创建一个streaming目录
mkdir streaming
一、运行网络版的WordCount
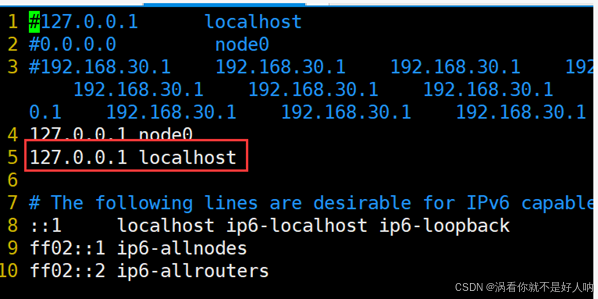
1. 连接虚拟机后利用sudo打开hosts后加入红色方框内语句并保存:
sudo vim /etc/hosts
Netcat是一个用于TCP/UDP连接和监听的Linux工具, 主要用于网络传输及调试领域。先下载:
sudo apt-get update
sudo apt-get -y install netcat-traditional
2. 启动 NetCat 服务端,并在1234端口监听
nc -lk 1234 #在lsn下面输入nc –l –p 1234
- 使用xshell 打开一个新的选项卡,连接虚拟机。启动NetCat客户端,并连接Netcat服务端
nc localhost 1234
注意:如果客户端和服务端不在同一台机器,localhost 可以换成实际IP。
- 在服务端输入以下字符串,并按回车,可以在客户端收到消息,并打印出来。这里注意替换学号为你个人学号。
hello 你的学号
- 在客户端输入字符串,并按回车,可以在服务端收到消息,并打印出来。这里注意替换学号为你个人学号。
你好 你的学号
- 在 NetCat 客户端的选项卡使用quit终止客户端进程。
- 利用有状态操作updateStateByKey实现词频统计。
在streaming目录下新建一个stateful目录,用于保存持久化的数据;接着编写独立的NetWordCountStateful.py代码
| 1 | from pyspark import SparkContext |
| 2 | from pyspark.streaming import StreamingContext |
| 3 | sc = SparkContext("local[2]","NetworkWordCountStateful") |
| 4 | ssc = StreamingContext(sc,10) |
| 5 | |
| 6 | ssc.checkpoint("file:///home/ubuntu/streaming/stateful") |
| 7 | def updateFunction(newValues, runningCount): |
| 8 | if runningCount is None: |
| 9 | runningCount = 0 |
| 10 | return sum(newValues, runningCount) |
| 11 | lines = ssc.socketTextStream('localhost', 1234) |
| 12 | running_counts = lines.flatMap(lambda line:line.split(' ')).map(lambda x:(x,1)).updateStateByKey(updateFunction) |
| 13 | running_counts.pprint() |
| 14 | ssc.start() |
| 15 | ssc.awaitTermination() |
注意:有状态转换需要进行设置检查点。
新建一个终端,开启服务端
| nc -l -p 1234 |
再建一个“流计算”终端,运行NetWordCountStateful.py代码:
| cd $SPARK_HOME/bin | |
| spark-submit /路径/NetWordCountStateful.py |
- 在 NetCat 服务端输入以下字符串,并按回车,观察Streaming WordCount的输出,并截图。
You jump I jump 1234
- 在客户端查看统计结果:
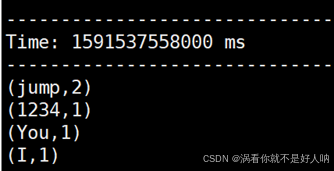
再次在服务端口输入以下字符串:
You and I jump 1234
回车后再次观察Streaming WordCount的输出,是否是累加后的结果。
可以用quit或ctrl+c停掉客户端,利用xshell的回滚来查看结果,因为回滚较快,所以在运行状态下查看结果截图较困难。
二、利用滑动窗口实现WordCount
1. 创建文件流监听目录:
mkdir logfile
cd logfile
- 在streaming目录下新建一个code文件夹,用于持久化数据的存储;然后新开一个终端,输入“pyspark”进入PySpark交互式环境后,输入以下代码:
from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc,10)
ssc.checkpoint("file:///home/ubuntu/streaming/code")
lines = ssc.textFileStream("file:///home/ubuntu/streaming/logfile")
counts = lines.flatMap(lambda x:x.split(' ')).map(lambda x:(x,1)).reduceByKeyAndWindow(lambda x, y:x+y, lambda x,y:x-y, 30, 10)
counts.pprint()
ssc.start()
ssc.awaitTermination()
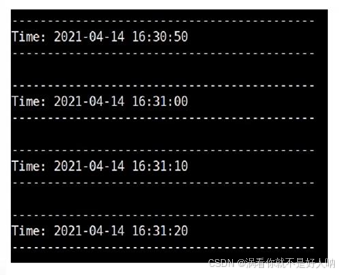
输入ssc.start()后,程序就开始自动进入循环监听状态,如下图所示:
打开一个新的shell窗口,切换到logfile目录下,创建一个log.txt文档保存,再创建一个log_new.txt文档保存,里面输入一些随意的单词,并用空格间隔开。查看监听页面,可以看到打印结果,例如下图所示:
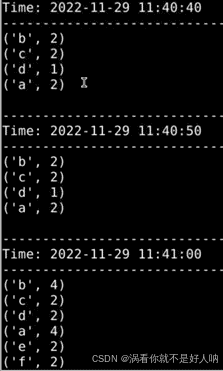
注:log.txt输入为“a b c a b c d”,log_new.txt输入为“a b d e f a b e f”。