Redis Cluster是Redis官方提供的分布式解决方案。当遇到内存、并发、流量等瓶颈时,就可以采用Cluster架构达到负载均衡目的。
1.为什么要用redis-cluster集群?
1.首先Redis单实例主要有单点,容量有限,流量压力上限的问题。
Redis单点故障,可以通过主从复制replication,和自动故障转移sentinel哨兵机制。但Redis单Master实例提供写服务,仍然有容量和压力问题,因此需要数据分区,构建多个Master实例同时提供读写服务(不仅限于从replica节点提供读服务)。
2.并发问题
redis官方声称可以达到 10万/s,每秒执行10万条命令
假如业务需要每秒100万的命令执行呢?
解决方案如下
正确的应该是考虑分布式,加机器,把数据分到不同的位置,分摊集中式的压力,一堆机器做一件事.还需要一定的机制保证数据分区,并且数据在各个主Master节点间不能混乱,当然最好还能支持在线数据热迁移的特性。
2、什么是Redis-Cluster
为何要搭建Redis集群。Redis是在内存中保存数据的,而我们的电脑一般内存都不大,这也就意味着Redis不适合存储大数据,Redis更适合处理高并发,一台设备的存储能力是很有限的,但是多台设备协同合作,就可以让内存增大很多倍,这就需要用到集群。
Redis集群搭建的方式有多种,例如使用客户端分片、Twemproxy、Codis等,但从redis 3.0之后版本支持redis-cluster集群,它是Redis官方提出的解决方案:
Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。其Redis-cluster架构图如下:
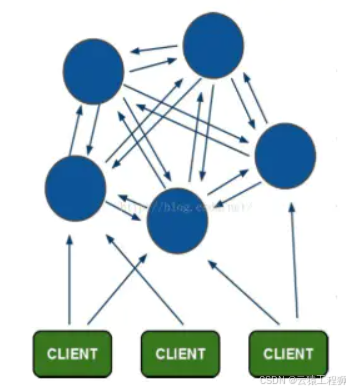
2.1 redis cluster特点
1.所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2.客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
3.节点的fail是通过集群中超过半数的节点检测失效时才生效。
2.2 redis-cluster数据分布
Redis-cluster集群中有16384(0-16383)个哈希槽(卡槽),每个redis实例负责一部分slot/槽位,集群中的所有信息通过节点数据交换而更新。一个hash slot中会有很多key和value。
2.3 数据分布存储原理
Redis 集群使用数据分片(sharding)来实现:Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value(name1: 张三) 时,redis 先对 key 使用 crc16 算法算出一个结果678698,然后把结果对 16384 求余数(集群使用公式 CRC16(key) % 16384),这样每个key 都会对应一个编号在 0-16383 之间的哈希槽,那么redis就会把这个key 分配到对应范围的节点上了。同样,当连接三个节点任何一个节点想获取这个key时,也会这样的算法,然后内部跳转到存放这个key节点上获取数据。
例如三个节点:哈希槽分布的值如下:
cluster1: 0-5460
cluster2: 5461-10922
cluster3: 10923-16383这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。 比如说:
- 如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
- 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
3、Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉.
1.主从切换机制
选举过程是集群中所有master参与,如果半数以上master节点与故障节点通信超过(cluster-node-timeout),认为该节点故障,自动触发故障转移操作. #故障节点对应的从节点自动升级为主节点
2.什么时候整个集群就不能用了?
如果集群任意一个主节点挂掉,且当前主节点没有从节点,则集群将无法继续,因为我们不再有办法为这个节点承担范围内的哈希槽提供服务。但是,如果这个主节点和所对应的从节点同时失败,则Redis Cluster无法继续运行。
二、集群部署
环境准备:
1.准备三机器,关闭防火墙和selinux
2.制作解析并相互做解析
注:规划架构两种方案,一种是单机多实例,这里我们采用多机器部署
三台机器,每台机器上面两个redis实例,一个master一个slave,第一列做主库,第二列做备库
#记得选出控制节点
redis-cluster1 192.168.146.169 7000、7001
redis-cluster2 192.168.146.172 7002、7003
redis-cluster3 192.168.146.179 7004、7005三台机器相同操作
1.安装redis
[root@redis-cluster1 ~]# mkdir /data
[root@redis-cluster1 ~]# yum -y install gcc automake autoconf libtool make
[root@redis-cluster1 ~]# wget https://download.redis.io/releases/redis-6.2.0.tar.gz
[root@redis-cluster1 ~]# tar xzvf redis-6.2.0.tar.gz -C /data/
[root@redis-cluster1 ~]# cd /data/
[root@redis-cluster1 data]# mv redis-6.2.0/ redis
[root@redis-cluster1 data]# cd redis/
[root@redis-cluster1 redis]# make #编译
[root@redis-cluster1 redis]# mkdir /data/redis/data #创建存放数据的目录2.创建节点目录:按照规划在每台redis节点的安装目录中创建对应的目录(以端口号命名)
[root@redis-cluster1 redis]# pwd
/data/redis
[root@redis-cluster1 redis]# mkdir cluster #创建集群目录
[root@redis-cluster1 redis]# cd cluster/
[root@redis-cluster1 cluster]# mkdir 7000 7001 #创建节点目录3.拷贝配置文件到节点目录中
[root@redis-cluster1 cluster]# cp /data/redis/redis.conf 7000/4.修改集群每个redis配置文件。(主要是端口、ip、pid文件,三台机器相同操作),修改如下:
[root@redis-cluster1 cluster]# cd 7000/
[root@redis-cluster1 7000]# vim redis.conf #修改如下
bind 0.0.0.0 #每个实例的配置文件修改为对应节点的ip地址
port 7000 #监听端口,运行多个实例时,需要指定规划的每个实例不同的端口号
daemonize yes #redis后台运行
pidfile /var/run/redis_7000.pid #pid文件,运行多个实例时,需要指定不同的pid文件
logfile /var/log/redis_7000.log #日志文件位置,运行多实例时,需要将文件修改的不同。
dir /data/redis/data #存放数据的目录
appendonly yes #开启AOF持久化,redis会把所接收到的每一次写操作请求都追加到appendonly.aof文件中,当redis重新启动时,会从该文件恢复出之前的状态。
appendfilename "appendonly.aof" #AOF文件名称
appendfsync everysec #表示对写操作进行累积,每秒同步一次
以下为打开注释并修改
cluster-enabled yes #启用集群
cluster-config-file nodes-7000.conf #集群配置文件,由redis自动更新,不需要手动配置,运行多实例时请注修改为对应端口
cluster-node-timeout 5000 #单位毫秒。集群节点超时时间,即集群中主从节点断开连接时间阈值,超过该值则认为主节点不可以,从节点将有可能转为master
cluster-replica-validity-factor 10 #在进行故障转移的时候全部slave都会请求申请为master,但是有些slave可能与master断开连接一段时间了导致数据过于陈旧,不应该被提升为master。该参数就是用来判断slave节点与master断线的时间是否过长。(计算方法为:cluster-node-timeout * cluster-replica-validity-factor,此处为:5000 * 10 毫秒)
cluster-migration-barrier 1 #一个主机将保持连接的最小数量的从机,以便另一个从机迁移到不再被任何从机覆盖的主机
cluster-require-full-coverage yes #集群中的所有slot(16384个)全部覆盖,才能提供服务
#注:
所有节点配置文件全部修改切记需要修改的ip、端口、pid文件...避免冲突。确保所有机器都修改。5.cluster1中 7000/目录中的配置文件修改完后复制 7001/ 目录
[root@redis-cluster1 cluster]# cp -r 7000 70016.到 7001/ 目录中使用 sed 命令把配置文件中的 7000 全部修改成 7001
[root@redis-cluster1 7001]# sed -i 's/7000/7001/g' 7001/redis.conf7.cluster1创建完后将redis目录拷贝到cluster2,cluster3中(前提cluster2,3中创建了data目录)
scp -r 7000/ 192.168.146.172:/data/redis/cluster/
scp -r 7000/ 192.168.146.179:/data/redis/cluster/8.当cluster2、cluster3中有redis目录后执行以下操作,修改端口配置文件
[root@redis-cluster2 cluster]# mv 7000 7002
[root@redis-cluster2 cluster]# cd 7002/
[root@redis-cluster2 cluster]# sed -i "s/7000/7002/" 7002/redis.conf
[root@redis-cluster2 cluster]# cp -r 7002 7003
[root@redis-cluster2 cluster]# cd 7003/
[root@redis-cluster2 cluster]# sed -i "s/7002/7003/" 7002/redis.confcluster3 也如以上操作,将7002,7003 换成 7004,7005 即可。
9.启动三台机器上面的每个节点(三台机器相同操作)
[root@redis-cluster1 ~]# cd /data/redis/src/
[root@redis-cluster1 src]# nohup ./redis-server ../cluster/7000/redis.conf &
[root@redis-cluster1 src]# nohup ./redis-server ../cluster/7001/redis.conf &
10.创建redis-cluster集群:在其中一个节点操作就可以
redis节点搭建起来后,需要完成redis cluster集群搭建,搭建集群过程中,需要保证6个redis实例都是运行状态。
Redis是根据IP和Port的顺序,确定master和slave的,所以要排好序,再执行。
参数:
--cluster-replicas 1:表示为集群中的每个主节点创建一个从节点.书写流程:主节点ip+port 对应一个从节点ip+port(注意:若节点在不同的机器上,注意主节点的书写位置,要避免主节点在同一台机器上,影响性能。正常是前面三个节点为主节点,后面的为从节点)
[root@redis-cluster1 src]# cd /data/redis/src/
[root@redis-cluster1 src]# ./redis-cli --cluster create --cluster-replicas 1 192.168.146.169:7000 192.168.146.172:7002 192.168.146.179:7004 192.168.146.169:7001 192.168.146.172:7003 192.168.146.179:7005
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.146.172:7003 to 192.168.146.169:7000
Adding replica 192.168.146.179:7005 to 192.168.146.172:7002
Adding replica 192.168.146.169:7001 to 192.168.146.179:7004
M: a8779ba1ca5bee649076808cd6b1c6b21aad8fcc 192.168.146.169:7000
slots:[0-5460] (5461 slots) master
S: ae6e288245186c5392e2120a6309cc0f072eca55 192.168.146.169:7001
slots: (0 slots) slave
replicates 043e33e9166057e1e4d0bf976f1c601aa8a16f32
M: eb4b3885e4e1b8b72cb5c6230db5d71f2adb313b 192.168.146.172:7002
slots:[5461-10922] (5462 slots) master
S: 60234c6dadc448c5ae9a810f42489e9f131ed211 192.168.146.172:7003
slots: (0 slots) slave
replicates a8779ba1ca5bee649076808cd6b1c6b21aad8fcc
M: 043e33e9166057e1e4d0bf976f1c601aa8a16f32 192.168.146.179:7004
slots:[10923-16383] (5461 slots) master
S: 73b7078b88b18811feb6bb133c3395a158377227 192.168.146.179:7005
slots: (0 slots) slave
replicates eb4b3885e4e1b8b72cb5c6230db5d71f2adb313b
Can I set the above configuration? (type 'yes' to accept): yes #写yes同意
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 192.168.146.169:7000)
M: a8779ba1ca5bee649076808cd6b1c6b21aad8fcc 192.168.146.169:7000
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: eb4b3885e4e1b8b72cb5c6230db5d71f2adb313b 192.168.146.172:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: ae6e288245186c5392e2120a6309cc0f072eca55 192.168.146.169:7001
slots: (0 slots) slave
replicates 043e33e9166057e1e4d0bf976f1c601aa8a16f32
M: 043e33e9166057e1e4d0bf976f1c601aa8a16f32 192.168.146.179:7004
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 60234c6dadc448c5ae9a810f42489e9f131ed211 192.168.146.172:7003
slots: (0 slots) slave
replicates a8779ba1ca5bee649076808cd6b1c6b21aad8fcc
S: 73b7078b88b18811feb6bb133c3395a158377227 192.168.146.179:7005
slots: (0 slots) slave
replicates eb4b3885e4e1b8b72cb5c6230db5d71f2adb313b
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.11.查看集群状态可连接集群中的任一节点,此处连接了集群中的节点
192.168.146.169:7000
# 登录集群客户端,-c标识以集群方式登录
[root@redis-cluster1 src]# ./redis-cli -h 192.168.146.169 -c -p 7000
192.168.146.169:7000> ping
PONG
192.168.146.169:7002> cluster info #查看集群信息
cluster_state:ok #集群状态
cluster_slots_assigned:16384 #分配的槽
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6 #集群实例数
......
192.168.146.169:7000> cluster nodes #查看集群实例