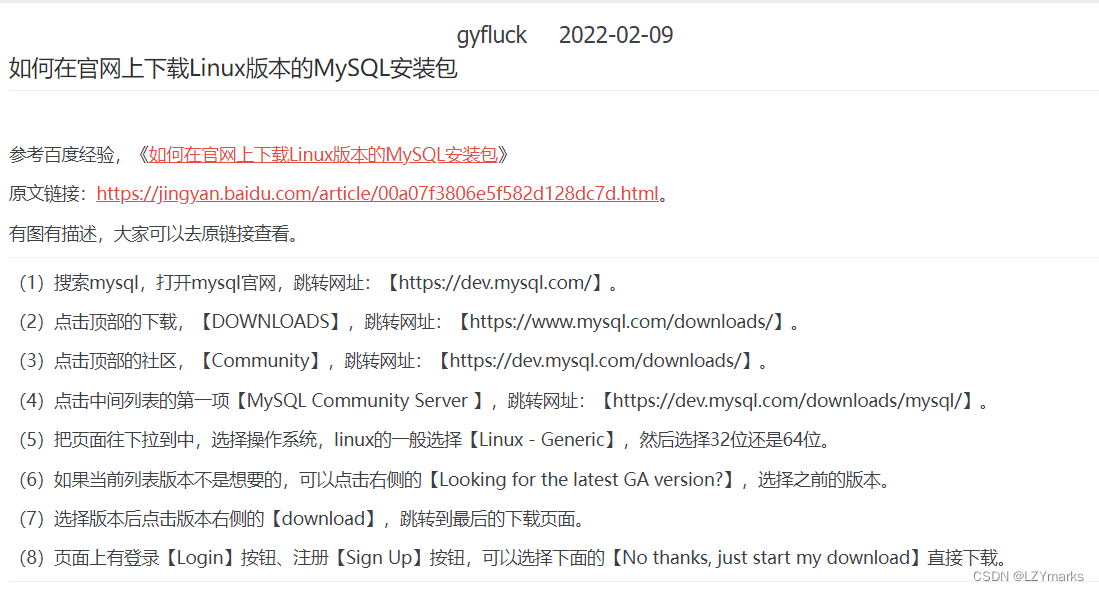
and 和 or 的 !=
or 不等于(条件同时满就不取) ,如两个条件不等于取得值为 除了(两个条件等于),比如 除了 where xingming = ‘a’ and shoujihao = ‘a’
and 不等于(条件只要有一个满足就不取) ,只要有一个不等于都取不到 等于的sql 可以复杂为 select * from table where id in (select id from table where xingming != ‘a’) and shoujihao != ‘a’;
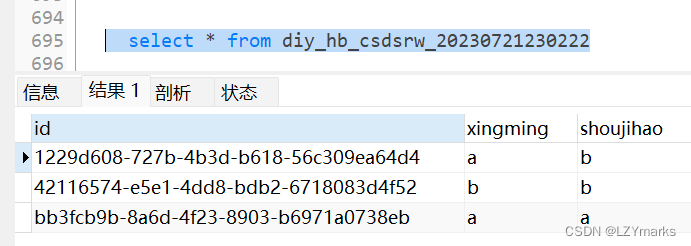
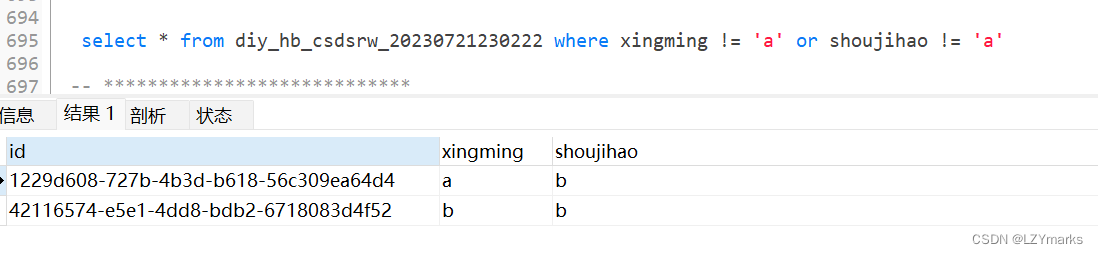
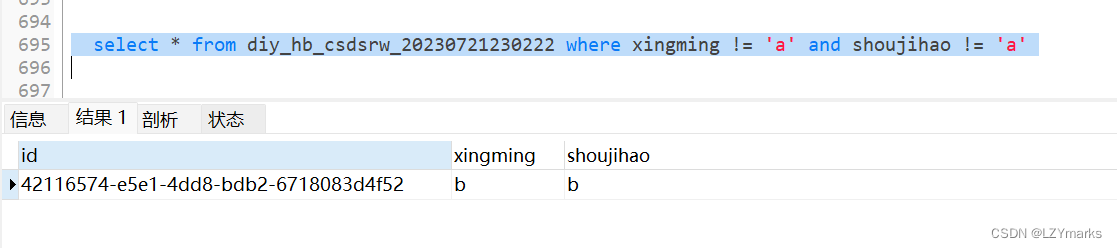
时间date可以直接比较
hiredate date comment ‘入职时间’,
a.hiredate < b.hiredate
CONVERT函数 没有转化为int
CONVERT函数用于将值转换为指定的数据类型或字符集
1.转换指定字符集
CONVERT函数用于将字符串expr的字符集变成transcoding_name
CONVERT(expr USING transcoding_name)
expr: 要转换的值
transcoding_name: 要转换成的字符集
– utf8mb4
SELECT CHARSET(‘ABC’);
– gbk
SELECT CHARSET(CONVERT(‘ABC’ USING gbk));
2.转换指定数据类型
CONVERT函数用于将字符串expr的字符集变成transcoding_name
语法结构
CONVERT(expr,type)
expr: 要转换的值
type: 要转换为的数据类型
– utf8mb4
SELECT CHARSET(‘ABC’);//utf8mb4
– gbk
SELECT CHARSET(CONVERT(‘ABC’ USING gbk));//gbk
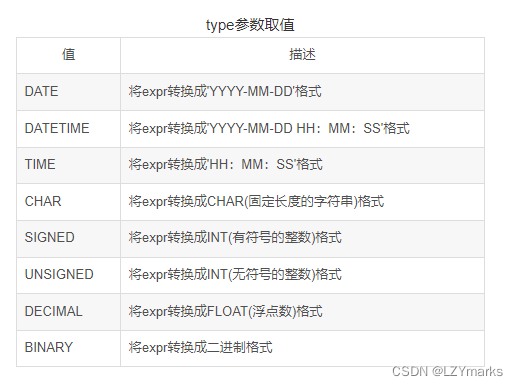
1.将值转换为DATE数据类型
SELECT CONVERT(‘2022-05-25’, DATE);//2022-05-25
SELECT NOW();//2022-09-04 19:45:46
SELECT CONVERT(NOW(), DATE);//2022-09-04
2.将值转换为DATETIME数据类型
SELECT CONVERT(‘2022-05-25’, DATETIME);//2022-05-25 00:00:00
3.将值转换为TIME数据类型
SELECT CONVERT(‘14:06:10’, TIME);//14:06:10
SELECT NOW();//2022-09-04 19:47:53
SELECT CONVERT(NOW(), TIME);//19:47:53
4.将值转换为CHAR数据类型
SELECT CONVERT(150, CHAR);//150
SELECT CONCAT(‘Hello World’,437);// 不报错 Hello World437
– ‘Hello World437’
SELECT CONCAT(‘Hello World’,CONVERT(437, CHAR));// Hello World437
5.将值转换为SIGNED数据类型
SELECT CONVERT(‘5.0’, SIGNED);//5
SELECT (1 + CONVERT(‘3’, SIGNED));//4
SELECT (1 + CONVERT(‘3’, SIGNED))/2; //2.0000
SELECT CONVERT(5-10, SIGNED);//-5
SELECT CONVERT(6.4, SIGNED);//6
SELECT CONVERT(-6.4, SIGNED);//-6
SELECT CONVERT(6.5, SIGNED);//7
SELECT CONVERT(-6.5, SIGNED);//-7
6.将值转换为UNSIGNED数据类型
SELECT CONVERT(‘5.0’, UNSIGNED);//5
SELECT CONVERT(6.4, UNSIGNED);//6
SELECT CONVERT(-6.4, UNSIGNED);//0
SELECT CONVERT(6.5, UNSIGNED);//7
SELECT CONVERT(-6.5, UNSIGNED);//0
7.将值转换为DECIMAL数据类型
SELECT CONVERT(‘9.0’, DECIMAL);//9
– DECIMAL(数值精度,小数点保留长度)
– DECIMAL(10,2)可以存储最多具有8位整数和2位小数的数字
– 精度与小数位数分别为10与2
– 精度是总的数字位数,包括小数点左边和右边位数的总和
– 小数位数是小数点右边的位数
SELECT CONVERT(‘9.5’, DECIMAL(10,2));//9.50
SELECT CONVERT(‘1234567890.123’, DECIMAL(10,2));//99999999.99
SELECT CONVERT(‘220.23211231’, DECIMAL(10,3));//220.232
SELECT CONVERT(220.23211231, DECIMAL(10,3));//220.232
创建数据库
create database MyDB_one; //创建数据库
show databases // 展示数据库
创建表模板
create table sys_userUnit(
name varchar(200) not null,
unitId varchar(200) not null,
userId varchar(200) not null
) engine=innoDB default charset=utf8;
游标模板
DELIMITER //
create PROCEDURE InsertIntoNameAndUtil()
BEGIN
DECLARE testBianLiang VARCHAR(200);
DECLARE endFlage1 int DEFAULT 1;
DECLARE endFlage2 int DEFAULT 0;
#1定义游标
DECLARE insertRuest CURSOR FOR select id,unitId from sys_user suser where id not in (select userId from sys_userUnit );
#2打开游标
OPEN insertRuest;
#2.1开始循环
REPEAT
set endFlage1 = 4;
set endFlage2 = 1;
SELECT endFlage2;
UNTIL endFlage1 > endFlage2
#2.2结束循环
END REPEAT;
#3关闭游标
CLOSE insertRuest;
END //
DELIMITER;
DROP PROCEDURE InsertIntoNameAndUtil;
call InsertIntoNameAndUtil()
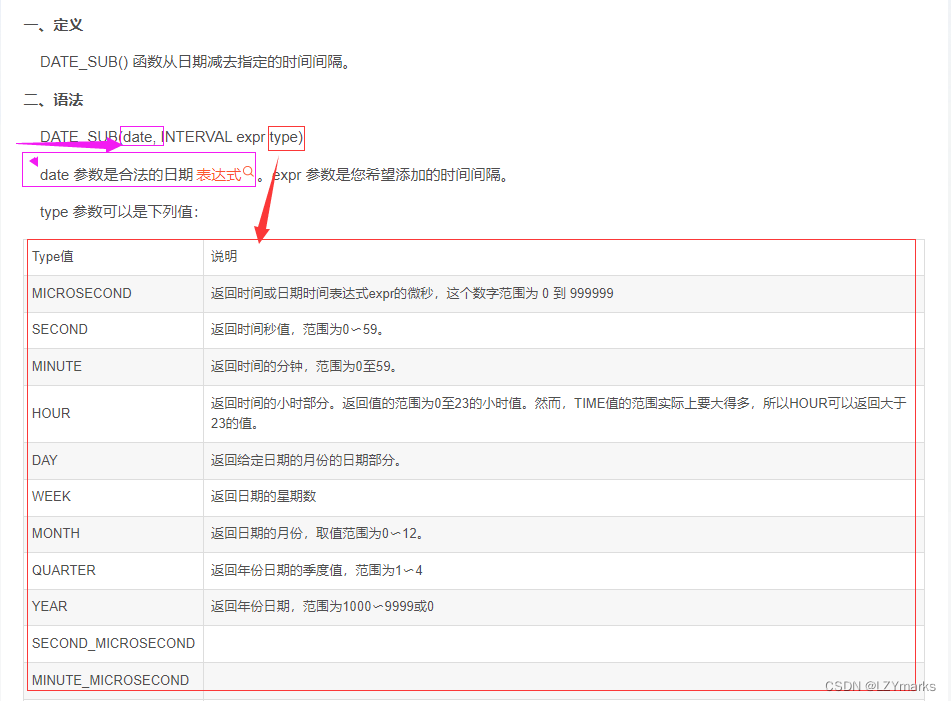
DATE_SUB()函数
CAST函数
CAST函数 与 CONVERT 函数相同,只是函数体不同 CAST 使用 as 而CONVERT 是用逗号
SELECT CAST(‘2017-08-29’ AS DATE); // 2017-08-29
SELECT CONVERT(‘2022-05-25’, DATE);//2022-05-25
各种join的区别
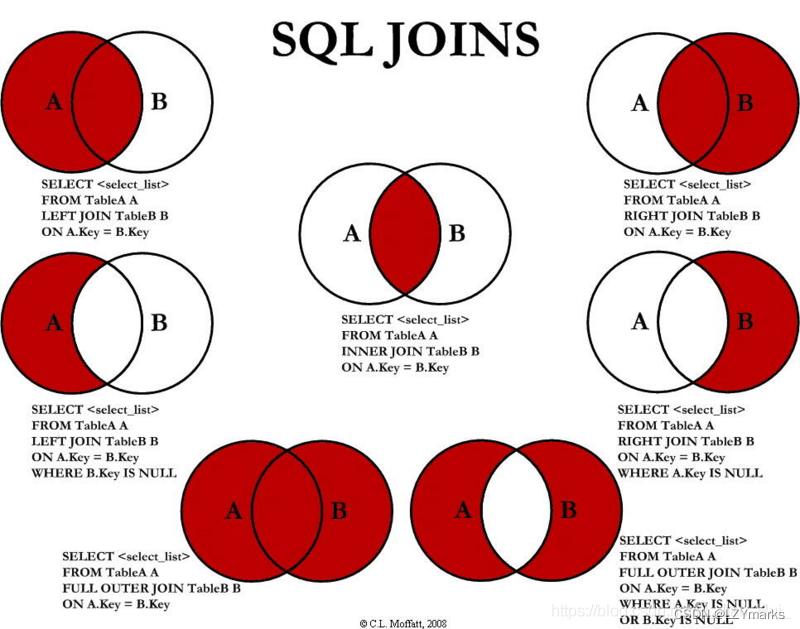
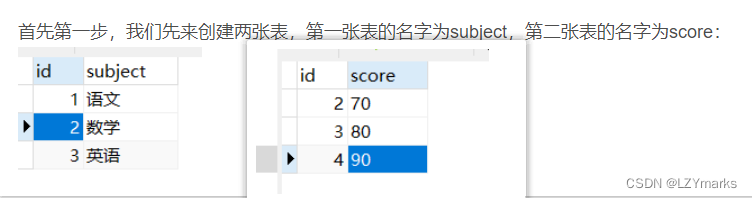
left join
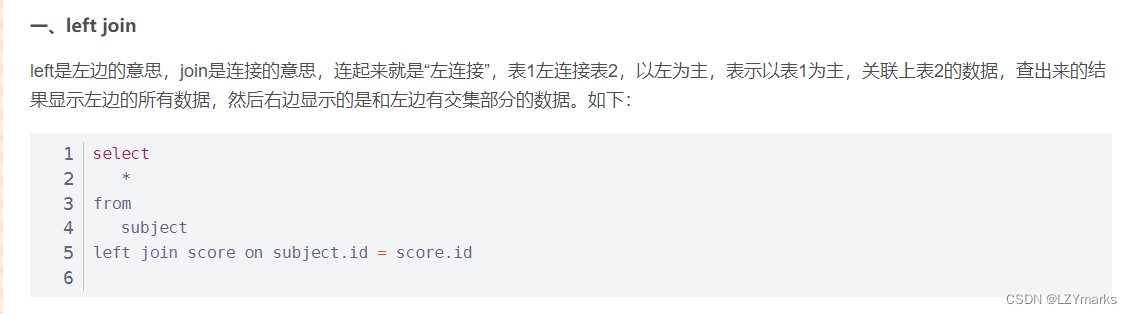
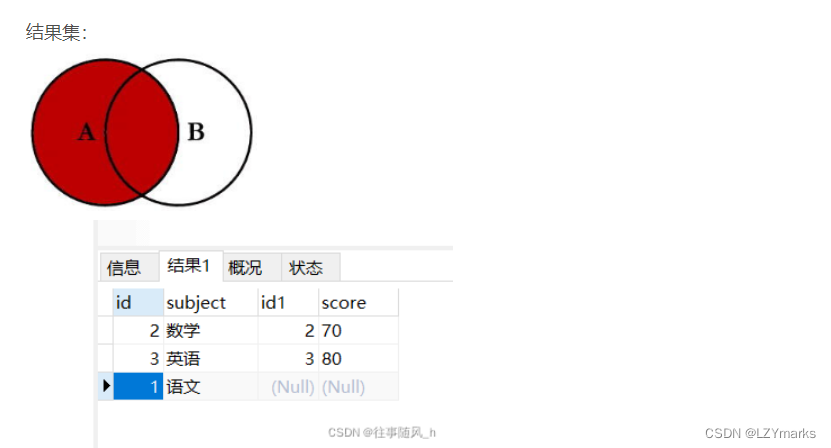
right join
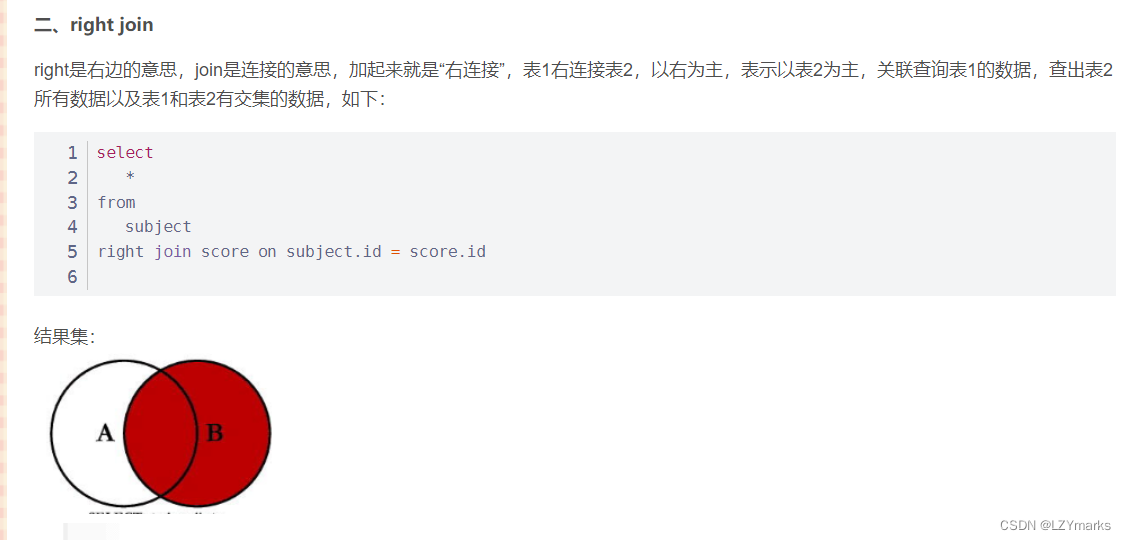
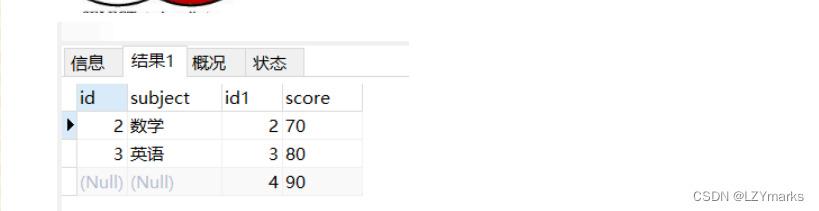
join
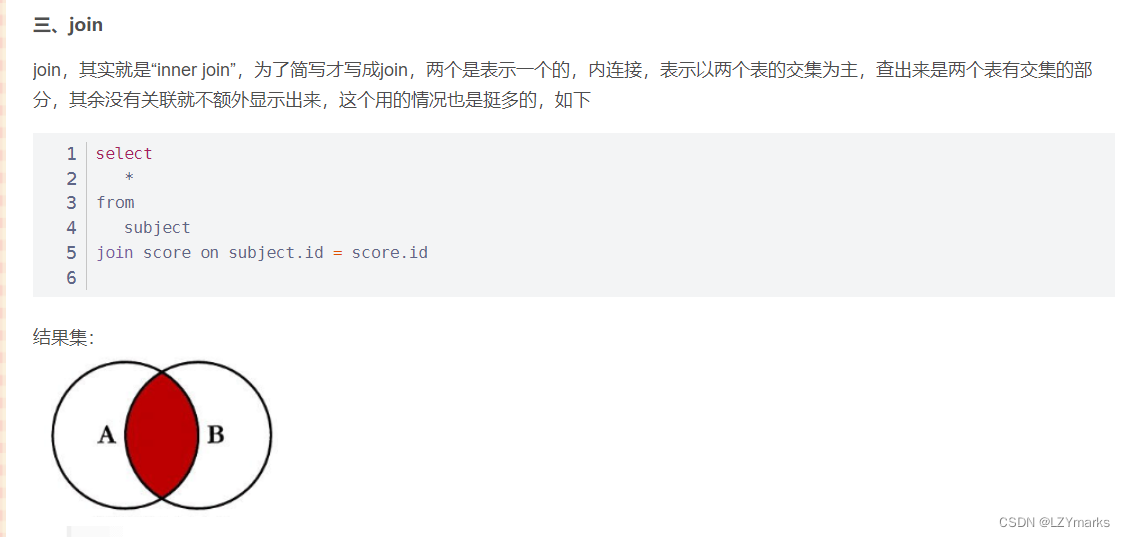
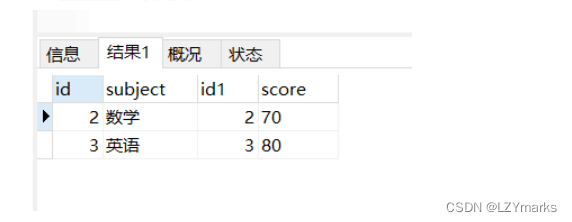
sql执行顺序
1.from
2.on
3.join
4.where
5.group by
6.having
7.select
8.distinct
9.order by
10. limit

distinct 的用法
select distinct(列名) from tableName
对数据列名进行 加减乘除
select 数据列名,数据列名-+*/ 数字
where
where中in的用法
select pname,price from product where price in (200,800);
where中like的用法
where 列名 like ‘%类%’
where 列名 like ‘类’
where中的null
where 列名 is null
where 列名 is not null
求最大值greatest(xx,xx,xx,xxx,xx)
select GREATEST(20,58,69,78,12)
求最小值 least(xx,xxx,xx)
select least(10,20,30)
多个列相加
select id,name,gender,(chinese+english+math) from student;
–查询总分大于200分的所有同学
mysql> select id,name,gender,(chinese+english+math) as count from student
where (chinese+english+math) > 200;
between 和等价sql
-查询英语分数在80-90之间的同学
select * from student where english between 80 and 90
select * from student where english > 80 && english < 90;
select * from student where english > 80 and english < 90;
-查询英语分数不在80-90之间的同学
select * from student where english not between 80 and 90;
select * from student where not (english > 80 && english < 90);
select * from student where not (english > 80 and english < 90)
-查询数学分数为89,90,91的同学
select * from student where math in (89,90,91);
select * from student where math=89 || math=90 || math=91;
select * from student where math=89 or math=90 or math=91;
–子查询
就是selec嵌套
–分为四种:
–1.单行单列:返回的是一个具体的内容,可以理解为一个单值数据
–2.单行多列:返回一行数据中多个列的内容
–3.多行单列:返回多行记录之中同一列的内容,相当于给出了一个操作范围
–4.多行多列:查询返回的结果是一张临时表
–子查询all关键字
格式 select … from … where c > all(查询语句)
-查询年龄大于‘1003’部门所有年龄的员工信息
mysql> select * from emp3 where age > all(select age from emp3 where dept_id=‘1003’);
–子查询any关键字
格式 select … from … where c > any(查询语句)
-查询年龄大于‘1003’ 部门任意员工员工年龄的员工信息
mysql> select * from emp3 where age > any(select age from emp3 where dept_id=‘1003’) and dept_id <>‘1003’;
子查询in关键字,前边还可加not
查询研发部和销售部的员工信息,包含员工号、员工信息
mysql> select * from emp3 where dept_id in(select deptno from dept3 where name in(‘研发部’,‘销售部’))
格式 select … from … where c in (查询语句)
子查询exists关键字
((查询语句)有结果,就执行前面的查询语句,如果没有结果,则不执行前面语句)
–格式 select … from … where exists(查询语句)
–查询公司是否有大于60岁的员工,有则输出
mysql> select * from emp3 a where exists (select age from emp3 where a.age>60);
工资水平多于平均工资的员工
9.返回工资水平多于平均工资的员工
mysql> select * from emp where sal>(select avg(sal) from emp);
-自关联查询
概念:mysql有时在信息查询时需要进行对表自身进行关联查询,即一张表自己和自己关联,一张表当成多张表来用。注意自关联时表必须给表其别名。
–格式:
/*select 字段列表 from 表1 a ,表1 b where 条件;
或者
select 字段列表 from 表1 a [left] join 表1 b on 条件;
*/
视图


sql中 union 和 union all 的用法
如果我们需要将两个 select 语句的结果作为一个整体显示出来,我们就需要用到 union 或者 union all 关键字。union (或称为联合)的作用是将多个结果合并在一起显示出来。
union 和 union all 的区别是,union 会自动压缩多个结果集合中的重复结果,而 union all 则将所有的结果全部显示出来,不管是不是重复。
union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;union 在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表 union。
如下sql:
SELECT create_time FROM e_msku_sku WHERE msku = ‘21-BQLEDNL120W-BK’
UNION
SELECT create_time FROM e_msku_sku WHERE msku = ‘21-BQLEDNL120W-BK’
union all:对两个结果集进行并集操作,包括重复行,不进行排序; 如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
如下sql:
SELECT create_time FROM e_msku_sku WHERE msku = ‘21-BQLEDNL120W-BK’
UNION ALL
SELECT create_time FROM e_msku_sku WHERE msku = ‘21-BQLEDNL120W-BK’
UNION 和 UNION ALL 内部的 SELECT 语句必须拥有相同数量的列
先来说下,如果顺序不同,会是什么结果?
答:结果字段的顺序以union all 前面的表字段顺序为准。
union all 后面的表的数据会按照顺序依次附在后面。注意:按照字段顺序匹配,而不是按照字段名称匹配。
union all 结果字段的顺序以 union all 前面的表字段顺序为准。union all 后面的表的数据会按照字段顺序依次附在后面,而不是按照字段名称匹配。
sql 中的组合in,可用 union all 来代替,提高查询效率
limit
mysql> SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
mysql> SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last.
mysql> SELECT * FROM table LIMIT 5; //检索前 5 个记录行
mysql> SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
mysql> SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last.
mysql> SELECT * FROM table LIMIT 5; //检索前 5 个记录行
select * from auto_dataToYouTasks LIMIT 0,5; // 第1-5条数据
select * from auto_dataToYouTasks limit 5; // 前5条数据
select * from auto_dataToYouTasks limit 10 // 前十条数据
select * from auto_dataToYouTasks limit 5,10 // 从第6行开始 检索10条
select * from table limit (指定页数-1)*每页数,每页数
-交叉连接查询(笛卡尔积)
格式:select * from 表1,表2;
表1中的每一条数据对应表2中的每一条数据
创建表单的时候 给列添加上备注comment
create table tableName(
列名 字段类型 comment ‘备注信息’
);
create table tb_user(
id int comment ‘编号’,
name varchar(50) comment ‘姓名’,
age int comment ‘年龄’,
gender varchar(1) comment ‘性别’
) comment ‘用户表’;
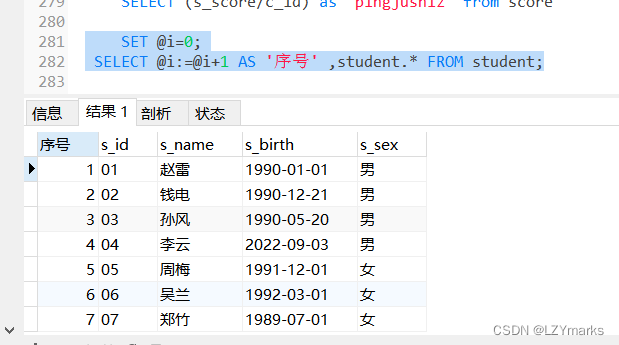
添加序号
方式一
SET @i=0;
SELECT @i:=@i+1 AS ‘序号’ ,student.* FROM student;
方式二
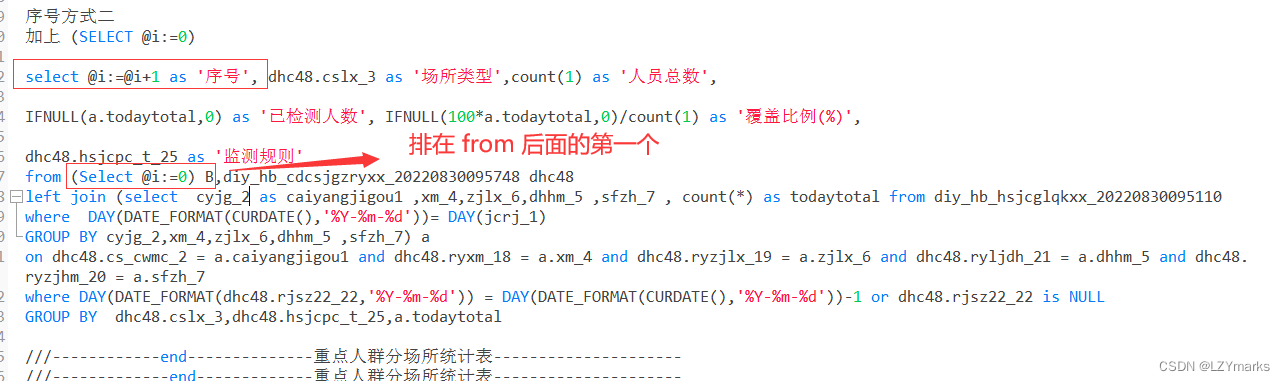
联系题
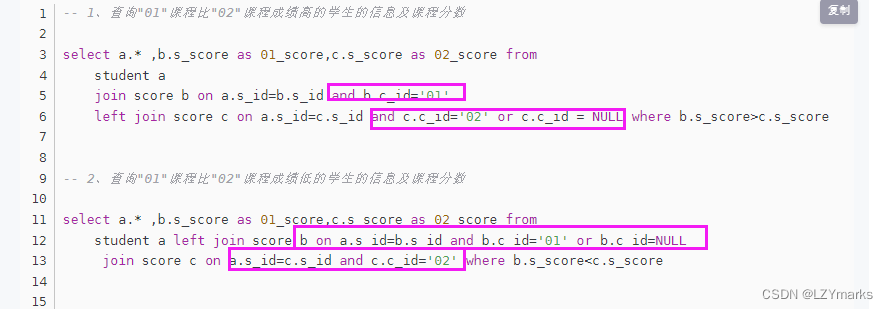
– 1、查询"01"课程比"02"课程成绩高的学生的信息(表列)及课程分数(两个表列)
select st.*,sc.s_score as ‘语文’ ,sc2.s_score ‘数学’
from student st
left join score sc on sc.s_id=st.s_id and sc.c_id=‘01’
left join score sc2 on sc2.s_id=st.s_id and sc2.c_id=‘02’
where sc.s_score>sc2.s_score
思路:
- 首先 select 的列名为 学生信息和 课程分数
student.* ,课程分数01 课程分数02
2. 需要的表from 学生表和课程表
student 和 score
3. 连接方式join 学生表为主表 课程表为副表 left join
4. 连接条件on s_id 和 c_id
5. 判断条件 where
– 2、查询"01"课程比"02"课程成绩低(列与列之间的比较可以使用where判断)的学生的信息(列名)及课程分数(列名)
select st.*,sc.s_score ‘语文’,sc2.s_score ‘数学’ from student st
left join score sc on sc.s_id=st.s_id and sc.c_id=‘01’
left join score sc2 on sc2.s_id=st.s_id and sc2.c_id=‘02’
where sc.s_score<sc2.s_score
– 3、查询平均成绩大于等于60分(having)的同学的学生编号(列表)和学生姓名(列表)和平均成绩(列表)
SELECT st.s_id,st.s_name,ROUND(AVG(sc.s_score),2) as “平均成绩”
FROM student st
LEFT JOIN score sc on sc.s_id = st.s_id
group by st.s_id
HAVING AVG(sc.s_score) >= 60
思路:
- select 学生编号 学生姓名 平均成绩
2.from 学生表和 成绩表 - 连接方式 左连接

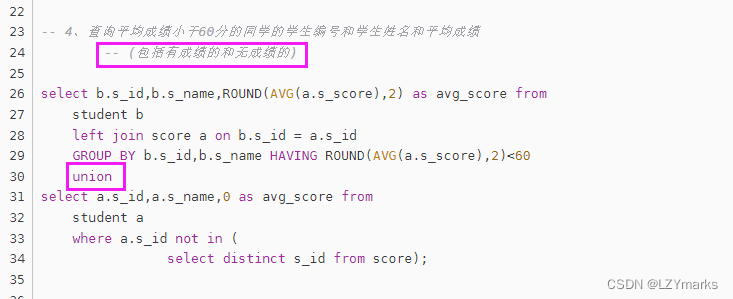
- 4、查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩
-- (包括有成绩的和无成绩的)
题干分析 平均成绩(GROUP BY)小于60(having)里面包括了没有成绩的
没有成绩的用 union 来连接 id not in (SELECT)
select b.s_id,b.s_name,ROUND(AVG(a.s_score),2) as avg_score from
student b
left join score a on b.s_id = a.s_id
GROUP BY b.s_id,b.s_name
HAVING ROUND(AVG(a.s_score),2)<60
union
select a.s_id,a.s_name,0 as avg_score from
student a
where a.s_id not in (
select distinct s_id from score);
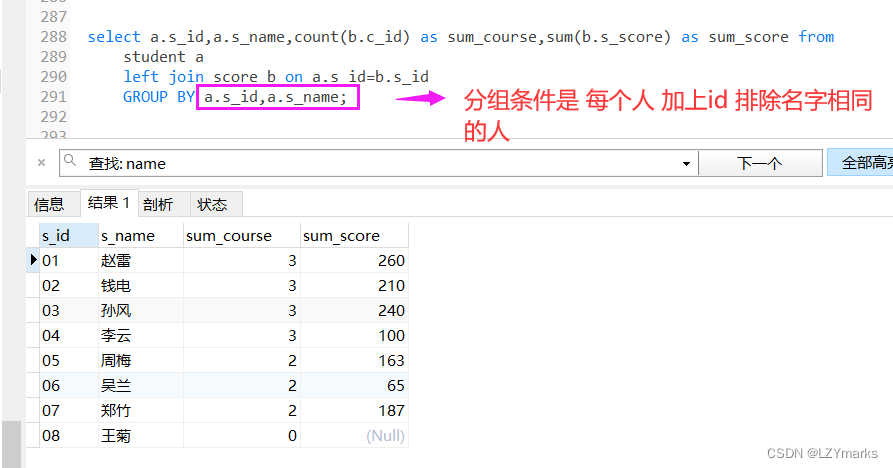
- 5、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
题干分析
查询所有同学的学生编号、学生姓名、选课总数(count(c_id))、所有课程的总成绩(sum(s_score))
需要连表 所有同学 有同学可能没有选择学习的课程 所以要 left JOIN
select stu.s_id, stu.s_name,count(sc.c_id) as '课程总数',sum(sc.s_score) as '总成绩'
from student stu
LEFT join score sc
on stu.s_id = sc.s_id
GROUP BY stu.s_id
-6 查询 李姓老师的数量
分析题干 李姓(like ‘李%’)老师的数量(count)
select count(t_id)
from teacher
where t_name like ‘李%’ ;
-7 查询学过 ‘‘张三’’老师授课的同学的信息
分析题干 查询学过 ‘‘张三’’老师(where条件)授课的同学的信息(select 列名)
学生—》老师
student --> score --> course --> teacher
select stu.*
from student stu
join score sc on stu.s_id = sc.s_id
join course co on sc.c_id = co.c_id
join teacher te on co.t_id = te.t_id
where te.t_name = ‘张三’
-8 查询学过 ‘‘张三老师授课的同学的信息’’
分析题干 查询学过 ‘‘张三”老师(where 条件)授课的同学的信息(select 列名)
同学的id 在没有在老师教的学生id当中
方法一
select *
from student
where s_id not in (
select stu.s_id from
student stu
join score sc on stu.s_id = sc.s_id
join course co on sc.c_id =co.c_id
join teacher te on co.t_id = te.t_id
where te.t_name = ‘张三’
)
方法二
select st.*
from student st
where st.s_id not in(
select sc.s_id
from score sc
where sc.c_id in (
select c.c_id
from course c
left join teacher t on t.t_id=c.t_id
where t.t_name="张三"
)
)
- 9、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
题干分析 查询学过编号为"01"(c_id = 01)并且也学过编号为"02"(c_id = 02)的课程的同学的信息(select student.)
要用到两次c_id 一个表一个where 条件肯定是不行的
用两个一样的表加上学生表联查
方法一
SELECT stu.
from student stu
JOIN score sc1
on stu.s_id = sc1.s_id
join score sc2
on stu.s_id = sc2.s_id
where sc1.c_id = 01 and sc2.c_id = 02
方法二 更快一点
select stu.*
from student stu,score sc1,score sc2
where stu.s_id = sc1.s_id and stu.s_id = sc2.s_id and sc1.c_id = 01 and sc2.c_id = 02
- 10、查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
方法一
SELECT DISTINCT stu.*
from student stu
JOIN score sc1
on stu.s_id = sc1.s_id
join score sc2
on stu.s_id = sc2.s_id
where sc1.c_id = 01 and sc2.c_id != 02
方法二
select DISTINCT stu.*
from student stu,score sc1,score sc2
where stu.s_id = sc1.s_id and stu.s_id = sc2.s_id and sc1.c_id = 01 and sc2.c_id != 02
方法三 最慢
select a.* from
student a
where a.s_id in (select s_id from score where c_id='01' ) and a.s_id not in(select s_id from score where c_id='02')
- 11、查询没有学全所有课程的同学的信息
方法一
1全部课程的数量
select count(1) from course
2没有学完的学生s_id
SELECT s_id from score
GROUP BY s_id
HAVING count(c_id) != (select count(1) from course)
3没有课程的学生
SELECT * from student
where s_id not in (SELECT s_id from score )
4学生信息
SELECT * from student
WHERE s_id in (SELECT s_id from score
GROUP BY s_id
HAVING count(c_id) != (select count(1) from course))
UNION
SELECT * from student
where s_id not in (SELECT s_id from score )
方法二
select s.*
from student s
where s.s_id in(
select s_id
from score
where s_id not in(
// 查询出学完所有课程的学生s_id
// 三个一样的表联查
// 两个on 确定两个课程
// 一个where 确定剩下一个课程
select a.s_id
from score a
join score b on a.s_id = b.s_id and b.c_id=‘02’
join score c on a.s_id = c.s_id and c.c_id=‘03’
where a.c_id=‘01’))
- 12、查询至少有一门课与学号为"01"的同学所学相同的同学的信息
题干分析 查询至少(in)有一门课与(把01同学学的课程查询出来)学号为"01"(where 条件)的同学所学相同的同学的信息 (select 列名)
转化为
题干分析 查询在课程c_id内的同学的信息 (select 列名)
通过有01同学的学生id 根据课程id 根据课程id去查学生id 最后通过学生id去学生信息
查询的表 停留在 学生表 和 成绩表
查询学生信息 当然是单独查学生表student ,那么排除条件就只能剩下用where 排除,学生表能够用的就只有s_id ,s_id 存在的表就只有成绩score表,
select * from student where s_id in (
select distinct s_id
from score
where c_id in
(
select c_id from score where s_id = ‘01’
)
)
-13、查询和"01"号的同学学习的课程完全相同的其他同学的信息
题干分析 查询和"01"号的同学学习的课程完全(课程中的种类还必须是01同学学习过的)(课程数量要相同count()函数)相同的其他同学的信息(select 学生列 要查询学生信息根据学生的ID进行查询)
1查询出 01同学学习的课程、
select c_id from score where s_id = 01
2查询出学了01课程的同学
select s_id from score where s_id != 01 and c_id in (select c_id from score where s_id = 01)
3查询出01同学学习的课程数量
select count(1) from score where s_id = 01
4查询出与01同学学习课程数量相等的学生id
select s_id from score where s_id != 01 and c_id in (select c_id from score where s_id = 01)
GROUP BY s_id
HAVING COUNT(1) = (select count(1) from score where s_id = 01)
5根据学生id查询学生信息
select * from student where s_id in(
select s_id from score where s_id != 01 and c_id in (select c_id from score where s_id = 01)
GROUP BY s_id
HAVING COUNT(1) = (select count(1) from score where s_id = 01)
)
-14、查询没学过"张三"老师讲授的任一门课程的学生姓名
- 查询张三老师的t_id
SELECT t_id from teacher where t_name = ‘张三’ - 查询张三老师t_id 对应的课程C_id
SELECT c_id from course where t_id = (SELECT t_id from teacher where t_name = ‘张三’) - 查询课程id对应的学生s_id
SELECT s_id from score where c_id = (SELECT c_id from course where t_id = (SELECT t_id from teacher where t_name = ‘张三’)) GROUP BY s_id - 查询没有学习过 张三老师课程的学生姓名
SELECT s_name from student where s_id not in (SELECT s_id from score where c_id = (SELECT c_id from course where t_id = (SELECT t_id from teacher where t_name = ‘张三’)) GROUP BY s_id )
-15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
1.查询出课程数量两科以上成绩小于60分的学生id
select s_id
from score
where s_score < 60
GROUP BY s_id
HAVING COUNT(1) >= 2
2. 根据学生id查询学生的平均成绩和学生信息(需要连表)
select stu.s_id,stu.s_name,AVG(sc.s_score)
from student stu
join score sc on stu.s_id = sc.s_id
where stu.s_id in
(
select s_id
from score
WHERE s_score < 60
GROUP BY s_id
HAVING COUNT(1) >= 2
)
- 16、检索"01"课程分数小于60,按分数降序排列的学生信息
题干分析:检索"01"课程(where)分数小于60(where),按分数降序排列(desc)的学生信息(列表)
两张表 可以考虑联查 和 子查询(效率慢)
SELECT stu.* , sco.s_score from student stu
LEFT JOIN score sco
on stu.s_id = sco.s_id
where sco.c_id = 01 and sco.s_score < 60
ORDER BY sco.s_score desc
-* 17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
题干分析 按平均成绩(avg)从高到低(desc)显示所有学生的所有课程的成绩以及平均成绩
第一步 算出平均成绩 并排序
select s_id,
avg(s_score) as avgsocore,
from score sc
GROUP BY s_id
order by avgsocore DESC
第二步 还缺各课程成绩 这里用到的是用子查询代替列名
(select s_score from score where s_id = sc.s_id and c_id = 01) as '语文'
(select s_score from score where s_id = sc.s_id and c_id = 02) as '数学'
(SELECT s_score from score where s_id = sc.s_id and c_id = 03) as '英语'
总和
select a.s_id,
(select s_score from score where s_id=a.s_id and c_id='01') as 语文,
(select s_score from score where s_id=a.s_id and c_id='02') as 数学,
(select s_score from score where s_id=a.s_id and c_id='03') as 英语,
round(avg(s_score),2) as 平均分
from score a
GROUP BY a.s_id
ORDER BY 平均分 DESC;
这样思考
算出每位的平均分
在根据每位的学生id去查对应科目的分数
select a.s_id,
round(avg(s_score),2) as 平均分,
IFNULL((select s_score from score where s_id=a.s_id and c_id=‘01’),0) as 语文,
IFNULL((select s_score from score where s_id=a.s_id and c_id=‘02’),0) as 数学,
IFNULL((select s_score from score where s_id=a.s_id and c_id=‘03’),0) as 英语
from score a
GROUP BY a.s_id
ORDER BY 平均分 DESC;
-* 18.查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率 及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
select
a.c_id,
b.c_name,
MAX(s_score),
MIN(s_score),
ROUND(AVG(s_score),2),
ROUND(
100*(SUM(case when a.s_score>=60 then 1 else 0 end)/SUM(case when a.s_score then 1 else 0 end))
,2) as 及格率,
ROUND(100*(SUM(case when a.s_score>=70 and a.s_score<=80 then 1 else 0 end)/SUM(case when a.s_score then 1 else 0 end)),2) as 中等率,
ROUND(100*(SUM(case when a.s_score>=80 and a.s_score<=90 then 1 else 0 end)/SUM(case when a.s_score then 1 else 0 end)),2) as 优良率,
ROUND(100*(SUM(case when a.s_score>=90 then 1 else 0 end)/SUM(case when a.s_score then 1 else 0 end)),2) as 优秀率
from score a left join course b on a.c_id = b.c_id GROUP BY a.c_id,b.c_name
- 21、查询不同老师所教不同课程平均分从高到低显示
题干分析 查询不同老师所教不同课程(group by t_id,c_id,c_name)平均分(avg(s_score))从高到低显示(desc avg(s_score))
score 是连接 学生表和教师表
SELECT sc.c_id,te.t_id,co.c_name,avg(sc.s_score) as avgscore
from score sc
LEFT JOIN course co
on co.c_id = sc.c_id
left join teacher te
on te.t_id = co.t_id
GROUP BY sc.c_id,te.t_id,co.c_name
order by avgscore desc
- 23、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
解析 每一个总结用一个 select 结果集去表示 通过连表把结果集的信息显示出来
select distinct f.c_name,a.c_id,b.`85-100`,b.百分比,c.`70-85`,c.百分比,d.`60-70`,d.百分比,e.`0-60`,e.百分比
from score a
left join
(select c_id,SUM(case when s_score >85 and s_score <=100 then 1 else 0 end) as `85-100`,
ROUND(100*(SUM(case when s_score >85 and s_score <=100 then 1 else 0 end)/count(*)),2) as 百分比
from score GROUP BY c_id) b on a.c_id=b.c_id
left join (select c_id,SUM(case when s_score >70 and s_score <=85 then 1 else 0 end) as `70-85`,
ROUND(100*(SUM(case when s_score >70 and s_score <=85 then 1 else 0 end)/count(*)),2) as 百分比
from score GROUP BY c_id) c on a.c_id=c.c_id
left join (select c_id,SUM(case when s_score >60 and s_score <=70 then 1 else 0 end) as `60-70`,
ROUND(100*(SUM(case when s_score >60 and s_score <=70 then 1 else 0 end)/count(*)),2) as 百分比
from score GROUP BY c_id) d on a.c_id=d.c_id
left join (select c_id,SUM(case when s_score >=0 and s_score <=60 then 1 else 0 end) as `0-60`,
ROUND(100*(SUM(case when s_score >=0 and s_score <=60 then 1 else 0 end)/count(*)),2) as 百分比
from score GROUP BY c_id) e on a.c_id=e.c_id
left join course f on a.c_id = f.c_id
// 解析 每一个统计数和百分比 分别用一个表去表示
sum里面可以添加 case when then else end 函数 sum会统计每个组里面的每一个函数
select c_id,
SUM(case when s_score >85 and s_score <=100 then 1 else 0 end) as `85-100`,
ROUND(
100*(
SUM(case when s_score >85 and s_score <=100 then 1 else 0 end)/count(*)),
2) as 百分比
from score
GROUP BY c_id
-* 25、查询各科成绩前三名的记录
– 1.选出b表比a表成绩大的所有组
– 2.选出比当前id成绩大的 小于三个的
select a.s_id,a.c_id,a.s_score from score a
left join score b
on a.c_id = b.c_id and a.s_score<b.s_score
group by a.s_id,a.c_id,a.s_score
HAVING COUNT(b.s_id)❤️
ORDER BY a.c_id,a.s_score DESC
-26、查询每门课程被选修的学生数
题干分析 查询每门课程(group by 条件)被选修的学生数(count())
select c_id,count(1)
from score
GROUP BY c_id
-27、查询出只有两门课程的全部学生的学号和姓名
-
查询出只有两门课程的全部学生
查询出只有两门课程(count(*))的学生(gourp by 条件)
select s_id
from score
GROUP BY s_id
HAVING count(1) = 2 -
学生的学号和姓名
select s_id,s_name
from student
WHERE s_id in
(
select s_id
from score
GROUP BY s_id
HAVING count(1) = 2
)
- 28、查询男生、女生人数
题干分析 查询男生、女生人数(s_sex group by count()统计人数)
select s_sex,COUNT(s_sex) as 人数 from student GROUP BY s_sex
- 29、查询名字中含有"风"字的学生信息
select * from student where s_name like '%风%';
- 30、查询同名同性学生名单,并统计同名人数
同一张表的内容比较,两张表相互连接
题干分析:查询同名同性(连接条件)学生名单,并统计同名人数(count(*) 有函数的就要用group by)
两个学生表互联
连接条件名字和性别相同 学生id 不同
select s_name, count(s_id)
from student
group by s_name,s_sex
having count(s_id) > 1;
-31、查询1990年出生的学生名单
题干分析 1990年对应字段使用的是字符串
直接使用模糊查询
select s_name ,s_birth from student where s_birth like ‘1990%’
- 32、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
分析 只用一张表
查询每门课程(group by)的平均成绩(avg 要用分组),
结果按平均成绩降序排列(order by desc),平均成绩相同时,按课程编号升序排列(asc)
SELECT c_id , ROUND(AVG(s_score),2) as avgScore
from score
GROUP BY c_id
ORDER BY avgScore desc, c_id desc;
- 33、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
问题分析 1平均成绩大于等于85的学生
2 学生的学号、姓名和平均成绩
1平均成绩大于等于85的学生
select s_id , ROUND(AVG(s_score),2) as avgscore from score
GROUP BY s_id
HAVING avgscore >= 85
2 学生的学号、姓名和平均成绩
select sc.s_id ,st.s_name , ROUND(AVG(sc.s_score),2) as avgscore
from score sc
join student st on sc.s_id = st.s_id
GROUP BY s_id
HAVING avgscore >= 85
- 34、查询课程名称为"数学",且分数低于60的学生姓名和分数
题干分析
查询课程名称为 数学
select c_id from course where c_name = '数学'
分数低于60分
select s_id from score where s_score < 60 and c_id = (select c_id from course where c_name = '数学' )
学生姓名和分数 (两个表)
select stu.s_name, sc.s_score from student stu
JOIN score sc on sc.s_id = stu.s_id
where sc.s_score < 60 and sc.c_id = (select c_id from course where c_name = '数学' )
-* 35、查询所有学生的课程及分数情况;
// 没有加left join这种方法的只能选择出 语数外都学过的学生
SELECT stu.s_name, sc1.s_score as '语文',sc2.s_score as '数学',sc3.s_score as '英语'
from student stu
left JOIN score sc1 on stu.s_id = sc1.s_id and sc1.c_id = '01'
left join score sc2 on stu.s_id = sc2.s_id and sc2.c_id = '02'
left join score sc3 on stu.s_id = sc3.s_id and sc3.c_id = '03'
// 这个方法相对于上面方法来说 没有null值更具有可读性
select a.s_id,a.s_name,
SUM(case c.c_name when '语文' then b.s_score else 0 end) as '语文',
SUM(case c.c_name when '数学' then b.s_score else 0 end) as '数学',
SUM(case c.c_name when '英语' then b.s_score else 0 end) as '英语',
SUM(b.s_score) as '总分'
from student a left join score b on a.s_id = b.s_id
left join course c on b.c_id = c.c_id
GROUP BY a.s_id,a.s_name
- 36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数;
题干分析
查询任何一门(不要被迷惑用分组判断)课程成绩在70分以上的姓名、课程名称和分数;
=查询课程成绩在70分以上的姓名、课程名称和分数;
查询课程成绩在70分(where 条件)以上的姓名、课程名称和分数(三表查询);
select stu.s_name,co.c_name,sc.s_score
from student stu
JOIN score sc on stu.s_id = sc.s_id
join course co on sc.c_id = co.c_id
where sc.s_score >=70
- 37、查询不及格的课程
题干分析 查询不及格(where)的课程 (连表查询 课程表和成绩表)
select sc.s_score,sc.c_id,co.c_name,sc.s_id
from score sc
join course co on sc.c_id = co.c_id
where sc.s_score < 60
-38、查询课程编号为01且课程成绩在80分以上的学生的学号和姓名;
题干分析 查询课程编号为01(where 条件)且课程成绩在80分以上(where条件)
的学生的学号和姓名(连表查询 课程表 成绩表);
SELECT stu.s_id, stu.s_name
from student stu
JOIN score sc
on stu.s_id = sc.s_id
where sc.c_id = 01 and sc.s_score > 60
- 39、求每门课程的学生人数
题干分析 求每门(group by)课程的学生人数(count(*))
select c_id ,COUNT(*) from score
GROUP BY c_id
- 40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
题干分析 查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
// 该方法 是在确定了学生id的情况下查询
1查询选修"张三"老师所授课程
select c_id from teacher where t_name = '张三',
2 "张三"老师所授课程的学生
select s_id from score where c_id in (select c_id from teacher where t_name = '张三')
3 成绩最高(max)的学生信息及其成绩(两表查询)
SELECT max(sc.s_score) ,stu.* from
student stu
JOIN score sc on stu.s_id = sc.s_id
where stu.s_id in (select s_id from score where c_id in (select c_id from teacher where t_name = '张三'))
// 该方法 是在分别确认学生标号和课程标号的情况下查询
– 查询老师id
select c_id from course c,teacher d where c.t_id=d.t_id and d.t_name=‘张三’
– 查询最高分(可能有相同分数)
select MAX(s_score) from score where c_id=‘02’
– 查询信息
select a.*,b.s_score,b.c_id,c.c_name from student a
LEFT JOIN score b on a.s_id = b.s_id
LEFT JOIN course c on b.c_id=c.c_id
where b.c_id =(select c_id from course c,teacher d where c.t_id=d.t_id and d.t_name=‘张三’)
and b.s_score in (select MAX(s_score) from score where c_id=‘02’)
-* 41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
错的
csdn上的答案 select DISTINCT b.s_id,b.c_id,b.s_score from score a,score b where a.c_id != b.c_id and a.s_score = b.s_score
修改为
select DISTINCT b.s_id,b.c_id,b.s_score from score a,score b where a.c_id != b.c_id and a.s_score = b.s_score and a.s_id = b.s_id
解析 一个表就可以了 要进行表中数据的比较所以需要连表
条件 不同课程成绩相同 c_id 不同 c_score相同
有重复数据
select distinct sc1.s_id, sc1.c_id ,sc2.c_id,sc2.s_score from score sc1
JOIN score sc2
on sc1.c_id != sc2.c_id and sc1.s_score = sc2.s_score and sc1.s_id = sc2.s_id
对的
select * from score as sc1
where exists(SELECT * from score as sc2 where sc1.s_id = sc2.s_id and sc1.c_id != sc2.c_id and sc2.s_score = sc1.s_score )
-* 42、查询每门功课成绩最好的前两名
方法一
– 牛逼的写法
select a.s_id,a.c_id,a.s_score from score a
where (select COUNT(1) from score b where b.c_id=a.c_id and b.s_score>=a.s_score)<=2 ORDER BY a.c_id
方法二
select sc.c_id, sc.s_id
from score sc
left join score sb
on sc.c_id = sb.c_id
and sc.s_score < sb.s_score
group by sc.c_id, sc.s_id
having count(sc.c_id) < 2
- 43、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
题干分析
1.统计每门(group by)课程的学生选修人数(count(*))(超过5人的课程才统计 HAVING() )。
2.要求输出课程号(列名)和选修人数(列名),查询结果按人数降序(order by Desc)排列,若人数相同,按课程号(asc)升序排列
SELECT c_id , count(*) as total
from score
GROUP BY c_id
HAVING total > 5
ORDER BY total DESC, c_id ASC
select c_id,count(*) as total from score GROUP BY c_id HAVING total>5 ORDER BY total,c_id ASC
- 44、检索至少选修两门课程的学生学号
题干分析 检索至少选修两门课程(成绩表中的该id有两条信息)的学生学号
select s_id,count(*) as countAll from score
GROUP BY s_id
having countAll >= 2
- 45、查询选修了全部课程的学生信息
题干分析 查询选修了全部课程的学生信息
1.全部课程的数量 课程表中去查
select count(*) from course
2.在成绩表中查询满足1条件的学生id
SELECT s_id from score
GROUP BY s_id
HAVING count(*) = (select count(*) from course)
3.根据id 查询学生信息
select * from student where s_id in ( SELECT s_id from score
GROUP BY s_id
HAVING count(*) = (select count(*) from course))
-46、查询各学生的年龄
-- 按照出生日期来算,当前月日 < 出生年月的月日则,年龄减一
得到现在年份和出生年份直接间的差值
判断是否今年到现在已经过个生日,是则减0 不是则-1
用 ( DATE_FORMAT(NOW(),‘%Y’)-DATE_FORMAT(NOW(),‘%Y’)-(case when DATE_FORMAT(NOW(),‘%m%d’) )> DATE_FORMAT(s_birth,‘%m%d’) then 0 else 1 end)) as age
select s_birth,(DATE_FORMAT(NOW(),'%Y')-DATE_FORMAT(s_birth,'%Y') -
(case when DATE_FORMAT(NOW(),'%m%d')>DATE_FORMAT(s_birth,'%m%d') then 0 else 1 end)) as age
from student;
- 47、查询本周过生日的学生
select * from student where WEEK(DATE_FORMAT(NOW(),'%Y%m%d'))=WEEK(s_birth)
select * from student where YEARWEEK(s_birth)=YEARWEEK(DATE_FORMAT(NOW(),'%Y%m%d'))
一年的第几周 select WEEK(DATE_FORMAT(NOW(),‘%Y%m%d’))
- 48、查询下周过生日的学生
获取当前的第几周 Week(Date_Format(now(),%y%m%d)
通过字符串获取当前第几周
select * from student where
WEEK(DATE_FORMAT(NOW(),'%Y%m%d'))+1 =WEEK(s_birth)
- 49、查询本月过生日的学生
计算现在的月份 Month(Date_Format(now(),‘%y%m%d’))
通过string = ‘1998-09-09’ 得到月份 Month(string)
select * from student
where MONTH(DATE_FORMAT(NOW(),'%Y%m%d')) =MONTH(s_birth)
- 50、查询下月过生日的学生
计算现在的月份 Month(Date_Format(now(),‘%y%m%d’))
根据字符串 得到现在的月份 Month(string)
string=1990-01-01
select * from student
where MONTH(DATE_FORMAT(NOW(),'%Y%m%d'))+1 =MONTH(s_birth)
效率查询语句
查询进程
select * from information_schema.innodb_trx;
报错全部
1242 - Subquery returns more than 1 row

DateFormat 当中得到年份要用大Y 不能用小y
每日复习
1join on 的on后面还可以加条件
2某数据小于 == 包括真正小于的 和(union) 没有数据的
3每个学生的 ----- 分组条件已改是学生信息

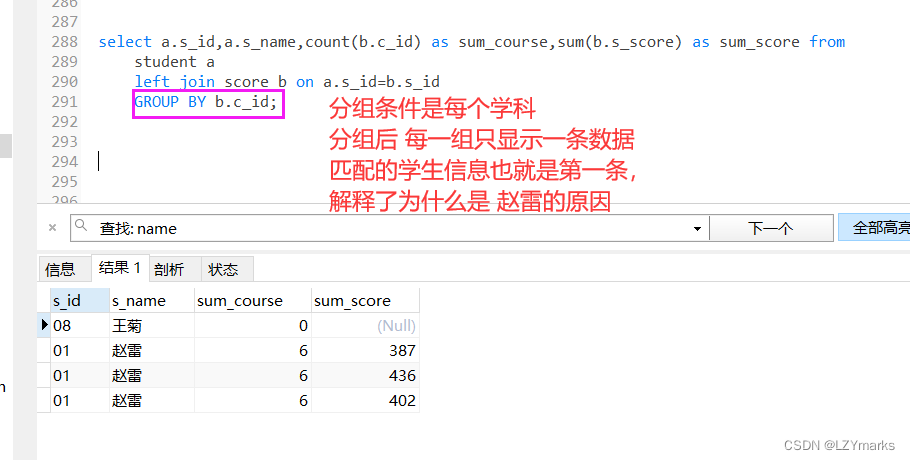
4相同列名 却有两种不同的条件 把一张表看成两张表
5 having count(xx) = (select 字句)

6 既要求平均值,也要各科分数

select a.s_id,
(select s_score from score where s_id=a.s_id and c_id='01') as 语文,
(select s_score from score where s_id=a.s_id and c_id='02') as 数学,
(select s_score from score where s_id=a.s_id and c_id='03') as 英语,
round(avg(s_score),2) as 平均分
from score a
GROUP BY a.s_id
ORDER BY 平均分 DESC;
7 查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率 --及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
select
a.c_id,
b.c_name,
MAX(s_score),
MIN(s_score),
ROUND(AVG(s_score),2),
ROUND(
100*(SUM(case when a.s_score>=60 then 1 else 0 end)/SUM(case when a.s_score then 1 else 0 end))
,2) as 及格率,
ROUND(100*(SUM(case when a.s_score>=70 and a.s_score<=80 then 1 else 0 end)/SUM(case when a.s_score then 1 else 0 end)),2) as 中等率,
ROUND(100*(SUM(case when a.s_score>=80 and a.s_score<=90 then 1 else 0 end)/SUM(case when a.s_score then 1 else 0 end)),2) as 优良率,
ROUND(100*(SUM(case when a.s_score>=90 then 1 else 0 end)/SUM(case when a.s_score then 1 else 0 end)),2) as 优秀率
from score a left join course b on a.c_id = b.c_id GROUP BY a.c_id,b.c_name
8统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
select distinct f.c_name,
a.c_id,
b.`85-100`,
b.百分比,
c.`70-85`,
c.百分比,
d.`60-70`,
d.百分比,
e.`0-60`,
e.百分比 from score a
left join (select c_id,
SUM(case when s_score >85 and s_score <=100 then 1 else 0 end) as `85-100`,
ROUND(100*(SUM(case when s_score >85 and s_score <=100 then 1 else 0 end)/count(*)),2) as 百分比
from score
GROUP BY c_id)b
on a.c_id=b.c_id
left join (select c_id,SUM(case when s_score >70 and s_score <=85 then 1 else 0 end) as `70-85`,
ROUND(100*(SUM(case when s_score >70 and s_score <=85 then 1 else 0 end)/count(*)),2) as 百分比
from score GROUP BY c_id)c on a.c_id=c.c_id
left join (select c_id,SUM(case when s_score >60 and s_score <=70 then 1 else 0 end) as `60-70`,
ROUND(100*(SUM(case when s_score >60 and s_score <=70 then 1 else 0 end)/count(*)),2) as 百分比
from score GROUP BY c_id)d on a.c_id=d.c_id
left join (select c_id,SUM(case when s_score >=0 and s_score <=60 then 1 else 0 end) as `0-60`,
ROUND(100*(SUM(case when s_score >=0 and s_score <=60 then 1 else 0 end)/count(*)),2) as 百分比
from score GROUP BY c_id)e on a.c_id=e.c_id
left join course f on a.c_id = f.c_id
简化版
8统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
select
distinct f.c_name,
a.c_id,
b.`85-100`,
b.百分比
from score a
left join (select c_id,
SUM(case when s_score >85 and s_score <=100 then 1 else 0 end) as 85-100,
ROUND(100*(SUM(case when s_score >85 and s_score <=100 then 1 else 0 end)/count(*)),2) as 百分比
from score
GROUP BY c_id)b
on a.c_id=b.c_id
left join course f on a.c_id = f.c_id
9 成绩前三名的记录
select a.s_id,a.c_id,a.s_score from score a
left join score b
on a.c_id = b.c_id and a.s_score<b.s_score
group by a.s_id,a.c_id,a.s_score
HAVING COUNT(b.s_id) ❤️
ORDER BY a.c_id,a.s_score DESC
10 查看同名同姓的人 group by 后面加没有在列名上的项
select s_name, count(s_id)
from student
group by s_name,s_sex
having count(s_id) > 1;
11、查询所有学生的课程及分数情况;
select a.s_id,a.s_name,
SUM(case c.c_name when '语文' then b.s_score else 0 end) as '语文',
SUM(case c.c_name when '数学' then b.s_score else 0 end) as '数学',
SUM(case c.c_name when '英语' then b.s_score else 0 end) as '英语',
SUM(b.s_score) as '总分'
from student a left join score b on a.s_id = b.s_id
left join course c on b.c_id = c.c_id
GROUP BY a.s_id,a.s_name
12 最高的成绩,可能存在多个学生有这最高的成绩

13 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
select DISTINCT b.s_id,b.c_id,b.s_score from score a,score b where a.c_id != b.c_id and a.s_score = b.s_score and a.s_id = b.s_id
select * from score as sc1
where exists(SELECT * from score as sc2
where sc1.s_id = sc2.s_id and sc1.c_id != sc2.c_id and sc2.s_score = sc1.s_score )
14 查询每门功课成绩最好的前两名
select a.s_id,a.c_id,a.s_score
from score a
where (select COUNT(1) from score b where b.c_id=a.c_id and b.s_score>=a.s_score)<=2
ORDER BY a.c_id
select sc.c_id, sc.s_id
from score sc
left join score sb
on sc.c_id = sb.c_id
and sc.s_score < sb.s_score
group by sc.c_id, sc.s_id
having count(sc.c_id) < 2
15 group by 的条件是谁 检索至少选修两门课程的学生学号
select s_id,count(*) as sel from score GROUP BY s_id HAVING sel>=2
16 判断年龄 不仅要判断年 还要判断日期是否一过
select s_birth,
(DATE_FORMAT(NOW(),‘%Y’)-DATE_FORMAT(s_birth,‘%Y’) -
(case when DATE_FORMAT(NOW(),‘%m%d’)>DATE_FORMAT(s_birth,‘%m%d’) then 0 else 1 end)) as age
from student;
select s_birth,(DATE_FORMAT(CURDATE(),'%Y')-DATE_FORMAT(s_birth,'%Y') -
(case when DATE_FORMAT(CURDATE(),'%m%d')>DATE_FORMAT(s_birth,'%m%d') then 0 else 1 end)) as age
from student;
select DATE_FORMAT(NOW(),'%m%d') # 结果是0907
select DATE_FORMAT('2022-09-05','%m%d') # 结果是0905
select DATE_FORMAT(NOW(),'%m-%d') # 结果是 09-07
select DATE_FORMAT('2022-09-05','%m-%d') # 结果是 09-05
select DATE_FORMAT(NOW(),'%Y') #2022
select DATE_FORMAT('2022-09-05','%Y') #结果是2022
17 时间处理
前提是正常的时间格式
17.1 时间大小的比较 时间类型的字符串可以之间比较
SELECT ‘2022-09-08’ <= DATE_ADD(curdate(),INTERVAL 12 hour) #结果为1
SELECT ‘2022-09-08 13:00:00’ < DATE_ADD(curdate(),INTERVAL 12 hour) #结果为0
select DATE_ADD(curdate(),INTERVAL 12 hour) #2022-09-08 12:00:00
SELECT NOW() #2022-09-08 15:36:50
select NOW() < DATE_ADD(curdate(),INTERVAL 12 hour) #结果为0
SELECT ‘2022-09-08 13:00:00’ < ‘2022-09-08 11:00:00’ #结果为0
SELECT ‘2022-09-08 13:00:00’ < ‘2022-09-08 16:00:00’ #结果为1
SELECT ‘2022-09-08’ < ‘2022-09-09’ #结果为1
SELECT ‘2022-09-10’ < ‘2022-09-09’ #结果为0
SELECT ‘2022-09-08’ < ‘2022-09-08 16:00:00’ #结果为1
SELECT ‘2022-09-09’ < ‘2022-09-08 16:00:00’ #结果为0
17.2前 n 天的时间
select CURDATE() #2022-09-08
select CURTIME() #15:19:15
select NOW() #2022-09-08 15:19:36
SELECT DATE_add(NOW(),INTERVAL -7 DAY);#获取7天前的日期 2022-09-01 15:20:02
SELECT DATE_add(NOW(),INTERVAL 7 DAY);#获取7天后的日期 2022-09-15 15:20:02
SELECT DATE_add(curdate(),INTERVAL -7 DAY);#获取7天前的日期 2022-09-01
SELECT DATE_add(curdate(),INTERVAL 7 DAY);#获取7天后的日期 2022-09-15
SELECT DATE_SUB(NOW(),INTERVAL -7 DAY);#获取7天后的日期 2022-09-15 15:20:19
SELECT DATE_SUB(NOW(),INTERVAL 7 DAY);#获取7天前的日期 2022-09-01 15:20:19
SELECT DATE_SUB(curdate(),INTERVAL -7 DAY);#获取7天后的日期 2022-09-15
SELECT DATE_SUB(curdate(),INTERVAL 7 DAY);#获取7天前的日期 2022-09-01
17.3前n个小时
SELECT DATE_ADD(curdate(),INTERVAL -12 hour) # 2022-09-08当天时间(默认为当天0点) 2022-09-07 12:00:00
SELECT DATE_ADD(curdate(),INTERVAL 12 hour) #2022-09-07 12:00:00
SELECT DATE_ADD(NOW(),INTERVAL -12 hour) # 2022-09-08 03:25:43
SELECT DATE_ADD(NOW(),INTERVAL 12 hour) #2022-09-09 03:25:56
17.4前 n 天的时间 前n个小时
星期一的12点之后 到 星期二的12点之前
DATE_ADD(date_sub(curdate(),INTERVAL WEEKDAY(curdate())-1 DAY),INTERVAL -12 hour)
时间字符串<= DATE_ADD(date_sub(curdate(),INTERVAL WEEKDAY(curdate())-1 DAY),INTERVAL 12 hour))
17.5周一至周日
星期一
select date_sub(curdate(),INTERVAL WEEKDAY(curdate()) DAY) #结果为2022-09-05
select date_sub(curdate(),INTERVAL WEEKDAY(curdate())-1 DAY) #结果为2022-09-06
select date_sub(curdate(),INTERVAL WEEKDAY(curdate())-2 DAY) #结果为2022-09-07
select date_sub(curdate(),INTERVAL WEEKDAY(curdate())-3 DAY) #结果为2022-09-08
select date_sub(curdate(),INTERVAL WEEKDAY(curdate())-4 DAY) #结果为2022-09-09
select date_sub(curdate(),INTERVAL WEEKDAY(curdate())-5 DAY) #结果为2022-09-10
select date_sub(curdate(),INTERVAL WEEKDAY(curdate())-6 DAY) #结果为2022-09-11
近一周的时间
DATE_FORMAT( ‘时间字符串’, ‘%Y-%m-%d’ )>= DATE_SUB( CURDATE(), INTERVAL 6 DAY )
上周的今天 采样时间 >= DATE_ADD(CURDATE(),INTERVAL -7 day)
17.6本周
WEEK(DATE_FORMAT(NOW(),‘%Y%m%d’)) = WEEK(s_birth) #系统会报错
计算当前周用 WEEK(now()) 代替 (DATE_FORMAT(NOW(),‘%Y%m%d’))
SELECT YEARWEEK(DATE_FORMAT(NOW(),‘%Y%m%d’))#结果为 202236
SELECT YEARWEEK(NOW()) #结果为 202236
SELECT YEARWEEK(‘2022-09-07’) #结果为 202236
SELECT WEEK(DATE_FORMAT(NOW(),‘%Y%m%d’)) #结果为36
SELECT WEEK(NOW()) #结果为36
SELECT WEEK(‘2022-09-07’) #结果为36
SELECT WEEK(‘09-07’) #null
17.7下周
WEEK(NOW())+1
17.8本月的MONTH
SELECT MONTH(DATE_FORMAT(NOW(),'%Y%m%d')) #结果为 9
SELECT MONTH(NOW()) #结果为 9
17.9下个月
SELECT MONTH(DATE_FORMAT(NOW(),'%Y%m%d'))+1 #结果为 10
SELECT MONTH(NOW())+1 #结果为 10
17.10 昨天
date_sub(curdate(),INTERVAL -1 DAY) = DATE_FORMAT(时间字符串,‘%Y-%m-%d’))
18 可以使用case 来创建列
case when (select 函数()where 条件加入 与主表的连接关系) then 列值 else 列值 end
19 sum()可以添加参数
统计 想要的总数可以在 sum()方法添加条件
select c_id,sum(s_score = ‘80’) as ‘80score’ , SUM(s_score = ‘90’) as ‘90score’ from score GROUP BY c_id
20 now() 与 curdate()的比较
now()时间转化 = 2022-08-21 10:29:39
WHEN DATE_FORMAT( ‘2022-08-21 10:29:39’, ‘%Y-%m-%d’ ) = DATE_SUB( CURDATE(), INTERVAL 2 DAY ) THEN
21 case 语法
CASE
WHEN 条件1 THEN
结果1
WHEN 条件2, INTERVAL 1 DAY ) THEN
结果2
WHEN 条件3, INTERVAL 2 DAY ) THEN
结果3
WHEN 条件4, INTERVAL 3 DAY ) THEN
结果4
WHEN 条件5, INTERVAL 4 DAY ) THEN
结果5
WHEN 条件6, INTERVAL 5 DAY ) THEN
结果6
WHEN 条件7, INTERVAL 6 DAY ) THEN
结果7 ELSE 兜底结果X
END
22 case when 中可以用like

case when 判断 null值
case when diyc.tableId is null then ‘否’ else ‘是’ end ‘是否配置Js’
23 if的用法

时间
#查询2020的数据:
select * from table where year(column)='2020';
#查找月份为12的数据:
select * from table where month(column)='12';
#查找天数为本年第二天的数据:
select * from table where dayofyear(column)='2';
#查询当月数据:
select * from table where date_format(column,'%Y-%m')=date_format(now(),'%Y-%m'
#mysql中获取本月第一天、本月最后一天、上月第一天、上月最后一天…
# 本年第一天
select date_sub(curdate(), interval dayofyear(curdate())-1 day);
SELECT curdate() - INTERVAL(dayofyear(curdate()) - 1) DAY;
# 本年最后一天
select concat(year(curdate()),'-12-31');
# 上年最后一天
select date_sub(curdate(), interval dayofyear(curdate()) day);
# 下年第一天(本年第一天加一年)
SELECT (curdate() - INTERVAL(dayofyear(curdate()) - 1) DAY) + INTERVAL 1 YEAR;
# 本月第一天
select date_add(curdate(), interval - day(curdate()) + 1 day);
# 本月最后一天
select last_day(curdate());
# 上月第一天
select date_add(curdate()-day(curdate())+1,interval -1 month);
# 上月最后一天
select last_day(date_sub(now(),interval 1 month));
# 下月第一天
select date_add(curdate()-day(curdate())+1,interval 1 month);
# 下月最后一天
select last_day(date_sub(now(),interval -1 month));
# 本月天数
select day(last_day(curdate()));
# 上月今天的当前日期
select date_sub(curdate(), interval 1 month);
# 上月今天的当前时间(时间戳)
select unix_timestamp(date_sub(now(),interval 1 month));
# 获取当前时间与上个月之间的天数
select datediff(curdate(), date_sub(curdate(), interval 1 month));
# 本周第一天:
select date_sub(curdate(),INTERVAL WEEKDAY(curdate()) + 1 DAY);
# 本周最后一天:
select date_sub(curdate(),INTERVAL WEEKDAY(curdate()) - 5 DAY);
# 上周第一天:
select date_sub(curdate(),INTERVAL WEEKDAY(curdate()) + 8 DAY);
# 上周最后一天:
select date_sub(curdate(),INTERVAL WEEKDAY(curdate()) + 2 DAY);
字符串截取 left right
left(‘字符串’,数字) 数字代表取字符串的位置
#1 代表 字符串的第一个位置上的数
0 代表空字符串
select LENGTH(‘123456’) 结果为 6
select left(‘123456’,0) 结果为 ‘’
select left(‘123456’,1) 结果为 ‘1’
select left(‘123456’,2) 结果为 ‘12’
select left(‘123456’,6) 结果为 ‘123456’
select substring(‘1234’,1) #1234
right(‘字符串’,数字) 数字代表取字符串的位置
‘红川街道不是人’
select LOCATE(‘红’,‘红川街道不是人’) #1
select RIGHT(‘红川街道不是人’,1) #‘人’
select LOCATE(‘川’,‘红川街道不是人’) #2
select RIGHT(‘红川街道不是人’,2) #‘是人’
字符串定位locate
locate(substr,str,pos) 表示从pos位置开始算,返回substr第一次出现在字符串str中的位置,没有返回0
SELECT locate(‘/’,‘四川省/成都市/新津区/兴义镇/岷江社区’,12) #12
SELECT locate(‘兴’,‘四川省/成都市/新津区/兴义镇/岷江社区’,12) #13
locate(substr,str) 表示返回字符串substr第一次出现字符串str中的位置
SELECT locate(‘/’,‘四川省/成都市/新津区/兴义镇/岷江社区’) #4
substring(字符串,截取位置) 截取位置从1开始截取
SELECT SUBSTRING(‘123456’,0) #结果为 ‘’
SELECT SUBSTRING(‘123456’,1) #结果为 ‘123456’
SELECT SUBSTRING(‘123456’,2) #结果为 ‘23456’
SELECT SUBSTRING(‘123456’,3) #结果为 ‘3456’
SELECT left(‘四川省/成都市/新津区/兴义镇/先寺村’,locate(‘/’,‘四川省/成都市/新津区/兴义镇/先寺村’,12)-1) #四川省/成都市/新津区
SELECT locate(‘/’,‘四川省/成都市/新津区/兴义镇/岷江社区’,12) #12
SELECT left(‘四川省/成都市/新津区/兴义镇/先寺村’,12-1) #四川省/成都市/新津区
SELECT left(‘四川省/成都市/新津区/兴义镇/先寺村’,locate(‘/’,‘四川省/成都市/新津区/兴义镇/先寺村’,12)) #四川省/成都市/新津区/
SELECT substring(‘四川省/成都市/新津区/兴义镇/先寺村’,locate(‘/’,‘四川省/成都市/新津区/兴义镇/先寺村’,12)+1) #兴义镇/先寺村
SELECT substring(‘四川省/成都市/新津区/兴义镇/先寺村’,locate(‘/’,‘四川省/成都市/新津区/兴义镇/先寺村’,12)) #/兴义镇/先寺村
左外连接
字符穿转数字
CONVERT(column, SIGNED)
身份证号确定性别
IF (MOD(SUBSTRING(shenfenzhenghaoma,17,1),2),‘男’,‘女’) as ‘性别’
身份证号拿年龄
(substring(CURDATE(),1,4)-substring(shenfenzhenghao,7,4))-(substring(shenfenzhenghao,11,4)-date_format(CURDATE(),‘%m%d’)>0) as ‘年龄’
身份证拿某时之前出生的人
在MySQL中,如果你的身份证字段存储了出生日期,你可以使用日期函数和条件语句来查找在2023年8月30日之前出生的人。假设你的表名为 people,身份证字段为 id_card,可以按照以下方式查询:
SELECT *
FROM people
WHERE STR_TO_DATE(SUBSTRING(id_card, 7, 8), ‘%Y%m%d’) <= ‘2023-08-30’;
字符串替换 replace
REPLACE(str,from_str,to_str)
在字符串 str 中所有出现的字符串 from_str 均被 to_str替换,然后返回这个字符串
REPLACE(要替换的字符串,被替换的内容,被替换后填充的内容)
去除空值 TRIM RTRIM LTRIM
select trim(’ string ‘) #string
select RTRIM(’ string ‘)# string
select LTRIM(’ string ')#string
字符串替换 INSERT
insert 的语法格式 用于替换字符串
INSERT(str,pos,len,newstr)
INSERT(指定字符串,开始被替换的位置,被替换的字符串长度,新的字符串)
select INSERT(‘string’,1,LENGTH(‘string’),‘b’) #b
select INSERT(‘string’,2,LENGTH(‘string’),‘b’) #sb
select INSERT(‘string’,3,LENGTH(‘string’),‘b’) #stb
select insert(‘string’,4,LENGTH(‘string’),‘b’) #strb
字符串重复出现 REPEAT
REPEAT (‘要重复的字符串’ ,重复的次数)
select REPEAT(‘repeat-’,5); #repeat-repeat-repeat-repeat-repeat-
前或后添加相同字符串 LPAD RPAD
LPAD(‘原字符串’,最终字符串的长度,‘左边单个需要添加的字符串’)
select LPAD(‘addString’,20,‘b’) #bbbbbbbbbbbaddString
RPAD(‘原字符串’,最终字符串的长度,‘右边单个需要添加的字符串’)
select RPAD(‘addString’,20,‘a’) #addStringaaaaaaaaaaa
字符串的位置 INSTR
INSERT(查询的字符串,寻找的字符串)
select INSTR(‘substring’,‘string’) #4
select INSTR(‘abcdef’,‘a’) #1
select INSTR(‘abcdef’,‘b’) #2
select INSTR(‘abcdef’,‘c’) #3
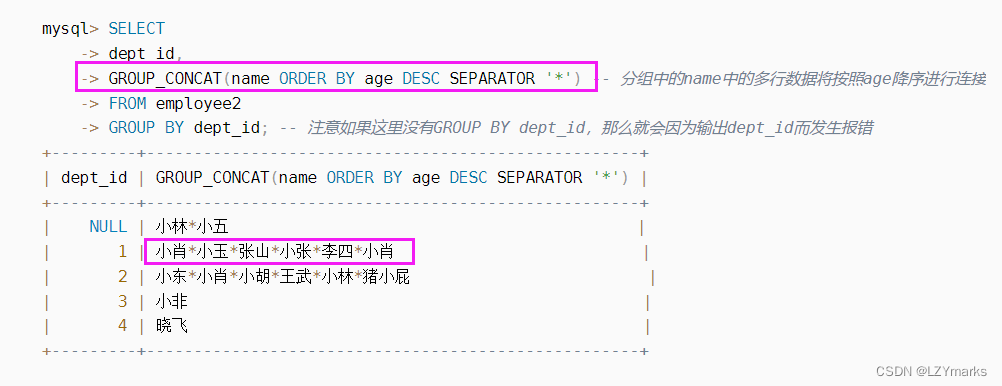
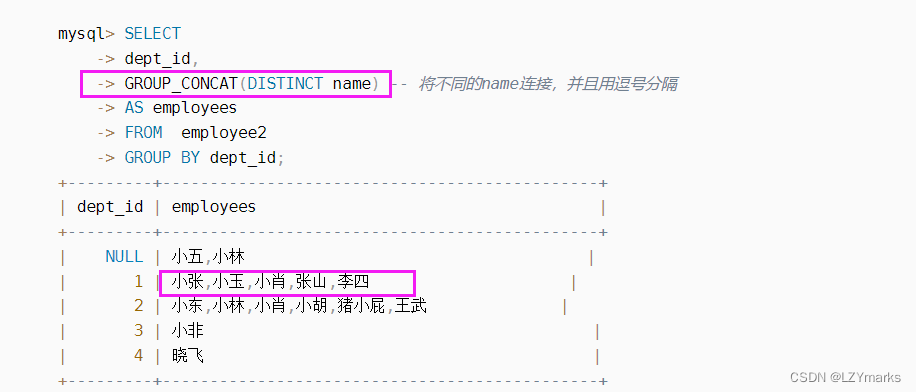
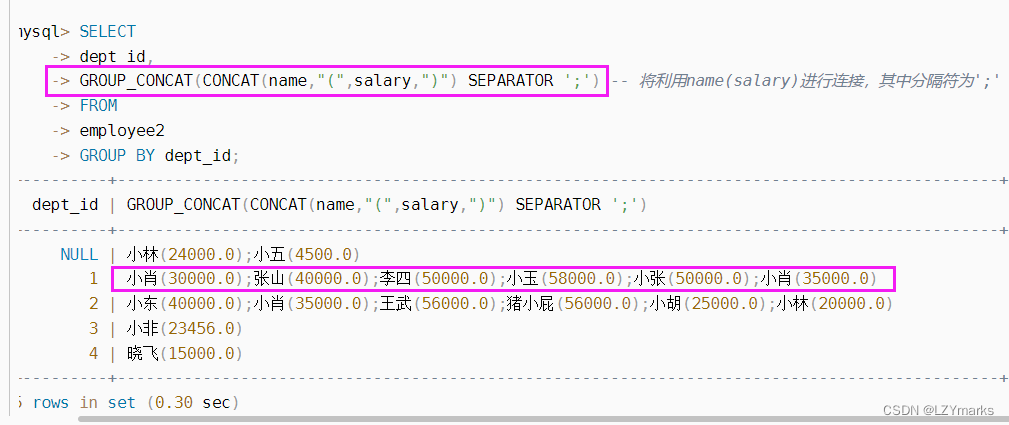
字符串分组连接 GROUP_CONCAT
GROUP_CONCAT([DISTINCT] column1 [ORDER BY column2 ASC\DESC] [SEPARATOR seq])
[ ORDER BY column2 ASC\DESC] :表示将会根据column2升序或者降序连接.其中column2不一定一定要求是column1,只要保证column2在这个分组中即可.如果没有写ORDER BY句段,那么连接是没有顺序的。
[ SEPARATOR seq] : 表示各个column1将会以什么分隔符进行分隔,
例如SEPARATOR ’ ',则表示column1将会以 ’ ’ 进行分隔。如果没有指定seq的时候,也即没有写SEPARATOR seq这个句段,那么就会默认是以 , 逗号分隔的。
CONCAT函数中要连接的数据含有NULL,最后返回的是NULL,但是GROUP_CONCAT不会这样,他会忽略NULL值。


SUBSTRING(str,pos,len)
SUBSTRING(‘要处理的字符串’,什么位置开始,多少位结束)
SELECT SUBSTRING(‘123456789’,1,4) #1234
SELECT SUBSTRING(‘123456789’,2,5) #23456
SELECT SUBSTRING(‘123456789’,3,5) #34567
select SUBSTRING(str FROM pos FOR len)
select SUBSTRING(str,pos,len)
select SUBSTRING(‘05-31-2019 45AM’,1,locate(’ ‘,‘2019-05-31 45AM’))
select CONCAT_WS
(’-‘, trim(SUBSTRING_INDEX(SUBSTRING(‘05-31-2019 45AM’,1,
locate(’ ‘,‘2019-05-31 45AM’)),’-‘,-1)),
SUBSTRING_INDEX(SUBSTRING(‘05-31-2019 45AM’,1,
locate(’ ‘,‘2019-05-31 45AM’)),’-‘,1),
SUBSTRING_INDEX(SUBSTRING_INDEX(SUBSTRING(‘05-31-2019 45AM’,1,locate(’ ‘,‘2019-05-31 45AM’)),’-‘,2),’-',-1)
) as time #2019-05-31
字符串截取 SUBSTRING_INDEX (正数和负数一起用)
SUBSTRING_INDEX 正数的情况
SUBSTRING_INDEX(要操作的字符串,标识符,第几位之前的出现的内容) 不包括该位置上的标识符
SUBSTRING_INDEX 负数的情况
SUBSTRING_INDEX(要操作的字符串,标识符,倒数第几位之前的出现的内容) 不包括该位置上的标识符
select SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,1) #大类
select SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,2) #大类–>中类
select SUBSTRING_INDEX(SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,2),‘–>’,-1) #中类
select SUBSTRING_INDEX(SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,2),‘–>’,-2) #大类–>中类
select SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,3) #大类–>中类–>小类
select SUBSTRING_INDEX(SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,3),‘–>’,-1) #小类
select SUBSTRING_INDEX(SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,3),‘–>’,-2) #中类–>小类
select SUBSTRING_INDEX(SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,3),‘–>’,-3) #大类–>中类–>小类
select SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,4) #大类–>中类–>小类–>细类
select SUBSTRING_INDEX(SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,4),‘–>’,-1) #细类
select SUBSTRING_INDEX(SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,4),‘–>’,-2) #小类–>细类
select SUBSTRING_INDEX(SUBSTRING_INDEX(‘大类–>中类–>小类–>细类’,‘–>’,4),‘–>’,-3) #中类–>小类–>细类
1、substring_index(str,delim,count)
str:要处理的字符串 delim:分隔符 count:计数
SELECT substring_index(‘www.google.com’,‘.’,1); //www
SELECT substring_index(‘www.google.com’,‘.’,2); //www.google
SELECT substring_index(‘www.google.com’,‘.’,3);//www.google.com
SELECT substring_index(‘www.google.com’,‘.’,4);//www.google.com
指数是负数的话 是从后面往前面
SELECT substring_index(‘www.google.com’,‘.’,-1);//com
SELECT substring_index(‘www.google.com’,‘.’,-2);//google.com
SELECT substring_index(‘www.google.com’,‘.’,-3);//www.google.com
SELECT substring_index(‘www.google.com’,‘.’,-4);//www.google.com
CONCAT_WS(sep,str1,str2,…,strn)
select CONCAT_WS(‘/’,‘新津区’,‘兴义镇’,‘杨柳村’) #新津区/兴义镇/杨柳村
select CONCAT_WS(‘—>’,‘新津区’,‘兴义镇’,‘杨柳村’) #新津区—>兴义镇—>杨柳村
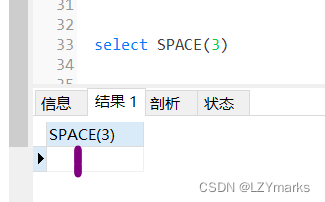
生成n个空格 SPACE
大小写 UCASE LCASE
select UCASE(‘strINg2’) #STRING2
select LCASE(‘STrRIiNG2’)#strriing2
update 连表更新优化1
update score sc
join student stu #注意这里一定是 join 不是left join left join 会把不匹配的设置为null
on sc.s_id = stu.s_id and sc.s_id = ‘07’
set sc.s_score = stu.s_id300.3
update 连表更新优化2
update tableName1 bieming1 , tableName2 bieming2
set bieming1.lieming1 = bieming2.lieming2
where 条件
建新表去除重复数据
create TABLE 新表名
select * from 旧表名 where 列名条件 GROUP BY 想要的字段(group by 过后就只有一条数据)
一张表中插入其他表的数据
insert into 新表名(前提先建好) #重点 没有values
select * from 旧表名 where 列名条件 GROUP BY 想要的字段(group by 过后就只有一条数据)
可以自定义排序 case when 新增排序列
得到每一条想要的数据 可以先 order by 在group by
如何存 ’
加一个转义符号 / 如: furname=‘属津区’
any_value()
会选择被分到同一组的数据里第一条数据的指定列值作为返回数据
mysql 开窗函数
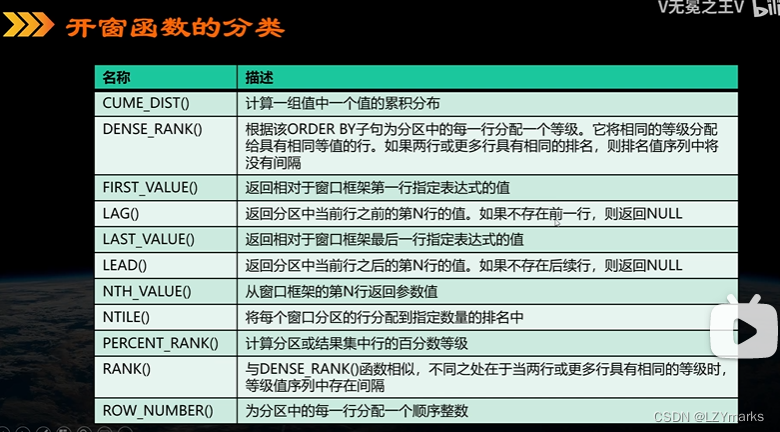
语法结构
窗口函数的语法结构形式:
<窗口函数> OVER ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
OVER 关键字指定窗口的范围:
如果省略后面括号中的内容,则窗口会包含满足WHERE条件的所有记录,窗口函数会基于所有满足WHERE条件的记录进行计算。
如果OVER关键字后面的括号不为空,则可以使用如下语法设置窗口:
PARTITION BY 子句: 指定窗口函数按照哪些字段进行分组, 分组后, 窗口函数可以在每个分组中分别执行;
ORDER BY 子句: 指定窗口函数按照哪些字段进行排序, 执行排序操作使窗口函数按照排序后的数据记录的顺序进行编号;
FRAME 子句: 为分区中的某个子集定义规则, 可以用来作为滑动窗口使用;
导入数据
CREATE TABLE books_goods (
t_category_id int,
t_category VARCHAR(64),
t_name VARCHAR(64),
t_price FLOAT(32),
t_upper_time datetime
);
INSERT INTO books_goods (t_category_id, t_category, t_name, t_price,t_upper_time) VALUES
(1,'教育','计算机网络',40.0,'2020-11-10 00:00:00'),
(1,'教育','数据结构',58.0,'2020-11-10 00:00:00'),
(1,'教育','计算机系统',55.0,'2020-11-10 00:00:00'),
(2,'科幻','三体',30.0,'2020-11-10 00:00:00'),
(2,'科幻','流浪地球',35.0,'2020-11-10 00:00:00')
一. 序号函数
1.ROW_NUMBER()函数
ROW_NUMBER()函数能够对数据中的序号进行顺序显示。
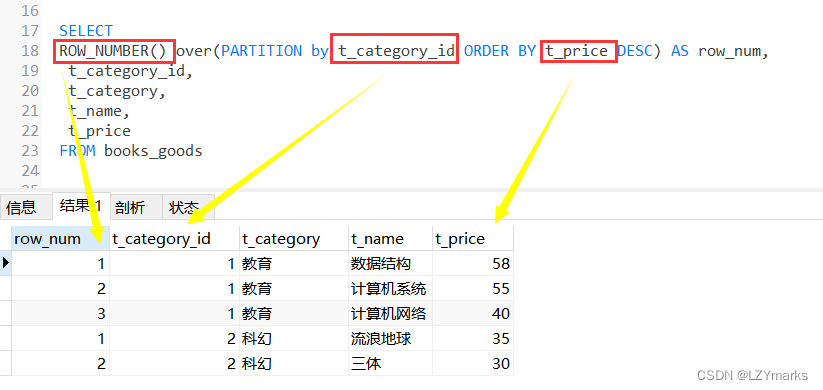
SELECT ROW_NUMBER() over(PARTITION by t_category_id ORDER BY t_price DESC) AS row_num,
t_category_id, t_category, t_name, t_price
FROM books_goods
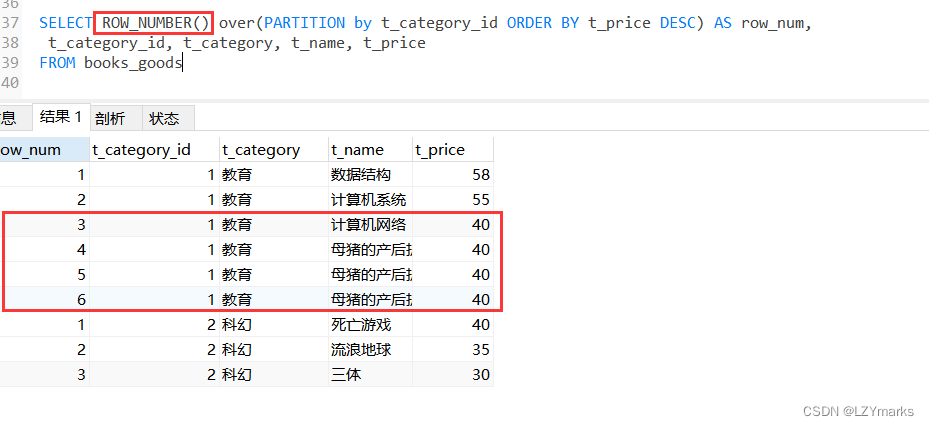
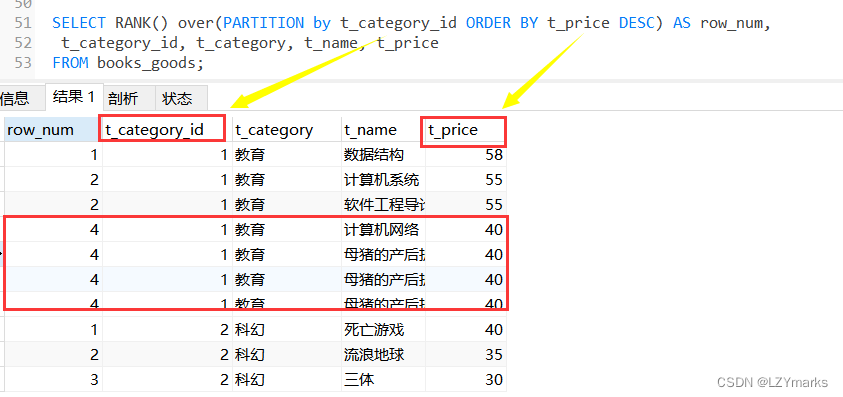
2.RANK()函数
使用RANK()函数能够对序号进行并列排序,并且会跳过重复的序号。
SELECT RANK() over(PARTITION by t_category_id ORDER BY t_price DESC) AS row_num,
t_category_id, t_category, t_name, t_price
FROM books_goods;
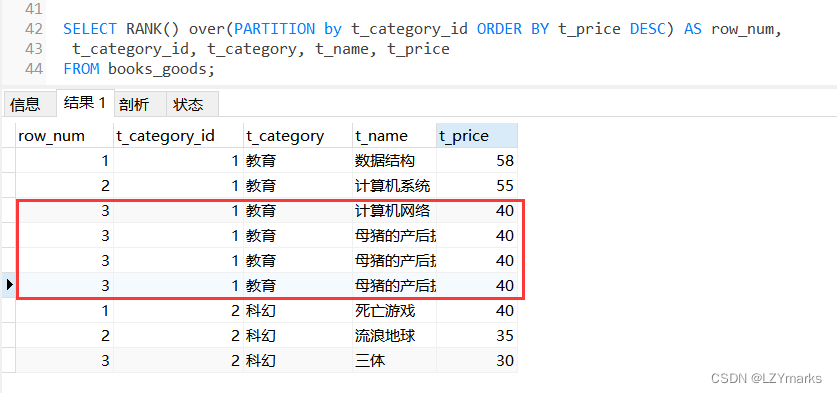
INSERT INTO books_goods (t_category_id, t_category, t_name, t_price,t_upper_time) VALUES
(1,'教育','软件工程导论',55.0,'2020-11-10 00:00:00');
3.DENSE_RANK()函数
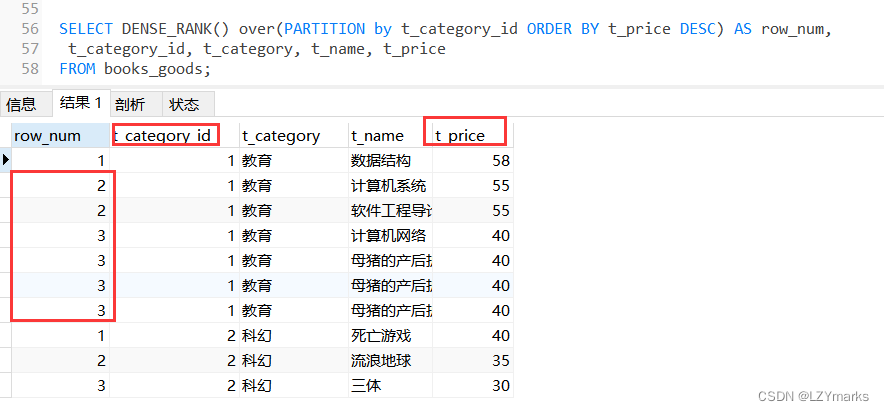
二.分布函数
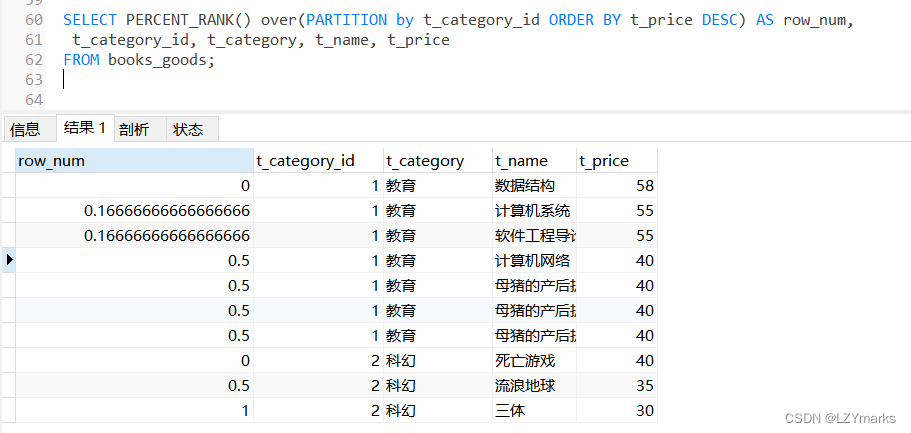
1.PERCENT_RANK()函数
PERCENT_RANK()函数是等级值百分比函数。按照如下方式进行计算:
(rank - 1) / (rows - 1)
其中,rank的值为使用RANK()函数产生的序号,rows的值为当前窗口的总记录数。
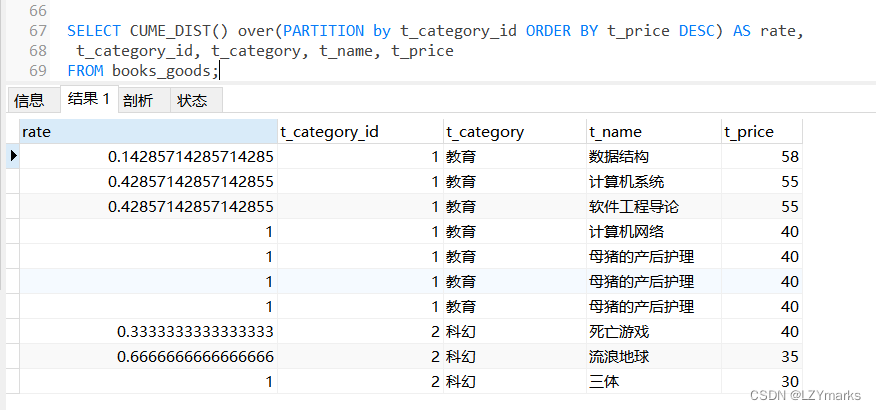
2.CUME_DIST()函数
CUME_DIST()函数主要用于查询小于或等于某个值的比例。
CUMEDIST=row/sum(row)
row为当前值的行数,sum(row)分组内总行数。若两值相等则当前行数计算为最大行数:
SELECT CUME_DIST() over(PARTITION by t_category_id ORDER BY t_price DESC) AS rate,
t_category_id, t_category, t_name, t_price
FROM books_goods;
三.前后函数
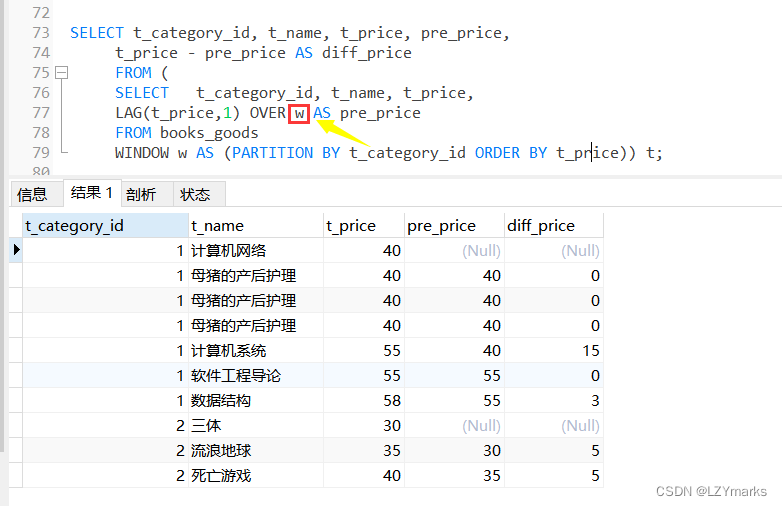
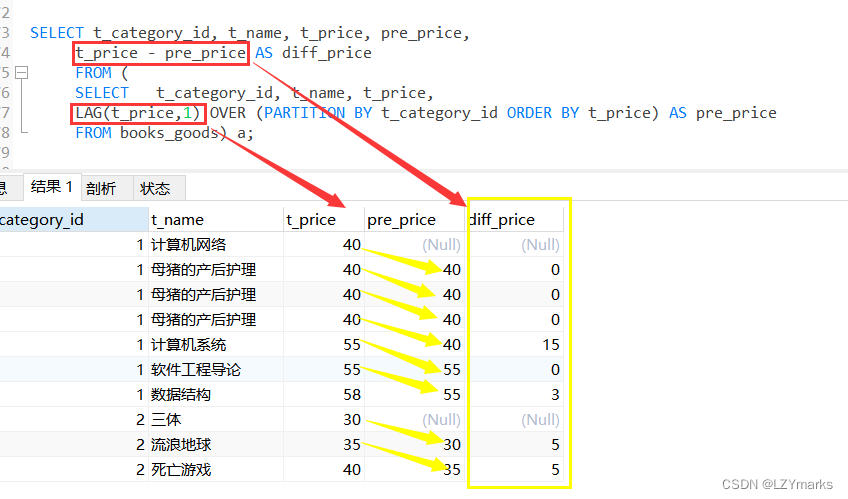
1.LAG(expr,n)函数
LAG(expr,n)函数返回当前行的前n行的expr的值。
例如,查询数据表中前一个商品价格与当前商品价格的差值。
SELECT t_category_id, t_name, t_price, pre_price,
t_price - pre_price AS diff_price
FROM (
SELECT t_category_id, t_name, t_price,
LAG(t_price,1) OVER w AS pre_price
FROM books_goods
WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price)) t;
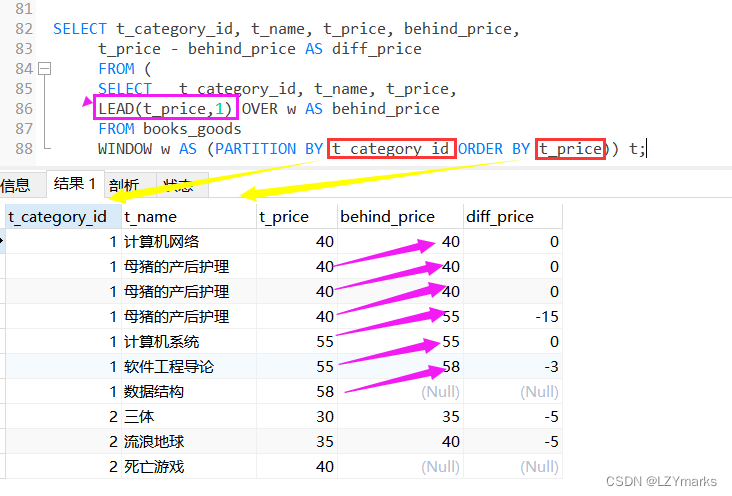
2.LEAD(expr,n)函数
LEAD(expr,n)函数返回当前行的后n行的expr的值。
例如,查询数据表中后一个商品价格与当前商品价格的差值。
SELECT t_category_id, t_name, t_price, behind_price,
t_price - behind_price AS diff_price
FROM (
SELECT t_category_id, t_name, t_price,
LEAD(t_price,1) OVER w AS behind_price
FROM books_goods
WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price)) t;
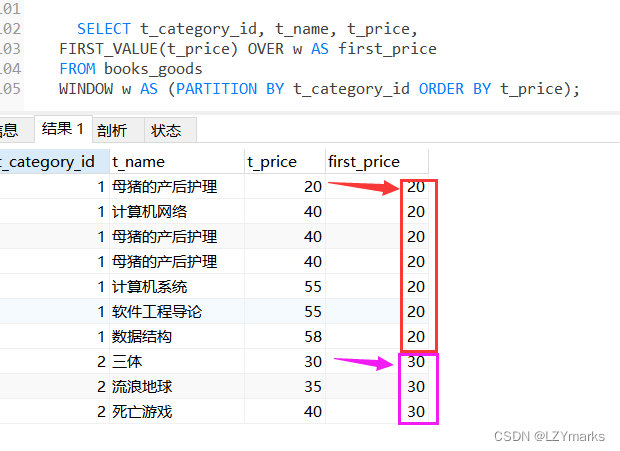
四.首尾函数
1.FIRST_VALUE(expr)函数
FIRST_VALUE(expr)函数返回第一个expr的值。
例如,按照价格排序,查询第1个商品的价格信息。
SELECT t_category_id, t_name, t_price,
FIRST_VALUE(t_price) OVER w AS first_price
FROM books_goods
WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price);
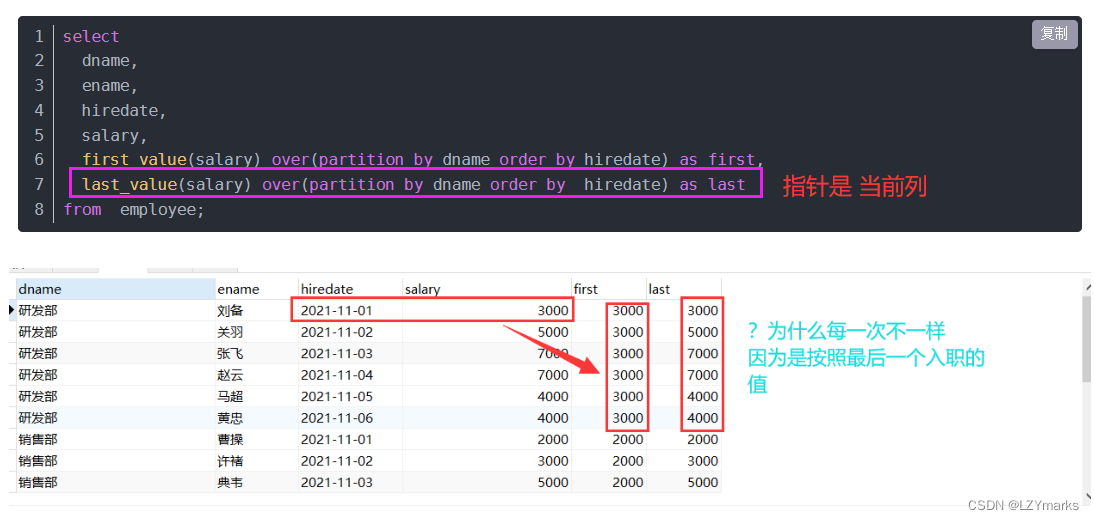
2. LAST_VALUE(expr)函数
LAST_VALUE(expr)函数返回最后一个expr的值。
例如,按照价格排序,查询最后一个商品的价格信息。
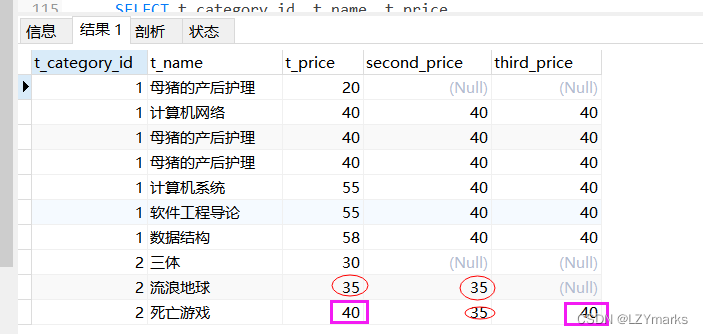
五、其他函数
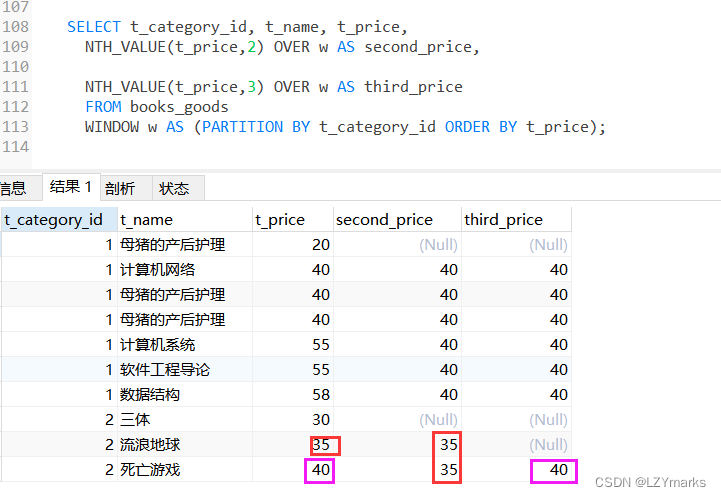
NTH_VALUE(expr,n)函数
NTH_VALUE(expr,n)函数返回第n个expr的值。
查询数据表中排名第3和第4的价格信息。
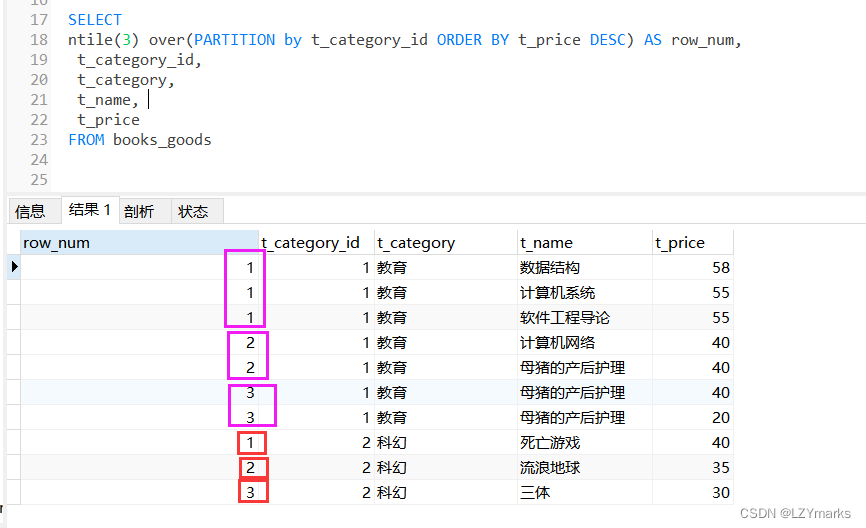
桶函数
分组后 再分为几组
ntile(再分为几组)
索引
CREATE INDEX card_no ON diy_hb_wwsgrfsjhyb_gcjd_20230601013905 (card_no);
CREATE INDEX sqmc ON diy_hb_wwsgrfsjhyb_gcjd_20230601013905 (sqmc);
CREATE INDEX yxmc ON diy_hb_wwsgrfsjhyb_gcjd_20230601013905 (yxmc);
CREATE INDEX ldh ON diy_hb_wwsgrfsjhyb_gcjd_20230601013905 (ldh);
添加索引一般这几个字段就行了哈,如果没有按照街道进行分表,就增加一个“镇(街道)名称”字段
SQL优化
1. 不使用 select * 而是使用后 select 列名
理由
节省资源、减少网络开销。
可能用到覆盖索引,减少回表,提高查询效率。
2. where 子句避免使用or 使用union 替换or 或者将分开写
SELECT * FROM user WHERE id=1 OR salary=5000
替换为
SELECT * FROM user WHERE id=1
UNION ALL
SELECT * FROM user WHERE salary=5000
或者
SELECT * FROM user WHERE id=1
SELECT * FROM user WHERE salary=5000
理由
使用or可能会使索引失效,从而全表扫描;
对于or没有索引的salary这种情况,假设它走了id的索引,但是走到salary查询条件时,它还得全表扫描;
也就是说整个过程需要三步:全表扫描+索引扫描+合并。如果它一开始就走全表扫描,直接一遍扫描就搞定;
虽然mysql是有优化器的,出于效率与成本考虑,遇到or条件,索引还是可能失效的;
3. 尽量使用数值替代字符串类型
1、正例
主键(id):primary key优先使用数值类型int,tinyint
性别(sex):0代表女,1代表男;数据库没有布尔类型,mysql推荐使用tinyint
2、理由
因为引擎在处理查询和连接时会逐个比较字符串中每一个字符;
而对于数字型而言只需要比较一次就够了;
字符会降低查询和连接的性能,并会增加存储开销;
4.使用varchar代替char
反例 address char(100) DEFAULT NULL COMMENT ‘地址’
正例 address varchar(100) DEFAULT NULL COMMENT ‘地址’
理由
varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间;
char按声明大小存储,不足补空格;
其次对于查询来说,在一个相对较小的字段内搜索,效率更高;
效率复盘
快速看别人的sql
- 这条sql最后的显示的结果是什么 带着问题去看
- 将这条sql 从最里面开始分解
3.将表名和字段名找到 放到word方便查询
多个空值统一排除
mysql coalesce函数用法是将多个参数进行比较,返回第一个非空值的函数。如果所有参数都是空值,那么返回NULL。该函数在需要处理可能为空的字段时十分有用。例如,COALESCE(col1, col2, col3)会先比较col1是否为空值,若不是则返回col1的值,否则比较col2是否为空,不为空则返回col2的值,否则返回col3的值
navicat 快捷键
ctrl + tab 下一个窗口
ctrl + / 注解
ctrl + R 运行
ctrl + f 查找文本 F3查找下一个选中的文本
ctrl+ Q 新添一个查询窗口
F8 定位到主窗体
F12 打开左侧数据库对象栏
mysql 运维
日志
1.1 错误日志
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志
该日志是默认开启的,默认存放目录 /var/log/,默认的日志文件名为mysqld.log 。
查看日志位置: show variables like '%log_error%';

1.2 二进制日志
1.2.1 介绍
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
作用:①. 灾难时的数据恢复;②. MySQL的主从复制。在MySQL8版本中,默认二进制日志是开启着的,
涉及到的参数如下:show variables like '%log_bin%';

cd /var/lib/mysql/
参数说明:
log_bin_basename:当前数据库服务器的binlog日志的基础名称(前缀),具体的binlog文件名需要再该basename的基础上加上编号(编号从000001开始)。
log_bin_index:binlog的索引文件,里面记录了当前服务器关联的binlog文件有哪些。

1.2.2 格式
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:

show variables like '%binlog_format%';

如果我们需要配置二进制日志的格式,只需要在 /etc/my.cnf 中配置binlog_format 参数即可。
cat /etc/my.cnf
里面有端口号等的设置
1.2.3 查看
由于日志是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具 mysqlbinlog 来查看,具体语法:

1.2.4 删除
对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不清除,将会占用大量磁盘空间。可以通过以下几种方式清理日志:
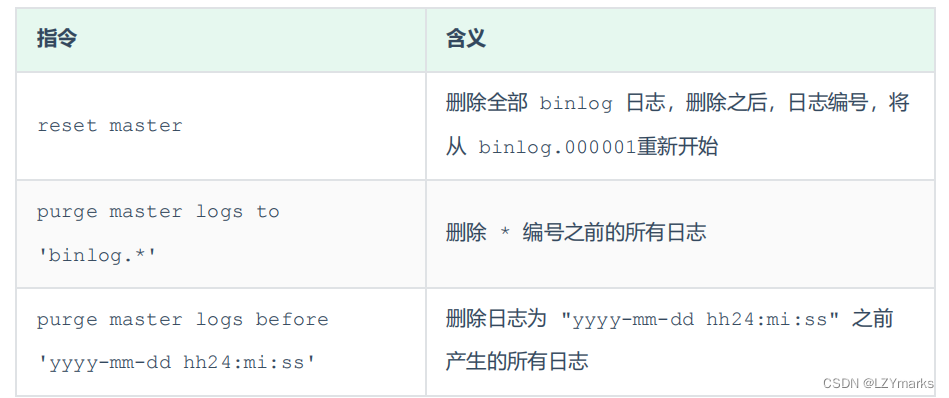
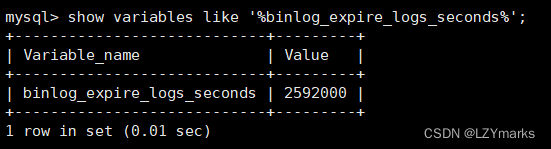
也可以在mysql的配置文件中配置二进制日志的过期时间,设置了之后,二进制日志过期会自动删除。
show variables like '%binlog_expire_logs_seconds%'; 1
1.3 查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的SQL语句。默认情况下,查询日志是未开启的。
在这里插入代码片
show variables like ‘%general%’;
如果需要开启查询日志,可以修改MySQL的配置文件 /etc/my.cnf 文件,添加如下内容:
开启了查询日志之后,在MySQL的数据存放目录,也就是 /var/lib/mysql/ 目录下就会出现mysql_query.log 文件。之后所有的客户端的增删改查操作都会记录在该日志文件之中,长时间运行后,该日志文件将会非常大。


1.4 慢查询日志
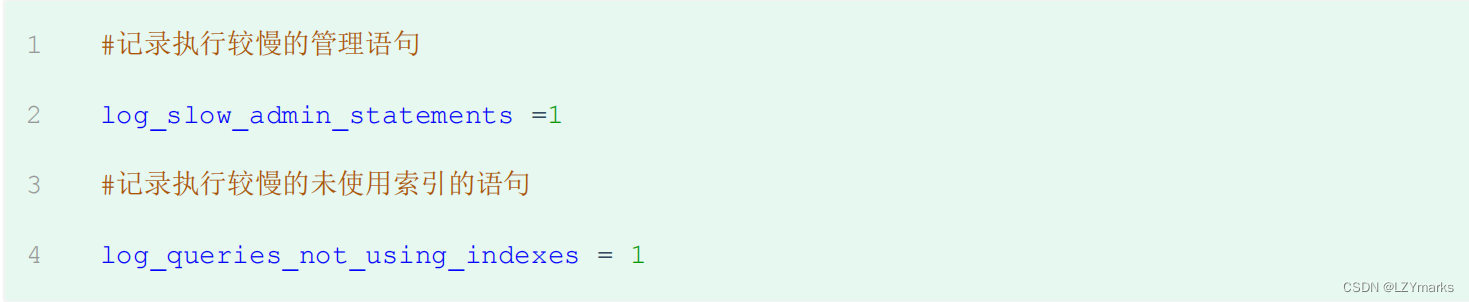
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于min_examined_row_limit 的所有的SQL语句的日志,默认未开启。long_query_time 默认为10 秒,最小为 0, 精度可以到微秒。
如果需要开启慢查询日志,需要在MySQL的配置文件 /etc/my.cnf 中配置如下参数:

默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以使用log_slow_admin_statements和 更改此行为 log_queries_not_using_indexes,如下所述。
上述所有的参数配置完成之后,都需要重新启动MySQL服务器才可以生效。
主从复制
2.1 概述
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制
MySQL 复制的优点主要包含以下三个方面:
主库出现问题,可以快速切换到从库提供服务。
实现读写分离,降低主库的访问压力。
可以在从库中执行备份,以避免备份期间影响主库服务。

2.2 原理
MySQL主从复制的核心就是 二进制日志,具体的过程如下:
从上图来看,复制分成三步:
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog中。
- 从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
- slave重做中继日志中的事件,将改变反映它自己的数据。
2.3 搭建
2.3.1 准备
准备好两台服务器之后,在上述的两台服务器中分别安装好MySQL,并完成基础的初始化准备(安装、密码配置等操作)工作。 其中:
192.168.200.200 作为主服务器master
192.168.200.201 作为从服务器slave

2.3.2 主库配置
- 修改配置文件 /etc/my.cnf
- 重启MySQL服务器

systemctl restart mysqld
- 登录mysql,创建远程连接的账号,并授予主从复制权限
#创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务
CREATE USER 'itcast'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456';
#为 'itcast'@'%' 用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'itcast'@'%';
- 通过指令,查看二进制日志坐标
show master status ;
字段含义说明:
file : 从哪个日志文件开始推送日志文件
position : 从哪个位置开始推送日志
binlog_ignore_db : 指定不需要同步的数据库

2.3.3 从库配置
- 修改配置文件 /etc/my.cnf
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,和主库不一样即可
server-id=2
#是否只读,1 代表只读, 0 代表读写
read-only=1
- 重新启动MySQL服务
systemctl restart mysqld
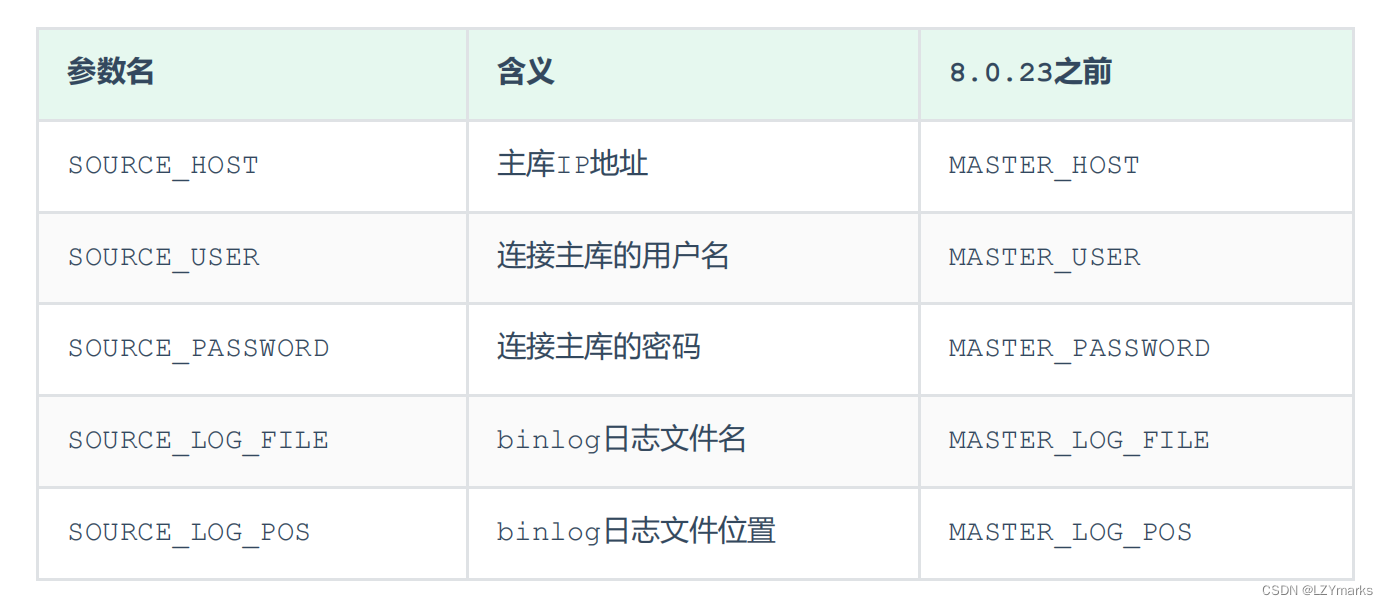
- 登录mysql,设置主库配置
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.200.200', SOURCE_USER='itcast',
SOURCE_PASSWORD='Root@123456', SOURCE_LOG_FILE='binlog.000004',
SOURCE_LOG_POS=663;
上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本,执行如下SQL:
CHANGE MASTER TO MASTER_HOST='192.168.200.200', MASTER_USER='itcast',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000004',
MASTER_LOG_POS=663;
4. 开启同步操作
start replica ; #8.0.22之后
start slave ; #8.0.22之前
- 查看主从同步状态
show replica status ; #8.0.22之后
show slave status ; #8.0.22之前
分库分表
3.1 介绍
3.1.1 问题分析
随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库进行数据存
储,存在以下性能瓶颈:
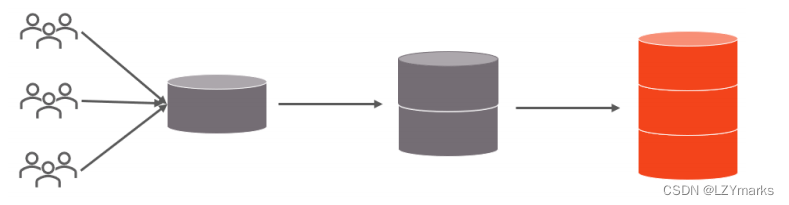
- IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。 请求数据太多,带宽不够,网络IO瓶颈。
- CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
为了解决上述问题,我们需要对数据库进行分库分表处理。
分库分表的中心思想都是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
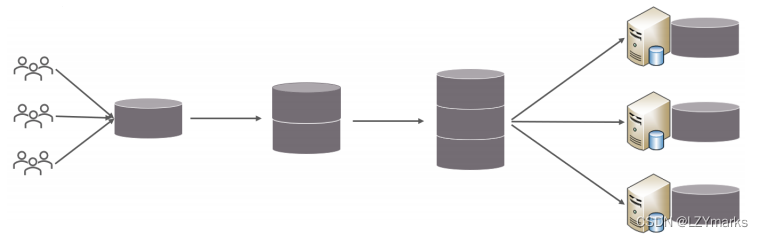
3.1.2 拆分策略
分库分表的形式,主要是两种:垂直拆分和水平拆分。而拆分的粒度,一般又分为分库和分表,所以组成的拆分策略最终如下:
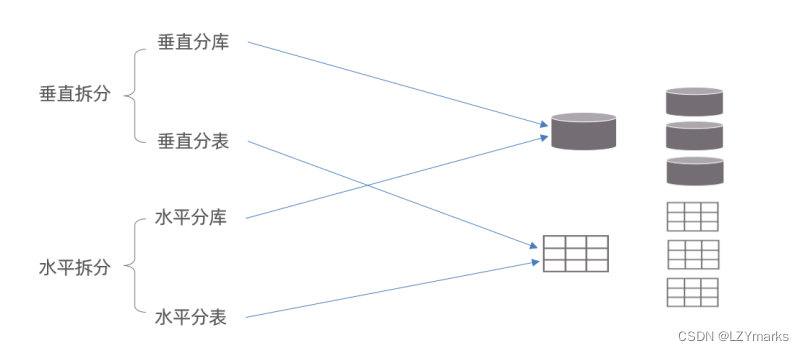
3.1.3 垂直拆分
-
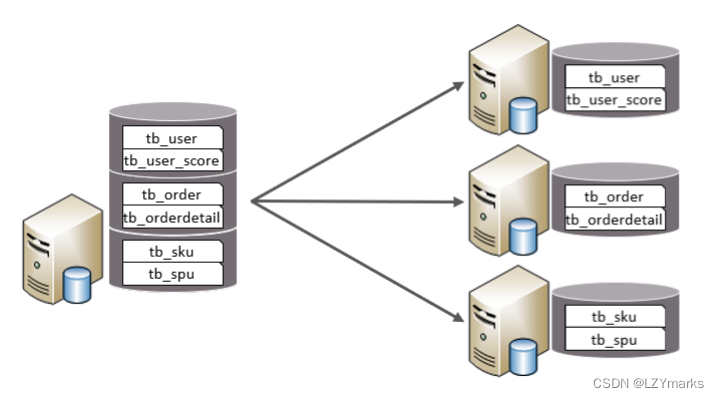
垂直分库
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。
特点:
每个库的表结构都不一样。
每个库的数据也不一样。
所有库的并集是全量数据。 -
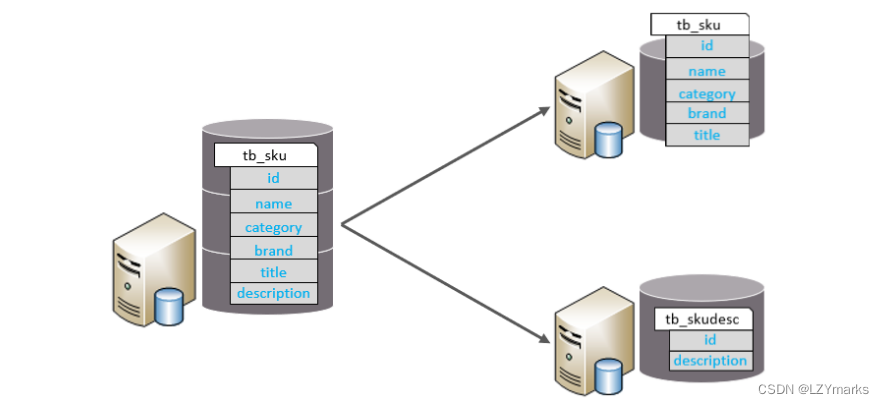
垂直分表
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。
特点:
每个表的结构都不一样。
每个表的数据也不一样,一般通过一列(主键/外键)关联。
所有表的并集是全量数据。
3.1.4 水平拆分
- 水平分库
水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。
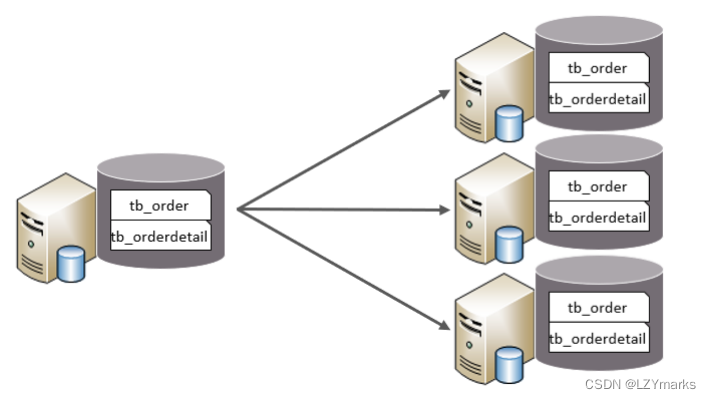
特点:
每个库的表结构都一样。
每个库的数据都不一样。
所有库的并集是全量数据。
- 水平分表
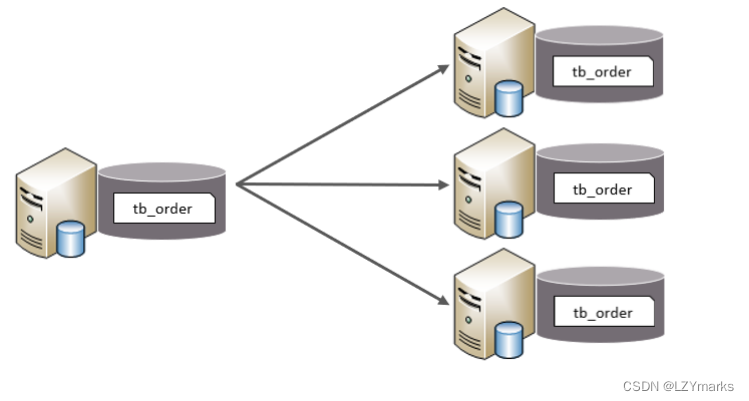
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。
特点:
每个表的表结构都一样。
每个表的数据都不一样。
所有表的并集是全量数据。
在业务系统中,为了缓解磁盘IO及CPU的性能瓶颈,到底是垂直拆分,还是水平拆分;具体是分库,还是分表,都需要根据具体的业务需求具体分析。
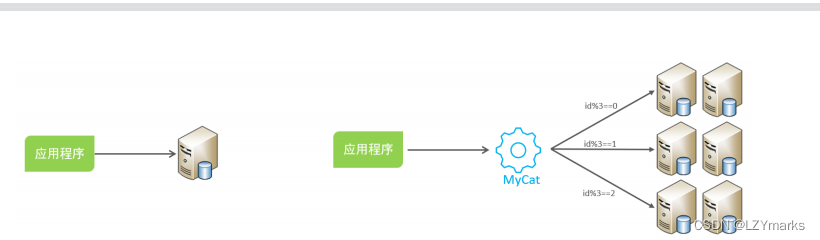
3.1.5 实现技术
shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高。
MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者。
本次课程,我们选择了是MyCat数据库中间件,通过MyCat中间件来完成分库分表操作。
3.2 MyCat概述
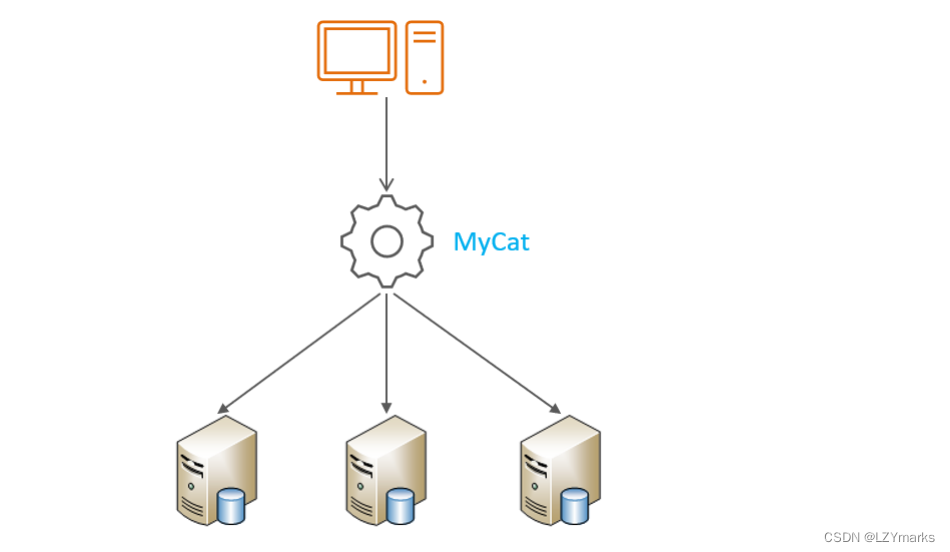
3.2.1 介绍
Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用mysql一样来使用mycat,对于开发人员来说根本感觉不到mycat的存在
开发人员只需要连接MyCat即可,而具体底层用到几台数据库,每一台数据库服务器里面存储了什么数据,都无需关心。 具体的分库分表的策略,只需要在MyCat中配置即可。
3.2.2 下载
下载地址:http://dl.mycat.org.cn/
3.2.3 安装
Mycat是采用java语言开发的开源的数据库中间件,支持Windows和Linux运行环境,下面介绍
MyCat的Linux中的环境搭建。我们需要在准备好的服务器中安装如下软件。
MySQL
JDK
Mycat
3.2.4 目录介绍
bin : 存放可执行文件,用于启动停止mycat
conf:存放mycat的配置文件
lib:存放mycat的项目依赖包(jar)
logs:存放mycat的日志文件

3.2.5 概念介绍
在MyCat的整体结构中,分为两个部分:上面的逻辑结构、下面的物理构。
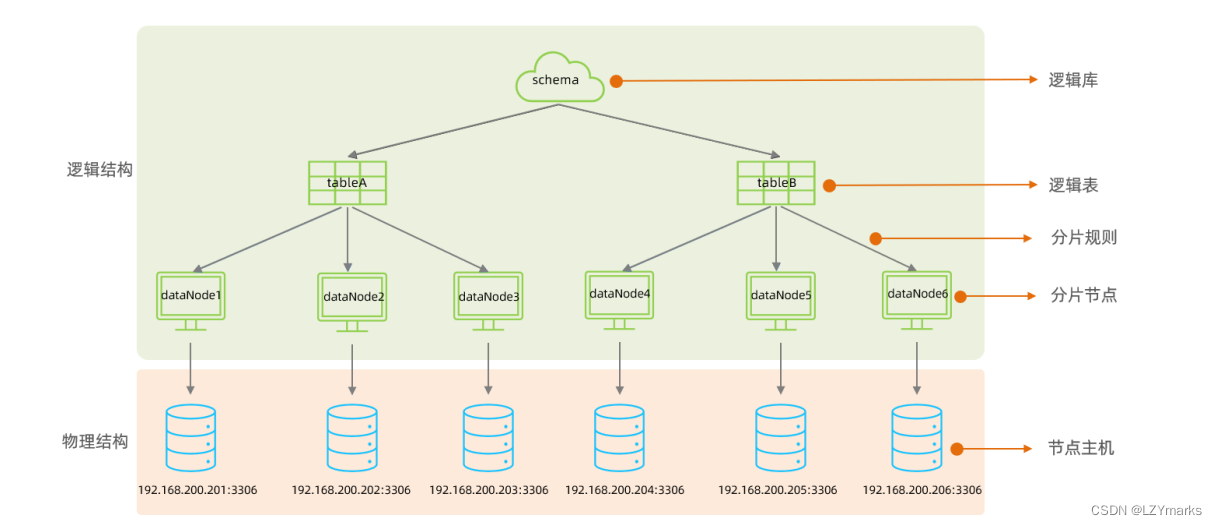
在MyCat的逻辑结构主要负责逻辑库、逻辑表、分片规则、分片节点等逻辑结构的处理,而具体的数据
存储还是在物理结构,也就是数据库服务器中存储的。
在后面讲解MyCat入门以及MyCat分片时,还会讲到上面所提到的概念。
Mysql 官网下载指定版本