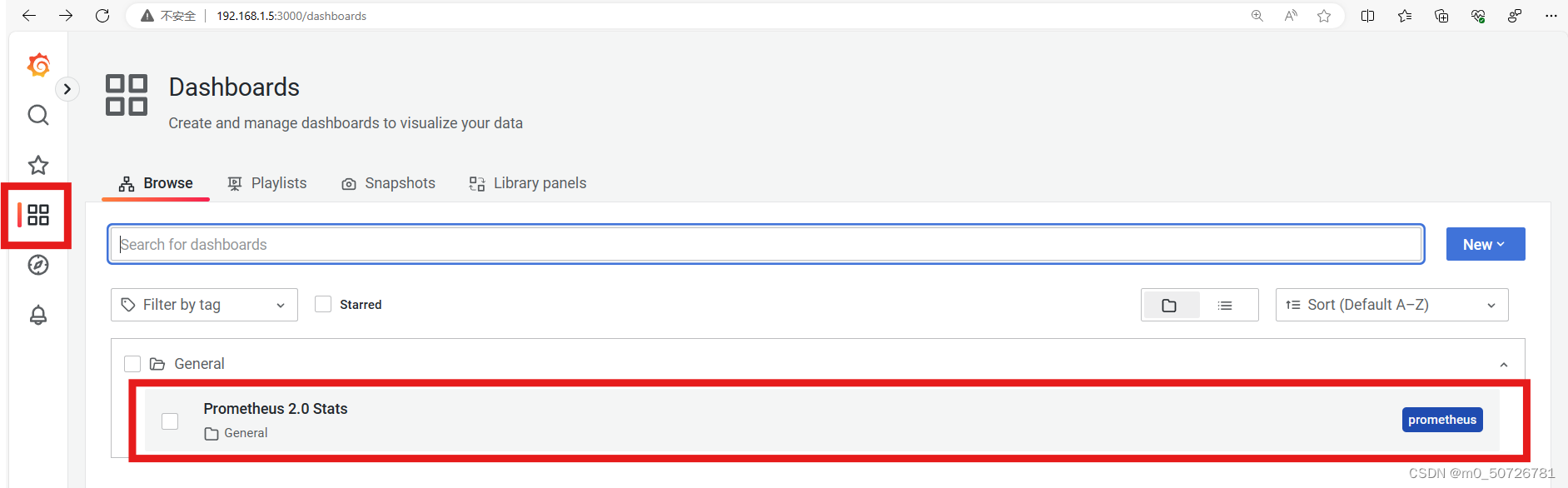
(4) 添加仪表盘
点击右边的Dashboards,我们可以选择Prometheus 2.0 Stats,点击import导入。

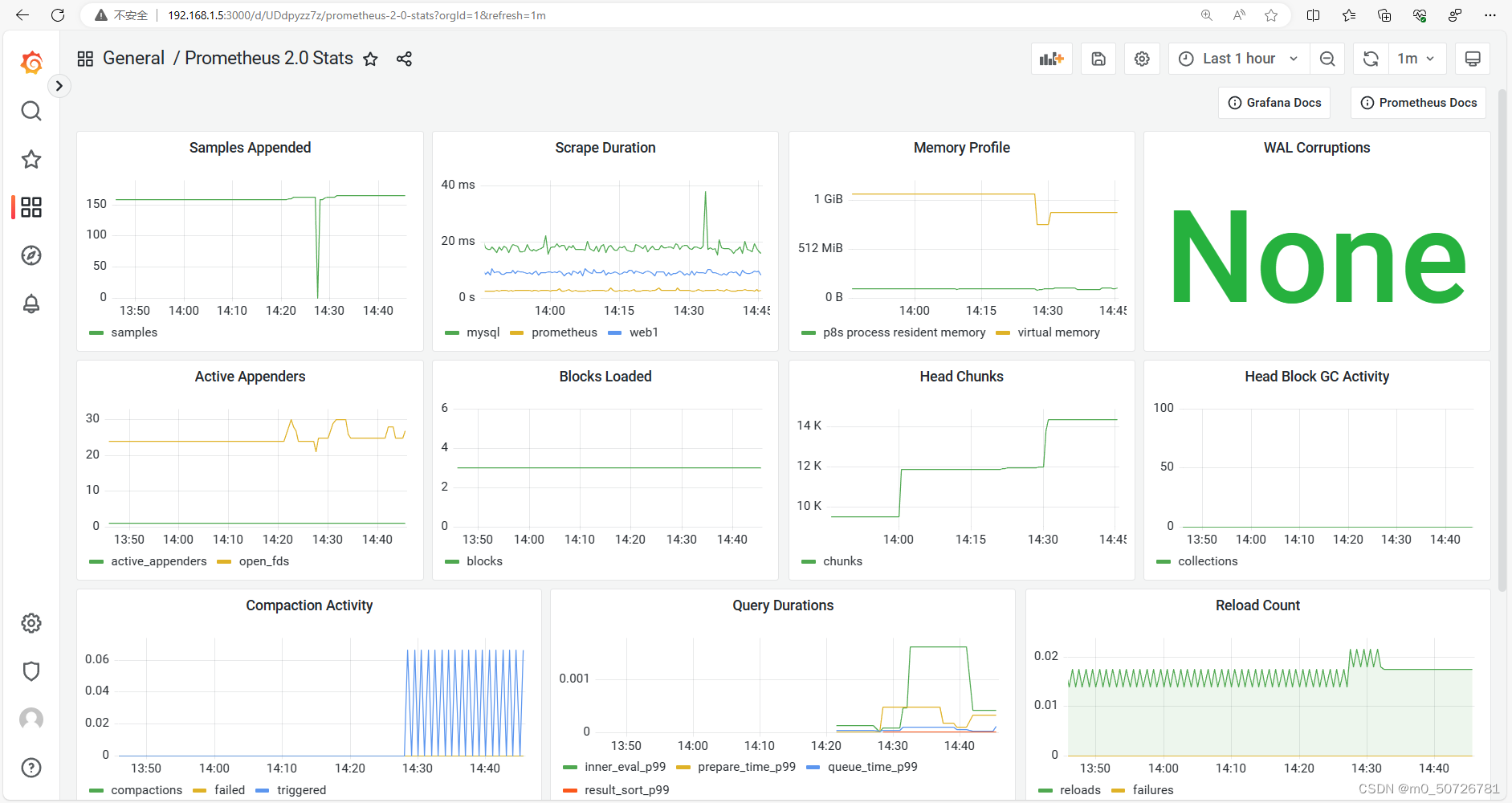
此时在仪表盘可以看见General目录下有个Prometheus2.0 Stats,点击它可以看到prometheus主服务的资源信息。
(5) 添加自定义仪表盘,监控node节点主机资源信息
自定义仪表盘是json文件,可以从官网下载Dashboards | Grafana Labs,我这里使用自定义仪表盘文件:1-node-exporter-for-prometheus-dashboard-update-1102_rev11.json
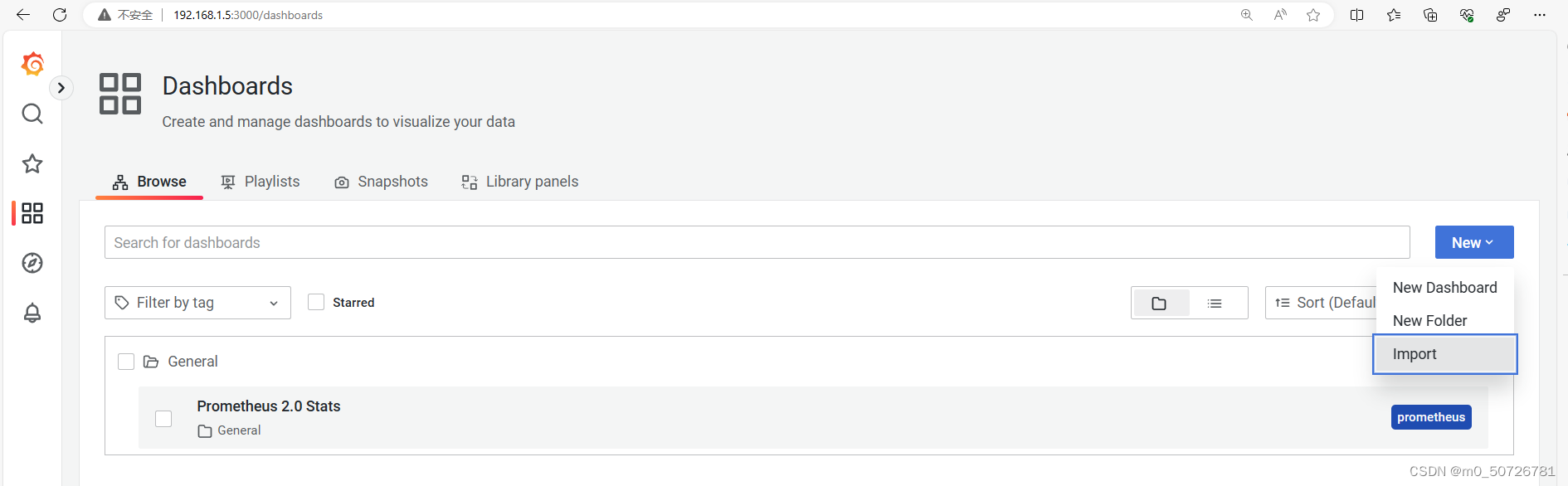
1) 点击仪表盘(Dashboards) 的New/Import导入
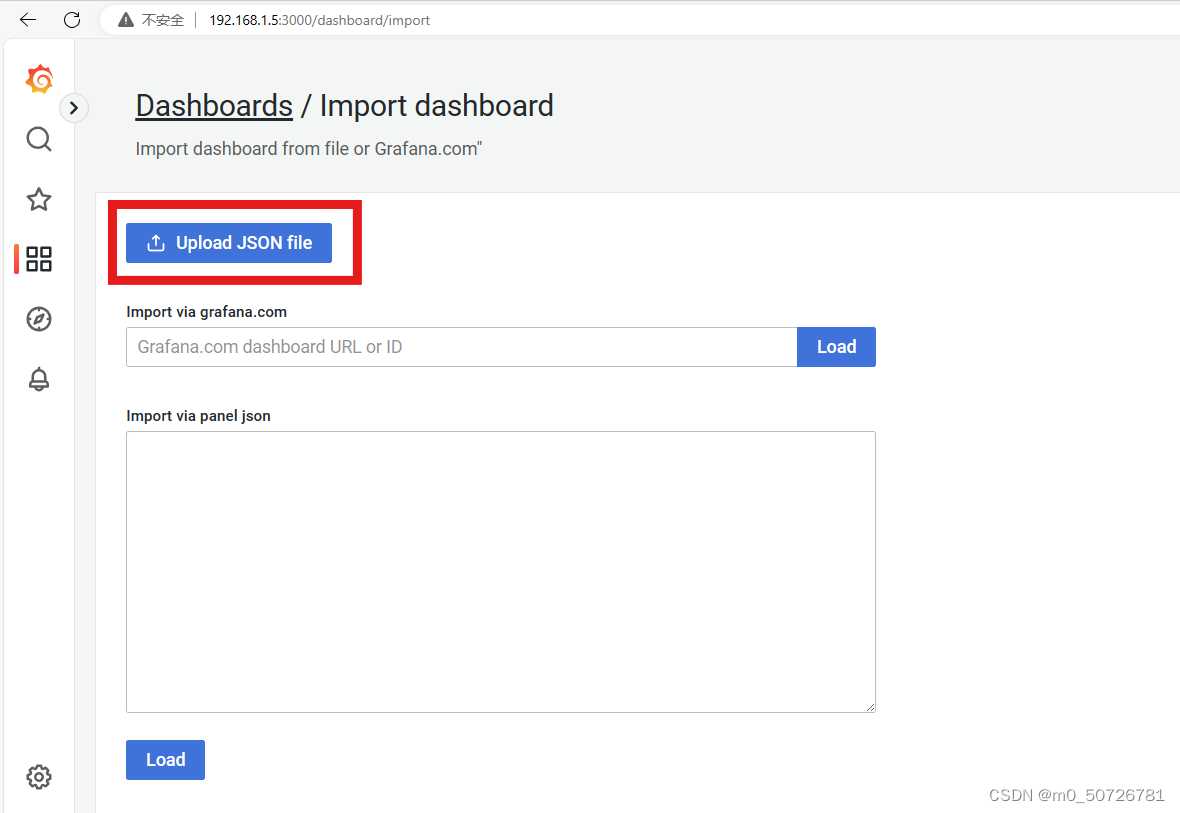
2) 点击Upload JSON file 导入模板文件
3) 选择数据来源为Prometheus
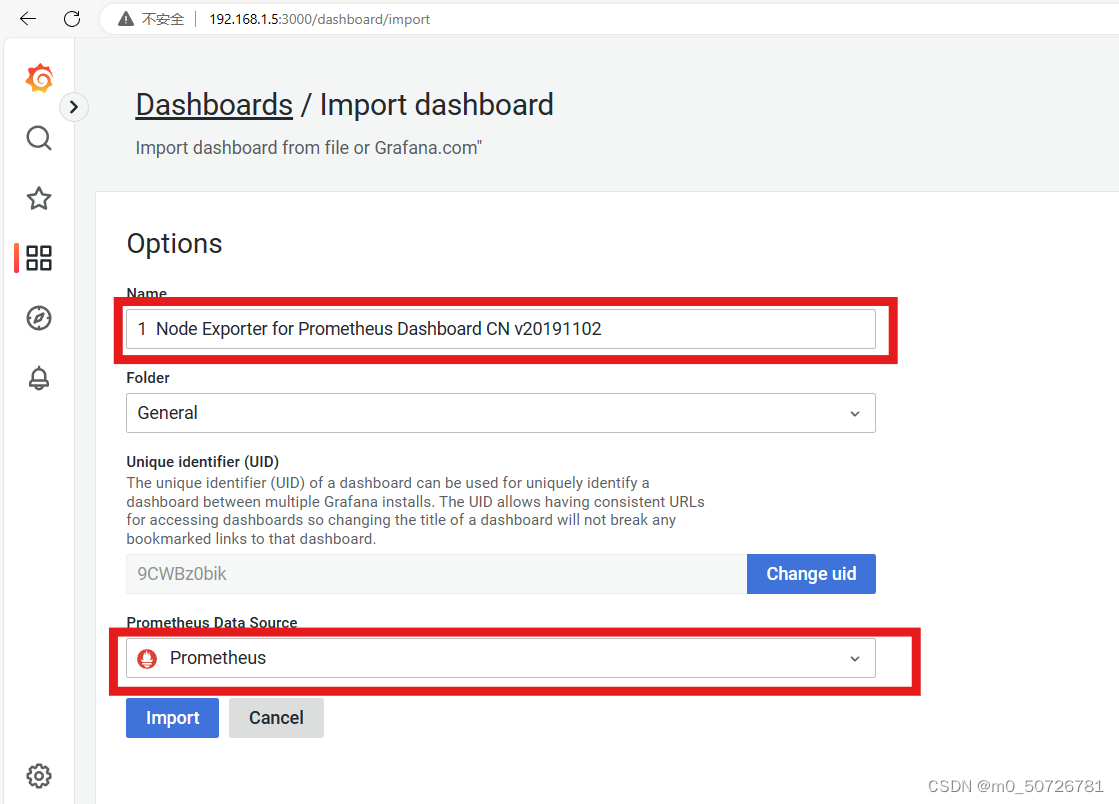
以下就显示prometheus的node节点资源信息
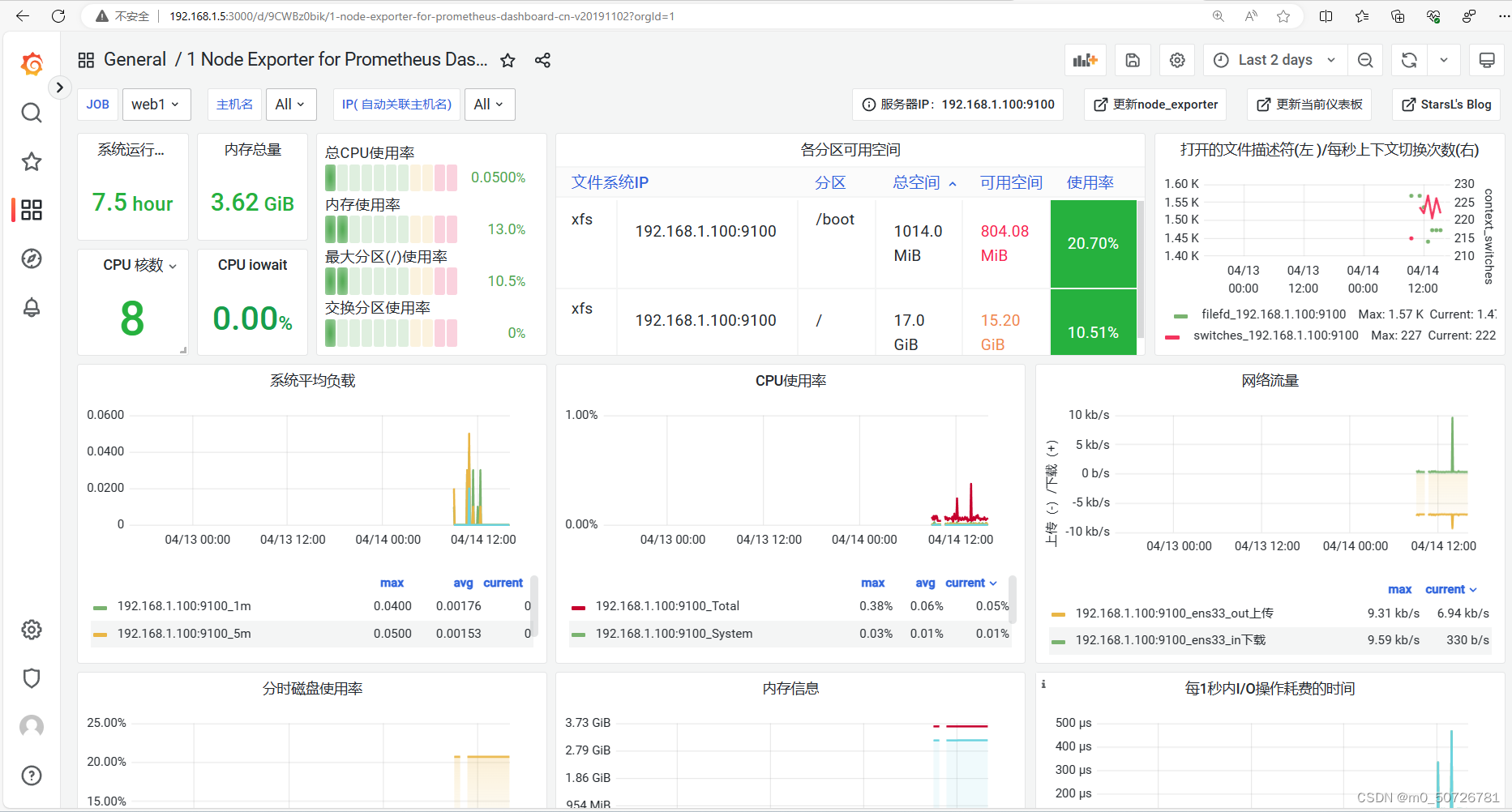
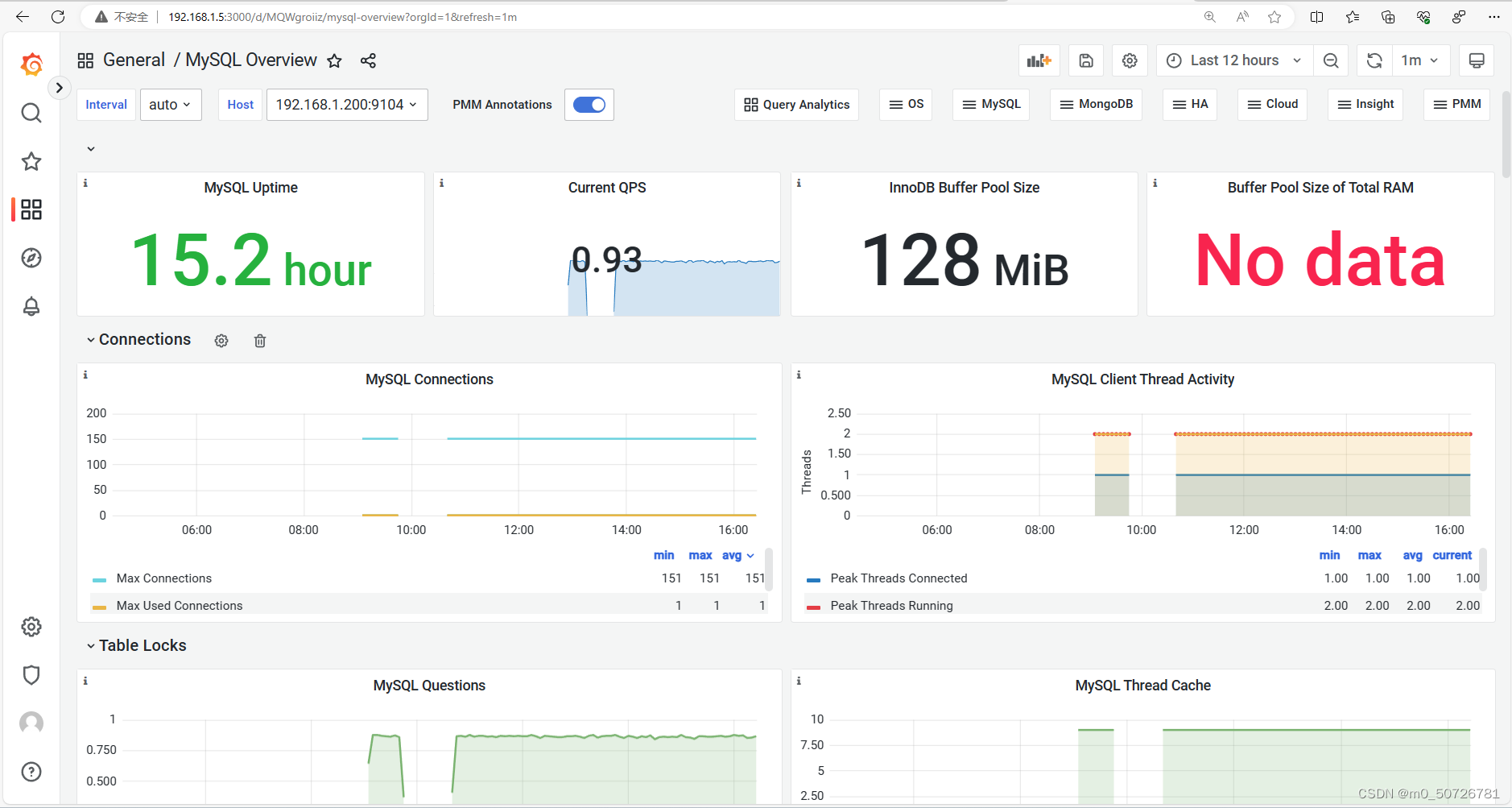
(6) 添加自定义仪表盘,监控mysql数据库
监控mysql也可以使用自定义仪表盘JSON模板文件,步骤与上一步添加node节点仪表盘相同。(JSON文件:mysql-overview_rev5.json)
1) 点击仪表盘(Dashboards) 的New/Import导入
2) 点击Upload JSON file 导入模板文件
3) 选择数据来源为Prometheus

以下就显示mysql数据库信息
6. 配置自动发现
配置自动发现后,Prometheus服务可以自动发现后端节点信息,并自动添加到监控服务中。
(1) 修改prometheus配置文件
[root@prometheus ~] vim /usr/local/prometheus/prometheus.yml删除原有静态配置,修改成以下内容(删除是为了再次利用用这些主机,删除不是必须的,自动发现和静态配置可以同时存在)
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "web1"
static_configs:
- targets: ["192.168.1.100:9100"]
- job_name: "mysql"
static_configs:
- targets: ["192.168.1.200:9104"]scrape_configs: # 监控资源配置
- job_name: "groups1" # 资源名称
file_sd_configs: # 文件service discovery配置
- refresh_interval: 120s # 刷新频率
files:
- /usr/local/prometheus/sd_config/*.yml # 文件路径
(2) 重启服务
[root@prometheus ~] systemctl restart prometheus(3) 创建发现文件
在定义的用于发现服务资源的文件路径,创建这个发现文件:
[root@prometheus ~] mkdir /usr/local/prometheus/sd_config
[root@prometheus ~] vim /usr/local/prometheus/sd_config/discovery.yml- targets: # 自动发现目标
- 192.168.1.5:9090
- 192.168.1.100:9100
- 192.168.1.200:9104
大约2分钟后,在prometheus主页就可以看到groups1的资源信息
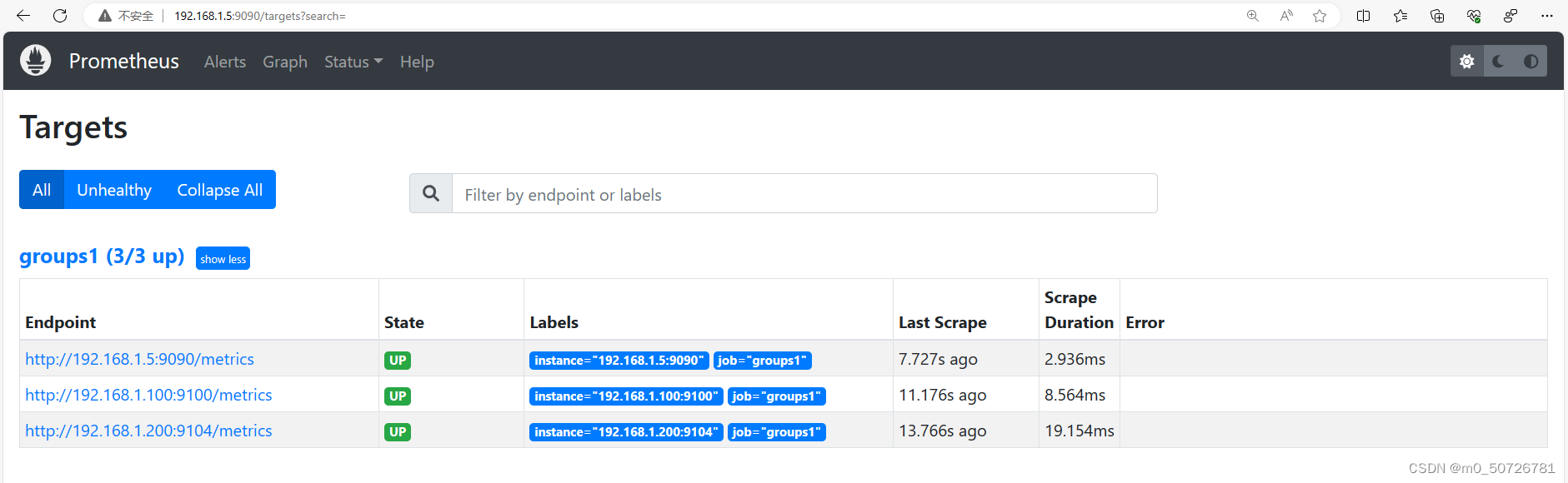
向/usr/local/prometheus/sd_config/discovery.yml发现文件中添加任意目标,2分钟后都会被发现。删除任意目标,2分钟后也会同步删除。
7. Altermanager告警功能
Altermanager告警具有去重、分组、路由的特性:
去重:当服务器发生严重故障触发一系列问题时,告警服务会根据规则抑制多个告警,显示最紧急的问题。
分组:对多个告警按类分,一目了然。
路由:让不同工作人员看到不同的告警。
(1) 安装部署
源码包alertmanager-0.25.0.linux-amd64.tar.gz,解压及可使用
[root@prometheus ~] tar -xf alertmanager-0.25.0.linux-amd64.tar.gz
[root@prometheus ~] mv alertmanager-0.25.0.linux-amd64 /usr/local/alertmanager(2) 编写服务启动文件并启动服务
[root@prometheus ~] vim /usr/lib/systemd/system/alertmanager.service[Unit] # 描述服务的元数据
Description=alertmanager System # 服务的描述信息
[Service] # 服务运行参数
ExecStart=/usr/local/alertmanager/alertmanager \ # 服务启动命令路径
--config.file=/usr/local/alertmanager/alertmanager.yml # 配置文件路径
[Install] # 安装参数
WantedBy=multi-user.target # 安装目标(多用户)
[root@prometheus ~] systemctl daemon-reload
[root@prometheus ~] systemctl enable alertmanager.service --now访问Alertmanager主页:http://192.168.1.5:9093/
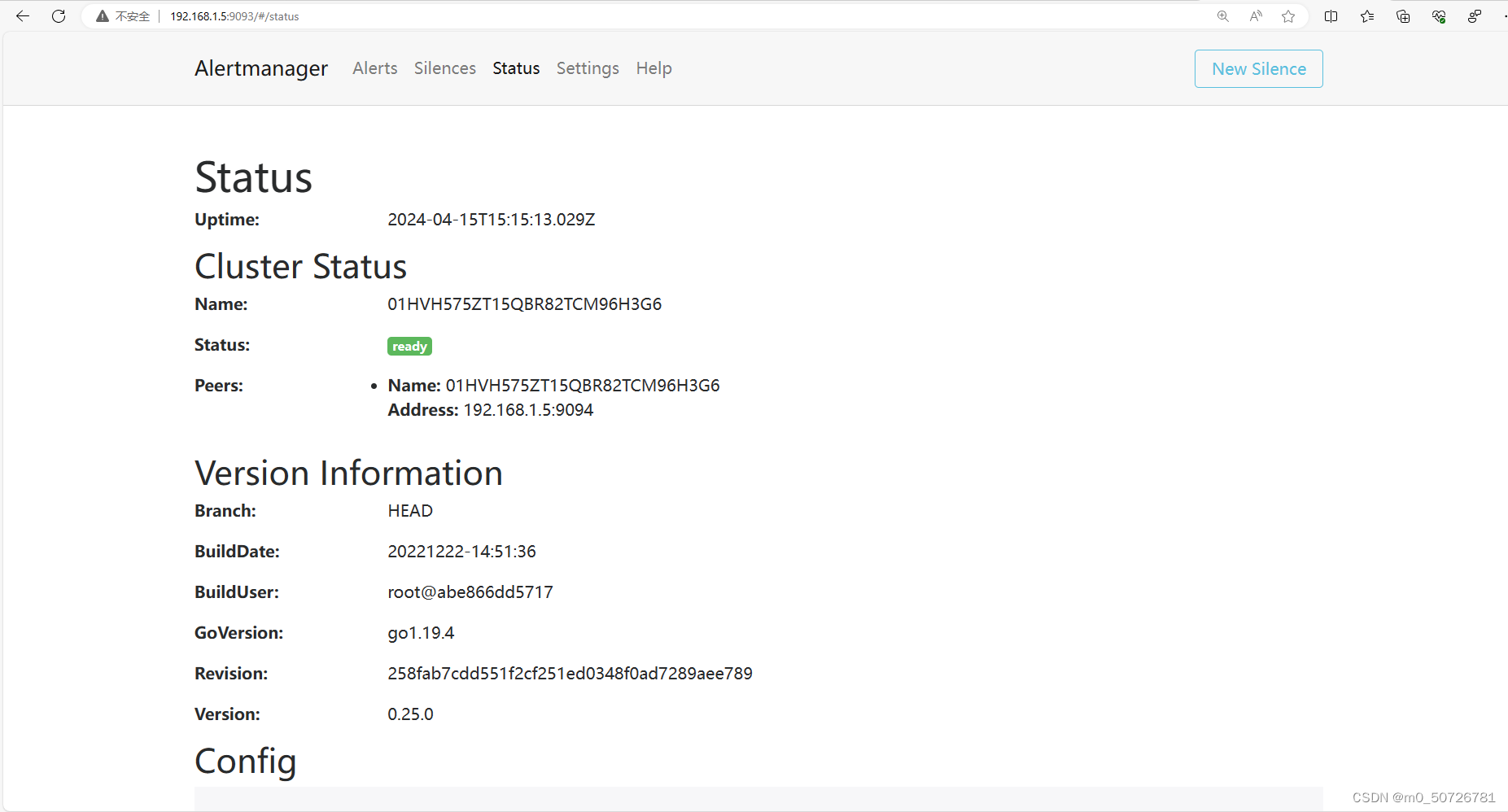
此时Alertmanager处于ready状态
(3) 修改prometheus主配置文件:
[root@prometheus ~] vim /usr/local/prometheus/prometheus.yml 在targets条目下指定- localhost:9093主机
...略...
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
...略...
[root@prometheus ~] systemctl restart prometheus.service 在prometheus主页status/configuration中可以看到alert配置
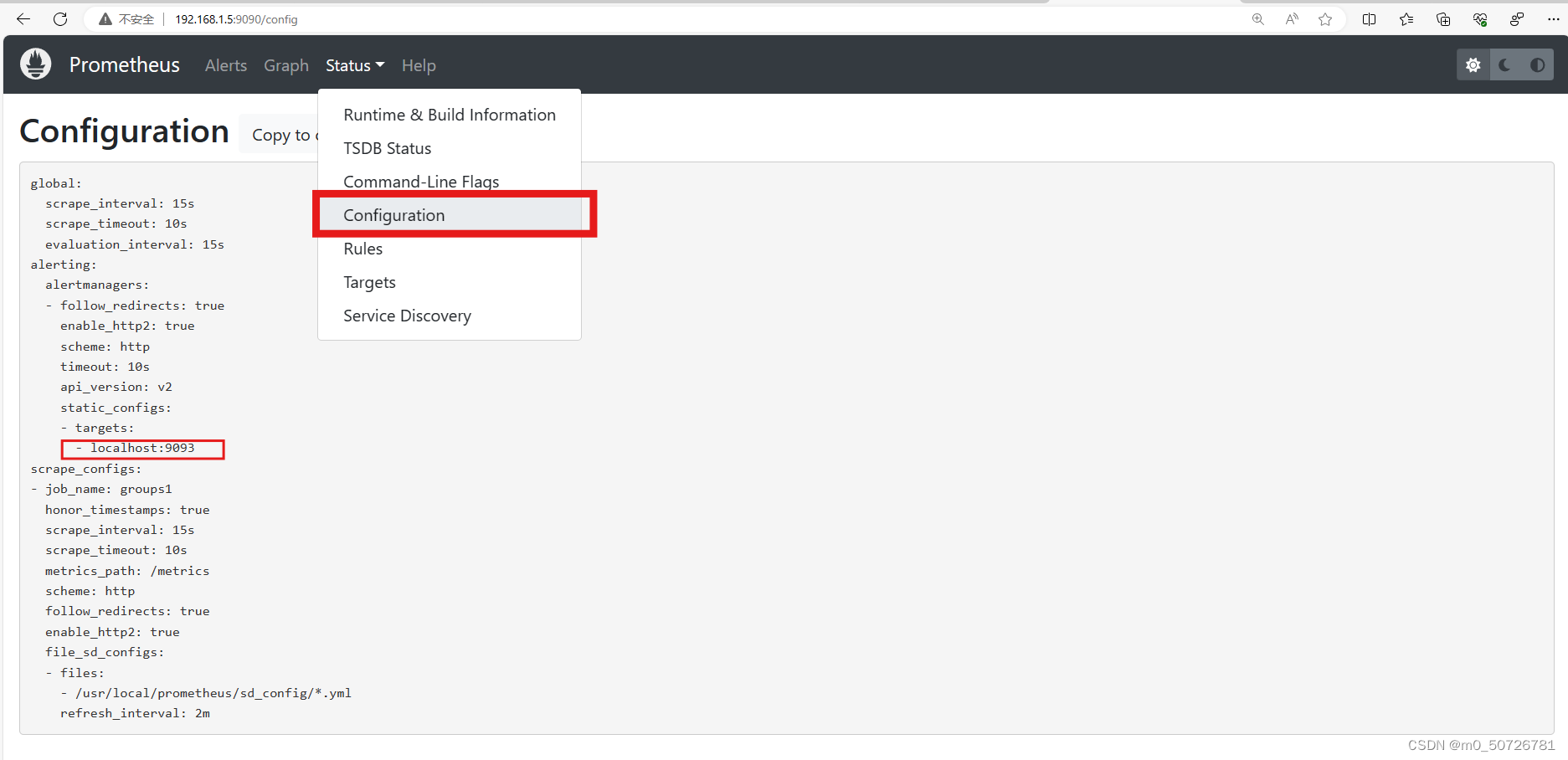
(4) 修改alertmanager配置文件,设置通过邮件发送报警
[root@prometheus ~] vim /usr/local/alertmanager/alertmanager.ymlglobal: # 全局配置
smtp_from: '[email protected]' # 发件人地址
smtp_smarthost: 'localhost:25' # 邮件服务器地址
smtp_require_tls: false # 是否使用TLS安全连接
route: # 路由配置
group_by: ['alertname'] # 分组方式,按告警名称分组
group_wait: 30s # 等待告警分组时间
group_interval: 5m # 分组告警的时间间隔
repeat_interval: 1h # 重复通知间隔
receiver: 'default-receiver' # 接收器名称
receivers: # 接收器配置
- name: 'default-receiver' # 配置接收器为邮件
email_configs: # 邮件配置
- to: '[email protected]'
inhibit_rules: # 抑制规则
- source_match: # 触发抑制匹配
severity: 'critical' # 当告警为critical标签,触发抑制
target_match: # 抑制目标匹配
severity: 'warning' # 抑制目标为warning标签的警告
equal: ['alertname', 'dev', 'instance'] #相等匹配,用于指定需要相等的标签
(5) 定义告警规则
[root@prometheus ~] mkdir /usr/local/prometheus/rules
[root@prometheus ~] vim /usr/local/prometheus/rules/hoststats-alert.rulesgroups:
- name: example
rules:
- alert: InstanceDown # 告警名称
expr: up == 0 # 条件,当内置变量up == 0 为真时
for: 5m # 持续时间超过5min
labels: # 标签
severity: warn # 级别:警告
annotations: # 告警摘要
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes." # 描述信息
- alert: hostMemUsageAlert # 告警名称
expr: (node_memory_MemTotal -node_memory_MemAvailable)/node_memory_MemTotal > 0.85 # 内存占用85%
for: 1m # 持续时间超过1min
labels:
severity: warn # 级别:警告
annotations: # 告警摘要
summary: "Instance {{ $labels.instance }} MEM usgae high"
(6) 在Prometheus中声明规则文件位置
[root@prometheus ~] vim /usr/local/prometheus/prometheus.yml rule_files:
- /usr/local/prometheus/rules/*.rules
[root@prometheus ~] systemctl restart alertmanager.service
[root@prometheus ~] systemctl restart prometheus.service (7) 安装并启动邮件服务
[root@prometheus ~] yum install -y postfix mailx
[root@prometheus ~] systemctl enable postfix --now查看prometheus规则
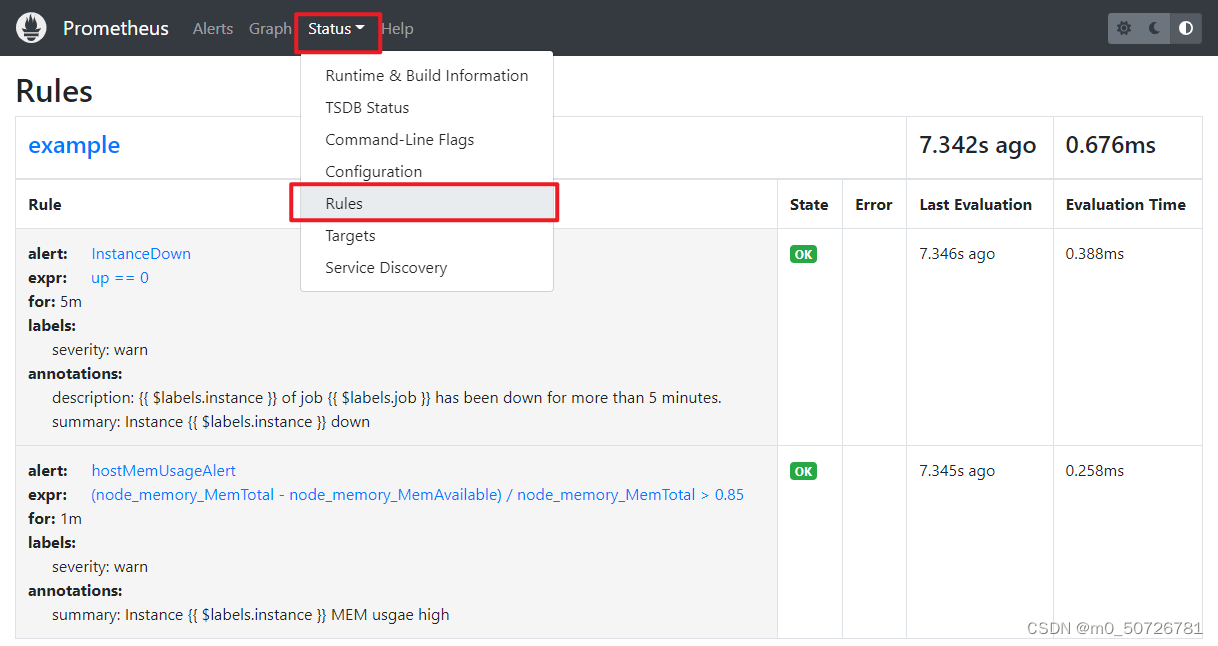
(8) 测试
关闭web1主机,等待5分钟以上,查看邮件:
[root@prometheus ~] mail>N 1 [email protected] Sun Jan 1 18:59 227/10404 "[FIRING:1] InstanceDown (192.168.1.200:9100 prometheus warn)"
查看Alertmanager
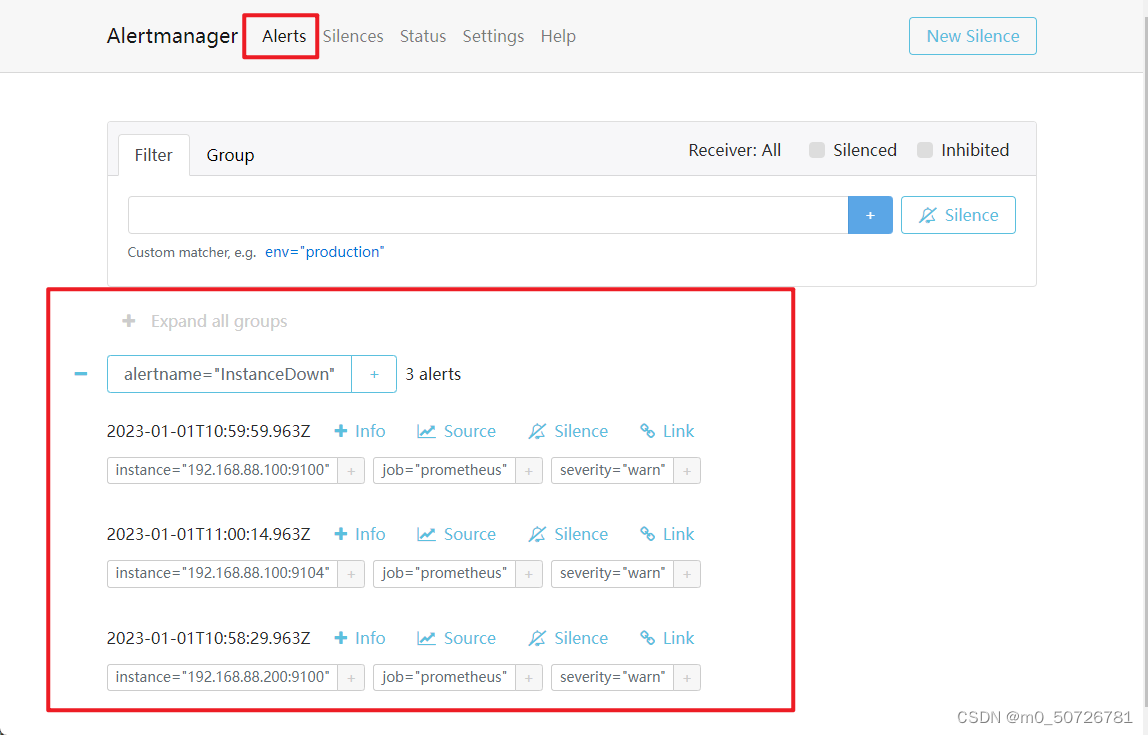
操作到此结束,感谢观看!