MuDPT:用于大型预训练视觉语言模型的多模态深度联合提示微调
摘要
随着大型预训练视觉语言模型的出现(比如CLIP),提示微调(比如CoOp)最近在各种下游任务中表现出不错的视觉识别和迁移学习能力。无论如何,我们发现现存的单模态的提示调优方法可能会导致次优的性能,因为单模态设计破坏了预训练模型中文本表示和视觉表示的原始对齐。
受到预训练视觉语言模型本质的启发,我们旨在实现提示微调的完整性,并且提出了一种新的方法,称为多模态深度联合提示微调MuDPT,这种方法通过额外地学习一个与模型无关的转换网络来扩展独立的多模态提示微调,来实现深度的分层的双向提示融合。
同时,本文评估了MuDPT在few-shot视觉识别和域外泛化任务上的有效性。与当前最先进的方法相比,由于文本和视觉表征的协同对齐,MuDPT实现了更好的识别和泛化能力,并且具有明显的优势。
关键词:Prompt tuning, Multi-modal, Prompt fusion, Few-shot learning
Introduction
1.传统的视觉表征学习是通过训练一个模型来预测一组具有预定类别固定集合的视觉对象。然而,这种范式将模型限制在固定且有限的类别数据中,使得模型对未见过的类别对象的泛化能力很差。最近,在大量的图像文本对中预训练的大规模视觉语言模型,即VL-PTMs,已经成为一种很有前景的替代方式,并且对不同的下游任务表现出明显的zero-shot可迁移能力。由于自然语言语境中包含更广泛的监督来源,使得VL-PTMs能够表示未见过的类别。
2.随着VL-PTMs展现出更加诱人的泛化能力,大家都开始探索将这些模型迁移到下游任务的可选方案。一种有效的方式就是利用提示(a photo of [class])注入到预训练模型中,来缓解预训练形式和下游任务之间的差距。然而,prompt engineering 是一种直观并且经验导向型的工作,通常会存在性能次优的问题。一些提示微调被开发用于自动提示工程,比如CoOp等。
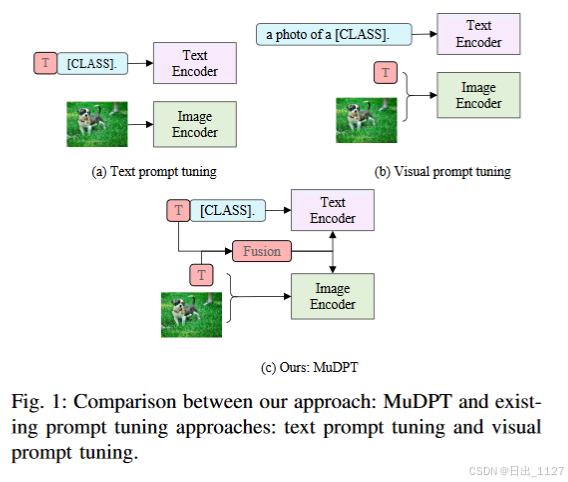
解释图1:
先前的工作主要集中在VL-PTMs的文本或者视觉分支的单模态提示微调,而同时在两种模态中的多模态提示微调仍然未被探索。
3.本文发现任何一种单模态提示调优方法都不会带来一致的性能提升。我们假设其潜在性原因在于单模态提示微调使VL-PRMs中原本已经对齐的文本和视觉表征造成损坏。
继续解释图1:在现有的单模态提示调优方法中,VL-PRM中其中一个模态在下游训练时被完全冻结。例如在文本提示调优中,通过在文本编码器中引入可学习的参数来动态优化文本表示,然而此时视觉表示是完全固定的。
VL-PTMs的本质就是在一个共同的多模态空间中相互对齐文本表示和图像表示,而单模态设计破坏了这种表示。先前的研究已经证明了在多模态表示之间的对齐可以增强其在下游任务中的性能。
4.本文从CLIP预训练的内在意图出发,即协同训练文本编码器和图像编码器来对齐文本特征和图像特征,本文的目的是引入文本和视觉深度提示来动态协调文本和视觉表征。一个最直观的解决方案就是分别将多模态的提示输入到相应的编码器中,以进行端到端的监督训练,以单独优化提示。但是早期的实验已经证明,由于两种模态之间本质的区别,这种朴素的联合提示微调通常会带来次优的效果。
5.为了实现提示微调方法能够更适应VL-PTMs,本文提出MuDPT,通过学习一个与模态无关的转换网络来充分微调文本和视觉表示。本文在few-shot视觉识别和域外泛化任务上测试该方法的有效性。对比当前最好的方法,本文方法在few-shot视觉识别中表现出明显的优势。
本文贡献:
(1)提出MuDPT,多模态深度联合提示微调,实现了文本和视觉表征的协同动态对齐。
(2)为实现跨模态提示的转换和融合,提出了一种轻量级模态无关的转换网络。它搭建了视觉与文本提示之间的协同的桥梁。
(3)大量实验证明MuDPT有效。
Methodology
本文的方法关注多模态深度联合提示微调从而适应VL-PTMs,从而在下游任务中表现出更好的视觉识别能力和泛化能力。
方法分为两个部分,首先,本文对CLIP的文本分支和视觉分支对称地引入可学习的文本提示T和视觉提示V。第二部分,本文设计了一个称为“注入模型”的转换模块,以建立视觉和文本提示之间的跨模态注意力,从而进行深层次地分层双向提示融合。
A.Preliminaries
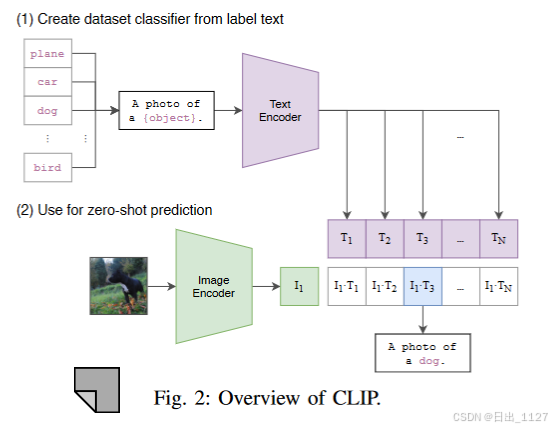
解释图2:CLIP是一种基于transformer的VL-PTM,包含一个文本编码器和图像编码器。本文也使用了基于ViT的CLIP,这和现有的提示微调方法保持一致。
文本编码器:
(1)CLIP中的编码器将单词嵌入word embedding(W0)的序列作为输入:
其中每一个w0都表示单个token的嵌入向量,其中维度为dt。
(2)嵌入向量W0被送入Transformer T进行处理。
(3)在Transformer的每个隐藏层中,前一层的输出Wi就会成为下一层Ti+1的输入,连续经过k个隐藏层的处理。
(4)最终需要得到文本的向量化表示z,这个向量化表示z是通过映射最后一个transformer块中与[EOS](结束标记)相对应的最后一个隐藏状态来实现的。
而映射的过程涉及到投影矩阵TextProj(与投影矩阵做乘法),这个投影矩阵将隐藏状态从原始维度映射到共同的多模态空间维度中,多模态空间中允许不同类型数据在同一空间进行表示,以便于跨模态的交互。
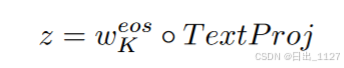
图像编码器:
(1)图像编码器将输入图像编码为一组具有固定大小的patch
(2)这个patch编码会和一个可学习的[cls]token结合,输入到transformer中,经过K个transformer块的处理,得到最终的隐藏状态。其中’,’表示级联操作。
(3)最终需要获得图像的向量化表示x,这个向量化表示x是由映射最后一个transformer块中[cls]token标记的嵌入实现的。
这个映射过程涉及投影矩阵ImageProj(与投影矩阵做乘法),这个矩阵投影将ck从原始维度映射到共同的多模态空间的维度。
Inference
对于视觉识别任务,在文本编码器中注入带有类别符号的提示文本( A photo of [class]),通过填写特定的类别名称来合成分类权重Z。
给定图像I的预测与分类权重和和图像表示之间的余弦相似度最高。
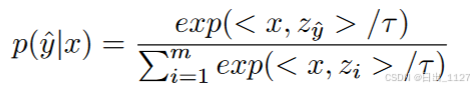
B.Multi-modal Deep-symphysis Prompt Tuning
在CLIP本质的驱动下,本文提出了MuDPT来实现提示微调的完备性,从而更适应VL-PTMs的视觉识别任务。
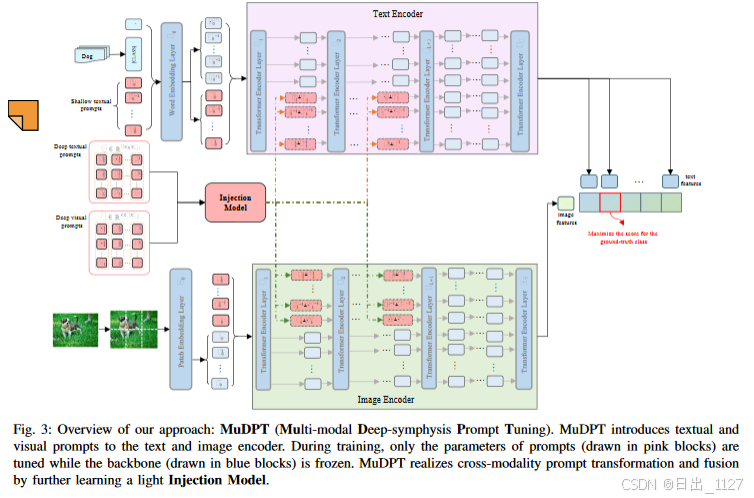
解释图3:为了进行深层次的分层双向提示融合,本文设计了一个轻量级的变换模块“注入模块”,用于建立多模态提示中的跨模态注意力。除了在嵌入层引入可学习的提示以外,进一步将其他组的提示注入到更深的transformer层中,以逐步建模文本和视觉表示。
1)Deep-symphysis Prompt Fusion深层联合提示融合:
基于建立跨模态交互的考虑,本文提出一个极小的变换模块,称为注入模块,用于在两种模态之间共享提示。
在CLIP的文本和视觉分支中分别引入深度文本提示T和视觉提示V。
其中L表示提示的深度,可以理解提示的层数,L决定了提示有多少层。n表示提示的长度。为了保证提示的分层次且双向的融合,进一步将文本提示T和视觉提示V作为注入模块的输入,从而获得跨模态的提示。
Injection表示注入模块的隐藏层。然后多模态提示T^和V^分别由原始的提示和跨模态提示组成,此时称为分层次双向提示融合。

2)Deep Text Prompt Tuning深层文本提示微调
本文在CLIP的文本分支中进行了深度文本提示微调。在本文的方法中,输入向量是嵌入层文本提示T0(类似于 A Photo of )和特定类别名称的单词嵌入的级联,表示为[T0,W0,weos],其中W0代表类名的单词嵌入,weos代表[EOS]token的向量。
然后将[T0,W0,weos](文本提示和类别的单词嵌入)进一步注入到每个transformer层中,直到第L层。第一个transformer编码层中T的输入为原始提示,后续都为多模态提示。
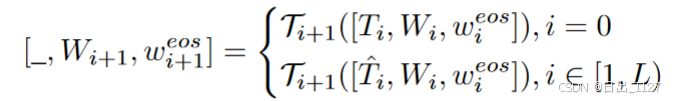
在第L层之后,后续的层依次处理上一层的输出,最后的文本表征z由最后一个隐藏层的状态weos和TextProj计算得到。
j ∈ [L, K),当L=1时,即仅在CLIP的文本分支的嵌入层引入可学习向量,深度文本提示微调退化为CoOp。
3)Deep visual Prompt Tuning深层视觉提示微调
类似的,本文在CLIP的视觉分支引入了深层视觉提示。[c0, V0, P0]作为输入,其中V表示多模态输入,c表示[cls]token的编码,P表示图像的patch。
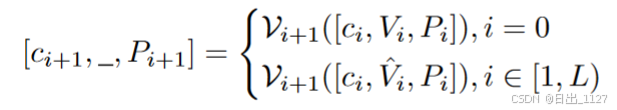
在结束L层后,后续的层采用相似的步骤:
通过映射矩阵ImageProj将类嵌入ck中的最后一个隐藏状态映射到多模态空间中,得到最终的图像向量表示x。
最后,本文利用两种表征之间的余弦相似度来获得预测。对真实值和预测值进行交叉熵损失,来优化多模态提示和注入模型的参数。学习的目标就是最大化真实类的预测分数。
Conclusion
在本文中,我们发现现有的提示微调方法中一个关键的问题:单模态的设计打破了预训练模型中文本和视觉表示的原始对齐状态,导致在下游任务中性能欠佳。
为了解决这个问题,本文提出MuDPT,允许在提示微调中进行多模态深层次的提示融合。
与基线方法相比,本文的方法提高了few-shot的视觉识别性能,并在域外泛化任务中获得更好的泛化能力。
然而,11个数据集中的3个数据集MuDPT的性能仍然落后于zero-shot的CLIP,这表明在未来的工作中仍然需要更多的努力来缩小VL-PTMs中连续提示和手工提示之间的差距。
---------------------------巴好意西,初学者先不解析实验啦,需要PPT可以私信哦---------------------------