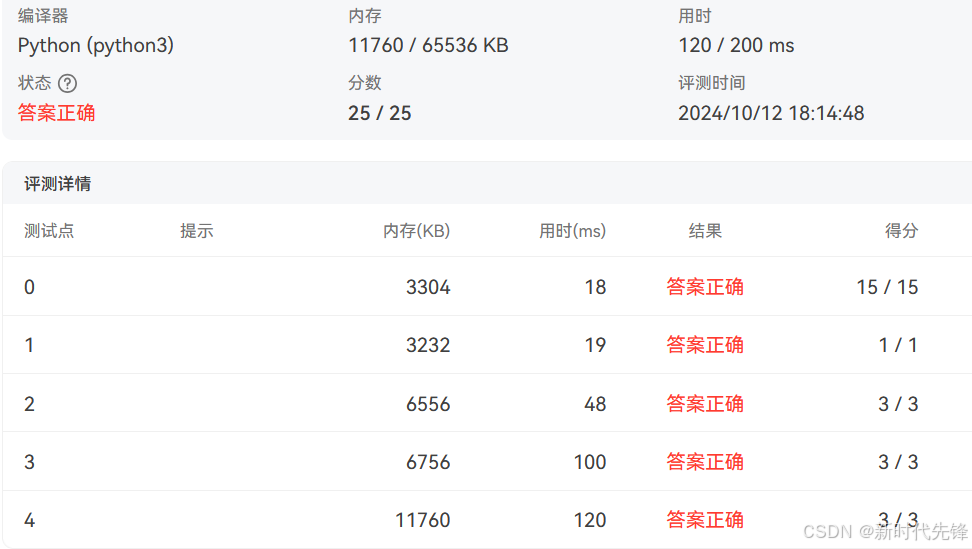
原题链接:PTA | 程序设计类实验辅助教学平台
参考资料:
Tips:以下Python代码仅个人理解,非最优算法,仅供参考!多学习其他大佬的AC代码!
量大管饱题——技巧:
0. 使用sys模块提高Python的输入输出处理速度
-
分类存储:预处理阶段对数据分类存储到多个字典中,这样后续的数据查询就可以直接访问而不必重新遍历。
-
使用
defaultdict:对房间、日期进行计数时,使用defaultdict可简化代码并提高速度。 -
减少重复数据处理:在查询阶段,避免重复计算,将计算放在数据预处理阶段,这样在查询时直接从预处理的结果中获取。
-
强化内存访问效率:通过字典直接访问而不是使用列表进行遍历,提高了内存访问效率。
import sys
from collections import defaultdict
n, m = map(int, sys.stdin.readline().split())
stu = {}
level_index = defaultdict(list) # 记录每个level的学号和分数
room_index = defaultdict(lambda: defaultdict(int)) # 记录每个room的分数和计数
date_index = defaultdict(lambda: defaultdict(int)) # 记录每个日期的room计数
# 数据预处理
for i in range(n):
zkz, score = sys.stdin.readline().split()
score = int(score)
stu[zkz] = score
level = zkz[0]
room = zkz[1:4]
date = zkz[4:10]
level_index[level].append((zkz, score))
room_index[room][zkz] += score
date_index[date][room] += 1
for i in range(1, m + 1):
query_type, cmd = sys.stdin.readline().split()
sys.stdout.write(f'Case {i}: {query_type} {cmd}\n')
if query_type == '1':
# 根据预处理好的数据,快速获取
res = level_index[cmd]
if res:
res.sort(key=lambda x: (-x[1], x[0]))
for zkz, score in res:
sys.stdout.write(f'{zkz} {score}\n')
else:
sys.stdout.write('NA\n')
elif query_type == '2':
sum_scores = sum(room_index[cmd][zkz] for zkz in room_index[cmd])
count = len(room_index[cmd])
if count > 0:
sys.stdout.write(f'{count} {sum_scores}\n')
else:
sys.stdout.write('NA\n')
elif query_type == '3':
res = date_index[cmd]
if res:
sorted_res = sorted(res.items(), key=lambda x: (-x[1], x[0]))
for room, cnt in sorted_res:
sys.stdout.write(f'{room} {cnt}\n')
else:
sys.stdout.write('NA\n')