✨个人主页欢迎您的访问 ✨期待您的三连 ✨
✨个人主页欢迎您的访问 ✨期待您的三连 ✨
✨个人主页欢迎您的访问 ✨期待您的三连✨




1. K-均值聚类算法的原理解释 ✨ ✨
1.1 算法概述
K-均值(K-Means)聚类算法是一种常用的无监督学习算法,用于将数据集划分为K个簇(Cluster),使得每个簇内的样本尽可能相似,而不同簇之间的样本尽可能不同。算法的目标是通过最小化样本与簇中心之间的距离来实现这一划分。
1.2 算法流程
K-均值聚类的基本思想是通过以下步骤进行迭代优化,直到聚类结果稳定。
- 初始化:选择K个聚类中心(可以随机选择K个数据点,或者通过某些启发式方法初始化)。
- 分配步骤:根据当前聚类中心,将每个数据点分配给距离最近的聚类中心。
- 更新步骤:重新计算每个簇的聚类中心,通常是簇中所有点的均值。
- 重复步骤:不断重复步骤2和3,直到聚类中心不再发生变化或达到预设的迭代次数。
1.3 数学公式
假设数据集包含 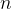
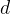
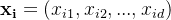
目标函数可以表示为:
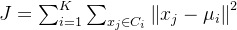
是第
个簇;
是属于簇
的第
个样本点;
-
是第
每个簇的中心
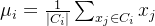
算法的目标就是最小化目标函数 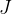
2. K-均值聚类算法的代码实现 ✨ ✨
下面是使用Python和sklearn库实现K-均值聚类算法的代码示例。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 生成模拟数据集
X, _ = make_blobs(n_samples=300, centers=4, random_state=42)
# 使用KMeans算法进行聚类
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(X)
# 获取聚类结果
y_kmeans = kmeans.predict(X)
# 绘制聚类结果
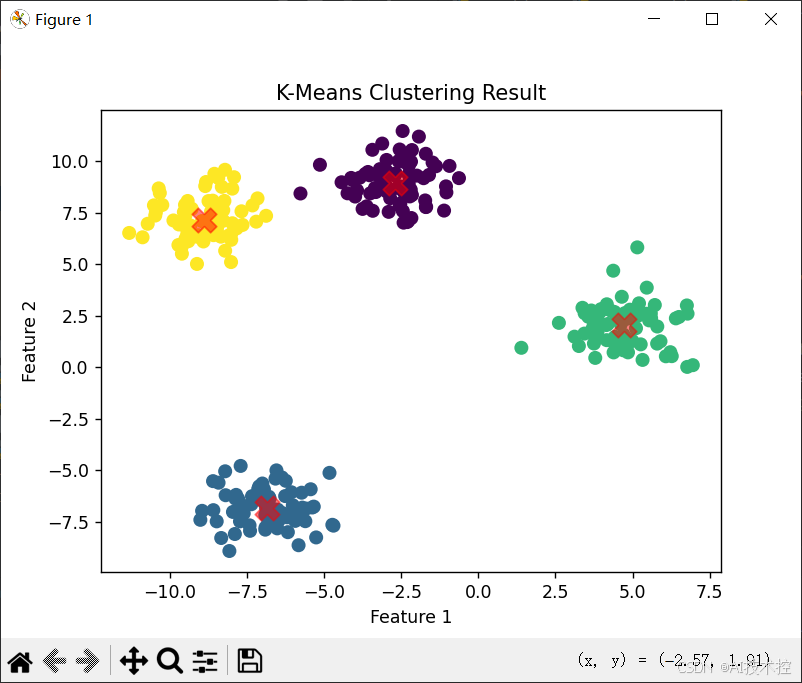
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
# 绘制簇中心
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.5, marker='X')
plt.title("K-Means Clustering Result")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
代码解释:
- 使用
make_blobs生成一个具有4个簇的模拟数据集。 - 使用
KMeans类初始化K-均值算法,设定聚类数为4,并拟合数据。 kmeans.predict(X)获取每个样本所属的簇。- 使用Matplotlib可视化聚类结果,并显示簇中心。
3. 数据集的介绍及下载地址 ✨ ✨
本示例中使用的是make_blobs生成的模拟数据集,通常用于测试聚类算法。它可以生成具有任意形状和数量的簇。对于实际的应用,您可以使用如下公开数据集进行K-均值聚类实验:
-
Iris数据集:Iris数据集包含150个花卉的样本,分为3个类别,每个类别有4个特征。适用于演示聚类算法。
- 数据集下载地址:Iris Dataset
-
Wine数据集:Wine数据集包含178个酒样本的13个特征,通常用于聚类和分类任务。
- 数据集下载地址:Wine Dataset
-
Digits数据集:Digits数据集包含1797个8x8像素的数字图像样本,常用于图像聚类任务。
- 数据集下载地址:Digits Dataset
4. K-均值聚类算法的应用场景 ✨ ✨
K-均值聚类算法作为一种经典的无监督学习方法,广泛应用于多个领域。其主要优势是实现简单、计算效率高,因此在大规模数据集上应用尤为广泛。下面是一些典型的应用场景:
4.1 市场细分与客户群体分析
K-均值聚类在市场营销领域的应用非常广泛。通过对客户的特征(如购买行为、兴趣爱好、人口统计特征等)进行聚类,可以将客户分成不同的群体。这些群体通常具有相似的需求和行为模式,可以帮助公司制定个性化的营销策略。
- 例如:
- 一家电商平台可以使用K-均值算法将客户分为多个群体,如高价值客户、潜力客户和低价值客户。
- 不同的客户群体可以接收到不同的广告或促销活动,提高营销效率和客户转化率。
实际案例:
- 亚马逊等电商平台会利用聚类分析来进行个性化推荐,根据客户的购买历史和浏览行为推送相关的商品或服务。
4.2 图像压缩与图像分割
在图像处理中,K-均值聚类算法也具有重要应用。它常用于图像压缩和图像分割中,主要通过将图像的颜色空间进行聚类,将相似颜色的像素点聚合在一起,从而减少图像的数据量。
-
图像压缩:通过对颜色进行量化,K-均值聚类算法可以将图像的颜色数目减少,进而压缩图像数据。
-
图像分割:K-均值聚类可用于将图像分割成多个区域(或对象)。图像的每个像素点可以根据其颜色、纹理等特征被分配到一个特定的簇中,从而实现图像的分割。
实际案例:
- 在卫星遥感图像中,K-均值聚类被用来分割不同类型的地物(如森林、城市、水体等),从而帮助分析地表覆盖变化。
4.3 文本聚类与信息检索
K-均值聚类还可以应用于文本挖掘,尤其是在信息检索和文档分类中。通过对文档的特征(如词频、TF-IDF等)进行聚类,可以将相似的文档归为一类,帮助提高搜索引擎的性能或自动分类文档。
-
文档分类:可以将新闻文章、博客帖子或技术文档等聚类成多个主题或类别。例如,将新闻文章按照政治、体育、娱乐等主题进行聚类。
-
信息检索:K-均值聚类可以用来将查询结果按照相关性或主题进行分组,从而改善信息检索的效果,使用户能够更快速地找到相关内容。
实际案例:
- Google、百度等搜索引擎会使用K-均值算法对搜索结果进行聚类,帮助用户更好地理解搜索内容。
4.4 异常检测
K-均值聚类也可以应用于异常检测。在数据集中,正常的数据点通常会聚集成一些簇,而异常点通常不属于任何簇或远离所有簇。通过对数据进行K-均值聚类,可以有效地识别出这些异常点。
- 例如:
- 在金融领域,可以使用K-均值算法检测信用卡交易中的欺诈行为。正常的交易会形成簇,而欺诈交易可能是与其他交易点距离较远的异常点。
- 在网络安全中,可以使用K-均值算法检测网络流量中的异常模式,如DDoS攻击等。
实际案例:
- 一些银行和金融机构使用K-均值聚类算法来检测信用卡欺诈,算法将正常交易和异常交易区分开来。
4.5 社交网络分析
社交网络分析中,K-均值聚类可以用于将社交网络中的用户分为不同的群体。每个群体可能代表具有相似兴趣、行为或社会关系的用户。例如,在Facebook、Twitter等社交平台中,K-均值聚类可以用来识别出不同的社交圈子,帮助平台推送个性化内容或广告。
-
社交圈识别:通过分析用户的互动行为(如好友关系、评论、分享等),可以将用户分成不同的群体。这些群体可能具有相似的兴趣或活动模式。
-
社区检测:通过聚类分析,识别社交网络中的潜在社区或群体,帮助理解网络中的信息传播模式或用户之间的关系。
实际案例:
- LinkedIn或Facebook等社交网络平台可以利用K-均值聚类分析用户的社交圈,以便推荐潜在的好友或群组。
4.6 医疗健康领域
K-均值聚类算法在医疗健康领域也有着广泛的应用。例如,通过对患者的病历数据、基因数据或健康监测数据进行聚类,可以发现患者之间的相似性,从而帮助医生为不同的患者制定个性化的治疗方案。
-
疾病分类:通过聚类算法对不同类型的疾病进行分类,例如,将不同类型的癌症患者根据基因表达的相似性进行分组,以便选择合适的治疗方案。
-
患者分组:基于患者的生活习惯、疾病史等信息,可以将患者分为高风险组和低风险组,从而有针对性地进行健康干预。
实际案例:
- 医院或诊所可以利用K-均值聚类算法根据患者的健康指标(如血糖、血压、体重等)将患者进行分类,从而制定个性化的治疗方案。
4.7 推荐系统
K-均值聚类在推荐系统中的应用通常用于将用户或物品分为若干个簇,然后在相同簇内进行推荐。例如,电商平台可以将商品分成若干个簇,根据用户的历史购买记录向其推荐最符合其兴趣的商品。
-
基于用户的推荐:将具有相似兴趣和行为的用户聚为一组,然后向这些用户推荐其他用户喜欢的物品。
-
基于物品的推荐:将相似的商品聚为一组,并向用户推荐该簇中的其他商品。
实际案例:
- Netflix、Spotify等流媒体平台会根据用户的观看或收听历史,将用户分为不同的群体,从而推荐用户可能喜欢的电影、电视剧或音乐。
K-均值聚类算法因其简单、易于实现、计算效率高,在多个领域中都有着广泛的应用。无论是在市场营销、图像处理、文本挖掘、社交网络分析,还是在医疗健康、金融安全等领域,K-均值聚类都能提供有效的数据分组和模式识别。尽管K-均值聚类算法存在一些局限性(如对初始聚类中心敏感、对非球形簇效果差等),但通过算法的变种和优化,依然能在许多实际应用中取得良好的效果。
5. 相关的优秀论文及其下载地址 ✨ ✨
以下是一些与K-均值聚类算法相关的经典论文,您可以进一步了解该算法的理论和应用。
-
"A K-Means Clustering Algorithm"
该论文介绍了K-均值算法的基本原理和优化方法。
论文链接:A K-Means Clustering Algorithm
-
"On the Convergence of the K-Means Algorithm"
这篇论文分析了K-均值算法的收敛性问题,提出了算法的一些理论保证。
论文链接:On the Convergence of the K-Means Algorithm
-
"Clustering by K-Means and Its Variants"
该文讨论了K-均值算法的一些变种和扩展,提供了对算法的更深入理解。
论文链接:Clustering by K-Means and Its Variants
6. 总结✨ ✨
K-均值聚类算法是一个强大且高效的无监督学习算法,广泛应用于数据挖掘、机器学习等领域。其核心思想是通过最小化簇内点与簇中心的距离来进行数据的划分。尽管K-均值具有较好的性能,但也存在一些局限性,如对初始聚类中心的敏感性以及处理非凸形状簇的困难。通过对算法的优化和变种,可以在许多复杂的场景中取得更好的聚类效果。
K-均值聚类不仅是机器学习中的一个基础算法,也是许多领域中的实际应用工具。通过深入学习其原理、实现以及优化方法,可以帮助我们在数据分析中发挥更大的价值。