Centos7环境下Hive的安装
- 前言
- 一、安装Hive
- 1.1 下载并解压
- 1.2 配置环境变量
- 1.3 修改配置
- 1. hive-env.sh
- 2. hive-site.xml
- 1.4 拷贝数据库驱动
- 1.5 初始化元数据库
- 报错
- 1.6 安装MySQL
- 1.7 启动
- 二、HiveServer2/beeline
- 2.1 修改Hadoop配置
- 2.2 修改Hive配置
- 2.2 启动hiveserver2
- 2.3 使用beeline
- 参考文章
前言
对于hive的安装和使用,需要先完成如下配置:
- Hadoop集群(Hadoop搭建集群)
- 安装HBase数据库(HBase数据库搭建)
一、安装Hive
1.1 下载并解压
下载所需版本的 Hive,这里我下载版本为 apache-hive-3.1.2-bin.tar.gz
下载地址:https://archive.apache.org/dist/hive/hive-3.1.2/
# 使用wget命令下载
wget https://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
下载后进行解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/hive-3.1.2
1.2 配置环境变量
# 这里修改自己的环境变量文件
vim /etc/profile.d/my_env.sh
添加环境变量:
#HIVE_HOME
export HIVE_HOME=/opt/module/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
让环境变量生效:
source /etc/profile.d/my_env.sh

1.3 修改配置
1. hive-env.sh
进入安装目录下的 conf/ 目录,拷贝 Hive 的环境配置模板 flume-env.sh.template
cd /opt/module/hive-3.1.2/conf/
cp hive-env.sh.template hive-env.sh
修改 hive-env.sh,指定 Hadoop 的安装路径:
HADOOP_HOME=/opt/module/hadoop-3.1.3

2. hive-site.xml
新建 hive-site.xml 文件,内容如下,主要是配置存放元数据的 MySQL 的地址、驱动、用户名和密码等信息:
vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop101:3306/hadoop_hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>111111</value>
</property>
</configuration>
1.4 拷贝数据库驱动
将 MySQL 驱动包拷贝到 Hive 安装目录的 lib 目录下, MySQL 驱动的下载地址为:https://dev.mysql.com/downloads/connector/j/
解压后上传jar包到服务器
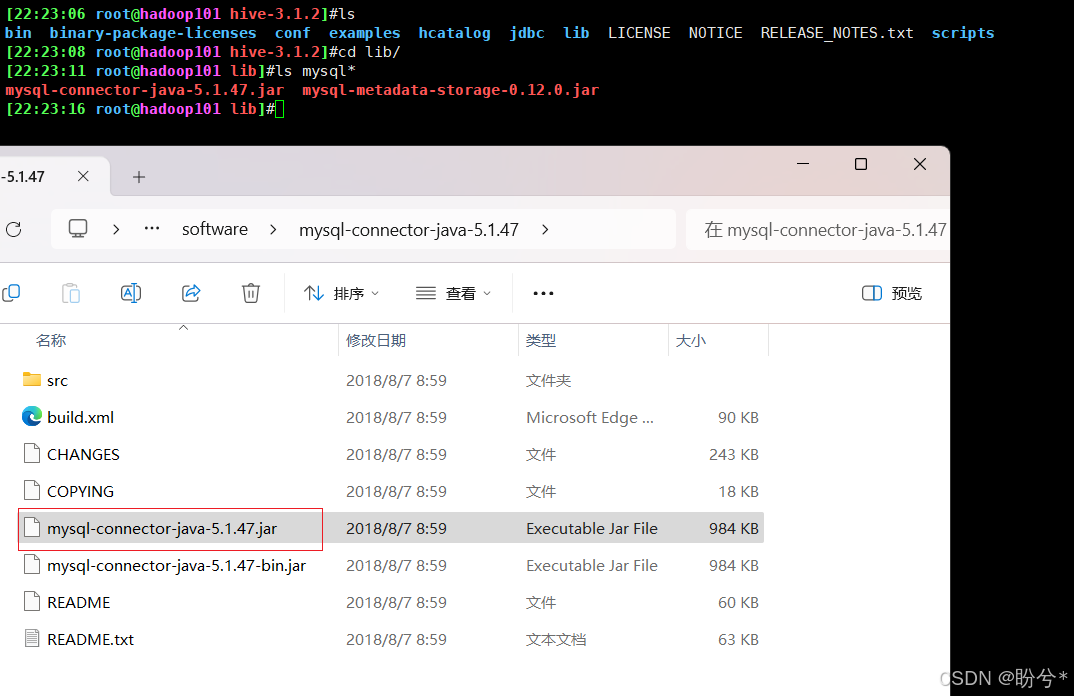
1.5 初始化元数据库
-
当使用的 hive 是 1.x 版本时,可以不进行初始化操作,Hive
会在第一次启动的时候会自动进行初始化,但不会生成所有的元数据信息表,只会初始化必要的一部分,在之后的使用中用到其余表时会自动创建; -
当使用的 hive 是 2.x及以上版本时,必须手动初始化元数据库。初始化命令:
# schematool 命令在安装目录的 bin 目录下,由于上面已经配置过环境变量,在任意位置执行即可
schematool -dbType mysql -initSchema
这里我使用的是hive-3.1.2-bin.tar.gz,需要手动初始化元数据库。
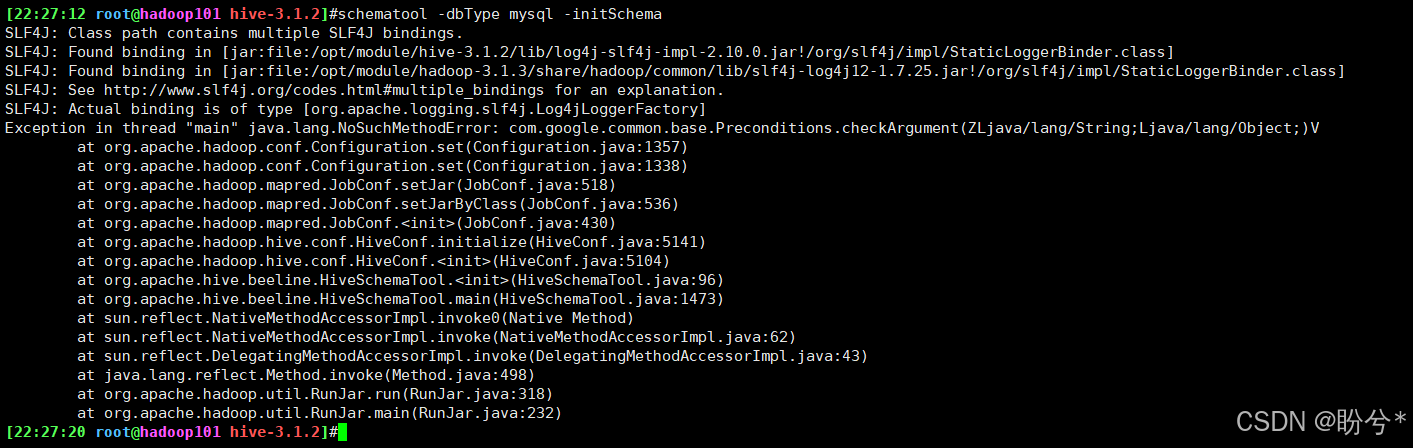
报错
这里执行后会出现如下报错:
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
原因是hadoop和hive的两个guava.jar版本不一致,两个jar位置分别位于下面两个目录:
find -name guava*
解决办法是删除低版本的那个,将高版本的复制到低版本目录下

cd /opt/module/hive-3.1.2/lib/
rm -rf guava-19.0.jar
cp /opt/module/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar .
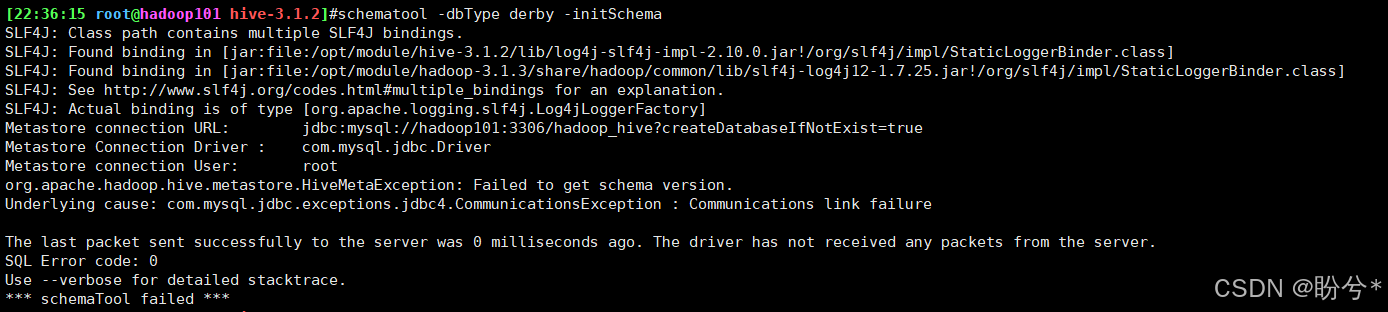
hive默认是derby数据库,但是前面已经配置了mysql,如果没有安装mysql的话会报如下错误:
可以先把前面配置的hive-site.xml文件删掉,再执行schematool -dbType derby -initSchema命令(后面改用mysql数据库时记得重新创建),即可成功初始化元数据库。
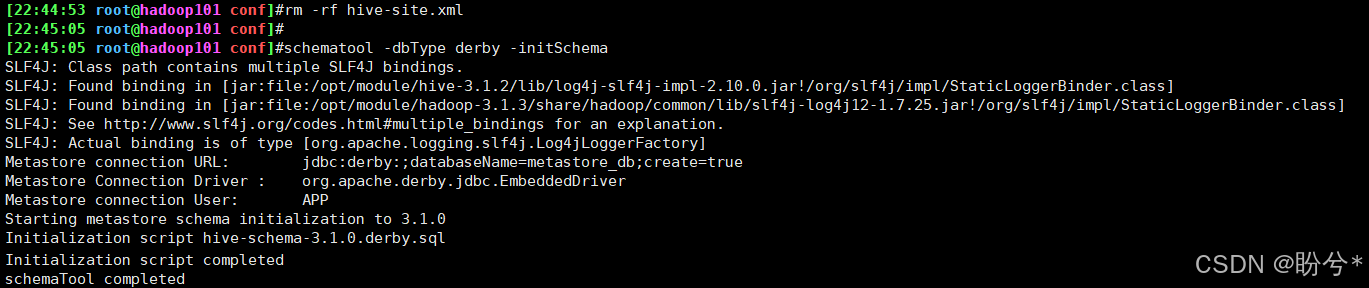
1.6 安装MySQL
由于之前已经写过安装mysql的文章,这里就不在赘述,直接放连接云服务器上配置Mysql
连接:https://blog.csdn.net/m0_70405779/article/details/140735557
安装好mysql后可以执行如下命令初始化元数据库
schematool -dbType mysql -initSchema
可以进到mysql中查看,已经创建了前面xml文件中设置的hadoop_hive数据库

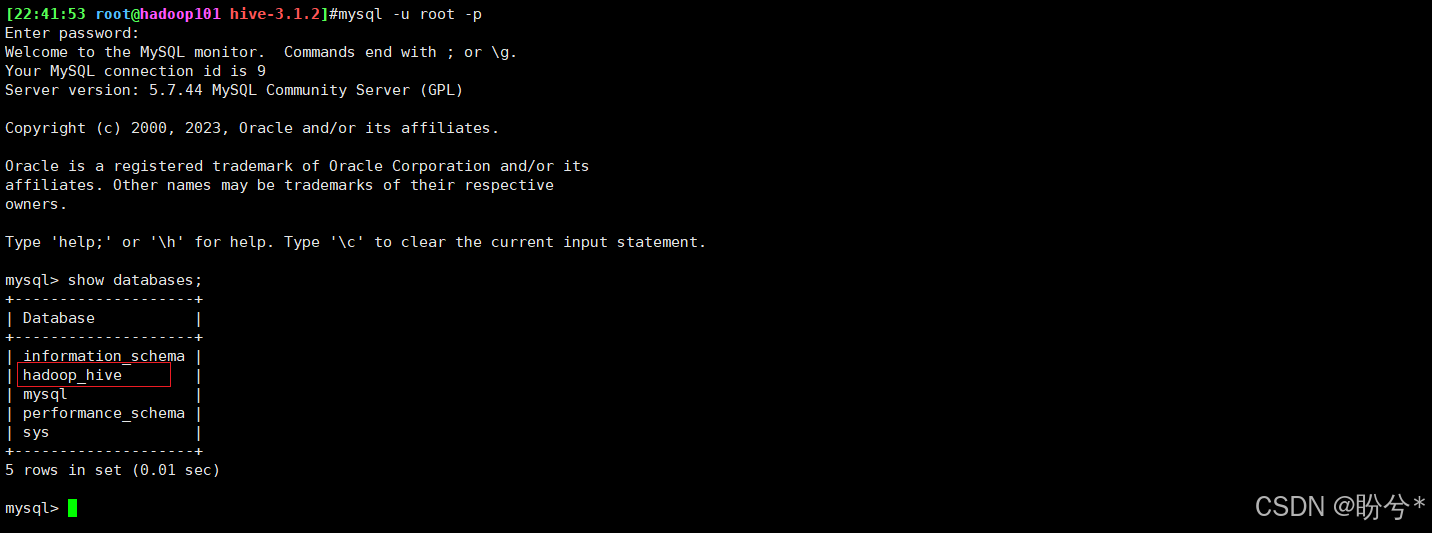
1.7 启动
启动hive之前先确保hadoop集群是否启动,没有就启动一下
# 配置了hadoop环境路径的话可以直接执行
start-all.sh
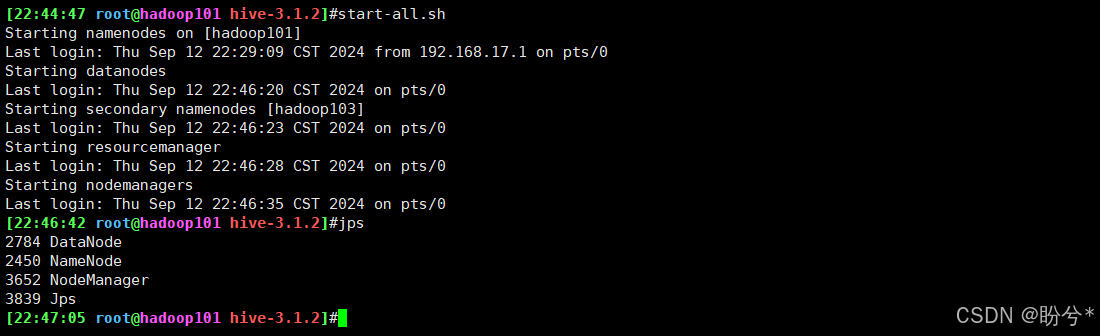
由于已经将 Hive 的 bin 目录配置到环境变量,直接使用以下命令启动,成功进入交互式命令行后执行 show databases 命令,无异常则代表搭建成功。
hive
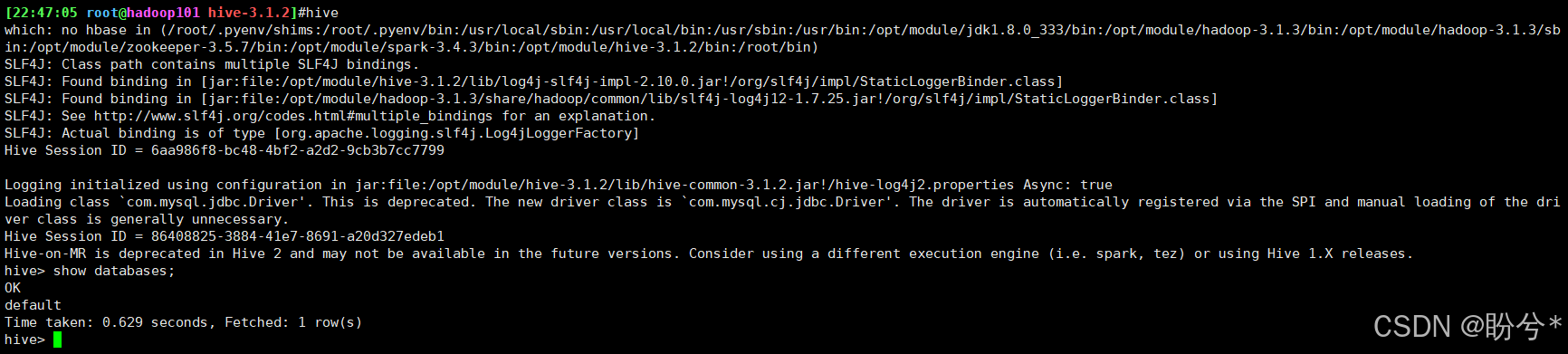
使用hive
hive> show databases;
hive> show tables;
hive> create table stu(id int, name string);
hive> insert into stu values(1,"chen");
hive> select * from stu;
问题记录
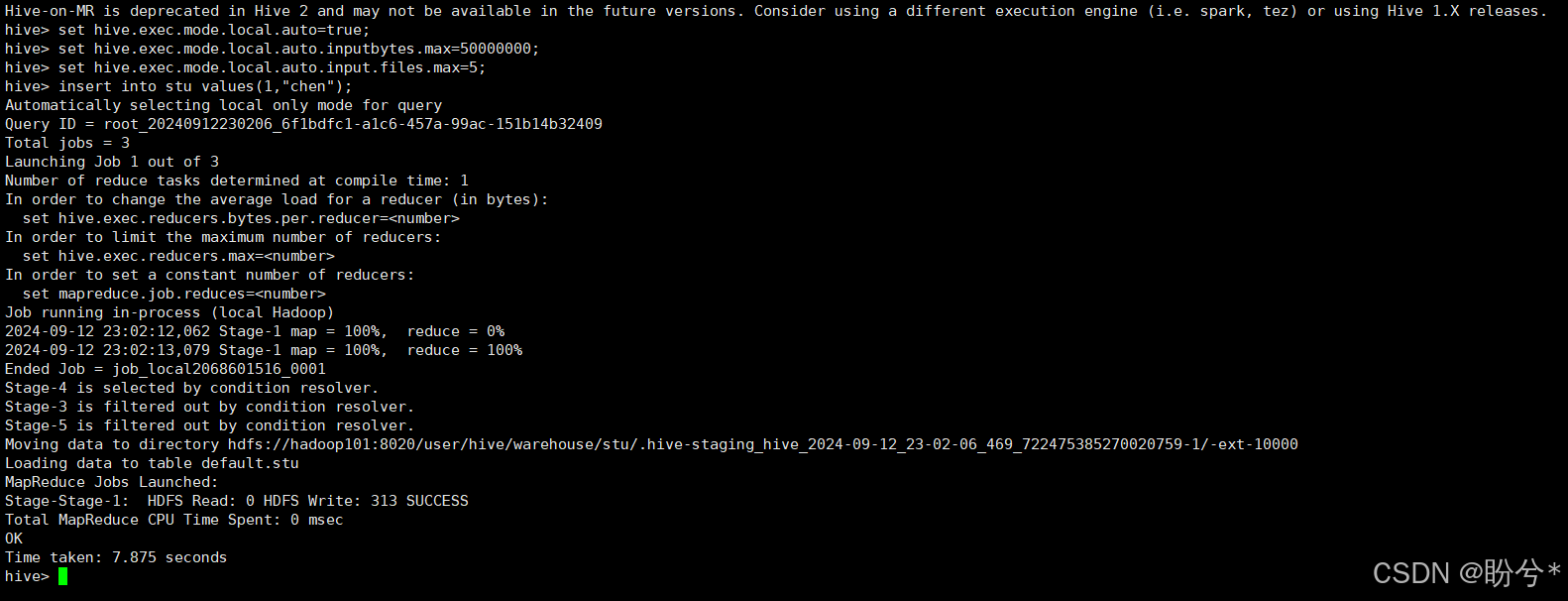
这里再hive中执行insert语句时可能会卡住
可以先退出来,重新进入hive,执行如下命令
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.inputbytes.max=50000000;
set hive.exec.mode.local.auto.input.files.max=5;
然后再次执行插入语句

二、HiveServer2/beeline
Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,因此产生了 HiveServer2。HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务。
HiveServer2 拥有自己的 CLI 工具——Beeline。Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于目前 HiveServer2 是 Hive 开发维护的重点,所以官方更加推荐使用 Beeline 而不是 Hive CLI。以下主要讲解 Beeline 的配置方式。
2.1 修改Hadoop配置
修改 hadoop 集群的 core-site.xml 配置文件,增加如下配置,指定 hadoop 的 root 用户可以代理本机上所有的用户。
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
之所以要配置这一步,是因为 hadoop 2.0 以后引入了安全伪装机制,使得 hadoop 不允许上层系统(如 hive)直接将实际用户传递到 hadoop 层,而应该将实际用户传递给一个超级代理,由该代理在 hadoop 上执行操作,以避免任意客户端随意操作 hadoop。如果不配置这一步,在之后的连接中可能会抛出 AuthorizationException 异常。
关于 Hadoop 的用户代理机制,可以参考:hadoop 的用户代理机制 或 Superusers Acting On Behalf Of Other Users
2.2 修改Hive配置
在hive-site.xml文件中添加如下配置信息:
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop001</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
2.2 启动hiveserver2
由于上面已经配置过环境变量,这里直接启动即可:
hive --service hiveserver2
# 或者
# nohup hiveserver2 &
2.3 使用beeline
可以使用以下命令进入 beeline 交互式命令行,出现 Connected 则代表连接成功。
bin/beeline -u jdbc:hive2://hadoop101:10000 -n root