本篇文章内容充实 文字量较大 每一个知识点都会附带有模版题以供练习 并有详细注释
若能基本掌握 稳稳拿省一~😎~如遇我解释不清楚的地方 欢迎私信我 我会耐心解答呀
目录
动态规划
01背包
N,V = map(int,input().split()) # 物品数量和背包容积
v = [] ; w = [] # 每个物品的体积和价值
for i in range(N) : # 读入数据
a,b = map(int,input().split())
v.append(a) ; w.append(b)
dp = [0]*(V+1) # dp数组
for i in range(N) :
for j in range(V,v[i]-1,-1) :
dp[j] = max(dp[j],dp[j-v[i]]+w[i]) # 状态转移方程
print(dp[V])模版题链接🔗: 2. 01背包问题 - AcWing题库
完全背包
n,m=map(int,input().split()) # 物品个数 背包容积
v=[0 for i in range(n+10)] # 物品体积
w=[0 for i in range(n+10)] # 物品价值
# 在前i个物品中选且背包体积为j时的最大价值
dp=[[0 for i in range(n+10)] for j in range(n+10)]
for i in range(1,n+1):
vv,ww=map(int,input().split())
v[i]=vv
w[i]=ww
for i in range(1,n+1) :
for j in range(m+1) :
dp[i][j] = dp[i-1][j]
if j >= v[i]:
dp[i][j] = max(dp[i][j],dp[i][j-v[i]]+w[i])
print(dp[n][m])模版题链接🔗:3. 完全背包问题 - AcWing题库
多重背包
N,V = map(int,input().split()) # 物品个数 背包体积
w = [] ; v = [] ; num = [] # 每个物品的价值 体积 个数
for i in range(N) :
a,b,c = map(int,input().split())
num.append(c) ; v.append(a) ; w.append(b)
dp = [0 for i in range(V+1)] # 当背包体积为i时能装下的最大价值
for i in range(N) :
for j in range(V,v[i]-1,-1) :
for k in range(num[i]+1) : # 枚举一下这个物品能装多少个
if k*v[i] > j : break # 大于背包体积则不能装了
dp[j] = max(dp[j],dp[j-k*v[i]]+k*w[i])
print(dp[V])模版题链接🔗: 4. 多重背包问题 I - AcWing题库
01背包最大价值方案数
n,V = map(int,input().split())
dp = [0 for j in range(V+1)] # 背包体积为j时能达到的最大价值
g = [1 for j in range(V+1)] # 背包体积为j时能达到最大价值的方案数
for i in range(1,n+1):
v,w = map(int,input().split())
for j in range(V,v-1,-1):
# 和01背包很像 只不过转移到对象是方案数
if dp[j] == dp[j-v]+w : g[j] += g[j-v]
elif dp[j] < dp[j-v]+w : g[j] = g[j-v]
dp[j] = max(dp[j], dp[j-v]+w)
print(g[V])
模版题链接🔗:11. 背包问题求方案数 - AcWing题库
完全背包填满背包的方案数
N = int(input())
dp = [0 for i in range(N+1)] #
dp[0] = 1
for i in range(1,N) :
for j in range(i,N+1) :
dp[j] += dp[j-i]
print(dp[N])模版题链接🔗: 279. 自然数拆分 - AcWing题库
最长上升子序列
num = int(input())
mountBox = list(map(int,input().split())) # 数组
Maxlen = [1 for i in range(num)] # 以第i个数字结尾的最长上升子序列
for i in range(num) :
for j in range(i) : # 枚举比i靠前的数
if mountBox[j] < mountBox[i] : # 如果这个数比当前数小
Maxlen[i] = max(Maxlen[j]+1,Maxlen[i]) # 更新答案
print(max(Maxlen))模版题链接🔗: [NOIP1999 普及组] 导弹拦截 - 洛谷
最长公共子串
n = int(input())
list1 = list(map(int,input().split()))
list2 = list(map(int,input().split()))
# list1前i长的子串和list2前j长的子串的最长公共子串
Map = [[0 for i in range(len(list1)+1)]for j in range(len(list2)+1)]
for i in range(1,len(list2)+1) :
for j in range(1,len(list1)+1) :
if list2[i-1] == list1[j-1] : # 如果当前字符相同
Map[i][j] = Map[i-1][j-1] + 1 # 在原基础上+1
else :
Map[i][j] = 0 # 否则为0
print(Map[-1][-1])模版题链接🔗:3875. 最长公共子串 - AcWing题库
最长公共子序列
n = int(input())
list1 = list(map(int,input().split()))
list2 = list(map(int,input().split()))
Map = [[0 for i in range(len(list1)+1)]for j in range(len(list2)+1)]
for i in range(1,len(list2)+1) :
for j in range(1,len(list1)+1) :
if list2[i-1] == list1[j-1] :
Map[i][j] = Map[i-1][j-1] + 1
else : # 所有代码和最长公共子串一样 只是这里不同 注意!
Map[i][j] = max(Map[i-1][j],Map[i][j-1])
print(Map[-1][-1])模版题链接🔗: 【模板】最长公共子序列 - 洛谷
最长公共上升子序列
请看这篇博客:Python:最长公共上升子序列模版_KS想去海底的博客-CSDN博客
模版题链接🔗:272. 最长公共上升子序列 - AcWing题库
最长上升子序列和
请看这篇博客:Python:最长上升子序列和_KS想去海底的博客-CSDN博客
模版题链接🔗:活动 - AcWing
最长回文子串
s = input() # 读入目标字符串
length = len(s)
dp = [[0 for i in range(length+10)]for j in range(length+10)]
#从第i个字符到第j个字符的最长回文串
res = ''
for l in range(1,length+1) : # 类似区间dp 枚举子串长度
i = 0 #从第0个字符开始
while i + l - 1 < length : # 只要比总长短
j = i + l - 1 # 子串右端点
if l == 1 : # 长度为1的情况
dp[i][j] = 1
elif l == 2 : # 长度为2的情况
if s[i] == s[j] : dp[i][j] = 2
else : # 否则 如果当前左右端点字符相同
if s[i] == s[j] and dp[i+1][j-1] : dp[i][j] = dp[i+1][j-1] + 2
if dp[i][j] > len(res) : res = s[i:j+1]
i += 1
print(len(res))
模版题链接🔗:1524. 最长回文子串 - AcWing题库
最长回文子序列
s = input()
length = len(s)
dp = [[0 for i in range(length)]for j in range(length)] # dp[i][j]表示 第i个字符到第j个字符的最长回文子序列长度
for i in range(length) :
dp[i][i] = 1
for i in range(length-1,-1,-1) : # 可以想像为往两端扩展
for j in range(i+1,length) :
if s[i] == s[j] : dp[i][j] = dp[i+1][j-1]+2
else : dp[i][j] = max(dp[i+1][j],dp[i][j-1])
print(dp[0][length-1])
模版题链接🔗:3996. 涂色 - AcWing题库
二分
检测是否最大满足
def check(x):
if(s[x]<=goal): return True
return False
s=[int(i) for i in input().split()]
goal=int(input())
left=0
right=len(s)-1# 左右端点
while(left<right):
mid=(left+right+1) // 2
if(check(mid)):
left=mid
else:
right=mid-1
print(left,s[left])
检测是否最小满足
def check(x):
if(s[x]>=goal):
return True
return False
s=[int(i) for i in input().split()]
goal=int(input())
left=0
right=len(s)-1
while(left<right):
mid=(left+right)>>1
if(check(mid)):
right=mid
else:
left=mid+1
print(left,s[left])
模版题链接🔗:113. 特殊排序 - AcWing题库
全排列
下一个全排列
# 对于12345的序列 最多让我数到54321
def nextP(index):
global s
for t in range(index):
if(n<=1): # 如果一共的字母小于等于1 没什么要干的 返回
return
for i in range(n-2,-1,-1):
# 从后往前看 找到第一个不是降序的数x
if(s[i]<s[i+1]):
for j in range(n-1,-1,-1):
if(s[j]>s[i]): # 从后往前找 找到第一个大于x的数
s[i],s[j]=s[j],s[i] # 把它们交换
s[i+1:]=sorted(s[i+1:]) # 后面按照升序排序
break
break
else:
if(i==0): s.sort()
n=int(input())
index=int(input())
s=[int(i) for i in input().split()]
nextP(index)
print(' '.join(map(str,s)))
模版题链接🔗:[NOIP2004 普及组] 火星人 - 洛谷
N个字符/数字的全排列
# n个数字的不同排列
from itertools import permutations
n=int(input())
s=[i for i in input().split()]
for p in permutations(s):
print("".join(map(str,p)))
# n个字母的不同排列
str=list(input().split()) # 根据空格划分开
for p in permutations(str):
print("".join(p))
N个字符选K个字符的组合
from itertools import combinations
n,k=map(int,input().split())
s=[i for i in range(1,n+1)]
for comb in combinations(s,k):
print("".join(map(str,comb)))
求组合数
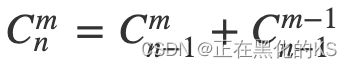
# 求组合数Cab
N=2010
mod=1e9+7
c=[[0 for i in range(N)] for j in range(N)]
def get():
global c
for i in range(N):
for j in range(i+1):
if(j==0): #
c[i][j]=1
else: # 用公式计算c[i][j]
c[i][j]=(c[i-1][j]+c[i-1][j-1])%mod
n=int(input())
get()
for k in range(n):
a,b=map(int,input().split())
print(c[a][b])
快速幂
小提示:Python语言其实可以不用背快速幂模版 因为自带的pow函数速度已经比快速幂还快了
但需要理解原理 可能会遇到变种题!
def power(base,exponent): # base : 底数 / exponent : 指数
res = 1
while exponent:
if exponent & 1: # 判断当前的最后一位是否为1,如果为1的话,就需要把之前的幂乘到结果中。
res *= base
base *= base # 一直累乘,如果最后一位不是1的话,就不用了把这个值乘到结果中,但是还是要乘。
exponent = exponent >> 1
return res
模版题链接🔗:【模板】快速幂||取余运算 - 洛谷
筛素数
这里给出的是线性筛法 速度比朴素的筛法要快
# 线性筛质数
N=1000010
n=int(input())
cnt=0 # 用来计算有几个素数
primes=[] # 用来存素数
def get_primes(n):
global cnt,primes
st=[False for i in range(N)] # 是否被筛过
for i in range(2,n+1):
if(st[i]==0): # 如果没被筛过 是素数
primes.append(i) # 放到素数列表中
cnt+=1
for j in range(N):
if(primes[j]>n//i): break # 枚举已经筛过的素数
st[primes[j]*i]=1 # 将他们标为已经筛过了
if(i%primes[j]==0): break
get_primes(n)
print(cnt)
模版题链接🔗:【模板】线性筛素数 - 洛谷
唯一分解定理

最大公约数与最小公倍数
import math
a,b = map(int,input().split())
t1 = math.gcd(a,b) # 最大公因数
t2 = print(a*b//math.gcd(a,b)) # 最小公倍数
模版题链接🔗:3642. 最大公约数和最小公倍数 - AcWing题库
图论
建图方法
# 邻接表存图 N个点 M条边
N = int(input()) ; M = int(input())
Map = [dict() for i in range(N+1)]
for i in range(M) :
a,b,c = map(int,input().split()) # 起点 终点 权值
Map[a][b] = c
# 邻接矩阵存图
Map = [[0]*(N+1) for i in range(N+1)]
for i in range(M) :
a,b,c = map(int,input().split()) # 起点 终点 权值
Map[a][b] = c
# 推荐第一种 空间消耗相对少最短路 Dijkstra算法(没有负边权)
import heapq
def dijkstra(G,start): ###dijkstra算法
INF = float('inf')
dis = dict((key,INF) for key in G) # start到每个点的距离
dis[start] = 0
vis = dict((key,False) for key in G) #是否访问过,1位访问过,0为未访问
###堆优化
pq = [] #存放排序后的值
heapq.heappush(pq,[dis[start],start])
#path = dict((key,[start]) for key in G) #记录到每个点的路径
while len(pq)>0:
v_dis,v = heapq.heappop(pq) #未访问点中距离最小的点和对应的距离
if vis[v] == True:
continue
vis[v] = True
#p = path[v].copy() #到v的最短路径
for node in G[v]: #与v直接相连的点
new_dis = dis[v] + float(G[v][node])
if new_dis < dis[node] and (not vis[node]): #如果与v直接相连的node通过v到src的距离小于dis中对应的node的值,则用小的值替换
dis[node] = new_dis #更新点的距离
heapq.heappush(pq,[dis[node],node])
#temp = p.copy()
#temp.append(node) #更新node的路径
#path[node] = temp #将新路径赋值给temp
return dis,path
if __name__ == '__main__':
G = {1:{1:0, 2:10, 4:30, 5:100},
2:{2:0, 3:50},
3:{3:0, 5:10},
4:{3:20, 4:0, 5:60},
5:{5:0},
}
distance,path = dijkstra(G,1)
模版题链接🔗:【模板】单源最短路径(标准版) - 洛谷
最短路 SPFA算法(有负边权)
def spfa(s) :
tot = 0
queue = collections.deque() # 双端队列的SFL优化
queue.append(s) # s是起点
dis = [INF for i in range(P+1)] # 起点到每个点的最近距离
dis[s] = 0 # 到起点自己是0
vis = [0 for i in range(P+1)] # 第i个点是否在队列中
vis[s] = 1
while queue :
now = queue.popleft() # 第一个元素出队
vis[now] = 0
for i in range(1,P+1) :
if Map[now][i] == INF : continue # 若不连通则跳过
if dis[i] > dis[now] + Map[now][i] :
dis[i] = dis[now] + Map[now][i]
if not vis[i] : # 若该点不在队列中 放入队列
vis[i] = 1
# SFL优化 如果当前点的dis小于队头元素的dis,则插入队头,反之队尾
if len(queue) != 0 and dis[i] < dis[queue[0]] :
queue.appendleft(i)
else : queue.append(i)
for item in start :
if dis[item] > INF//2 : return INF # 如果这点不可达,直接返回无穷大
tot += dis[item]
return tot
模版题链接🔗:1127. 香甜的黄油 - AcWing题库
最小生成树
n,k = map(int,input().split()) # 点数 边数
edges = [] # 存每一条边
for i in range(k) :
a,b,c = map(int,input().split())
edges.append((a,b,c))
# 并查集模版
def root(x) :
if x != p[x] :
p[x] = root(p[x])
return p[x]
def union(a,b) :
p[root(a)] = root(b)
p = [i for i in range(n+1)] # 并查集列表
edges.sort(key = lambda x : x[2]) # 按照边权从小到大排序
res = 0
while edges :
come,to,weight = edges.pop(0)
if root(come) != root(to) :
union(come,to) # 每次连接两条边
res += weight
print(weight)模版题链接🔗:【模板】最小生成树 - 洛谷
拓扑排序
#准备工作上需要一个字典:用于存放连接关系
def topsort(graph):
#初始化所有点的入度为0
indegrees=dict((i,0) for i in graph.keys())
#传入入度大小
for i in graph.keys():
for j in graph[i]:
indegrees[j]+=1#'a':'cd',代表a指向c和d,那么c和d的入度增加1
#获取入度为0的顶点
stack=[i for i in indegrees.keys() if indegrees[i]==0]
#创建拓扑序列
seq=[]
while stack:#深搜
tmp=stack.pop()#出栈
seq.append(tmp)#加入拓扑序列
for k in graph[tmp]:#遍历邻居,邻居入度-1,邻居入度为0入栈
indegrees[k]-=1
if indegrees[k]==0:
stack.append(k)
if len(seq)==len(graph):
print(seq)#输出拓扑序列
else:
print('存在环')#当存在环,最终余下的点入度都不为0,Seq个数少于总顶点数
G={
'a':'cd',
'b':'df',
'c':'e',
'd':'efg',
'e':'g',
'f':'g',
'g':''
}
topsort(G)
#['b', 'a', 'd', 'f', 'c', 'e', 'g']模版题链接🔗:164. 可达性统计 - AcWing题库
最近公共祖先
import collections
from typing import List
class Solution:
# 树中的节点都是int类型的
# bfs求解深度的一个好处是不容易爆栈而且是无向图也不用标记是否已经被访问了, 因为第一次访问到的距离肯定是最短的
def bfs(self, root: int, fa: List[List[int]], depth: List[int], g: List[List[int]]):
q = collections.deque([root])
# 这里0号点充当哨兵的作用
depth[0] = 0
depth[root] = 1
while q:
p = q.popleft()
for next in g[p]:
j = next
if depth[j] > depth[p] + 1:
depth[j] = depth[p] + 1
# 加入队列
q.append(j)
# 预处理fa列表, k = 0是边界为跳2 ^ 0 = 1步
fa[j][0] = p
# 因为节点个数最多为4 * 10 ** 4, 所以最多跳2 ^ 17, 这里0号点作为哨兵的好处是可以当跳出根节点之后那么节点的祖先是0, 可以避免边界问题
for k in range(1, 17):
# 从当前节点跳2 ^ (k - 1)步到某一个节点然后从那个节点再往上跳2 ^ (k - 1)步那么相当于是从j这个节点往上跳2 ^ j步
fa[j][k] = fa[fa[j][k - 1]][k - 1]
def lca(self, a: int, b: int, fa: List[List[int]], depth: List[int]):
# 确保a的深度比b的深度要大
if depth[a] < depth[b]:
a, b = b, a
# 1. 首先是从将深度较大的点跳到与深度较低的高度
for k in range(16, -1, -1):
if depth[fa[a][k]] >= depth[b]:
# a往上跳直到两者的深度相等(两个节点的深度一定会相等相当于是使用2 ^ i去凑来对应的深度是一定可以凑出来的)
a = fa[a][k]
# 说明b是a的祖先直接返回即可
if a == b: return a
# 2. 两个节点同时往上跳直到fa[a][k] = fa[b][k], 说明a再往上跳一步就是当前的最近公共最先
for k in range(16, -1, -1):
if fa[a][k] != fa[b][k]:
a = fa[a][k]
b = fa[b][k]
# 节点a往上跳1步就是两个节点的最近公共祖先
return fa[a][0]
# 需要理解其中的跳的过程
def process(self):
# n个节点
n = int(input())
root = 0
# 注意节点编号不一定是1~n
g = [list() for i in range(5 * 10 ** 4)]
for i in range(n):
a, b = map(int, input().split())
if b == -1:
# 当前的a是根节点
root = a
else:
# 注意是无向边
g[a].append(b)
g[b].append(a)
INF = 10 ** 10
fa, depth = [[0] * 17 for i in range(5 * 10 ** 4)], [INF] * (5 * 10 ** 4)
# bfs预处理fa和depth列表
self.bfs(root, fa, depth, g)
# m个询问
m = int(input())
for i in range(m):
x, y = map(int, input().split())
t = self.lca(x, y, fa, depth)
if t == x: print(1)
elif t == y: print(2)
else: print(0)
Solution().process()模版题链接🔗: 【模板】最近公共祖先(LCA) - 洛谷
二分图匹配
def find(x): # x表示左半部分第x号点
for j in graph[x]: # 遍历与左半部分x号点相连的右半部分的节点
if st[j]==False:
st[j]=True
if match[j]==0 or find(match[j]): # 如果右半部分的第j号点没有与左半部分匹配或者 与右半部分的第j号点匹配的左半部分的点可以匹配其他点
match[j] = x
return True
return False
模版题链接🔗: 378. 骑士放置 - AcWing题库
并查集
p = [i for i in range(N+1)]
def root(x) :
if x != p[x] : # 如果自己不是祖先
p[x] = root(p[x]) # 就寻找自己的父亲是否是祖先
return p[x] # 返回祖先
def union(x,y) :
if root(x) != root(y) : # 如果两个节点不是同一个祖先,说明该两点之间没有边,if为假则说明有边
p[root(x)] = root(y) # 就将两个节点的祖先合并模版题链接🔗: 【模板】并查集 - 洛谷
前缀和与差分
前缀和
lst = list(map(int,input().split())) # 原数组
length = len(lst) # 原数组长度
lst = [0] + lst # 一般前缀和数组的第一个值都是0
for i in range(1,length+1) : # 处理成为前缀和数组
lst[i] += lst[i-1]模版题链接🔗: 连续自然数和 - 洛谷
差分
lst = list(map(int,input().split())) # 原数组
length = len(lst) # 原数组长度
for i in range(length-1,0,-1) : # 处理成为差分数组
lst[i] -= lst[i-1]模版题链接🔗: 语文成绩 - 洛谷
搜索
深度优先搜索
def dfs(u):
#当所有坑位被占满 那么输出储存的路径
if u == n:
for i in range(0,n):
print(path[i], end = " ")
print('')
#另一种(几乎)等价写法ans.append(' '.join(list(map(str, path))))
#从1到n遍历寻找第u个位置可以填的数
for i in range(1, n+1):
#确认数字状态,是否已经被使用 如果没有被占执行下面操作
if not state[i]: #等价于state[i]是[False]
path[u] = i #在坑位上填上次数字
state[i] = True #标注数字状态,已经被使用
dfs(u+1) #进入下一层
state[i] = False #回溯恢复数字状态
模版题链接🔗:165. 小猫爬山 - AcWing题库
广度优先搜索
"""
1. 初始化队列
2. while queue不为空
3. 队顶元素出队
4. 遍历,满足条件的入队
"""
def bfs():
queue = [1]
st[1] = True
d[1] = 0
while queue:
t = queue.pop(0)
if t not in graph: continue
for i in graph[t]:
if not st[i]:
st[i] = True
queue.append(i)
if d[i]==-1:
d[i] = d[t]+1
print(d[n])
模版题链接🔗:188. 武士风度的牛 - AcWing题库
记忆化搜索
关于记忆化搜索 我的这两篇博客有详细的讲解:
蓝桥杯/洛谷 : 最长滑雪道/滑雪 + 扩展题目(记忆化搜索 Python)_正在黑化的KS的博客-CSDN博客
Acwing:食物链(记忆化搜索 Python)_正在黑化的KS的博客-CSDN博客
树状数组
def createTree(array) :
_array = [0] + array
length = len(array)
for i in range(1,length+1) :
j = i + (i & -i)
if j < length + 1 :
_array[j] += _array[i]
return _array
def lowbit(x) :
return x & (-x)
def update(array,idx,val) :
# prev = query(idx,idx+1,array) # 若将某节点值更新为val 则打开 / 若增加val 则关闭
idx += 1
# val -= prev
while idx < len(array) :
array[idx] += val
idx += lowbit(idx)
return array
def query(begin,end,array) : # 输入索引皆以0为初始点
return _query(end,array) - _query(begin,array)
def _query(idx,array) :
res = 0
while idx > 0 :
res += array[idx]
idx -= lowbit(idx)
return res模版题链接🔗:【模板】树状数组 1 - 洛谷
单调栈
# 单调递增
def IncreasingStack(nums):
stack = []
for num in nums:
# 当前值大于栈顶元素,将栈顶元素弹出
while stack and num >= stack[-1]:
stack.pop()
stack.append(num)
# 单调递减
def DecreasingStack(nums):
stack = []
for num in nums :
while stack and num <= stack[-1]:
stack.pop()
stack.append(num)模版题链接🔗:600. 仰视奶牛 - AcWing题库
写在最后
上述整理内容基本上是蓝桥杯省赛的高频考察内容 但并不是全部 当然正如我开头说的
只要将这些内容理解并掌握 省一真的就是洒洒水啦~
如果觉得有用的话~给个赞💕好吗 你的鼓励就是我写作的动力!