实验目的:
1. 学习数据预处理和特征工程方法。
2. 掌握逻辑回归算法的基本原理和实现。
3. 理解模型训练、验证和测试的过程。
4. 使用不同的评价指标对模型进行评估。
5. 通过数据可视化展示模型效果。
实验步骤与要求:
1. 数据集预处理与特征工程
数据集导入:选择一个适合分类任务的数据集(如Iris数据集、客户购买预测数据等)。
数据预处理:处理缺失值、去除异常值等,确保数据质量。
特征工程:对数据进行特征选择、特征变换(如独热编码、特征缩放等)。
2. 逻辑回归算法实现
算法原理:简要说明逻辑回归算法的原理,包括Sigmoid函数、损失函数(对数损失)以及梯度下降优化过程。
实现过程:使用编程语言(如Python)实现逻辑回归算法,可以使用现有库如scikit-learn。
模型训练:将数据集分为训练集和测试集,使用训练集训练模型。
3. 模型结果分析
结果展示:展示逻辑回归模型的预测结果,包括混淆矩阵、精确率、召回率、F1-score等指标。
评价指标:使用评价指标对模型进行评估,如ROC曲线、AUC值等。
特征重要性:分析各个特征对模型预测结果的重要性。
4. 数据可视化
特征分布可视化:使用直方图、盒线图等方法展示各个特征的分布情况。
模型效果展示:使用不同颜色或形状表示不同的分类结果,直观展示模型效果。
决策边界可视化:在二维或三维空间中可视化逻辑回归模型的决策边界。
5. 实验总结
结果分析:总结实验结果,分析逻辑回归算法的优缺点以及适用场景。
模型改进:探讨可能的模型改进方法,如使用正则化技术防止过拟合。
一.实验目的
【实际应用举例】
- 库存管理: 通过识别和分类鸢尾花品种,可以更好地管理库存,确保有足够的每种品种以满足客户需求。
- 市场定位: 对不同品种的鸢尾花进行准确的分类可以帮助你在市场上做出更有针对性的宣传和定位,吸引对特定品种感兴趣的顾客。
- 产品推荐: 基于鸢尾花品种的分类结果,可以向顾客推荐适合他们需求和偏好的花卉产品,提升销售效率和客户满意度。
- 品种识别: 对于新到货的鸢尾花,通过机器学习模型的预测,你可以快速准确地识别其品种,减少人工识别的时间和错误。
应用上述代码示例的过程:
数据收集与预处理: 收集一批鸢尾花的测量数据,包括花萼和花瓣的尺寸。这些数据被整理成一个数据集,每个样本都标记有其对应的鸢尾花品种。
数据分析与模型训练: 使用上述代码示例,通过Python编程,加载数据集并进行数据分析和可视化。训练了一个逻辑回归模型来学习如何根据花萼和花瓣的尺寸来分类不同的鸢尾花品种。
模型评估与应用: 训练完成后,对模型进行了评估,检查其在测试集上的准确度和分类性能。如果模型表现良好,可以将其应用于实际场景中,例如对新到货的鸢尾花进行自动分类和识别。
二.实验步骤
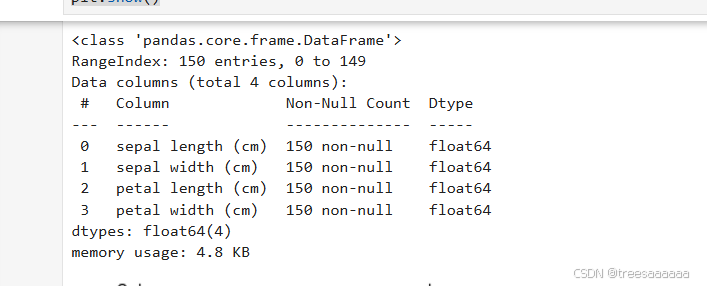
1.数据加载和基本信息:
使用 load_iris() 函数加载鸢尾花数据集,并打印数据集的基本信息,包括特征数、样本数和类别名称。
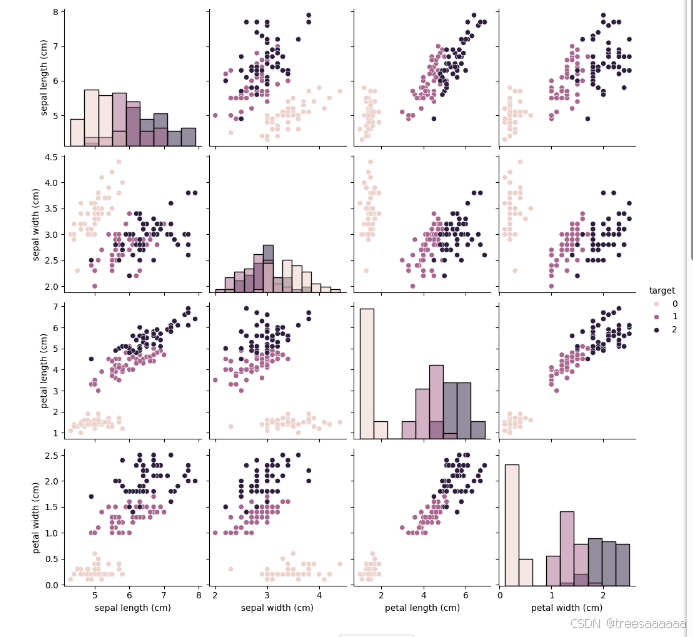
2.特征关系可视化:
使用 seaborn 的 pairplot 函数可视化数据集中各特征之间的关系,不同类别用不同的标记表示。
3.数据集划分:
使用 train_test_split 函数将数据集划分为训练集和测试集,这里测试集占总样本的20%。
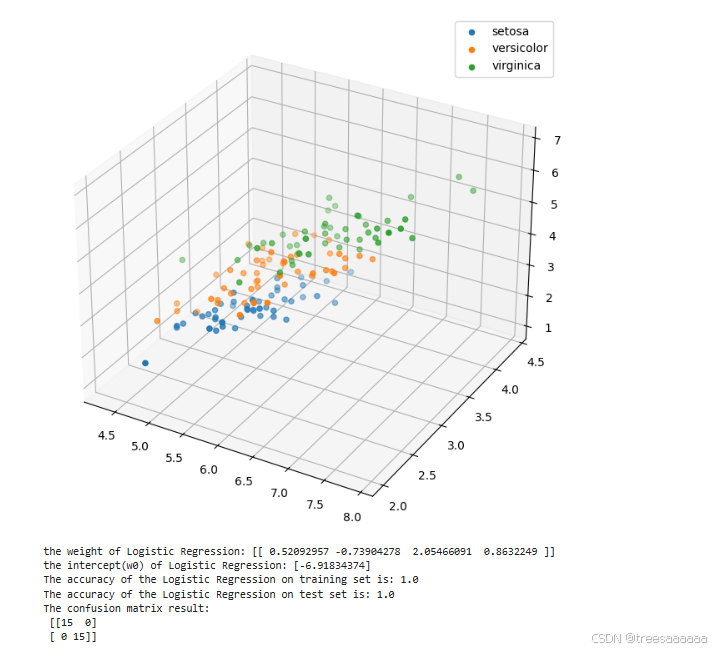
4.模型训练与预测:
初始化并训练一个逻辑回归模型 (LogisticRegression),使用训练集进行拟合,然后对测试集进行预测。
5.准确度评估:
使用 accuracy_score 函数计算模型在测试集上的准确度,并打印结果。
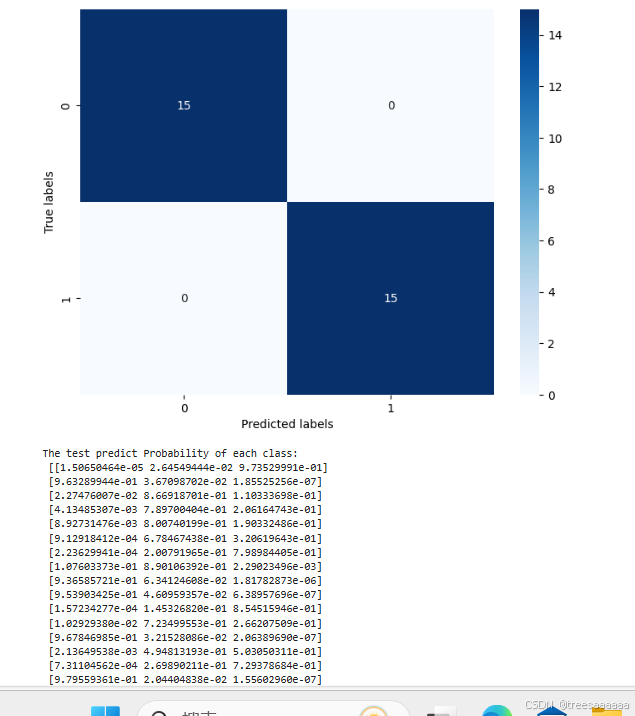
6.混淆矩阵可视化:
使用 confusion_matrix 函数计算预测结果的混淆矩阵,并通过 seaborn 的 heatmap 函数进行可视化。
7.多分类问题评估:
使用完整的数据集再次训练模型,并评估其在整个数据集上的准确度。
三.实验结果分析
- 结果展示
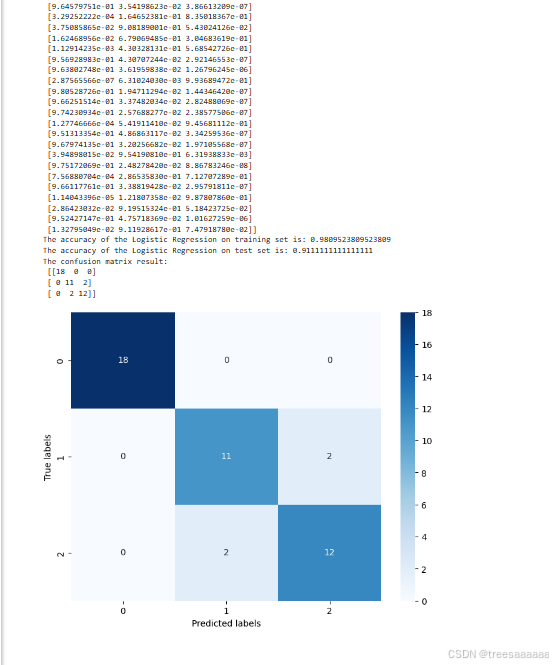
- 结果分析
数据处理和可视化:
代码首先导入并展示了鸢尾花数据集的基本信息,包括特征的统计描述和类别分布情况。
使用seaborn库进行了特征对之间的关系可视化,通过pairplot和3D散点图展示了不同类别(setosa、versicolor、virginica)在特征空间的分布情况。
数据预处理和模型训练:
使用了逻辑回归模型(Logistic Regression),将数据集划分为训练集和测试集。
分别对部分数据集(只包含类别0和1)和完整数据集进行了训练和预测,评估了模型在训练集和测试集上的准确度(accuracy)。
模型评估:
通过混淆矩阵(confusion matrix)详细分析了模型在测试集上的分类效果,使用heatmap进行了可视化展示。
多分类问题:
在完整数据集上进一步测试了多分类问题的表现,同样使用了逻辑回归模型,并评估了其在训练集和测试集上的表现。
遇到的问题和改进建议
参数选择:
在实际应用中,可以尝试不同的模型参数(如solver的选择、正则化项等)来优化模型的性能。
也可以尝试其他机器学习模型(如支持向量机、决策树、随机森林等)来比较不同模型的表现。
特征工程:
鸢尾花数据集相对简单且已经经过良好的特征工程处理。在处理更复杂的数据集时,可能需要进行特征缩放、特征选择或特征构建等预处理步骤。
结果应用:
该模型可以应用于实际生产环境中,例如根据花瓣和花萼的测量数据来自动识别鸢尾花的品种。
四.源代码
# 导入函数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 导入数据
from sklearn.datasets import load_iris
data = load_iris()
iris_target = data.target
iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) # 利用 Pandas 转化为 DataFrame 格式
# 查看数据的整体信息
iris_features.info()
# 查看每个类别数量
pd.Series(iris_target).value_counts()
# 对于特征进行一些统计描述
iris_features.describe()
# 合并标签和特征信息
iris_all = iris_features.copy() # 进行浅拷贝,防止对于原始数据的修改
iris_all['target'] = iris_target
# 可视化
sns.pairplot(data=iris_all, diag_kind='hist', hue='target')
plt.show()
# 3D 可视化
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
iris_all_class0 = iris_all[iris_all['target'] == 0].values
iris_all_class1 = iris_all[iris_all['target'] == 1].values
iris_all_class2 = iris_all[iris_all['target'] == 2].values
# 'setosa'(0), 'versicolor'(1), 'virginica'(2)
ax.scatter(iris_all_class0[:, 0], iris_all_class0[:, 1], iris_all_class0[:, 2], label='setosa')
ax.scatter(iris_all_class1[:, 0], iris_all_class1[:, 1], iris_all_class1[:, 2], label='versicolor')
ax.scatter(iris_all_class2[:, 0], iris_all_class2[:, 1], iris_all_class2[:, 2], label='virginica')
plt.legend()
plt.show()
# 划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 选择其类别为 0 和 1 的样本(不包括类别为 2 的样本)
iris_features_part = iris_features.iloc[:100]
iris_target_part = iris_target[:100]
# 训练集测试集 7/3 分
x_train, x_test, y_train, y_test = train_test_split(iris_features_part, iris_target_part, test_size=0.3, random_state=2020)
# 从 sklearn 中导入逻辑回归模型
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(random_state=0, solver='lbfgs')
# 训练模型
clf.fit(x_train, y_train)
# 查看其对应的 w
print('the weight of Logistic Regression:', clf.coef_)
# 查看其对应的 w0
print('the intercept(w0) of Logistic Regression:', clf.intercept_)
# 预测模型
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics
# 利用 accuracy(准确度)评估模型效果
print('The accuracy of the Logistic Regression on training set is:', metrics.accuracy_score(y_train, train_predict))
print('The accuracy of the Logistic Regression on test set is:', metrics.accuracy_score(y_test, test_predict))
# 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict, y_test)
print('The confusion matrix result:\n', confusion_matrix_result)
# 可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
# 多分类预测
# 训练集测试集还是 7/3 分
x_train, x_test, y_train, y_test = train_test_split(iris_features, iris_target, test_size=0.3, random_state=2020)
# 建模
clf = LogisticRegression(random_state=0, solver='lbfgs')
# 训练模型
clf.fit(x_train, y_train)
# 预测模型
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
# 预测模型概率
train_predict_proba = clf.predict_proba(x_train)
test_predict_proba = clf.predict_proba(x_test)
print('The test predict Probability of each class:\n', test_predict_proba)
# 利用 accuracy 评估模型效果
print('The accuracy of the Logistic Regression on training set is:', metrics.accuracy_score(y_train, train_predict))
print('The accuracy of the Logistic Regression on test set is:', metrics.accuracy_score(y_test, test_predict))
# 查看混淆矩阵
confusion_matrix_result = metrics.confusion_matrix(test_predict, y_test)
print('The confusion matrix result:\n', confusion_matrix_result)
# 可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()