SparkSQL
1、SparkSql初识案例 :WordCount
- spark sql处理数据的步骤
- 1、读取数据源
- 2、将读取到的DF注册成一个临时视图
- 3、使用sparkSession的sql函数,编写sql语句操作临时视图,返回的依旧是一个DataFrame
- 4、将结果写出到hdfs上
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, Dataset, Row, SaveMode, SparkSession}
object Demo1WordCount {
def main(args: Array[String]): Unit = {
//创建编写spark sql的环境
val sparkSession: SparkSession = SparkSession
/**
* 用于创建或配置 SparkSession 实例的一个构建器(Builder)模式的应用
* 使用 SparkSession.builder(),你可以链式地设置各种配置选项,
* 并最终通过调用 .getOrCreate() 方法来获取一个 SparkSession 实例。
*/
.builder()
// 执行模式:本地执行
.master("local")
// 名称
.appName("sql语法风格编写WordCount")
// 获取SparkSession.builder()创建的 SparkSession 实例
.getOrCreate()
/**
* spark sql是spark core的上层api,如果要想使用rdd的编程
* 可以直接通过sparkSession获取SparkContext对象
*/
val context: SparkContext = sparkSession.sparkContext
//spark sql的核心数据类型是DataFrame(注意与RDD的区别)
val df1: DataFrame = sparkSession.read
.format("csv") // 读取csv格式的文件,但是实际上这种做法可以读取任意分隔符的文本文件
.option("sep", "\n") //指定读取数据的列与列之间的分隔符
.schema("line STRING") // 指定表的列字段 包括列名和列数据类型
// 读取文件数据
.load("spark/data/wcs/words.txt")
// println(df1)
//查看DataFrame的数据内容
// df1.show()
//查看表结构
// df1.printSchema()
/**
* sql语句是无法直接作用在DataFrame上面的
* 需要提前将要使用sql分析的DataFrame注册成一张表(临时视图)
*/
//老版本的做法将df注册成一张表
// df1.registerTempTable("wcs")
df1.createOrReplaceTempView("wcs")
/**
* 编写sql语句作用在表上
* sql语法是完全兼容hive语法
*/
val df2: DataFrame = sparkSession.sql(
"""
|select
|t1.word,
|count(1) as counts
|from(
|select
|explode(split(line,'\\|')) as word
|from wcs) t1 group by t1.word
|""".stripMargin)
// df2.show()
//通过观察源码发现,DataFrame底层数据类型其实就是封装了DataSet的数据类型
// 对DataFrame或Dataset进行重分区,Spark将这个DataFrame或Dataset的数据重新分配到1个分区中。
val resDS: Dataset[Row] = df2.repartition(1)
/**
* 将计算后的DataFrame保存到本地磁盘文件中
*/
resDS.write
.format("csv") //默认的分隔符是英文逗号
// .option("sep","\t")
.mode(SaveMode.Overwrite) // 如果想每次覆盖之前的执行结果的话,可以在写文件的同时指定写入模式,使用模式枚举类
.save("spark/data/sqlout1") // 保存的路径其实是指定的一个文件夹
}
}
DataFrame DSL
Spark SQL中的DataFrame DSL(Domain Specific Language,领域特定语言)是一种用于处理DataFrame的编程风格,它允许开发者以命令式的方式,通过调用API接口来操作DataFrame。这种风格**介于代码和纯SQL之间,**提供了一种更加灵活和强大的数据处理方式。
DataFrame DSL(Domain Specific Language,领域特定语言)中的API接口是一系列用于操作DataFrame的函数和方法。
1、DSL处理WordCount
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object Demo2DSLWordCount {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("DSL语法风格编写spark sql")
.getOrCreate()
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("line STRING")
.option("sep", "\n")
.load("spark/data/wcs/words.txt")
/**
* 如果要想使用DSL语法编写spark sql的话,需要导入两个隐式转换
*/
//将sql中的函数,封装成spark程序中的一个个的函数直接调用,以传参的方式调用
import org.apache.spark.sql.functions._
//主要作用是,将来可以在调用的函数中,使用$函数,将列名字符串类型转成一个ColumnName类型
//而ColumnName是继承自Column类的
import sparkSession.implicits._
//老版本聚合操作
// df1.select(explode(split($"line","\\|")) as "word")
// .groupBy($"word")
// .count().show()
//新版本聚合操作
// .as("word") == as "word"
val resDF: DataFrame = df1.select(explode(split($"line", "\\|")) as "word")
.groupBy($"word")
.agg(count($"word") as "counts")
resDF
// 重分区
.repartition(1)
.write
.format("csv")
.option("sep","\t")
.mode(SaveMode.Overwrite)
.save("spark/data/sqlout2")
}
}
2、DSLApi
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession, expressions}
object Demo3DSLApi {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
val sparkSession: SparkSession = SparkSession.builder()
.config("spark.sql.shuffle.partitions","1")
.master("local")
.appName("DSL语法风格编写spark sql")
.getOrCreate()
/**
* 如果要想使用DSL语法编写spark sql的话,需要导入两个隐式转换
*/
//将sql中的函数,封装成spark程序中的一个个的函数直接调用,以传参的方式调用
import org.apache.spark.sql.functions._
//主要作用是,将来可以在调用的函数中,使用$函数,将列名字符串类型转成一个ColumnName类型
//而ColumnName是继承自Column类的
import sparkSession.implicits._
/**
* 读取json数据文件,转成DF
* 读取json数据的时候,是不需要指定表结构,可以自动根据json的键值来构建DataFrame
*/
//老版本的读取json数据的方式
// val df1: DataFrame = sparkSession.read
// .format("json")
// .load("spark/data/students.json")
val df1: DataFrame = sparkSession.read
// 由于是json数据,数据中就有它们的列名,所以无需再为它们设置列名
.json("spark/data/students.json")
//默认显示20行数据
// df1.show()
//传入要查看的行数
// df1.show(100)
//传入第二个参数 truncate = false,观察的更加详细,默认每一列只会保留20个字符
// df1.show(10,truncate = false)
/**
* DSL语法的第一个函数 select
* 类似于纯sql语法中的select关键字,传入要查询的列
*/
// select name,clazz from xxx;
df1.select("name","age").show()
df1.select($"name", $"age").show()
//查询每个学生的姓名,原本的年龄,年龄+1
df1.select("name", "age").show()
/**
* 与select功能差不多的查询函数
* 如果要以传字符串的形式给到select的话,并且还想对列进行表达式处理的话,可以使用selectExpr函数
*/
df1.selectExpr("name", "age", "age+1 as new_age").show()
//如果想要使用select函数查询的时候对列做操作的话,可以使用$函数将列变成一个对象
df1.select($"name", $"age", $"age" + 1 as "new_age").show()
/**
* DSL语法函数:where
* === : 类似于sql中的= 等于某个值
* =!= : 类似于sql中的!=或者<> 不等于某个值
*/
df1.where("gender='男'").show()
df1.where("gender='男' and substring(clazz,0,2)='理科'").show()
//TODO 建议使用隐式转换中的功能进行处理过滤,$"gender",将gender转换成一个ColumnName类对象
//过滤出男生且理科的
df1.where($"gender" === "男" and substring($"clazz",0,2) === "理科").show()
//过滤出女生且理科的
df1.where($"gender" =!= "男" and substring($"clazz",0,2) === "理科").show()
/**
* DSL语法函数:groupBy
*
* 非分组字段是无法出现在select查询语句中的
*/
//查询每个班级的人数
df1.groupBy("clazz")
.agg(count("clazz") as "counts")
.show()
/**
* DSL语法函数:orderBy
*/
df1.groupBy("clazz")
.agg(count("clazz") as "counts")
.orderBy($"counts".desc)
.show(3)
/**
* DSL语法函数: join
*/
val df2: DataFrame = sparkSession.read
.format("csv")
.option("sep", ",")
// .schema("sid STRING,subject_id STRING,score INT")
.schema("id STRING,subject_id STRING,score INT")
.load("spark/data/score.txt")
// 关联的字段名不一样的情况
// df2.join(df1,$"id" === $"sid","inner")
// .select("id","name","age","gender","clazz","subject_id","score")
// .show(10)
// 关联的字段名一样的情况
df2.join(df1,"id")
.select("id","name","age","gender","clazz","subject_id","score")
.show(10)
//如果关联的字段名一样且想使用其他连接方式的话,可以将字段名字用Seq()传入,同时可以传连接方式
df2.join(df1, Seq("id"),"left")
.select("id","name","age","gender","clazz","subject_id","score")
.show(10)
/**
* DSL语法函数: 开窗
* 无论是在纯sql中还是在DSL语法中,开窗是不会改变原表条数
*/
//计算每个班级总分前3的学生
//纯sql的方式实现
// df1.createOrReplaceTempView("students")
// df2.createOrReplaceTempView("scores")
// sparkSession.sql(
// """
// |select
// |*
// |from
// |(
// |select t1.id,
// |t2.name,
// |t2.clazz,
// |t1.sumScore,
// |row_number() over(partition by t2.clazz order by t1.sumScore desc) as rn
// |from
// |(
// | select id,
// | sum(score) as sumScore
// | from
// | scores
// | group by id) t1
// |join
// | students t2
// |on(t1.id=t2.id)) tt1 where tt1.rn<=3
// |""".stripMargin).show()
//DSL语法实现
df2.groupBy("id") //根据学号分组
.agg(sum("score") as "sumScore") // 计算每个人总分
.join(df1,"id") // 与学生信息表关联,得到班级列
// over 不要写成 over()
.select($"id",$"name",$"clazz",$"sumScore",row_number() over Window.partitionBy("clazz").orderBy($"sumScore".desc) as "rn")
.where($"rn" <= 3)
// .repartition(1)
.write
.format("csv")
.mode(SaveMode.Overwrite)
.save("spark/data/sqlout3")
}
}
3、SourceApi
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object Demo4SourceAPI {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("data source api")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
/**
* 导入隐式转换你
*/
import org.apache.spark.sql.functions._
import sparkSession.implicits._
/**
* ==========================================读写csv格式的数据==========================================
* 可以读取使用分隔符分开的数据文件,例如.txt文件
* 默认切分的分隔符为 ","
*/
//如果是直接调用csv函数读取数据的话,无法做表结构的设置
val df1: DataFrame = sparkSession.read
.csv("spark/data/test1.csv")
//使用format的形式读取数据的同时可以设置表结构
val df2: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age INT")
.load("spark/data/test1.csv")
df2.show()
val df3: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.option("sep", ",")
.load("spark/data/students.txt")
df3.createOrReplaceTempView("students")
val resDF1: DataFrame = sparkSession.sql(
"""
|select
|clazz,
|count(1) as counts
|from students
|group by clazz
|""".stripMargin)
//以csv格式写出到磁盘文件夹中
resDF1.write
.format("csv")
// .option("sep",",")
// 模式为覆盖写
.mode(SaveMode.Overwrite)
.save("spark/data/sqlout4")
/**
* ==========================================读写json格式的数据==========================================
* 对数据进行读取时,无需为其字段命名,会用它的键值作为列名
*/
val df5: DataFrame = sparkSession.read
.json("spark/data/students.json")
df5.groupBy("age")
.agg(count("age") as "counts")
.write
.json("spark/data/sqlout5")
/**
* ==========================================读写parquet格式的数据==========================================
*
* parquet格式的文件存储,是由【信息熵】决定的
* 存储有大量重复数据时,数据量比一般存储要少
*/
val df6: DataFrame = sparkSession.read
.json("spark/data/students2.json")
//以parquet格式写出去
df6.write
.parquet("spark/data/sqlout7")
// 读取parquet格式的数据
val df4: DataFrame = sparkSession.read
.parquet("spark/data/sqlout7/part-00000-23f5482d-74d5-4569-9bf4-ea0ec91e86dd-c000.snappy.parquet")
df4.show()
/**
* ==========================================读写orc格式的数据==========================================
* 存储大量重复的数据时,数据量最少
* 最常使用
*/
val df7: DataFrame = sparkSession.read
.json("spark/data/students2.json")
df7.write
.orc("spark/data/sqlout8")
sparkSession.read
.orc("spark/data/sqlout8/part-00000-a33e356c-fd1f-4a5e-a87f-1d5b28f6008b-c000.snappy.orc")
.show()
/**
* ==========================================读写jdbc格式的数据==========================================
*
*/
sparkSession.read
.format("jdbc")
.option("url", "jdbc:mysql://192.168.128.100:3306/studentdb?useUnicode=true&characterEncoding=UTF-8&useSSL=false")
.option("dbtable", "studentdb.jd_goods")
.option("user", "root")
.option("password", "123456")
.load()
.show(10,truncate = false)
}
}
4、RDD到DataFrame的类型转换
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object Demo5RDD2DataFrame {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("rdd与df之间的转换")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
//通过SparkSession获取sparkContext对象
val sparkContext: SparkContext = sparkSession.sparkContext
//作用1:使用$函数,将字符串转换成列名对象
//作用2:可以在不同的数据结构之间转换
import sparkSession.implicits._
/**
* spark core的核心数据结构是:RDD
* spark sql的核心数据结构是DataFrame
*/
// RDD->DataFrame .toDF
val linesRDD: RDD[String] = sparkContext.textFile("spark/data/students.txt")
val stuRDD: RDD[(String, String, String, String, String)] = linesRDD.map((line: String) => {
line.split(",") match {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
(id, name, age, gender, clazz)
}
})
val resRDD1: RDD[(String, Int)] = stuRDD.groupBy(_._5)
.map((kv: (String, Iterable[(String, String, String, String, String)])) => {
(kv._1, kv._2.size)
})
val df1: DataFrame = resRDD1.toDF
val df2: DataFrame = df1.select($"_1" as "clazz", $"_2" as "counts")
/**
*用于打印出该数据集的架构(schema)信息。
* 架构是指数据集中各列的名称、数据类型以及可能的元数据(如是否为空、默认值等)。
*/
df2.printSchema()
// DataFrame->RDD .rdd
val resRDD2: RDD[Row] = df2.rdd
//TODO RDD[Row]类型数据的取值
resRDD2.map((row:Row)=>{
val clazz: String = row.getAs[String]("clazz")
//TODO 这里的泛型最好使用Integer与在DataFrame中的类型保持一致
val counts: Integer = row.getAs[Integer]("counts")
s"班级:$clazz, 人数:$counts"
}).foreach(println)
resRDD2.map {
case Row(clazz:String, counts:Integer)=>
s"班级:$clazz, 人数:$counts"
}.foreach(println)
}
}
5、开窗函数
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 开窗:over
* 聚合开窗函数:sum count lag(取上一条) lead(取后一条)
* 排序开窗函数:row_number rank dense_rank
*
* 练习开窗的题目: DSL语法去做
* 统计总分年级排名前十学生各科的分数
* 统计每科都及格的学生
* 统计总分大于年级平均分的学生
* 统计每个班级的每个名次之间的分数差
*/
object Demo6WindowFun {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("rdd与df之间的转换")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
/**
* 导入隐式转换你
*/
import org.apache.spark.sql.functions._
import sparkSession.implicits._
/**
* 读取三个数据文件
* 补充:
* agg() 方法允许你指定一个或多个聚合函数,这些函数将应用于 DataFrame 的列上,以生成聚合后的结果。
* withColumn():用于向 DataFrame 中添加新的列或替换已存在的列。
*/
val studentsDF: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.load("spark/data/students.txt")
// studentsDF.show()
val scoresDF: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,subject_id STRING,score INT")
.load("spark/data/score.txt")
// scoresDF.show()
val subjectsDF: DataFrame = sparkSession.read
.format("csv")
.schema("subject_id STRING,subject_name STRING,subject_score INT")
.load("spark/data/subject.txt")
// subjectsDF.show()
//统计总分年级排名前十学生各科的分数
/**
* dense_rank() 在处理并列排名时不会留下空缺。
* 即,如果有两行或多行具有相同的排名依据值,它们将被赋予相同的排名,
* 并且下一个排名的值会紧接着这些并列排名的最后一个值
*/
val resDS1: Dataset[Row] = scoresDF.join(studentsDF, "id")
.withColumn("sumScore", sum("score") over Window.partitionBy("id"))
.withColumn("rn", dense_rank() over Window.partitionBy(substring($"clazz", 0, 2)).orderBy($"sumScore".desc))
.where($"rn" <= 10)
.limit(120)
//统计每科都及格的学生
val resDS2: Dataset[Row] = scoresDF.join(subjectsDF, "subject_id")
.where($"score" >= $"subject_score" * 0.6)
.withColumn("jigeCount", count(expr("1")) over Window.partitionBy($"id"))
.where($"jigeCount" === 6)
//统计总分大于年级平均分的学生,TODO(注:需要对年级进行分组:文科/理科,对班级字段进行切分)
val resDS3: Dataset[Row] = scoresDF
.join(studentsDF, "id")
.withColumn("sumScore", sum($"score") over Window.partitionBy($"id"))
.withColumn("avgScore", avg($"sumScore") over Window.partitionBy(substring($"clazz", 0, 2)))
.where($"sumScore" > $"avgScore")
//统计每个班级的每个名次之间的分数差
scoresDF
.join(studentsDF, "id")
// 使用分组来求解,只查询分组中的字段和聚合后的新字段,而不会出现有科目编号,使一个学生有六组数据的情况
.groupBy("id", "clazz")
.agg(sum("score") as "sumScore")
// |1500100001|文科六班| 406|, 只会输出 groupby 的字段和新添加的字段
.withColumn("rn", row_number() over Window.partitionBy($"clazz").orderBy($"sumScore".desc))
.withColumn("beforeSumScore", lag($"sumScore", 1, 750) over Window.partitionBy($"clazz").orderBy($"sumScore".desc))
.withColumn("cha", $"beforeSumScore" - $"sumScore")
.show()
}
}
6、concat() 与 agg() 的补充
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo9Test {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("提交到yarn 计算每个班级的人数")
//参数设置的优先级:代码优先级 > 命令优先级 > 配置文件优先级
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.option("sep", ",")
.load("spark/data/students.txt")
//TODO 通过对“数加”的expr("'数加: '")处理,使得其可以拼接到所查询的数据中
df1.select($"name", concat(expr("'数加: '"),$"name") as "new_str").show()
// TODO agg(): 可以同时添加多个新的列
df1.groupBy($"clazz")
.agg(
count(expr("1")) as "counts",
avg($"age") as "avgAge"
).show()
}
}
7、提交到yarn上进行执行
idea里面将代码编写好打包上传到集群中运行,上线使用
--conf spark.sql.shuffle.partitions=1 -- 设置spark sqlshuffle之后分区数据,和代码里面设置是一样的,代码中优先级高
spark-submit提交
spark-submit --master yarn-client --class com.shujia.sql.Demo8SubmitYarn --conf spark.sql.shuffle.partitions=1 spark-1.0.jar
//新版本spark提交yarn的命令
spark-submit --master yarn --deploy-mode client --class com.shujia.sql.Demo10SparkOnHive --conf spark.sql.shuffle.partitions=100 spark-1.0.jar
// 样例:
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo8SubmitYarn {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
// .master("local")
.appName("提交到yarn 计算每个班级的人数")
//TODO 设置shuffle分区数(进行重分区),参数设置的优先级:代码优先级 > 命令优先级 > 配置文件优先级
// 分区数越多,并行度越高,理论上可以加快数据处理速度。但过高的分区数也可能导致调度和管理开销增加,反而降低性能。
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
// TODO 下面函数中的路径为HDFS上的路径(图为要打包到集群中运行)
.load(args(0))
val df2: DataFrame = df1.groupBy($"clazz")
.agg(count($"id") as "counts")
df2.show()
df2.write
// 将数据存储到HDFS上的路径
.csv(args(1))
}
}
// 实例:
// 执行语句:spark-submit --master yarn --deploy-mode client --class com.shujia.sql.Demo10SparkOnHive --conf spark.sql.shuffle.partitions=100 spark-1.0.jar
import org.apache.spark.sql.SparkSession
object Demo10SparkOnHive {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("提交到yarn 计算每个班级的人数")
//参数设置的优先级:代码优先级 > 命令优先级 > 配置文件优先级
.config("spark.sql.shuffle.partitions", "1")
.enableHiveSupport() // 开启hive的配置
.getOrCreate()
sparkSession.sql("use ads")
//truncate = false 时,完整地显示某列值,不进行任何截断。
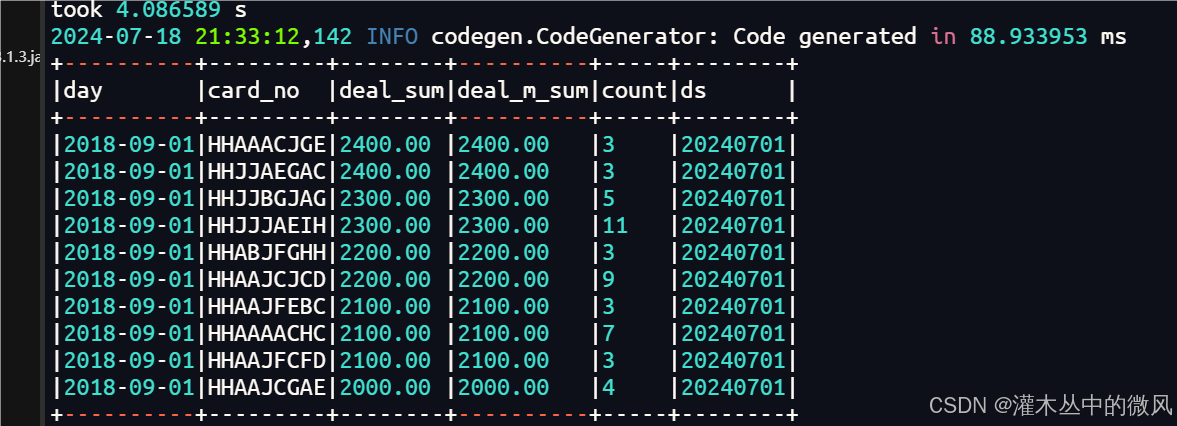
sparkSession.sql("select * from ads_card_deal_day_top limit 10").show(truncate = false)
/**
* spark-submit --master yarn --deploy-mode client --class com.shujia.sql.Demo10SparkOnHive --conf spark.sql.shuffle.partitions=100 spark-1.0.jar
*/
}
}
结果:
8、spark shell
**–Spark提供的命令行界面 ,**提供了一个REPL(Read-Eval-Print Loop)环境。
**REPL:“Read(读取)-Eval(求值)-Print(打印)-Loop(循环)” **
里面使用sqlContext , 测试使用,简单任务使用
//进行命令:
spark-shell --master yarn-client
spark-shell --master yarn --deploy-mode client
//不能使用yarn-cluster Driver必须再本地启动
//示例:
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
import spark.implicits._
val df1: DataFrame = spark.read.format("csv").schema("id STRING,name STRING,age INT,gender STRING,clazz STRING").load("/bigdata30/spark_in/students.csv")
val df2: DataFrame = df1.groupBy($"clazz").agg(count($"id") as "counts")
df2.show()
df2.write
.csv(args(1))
spark sql整合hive
在spark sql中使用hive的元数据
spark sql是使用spark进行计算的,hive使用MR进行计算的
1、在hive的hive-site.xml修改一行配置,增加了这一行配置之后,以后在使用hive之前都需要先启动元数据服务
vim /usr/local/soft/hive-1.2.1/conf/hive-site.xml
<!-- 在配置hive时已经配置好了,作用是可以让一台机器开启hive作为服务器,使用另一台机器连接它,实现对hive表的操作 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
2、启动hive元数据服务, 将hvie的元数据暴露给第三方使用
nohup hive --service metastore >> metastore.log 2>&1 &
3、将hive-site.xml 复制到spark conf目录下
cp hive-site.xml /usr/local/soft/spark-3.1.3/conf/
4、 将mysql 驱动包复制到spark jars目录下
cd /usr/local/soft/hive-3.1.2/lib
cp mysql-connector-java-8.0.29.jar /usr/local/soft/spark-3.1.3/jars/
5、spark-sql spark-sql --master yarn --deploy-mode client 不能使用yarn-cluster 和hive的命令行一样,直接写sql
在spark-sql时完全兼容hive sql的
spark-sql底层使用的时spark进行计算的
hive 底层使用的是MR进行计算的
注:
在打开命令行界面界面后,使用ctrl + z 并不能使它在yarn上的任务停止
本地虚拟机资源过少,ctrl + z 后再次进入命令行界面,默认重新开启一个yarn上的任务.但是资源无法支撑开启两个任务,这就导致再次进入时无法获取需要的资源.
需要使用命令:
yarn application -kill application_1721303356522_0006
hadoop yarn application -kill application_1721303356522_0006
spark-sql --master yarn --deploy-mode client
spark-sql:这是启动 Spark SQL CLI 的命令。
Spark SQL的命令行界面(Command-Line Interface),它允许用户通过命令行输入SQL查询和操作,然后将这些命令发送到Spark集群进行执行,并在界面中显示运行过程和最终的结果。
Spark SQL 是 Spark 的一个模块,它允许用户以 SQL 的方式查询数据。Spark SQL 支持多种数据源,并且可以与 DataFrame API 紧密集成。
--master yarn
yarn 表示 Spark 应用程序将通过 YARN(Yet Another Resource Negotiator)集群管理器来管理资源。
--deploy-mode client
这个选项指定了 Spark 应用程序的部署模式。Spark 支持两种部署模式:client 和 cluster。
# 模式是local模式
# 设置在进行shuffle操作(如join、groupBy、sort等)时,使用的分区(partition)数量为2。
spark-sql -conf spark.sql.shuffle.partitions=2
# 使用yarn-client模式
# 这个命令启动了一个 Spark SQL CLI 会话,该会话通过 YARN 集群管理器以 client 模式运行,并且在进行 shuffle 操作时仅使用 1 个分区。
spark-sql --master yarn-client --conf spark.sql.shuffle.partitions=1
#在spark-sql中设置运行参数
set spark.sql.shuffle.partitions=2;
# 查看数据库
show databases;
# 选择数据库
use XXX;
6、类似于hive的第三种交互方式,无需进行命令行界面即可执行SQL
spark-sql -e
spark-sql -f
-- 执行一条sql语句,执行完,自动退出
spark-sql -e "select * from student"
-- 编写一个sql文件,来执行这个sql文件
vim a.sql
select * from student
-- 执行一个sql文件
spark-sql -f a.sql
7、在idea中通过spark来对hive中的表进行操作
添加依赖
<!-- 在idea中添加下列配置 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.0</version>
添加下列xml文件
core-site.xml:
log4j.properties文件,是用于修改启动 Spark SQL CLI 时日志文件的内容,使其只会输出特定的文件日志
8、自定义类继承UDF类,在Spark SQL的命令行界面执行
步骤:
1、自定义类继承UDF类,重写evaluate方法
2、打包,spark-1.0.jar 将jar包放到spark目录下的jars目录下 /usr/local/soft/spark-3.1.3/jars
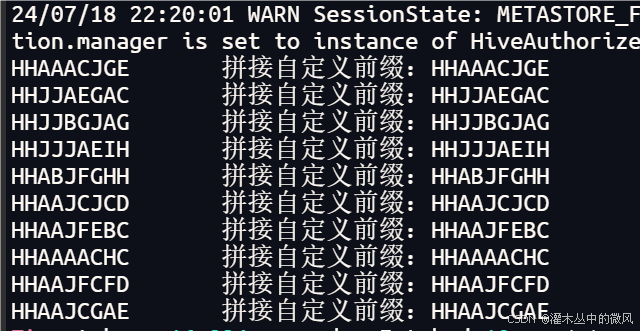
3、在spark-sql命令行中注册函数
create function new as ‘com.shujia.sql.Demo13Str’
执行:
import org.apache.hadoop.hive.ql.exec.UDF
class Demo13Str extends UDF {
def evaluate(line: String): String = "拼接自定义前缀:" + line
}
结果:
9、实现案例
将代码提交到yarn,调用HDFS上的数据,由spark进行操作。将输出结果写回到HDFS上,并将改数据映射到Hive上形成一张表。
执行:
-- 上传jar后进行执行 spark-submit --master yarn --deploy-mode client --class com.shujia.sql.Demo14SheBao --conf spark.sql.shuffle.partitions=100 spark-1.0.jar
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object Demo14SheBao {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("社保练习")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,burk STRING,sdate STRING")
.load("/bigdata30/experience.txt")
val resDF: DataFrame = df1.withColumn("before_burk", lag($"burk", 1) over Window.partitionBy($"id").orderBy($"sdate"))
.select(
$"id",
$"burk",
$"sdate",
when($"before_burk".isNull, $"burk").otherwise($"before_burk") as "before_burk"
).withColumn("flag", when($"burk" === $"before_burk", 0).otherwise(1))
.withColumn("tmp", sum($"flag") over Window.partitionBy($"id").orderBy($"sdate"))
.groupBy($"id", $"burk", $"tmp")
.agg(
min($"sdate") as "start_date",
max($"sdate") as "end_date"
).select($"id", $"burk", $"start_date", $"end_date")
resDF.write
.format("csv")
.mode(SaveMode.Overwrite)
.save("/bigdata30/spark_out4")
}
}
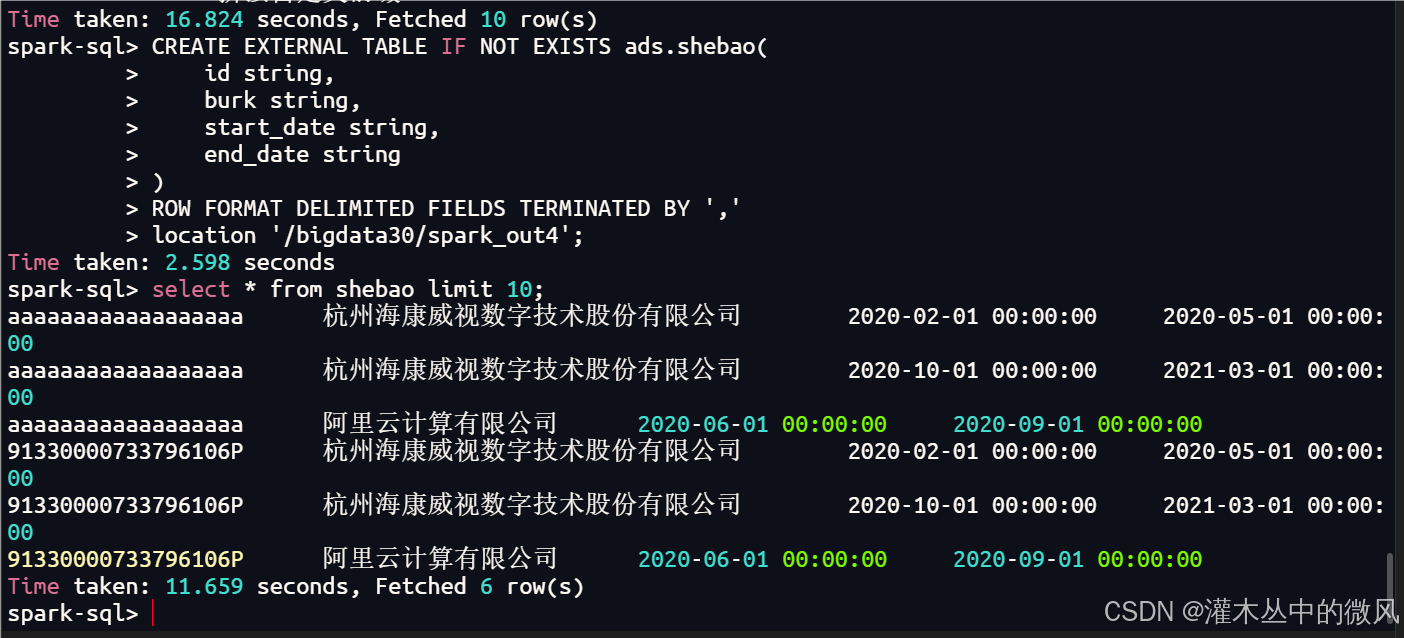
-- 在命令行界面执行将HDFS上的数据映射成一张表
CREATE EXTERNAL TABLE IF NOT EXISTS ads.shebao(
id string,
burk string,
start_date string,
end_date string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
location '/bigdata30/spark_out4';
结果:
禁用集群spark日志
cd /usr/local/soft/spark-2.4.5/conf
mv log4j.properties.template log4j.properties
vim log4j.properties
修改配置
log4j.rootCategory=ERROR, console
spark sql和hive区别
1、spark sql缓存
-- 进入spark sql命令行
spark-sql
-- 可以通过一个网址访问spark任务
http://master:4040
-- 设置并行度
set spark.sql.shuffle.partitions=1;
-- 再spark-sql中对同一个表进行多次查询的时候可以将表缓存起来
cache table student;
-- 删除缓存
uncache table student;
-- 再代码中也可以缓存DF
studentDF.persist(StorageLevel.MEMORY_ONLY)
2、spark sql mapjoin — 广播变量
Reduce Join
select * from
student as a
join
score as b
on
a.id=b.student_id
MapJoin
当一个大表关联小表的时候可以将小表加载到内存中进行关联---- 广播变量
在map端进行表关联,不会产生shuffle
select /*+broadcast(a) */ * from
student as a
join
score as b
on
a.id=b.student_id