一、Flink的引入
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有Hadoop、Storm,以及后来的Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
l 第1代——Hadoop MapReduce
首先第一代的计算引擎,无疑就是Hadoop 承载的 MapReduce。它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法
l 第2代——DAG框架(Tez) + MapReduce
由于这样的弊端,催生了支持DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务
l 第3代——Spark
接下来就是以Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
l 第4代——Flink
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
批处理、流处理、SQL高层API支持自带DAG流式计算性能更高、可靠性更高
二、Flink发展史
Flink诞生背景
Flink起源于Stratosphere项目,Stratosphere是在2010~2014年由地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目。
2014年4月捐赠给了Apache软件基金会
2014年12月成为Apache软件基金会的顶级项目。
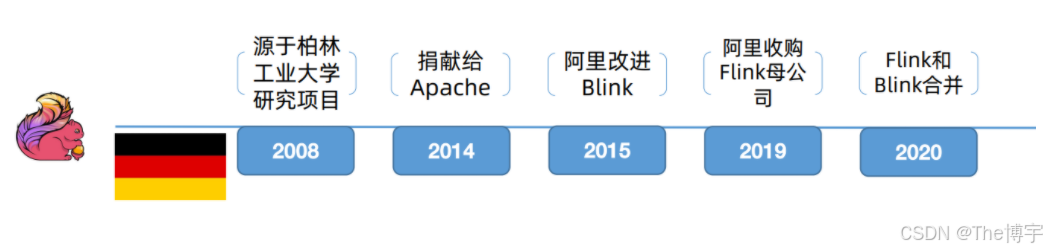
2008年,Flink 的前身已经是柏林理工大学一个研究性项目,原名 StratoSphere。
2014-04-16,Flink成为 ASF(Apache Software Foundation)的顶级项目之一,从Stratosphere 0.6开始,正式更名为Flink。由Java语言编写;
2014-11-04,Flink 0.7.0发布,介绍了最重要的特性:Streaming API
2016-03-08,Flink 1.0.0,支持 Scala
2019-01-08,阿里巴巴以9000万欧元的价格收购了总部位于柏林的初创公司Data Artisans,也就是Flink的母公司。
LOGO介绍:
在德语中,Flink一词表示快速和灵巧,项目采用松鼠的彩色图案作为logo,Flink的松鼠logo尾巴的颜色与Apache软件基金会的logo颜色相呼应,也就是说,这是一只Apache风格的松鼠。
 三、 Flink官方介绍
三、 Flink官方介绍
官网:Apache Flink Documentation | Apache Flink
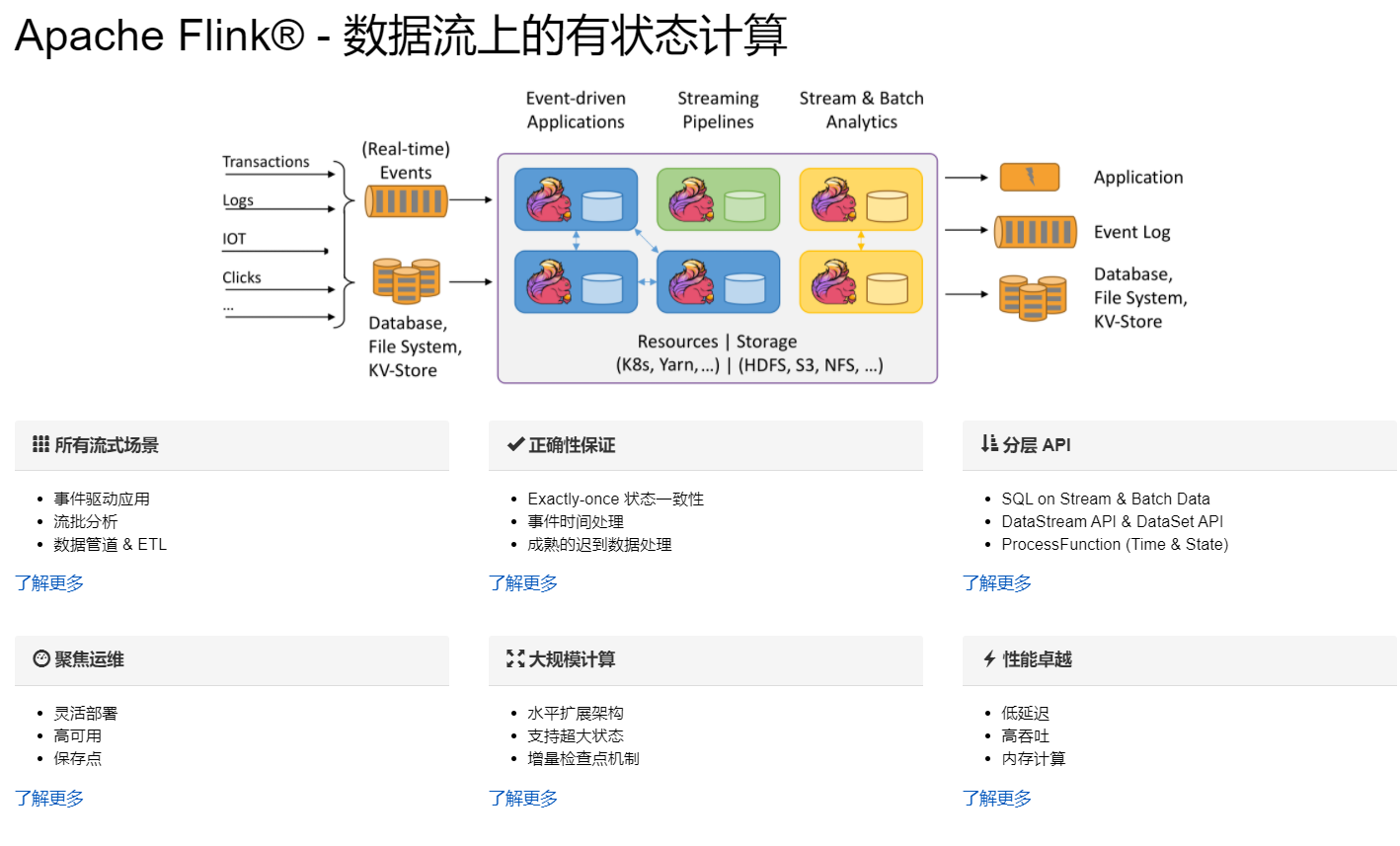
Flink主页在其顶部展示了该项目的理念:“Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Flink是一款分布式的计算引擎,它可以用来做流处理;也可以用来做批处理。
四、Flink中的批和流
批处理的特点是有界、持久、大量,非常适合需要访问全部记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统 传输的每个数据项执行操作,一般用于实时统计。
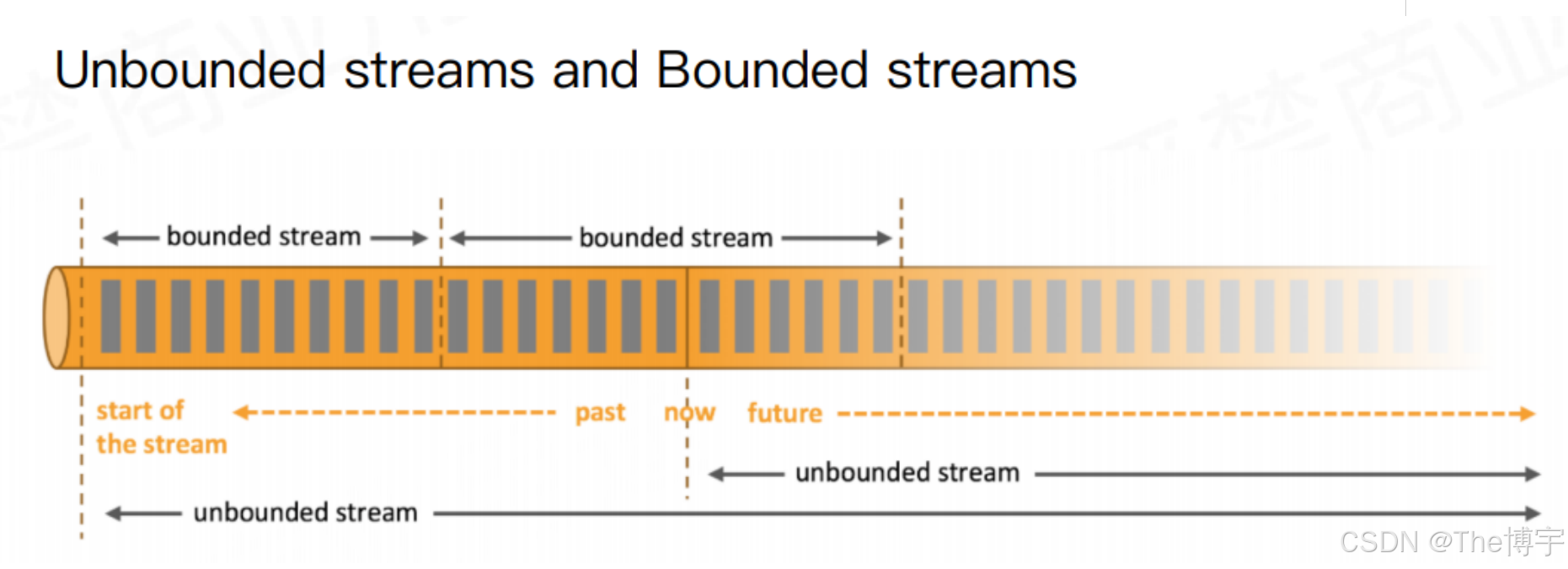
而在Flink中,一切都是由流组成的,Flink认为有界数据集是无界数据流的一种特例,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
无界流:意思很明显,只有开始没有结束。必须连续的处理无界流数据,也即是在事件注入之后立即要对其进行处理。不能等待数据到达了再去全部处理,因为数据是无界的并且永远不会结束数据注入。处理无界流数据往往要求事件注入的时候有一定的顺序性,例如可以以事件产生的顺序注入,这样会使得处理结果完整。
有界流:也即是有明确的开始和结束的定义。有界流可以等待数据全部注入完成了再开始处理。注入的顺序不是必须的了,因为对于一个静态的数据集,我们是可以对其进行排序的。有界流的处理也可以称为批处理。
五、性能比较
Spark和Flink全部都运行在Hadoop YARN上,性能为Flink > Spark > Hadoop(MR),迭代次数(数据量)越多越明显,性能上,Flink优于Spark和Hadoop最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能。
六、Standalone集群模式安装部署
1、Flink支持多种安装模式。
local(本地)——本地模式
standalone——独立模式,Flink自带集群,开发测试环境使用
standaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用
yarn——计算资源统一由Hadoop YARN管理,生产环境测试
下载链接:
https://archive.apache.org/dist/flink/flink-1.13.1/flink-1.13.1-bin-scala_2.11.tgz
2、上传Flink安装包,解压,配置环境变量
[root@hadoop11 modules]# tar -zxf flink-1.13.6-bin-scala_2.11.tgz -C /opt/installs/
[root@hadoop11 installs]# mv flink-1.13.6/ flink
[root@hadoop11 installs]# vim /etc/profile
export FLINK_HOME=/opt/installs/flink
export PATH=$PATH:$FLINK_HOME/bin
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop
记得source /etc/profile3、修改配置文件
① /opt/installs/flink/conf/flink-conf.yaml
cd /opt/installs/flink/conf/flink-conf.yamljobmanager.rpc.address: bigdata01
taskmanager.numberOfTaskSlots: 2
web.submit.enable: true
#历史服务器 如果HDFS是高可用,则复制core-site.xml、hdfs-site.xml到flink的conf目录下 hadoop11:8020 -> hdfs-cluster
jobmanager.archive.fs.dir: hdfs://bigdata01:9820/flink/completed-jobs/
historyserver.web.address: bigdata01
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://bigdata01:9820/flink/completed-jobs/② /opt/installs/flink/conf/masters
cd /opt/installs/flink/conf/mastersbigdata01:8081③ /opt/installs/flink/conf/workers
cd /opt/installs/flink/conf/workersbigdata01
bigdata02
bigdata034、 上传jar包并分发
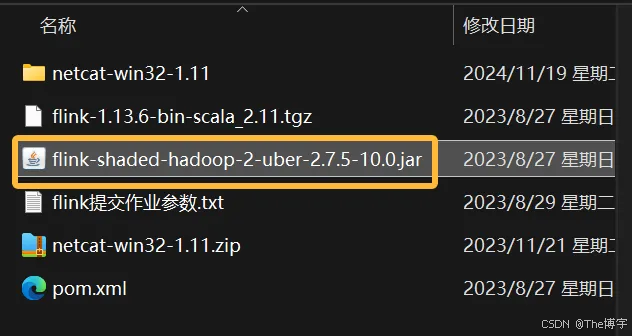
将资料下的flink-shaded-hadoop-2-uber-2.7.5-10.0.jar放到flink的lib目录下
分发:
xsync.sh /opt/installs/flink
xsync.sh /etc/profile七、启动
1、先启动集群
#启动HDFS
start-dfs.sh
#启动集群
start-cluster.sh
#启动历史服务器
historyserver.sh start假如 historyserver 无法启动,也就没有办法访问 8082 服务,原因大概是你没有上传 关于 hadoop 的 jar 包到 lib 下:
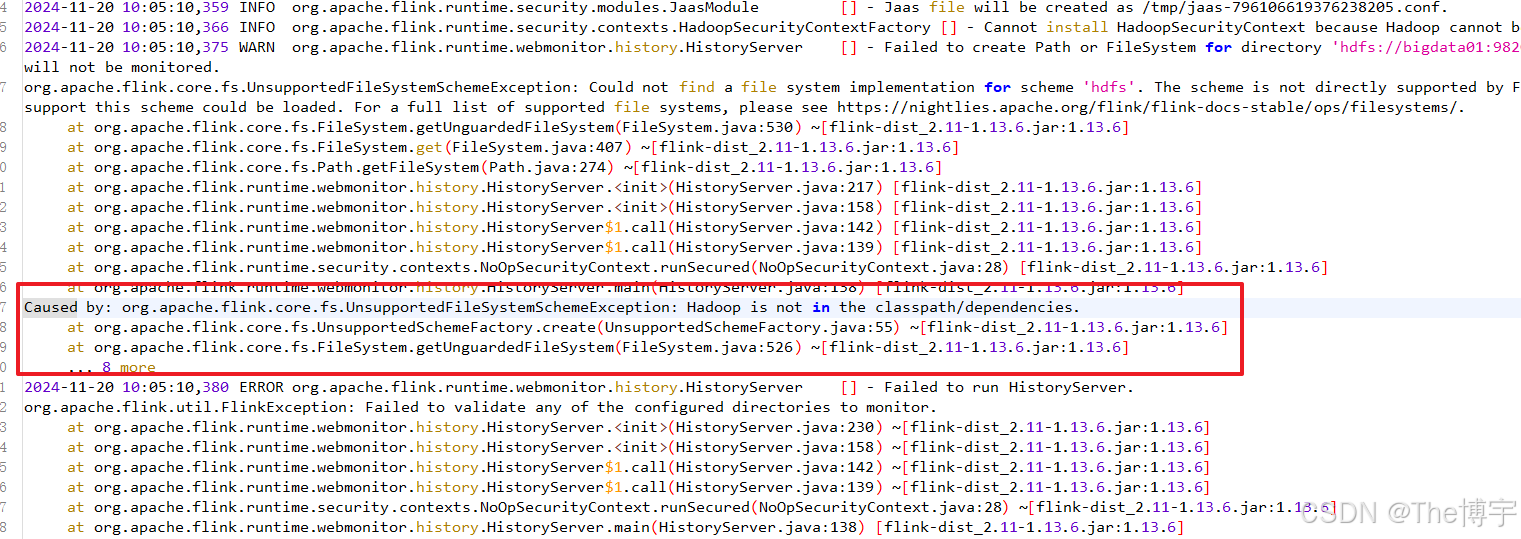
2、 观察webUI:
http://bigdata01:8081 -- Flink集群管理界面 当前有效,重启后里面跑的内容就消失了
能够访问8081是因为你的集群启动着呢
http://bigdata01:8082 -- Flink历史服务器管理界面,及时服务重启,运行过的服务都还在
能够访问8082是因为你的历史服务启动着·8081:Fink master的webUI端口,同时也是spark worker 的webUI端口。
两者的区别:
首先可以先把服务都停止
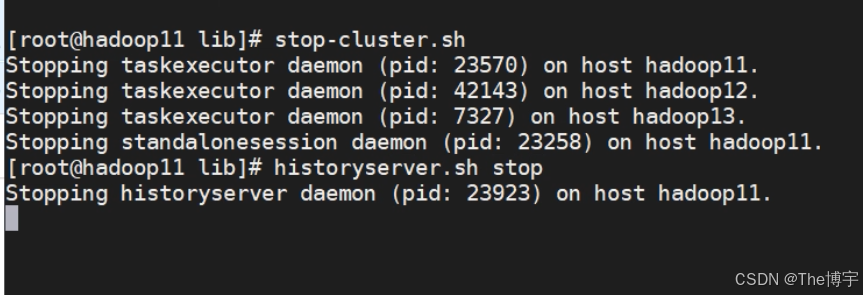
然后再重启,发现8081上已经完成的任务中是空的,而8082上的历史任务都还在,原因是8082读取了hdfs上的一些数据,而8081没有。
但是从web提供的功能来看,8081提供的功能还是比8082要丰富的多。
3、提交官方示例
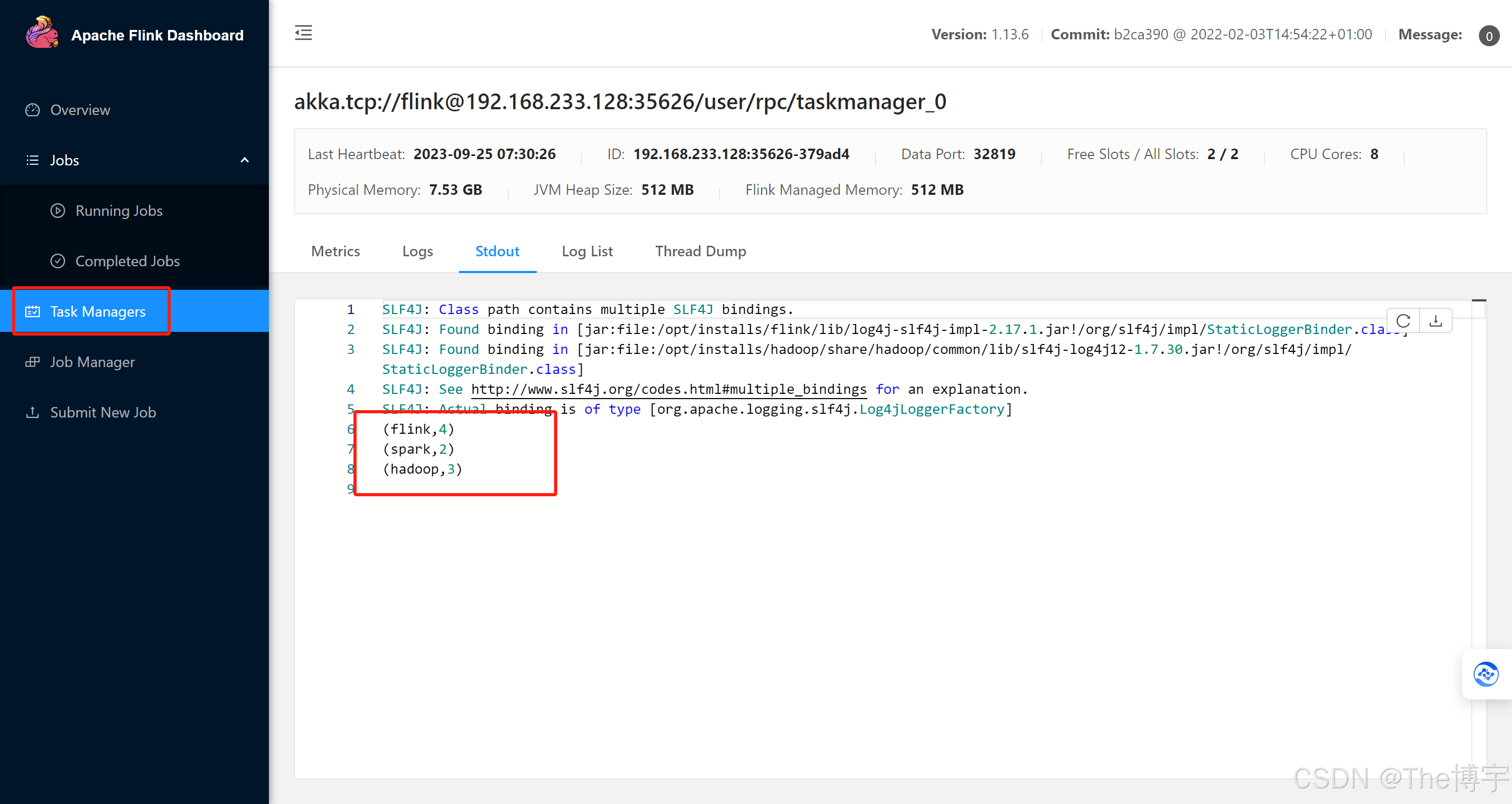
flink run /opt/installs/flink/examples/batch/WordCount.jar
或者
flink run /opt/installs/flink/examples/batch/WordCount.jar --input 输入数据路径 --output 输出数据路径
flink run /opt/installs/flink/examples/batch/WordCount.jar --input /home/wc.txt --output /home/result运行以上案例时,会出现有时候运行成功,有时候运行失败的问题:
Caused by: java.io.FileNotFoundException: /home/wc.txt (没有那个文件或目录)
at java.io.FileInputStream.open0(Native Method)
at java.io.FileInputStream.open(FileInputStream.java:195)
at java.io.FileInputStream.<init>(FileInputStream.java:138)
at org.apache.flink.core.fs.local.LocalDataInputStream.<init>(LocalDataInputStream.java:50)
at org.apache.flink.core.fs.local.LocalFileSystem.open(LocalFileSystem.java:134)
at org.apache.flink.api.common.io.FileInputFormat$InputSplitOpenThread.run(FileInputFormat.java:1053)
原因是:你的 taskManager 有三台,你的数据只在本地存放一份,所以需要将数据分发给 bigdata02 和 bigdata03
xsync.sh /home/wc.txt