import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
import seaborn as sns
plt. rcParams[ "font.family" ] = "SimHei"
plt. rcParams[ "axes.unicode_minus" ] = False
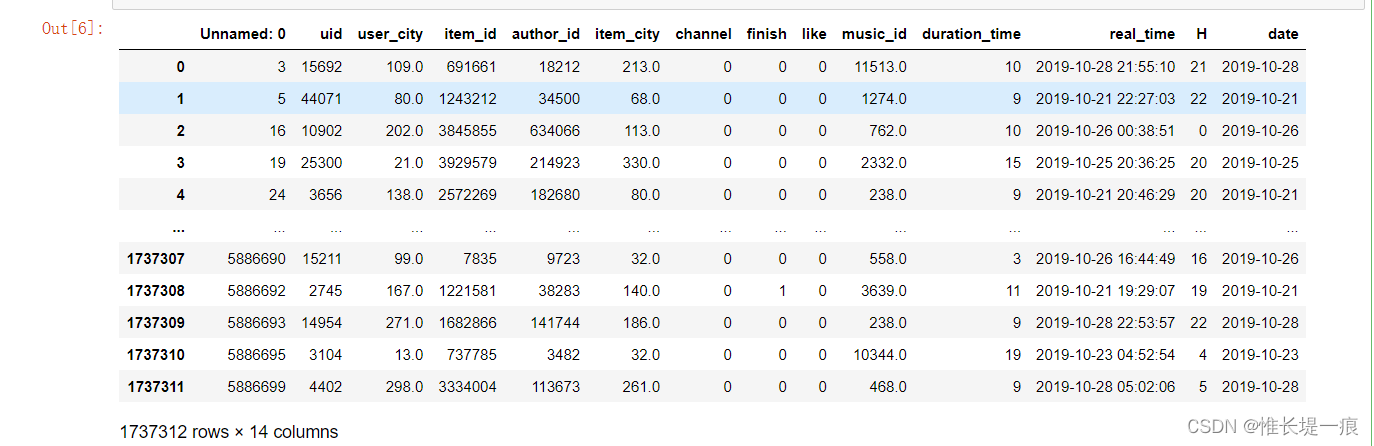
data= pd. read_csv( './data/douyin_dataset.csv' )
data
字段含义
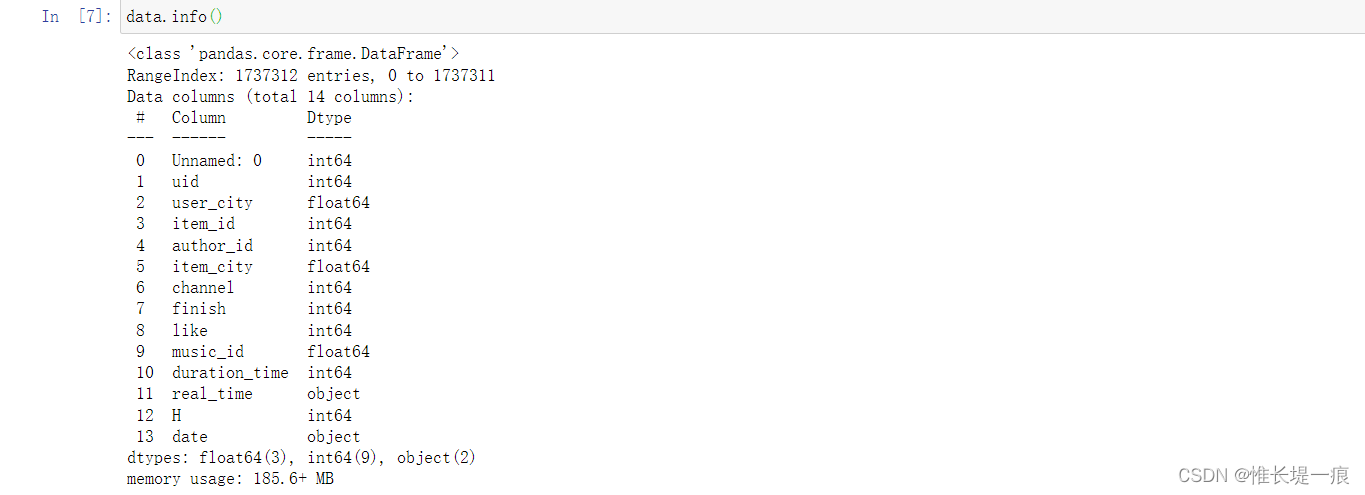
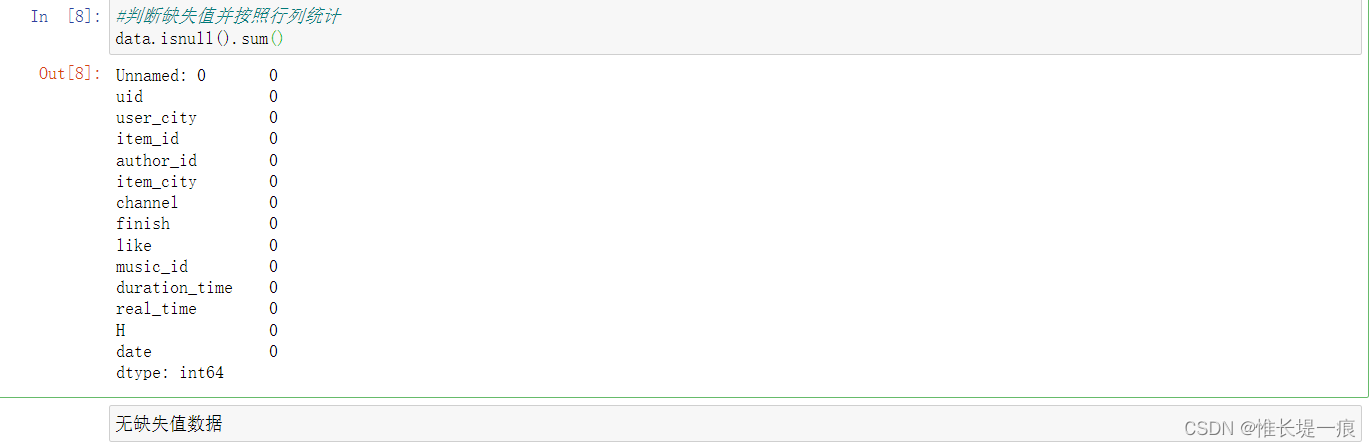
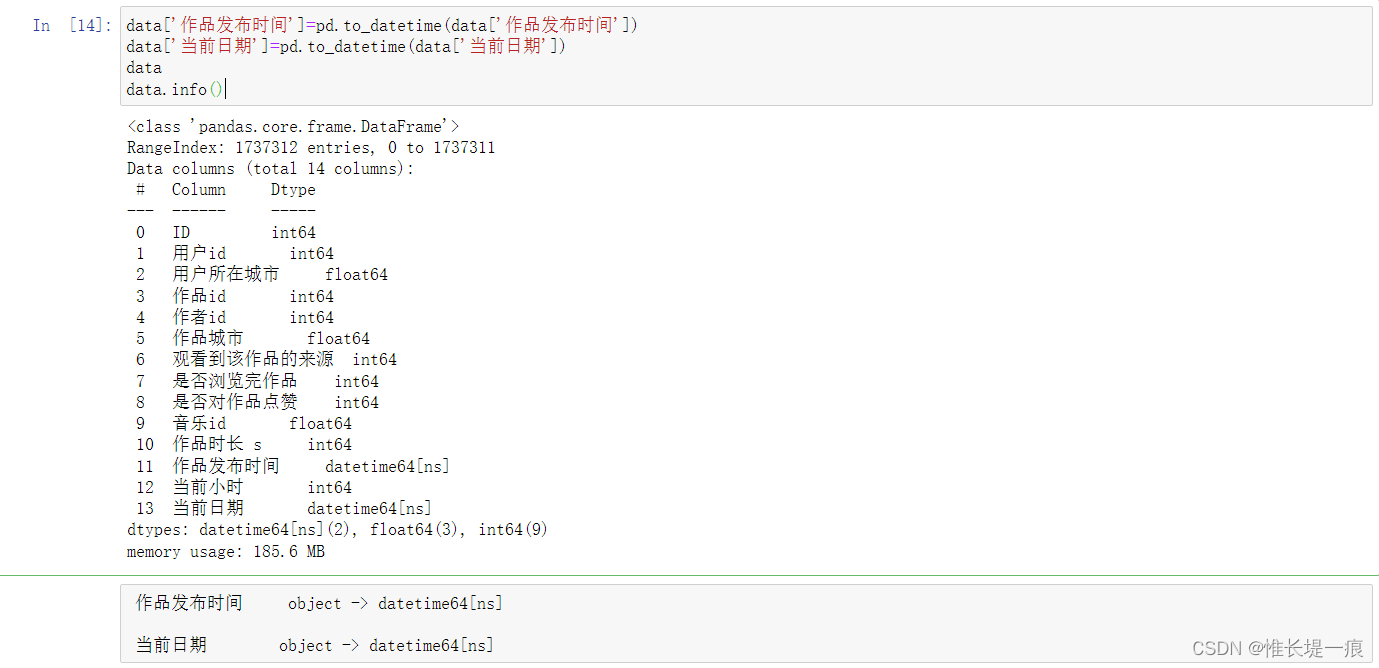
第一列是未定义的字段, 是顺序的, 但是不连续, 可能是过处理以后的数据集 uid:用户id user_city:用户所在城市 item_id:作品id author_id:作者id item_city:作品城市 channel:观看到该作品的来源 finish:是否浏览完作品 like:是否对作品点赞 music_id:音乐id duration_time:作品时长 (秒) real_time:作品发布时间 H:当前小时 date:当前日期 data. info( )
data. isnull( ) . sum ( )
data. duplicated( ) . sum ( )
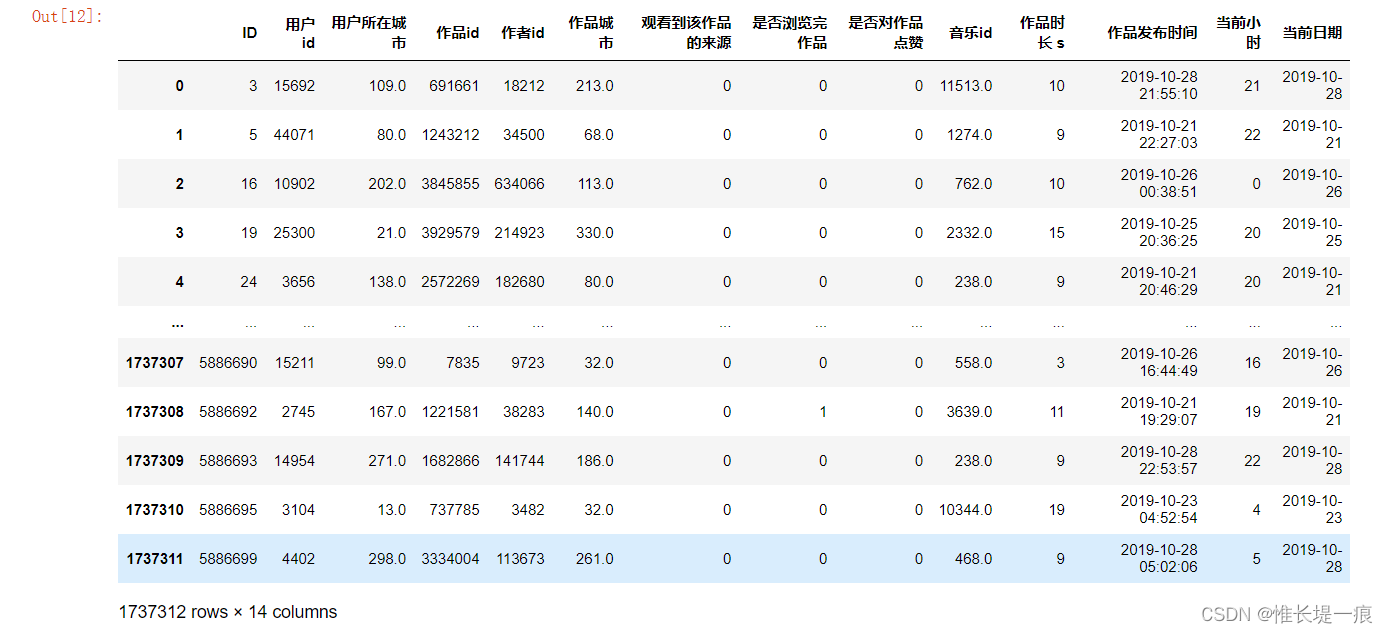
colNameDict = {
'Unnamed: 0' : 'ID' ,
'uid' : '用户id' ,
'user_city' : '用户所在城市' ,
'item_id' : '作品id' ,
'author_id' : '作者id' ,
'item_city' : '作品城市' ,
'channel' : '观看到该作品的来源' ,
'finish' : '是否浏览完作品' ,
'like' : '是否对作品点赞' ,
'music_id' : '音乐id' ,
'duration_time' : '作品时长 s' ,
'real_time' : '作品发布时间' ,
'H' : '当前小时' ,
'date' : '当前日期'
}
data = data. rename( columns= colNameDict)
data
data[ '作品发布时间' ] = pd. to_datetime( data[ '作品发布时间' ] )
data[ '当前日期' ] = pd. to_datetime( data[ '当前日期' ] )
data
data. info( )
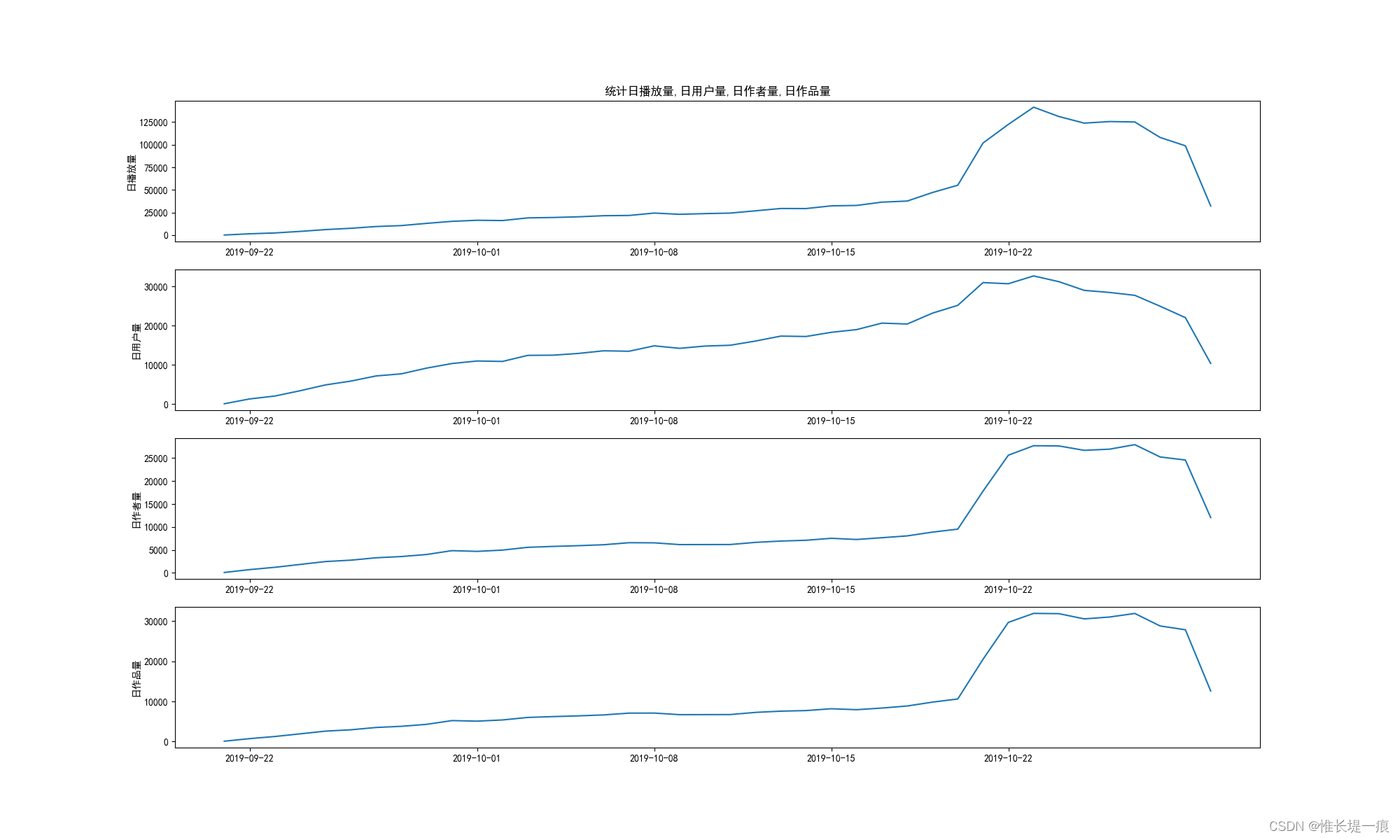
df_group= data. groupby( by= '当前日期' )
"""日播放量"""
df_id= df_group[ 'ID' ] . count( )
df_id
"""日用户量"""
df_uid= df_group[ '用户id' ] . nunique( )
df_uid
"""日作者量"""
df_author= df_group[ '作者id' ] . nunique( )
df_author
"""日作品量"""
df_item= df_group[ '作品id' ] . nunique( )
df_item
plt. figure( figsize= ( 20 , 12 ) , dpi= 100 )
x= df_id. index
ax1= plt. subplot( 411 )
plt. plot( x, df_id. values)
plt. ylabel( '日播放量' )
plt. title( '统计日播放量,日用户量,日作者量,日作品量' )
plt. subplot( 412 , sharex= ax1)
plt. plot( x, df_uid. values)
plt. ylabel( '日用户量' )
plt. subplot( 413 , sharex= ax1)
plt. plot( x, df_author. values)
plt. ylabel( '日作者量' )
plt. subplot( 414 , sharex= ax1)
plt. plot( x, df_item. values)
plt. ylabel( '日作品量' )
plt. savefig( './data/抖音日数据统计图2.png' )
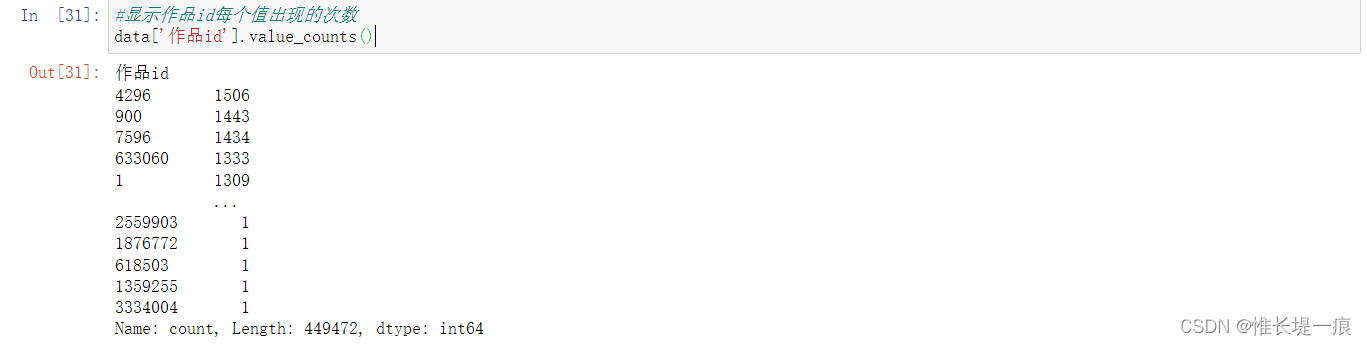
data[ '作品id' ] . value_counts( )
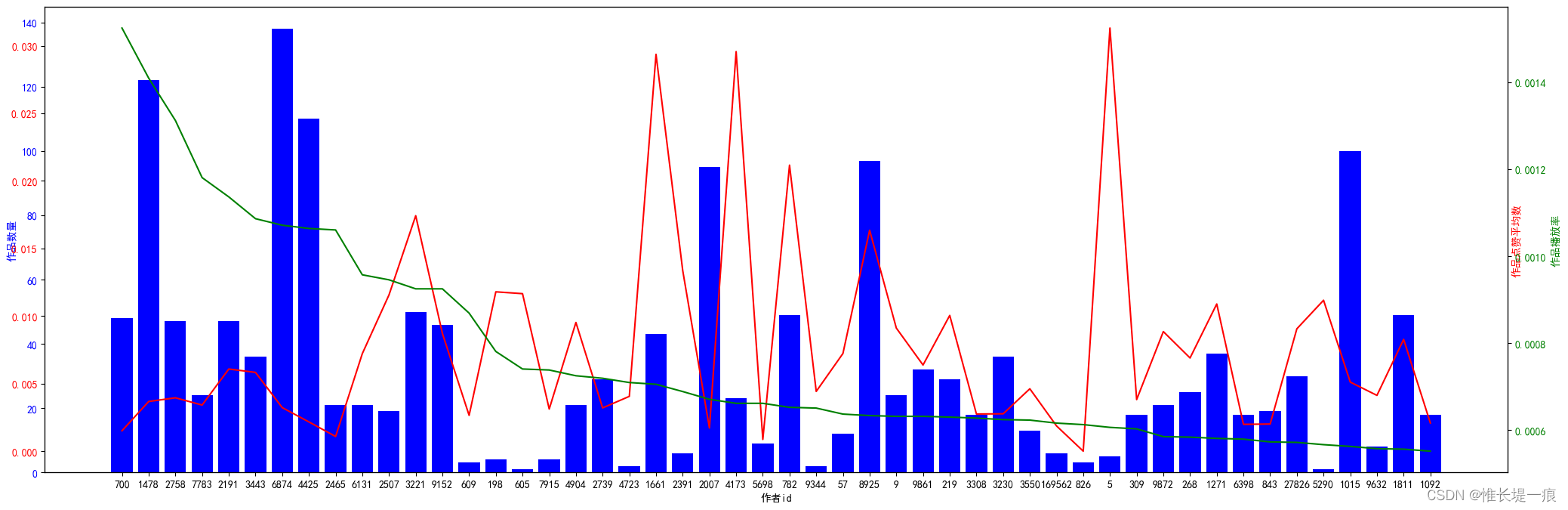
author_50 = data[ '作者id' ] . value_counts( ) . iloc[ : 50 ]
author_50
cols_outhor = author_50. index
cols_outhor
item_count = data. groupby( '作者id' ) [ '作品id' ] . nunique( ) [ cols_outhor]
item_count
authou_star_mean = data. groupby( '作者id' ) [ '是否对作品点赞' ] . mean( ) [ cols_outhor]
authou_star_mean
author_player = data[ '作者id' ] . value_counts( ) . sort_values( ascending= False ) [ cols_outhor] / len ( data[ 'ID' ] )
author_player
"""绘图"""
x = [ str ( i) for i in list ( author_50. index) ]
fig, ax1 = plt. subplots( figsize= ( 18 , 8 ) )
color = 'blue'
ax1. bar( x, item_count. values, color= color)
ax1. set_xlabel( '作者id' )
ax1. set_ylabel( '作品数量' , color= color)
ax1. tick_params( axis= 'y' , labelcolor= color)
ax2 = ax1. twinx( )
color = 'red'
ax2. plot( x, authou_star_mean. values, color= color)
ax2. set_ylabel( '作品点赞平均数' , color= color)
ax2. tick_params( axis= 'y' , labelcolor= color)
ax3 = ax2. twinx( )
color = 'green'
ax3. plot( x, author_player. values, color= color)
ax3. set_ylabel( '作品播放率' , color= color)
ax3. tick_params( axis= 'y' , labelcolor= color)
"""作品来源统计"""
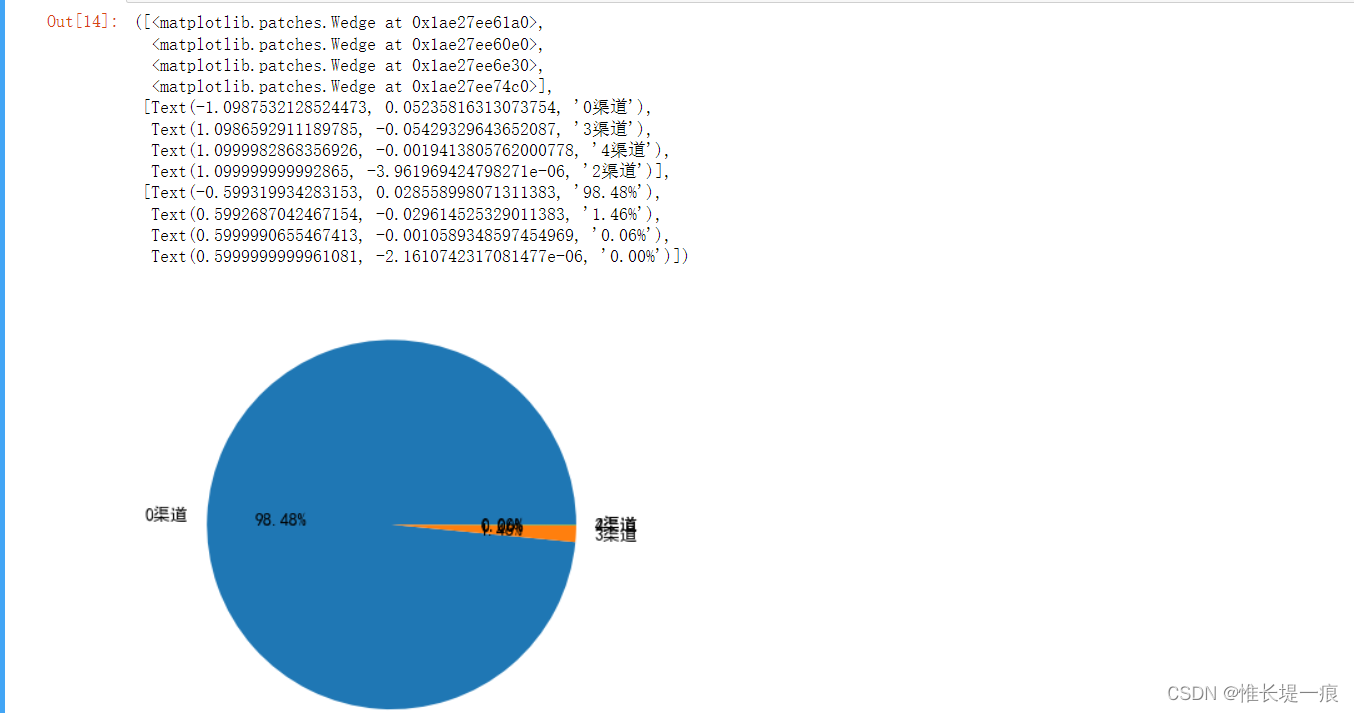
channel = data[ '观看到该作品的来源' ] . value_counts( )
channel
plt. pie(
x= channel. values,
labels= [ f' { char} 渠道' for char in channel. index] ,
autopct= '%.2f%%'
)
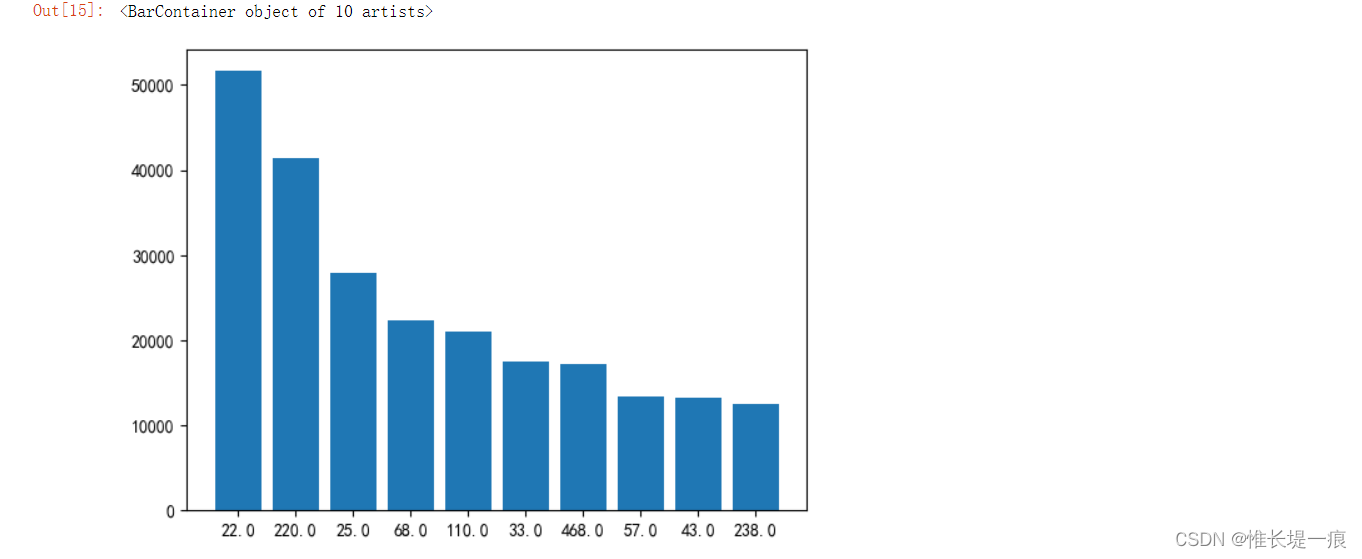
music_10 = data[ '音乐id' ] . value_counts( ) . head( 10 )
music_10
x = [ str ( char) for char in music_10. index]
plt. bar( x, music_10. values)
str ( music_10. index)
music_10. values
data_time = data. groupby( '作品时长 s' ) [ '用户id' ] . count( )
data_time_item = data. groupby( '作品时长 s' ) [ '作品id' ] . nunique( )
data_time_item
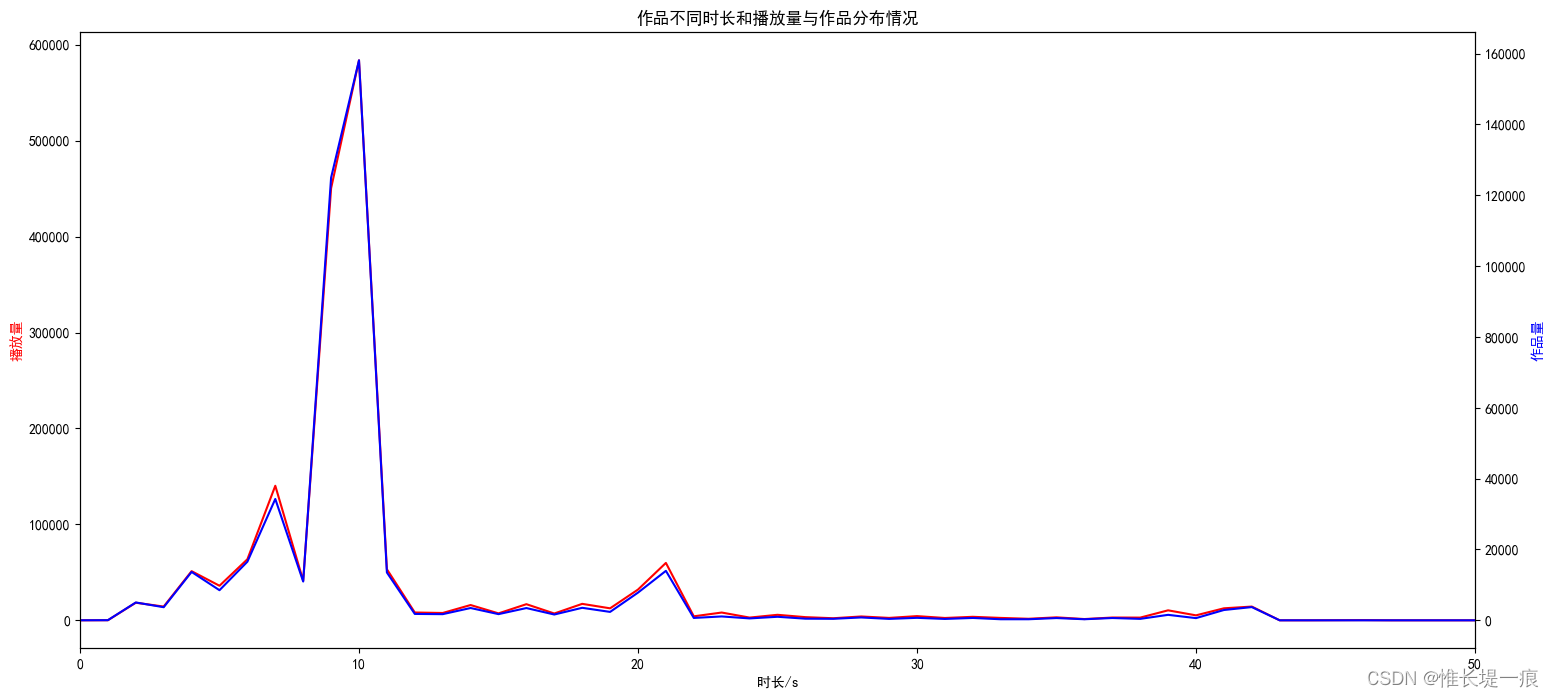
"""绘图"""
fig, ax1 = plt. subplots( figsize= ( 18 , 8 ) )
color = 'red'
ax1. set_title( '作品不同时长和播放量与作品分布情况' )
ax1. set_xlabel( '时长/s' )
ax1. set_ylabel( '播放量' , color= color)
ax1. plot( data_time. index, data_time. values, color= color)
ax2 = ax1. twinx( )
color = 'blue'
ax2. set_ylabel( '作品量' , color= color)
ax2. plot( data_time_item. index, data_time_item. values, color= color)
ax2. set_xlim( 0 , 50 )
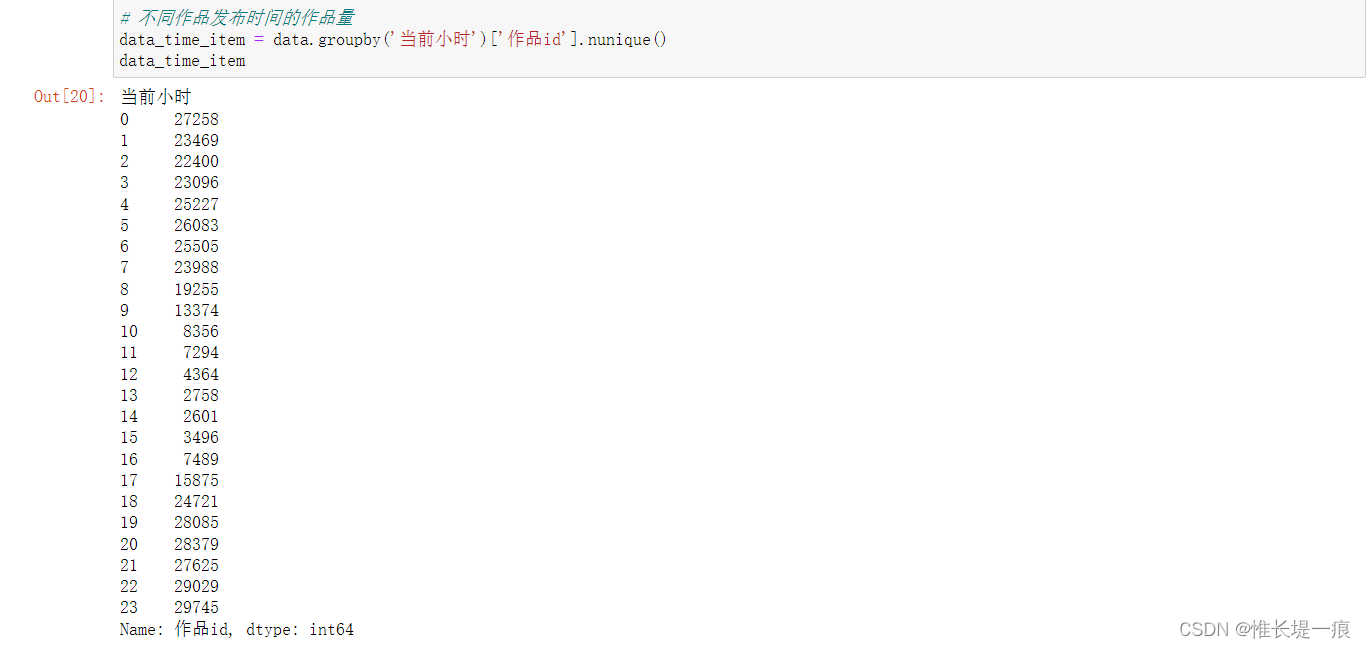
data_time = data. groupby( '当前小时' ) [ 'ID' ] . count( )
data_time
data_time_item = data. groupby( '当前小时' ) [ '作品id' ] . nunique( )
data_time_item
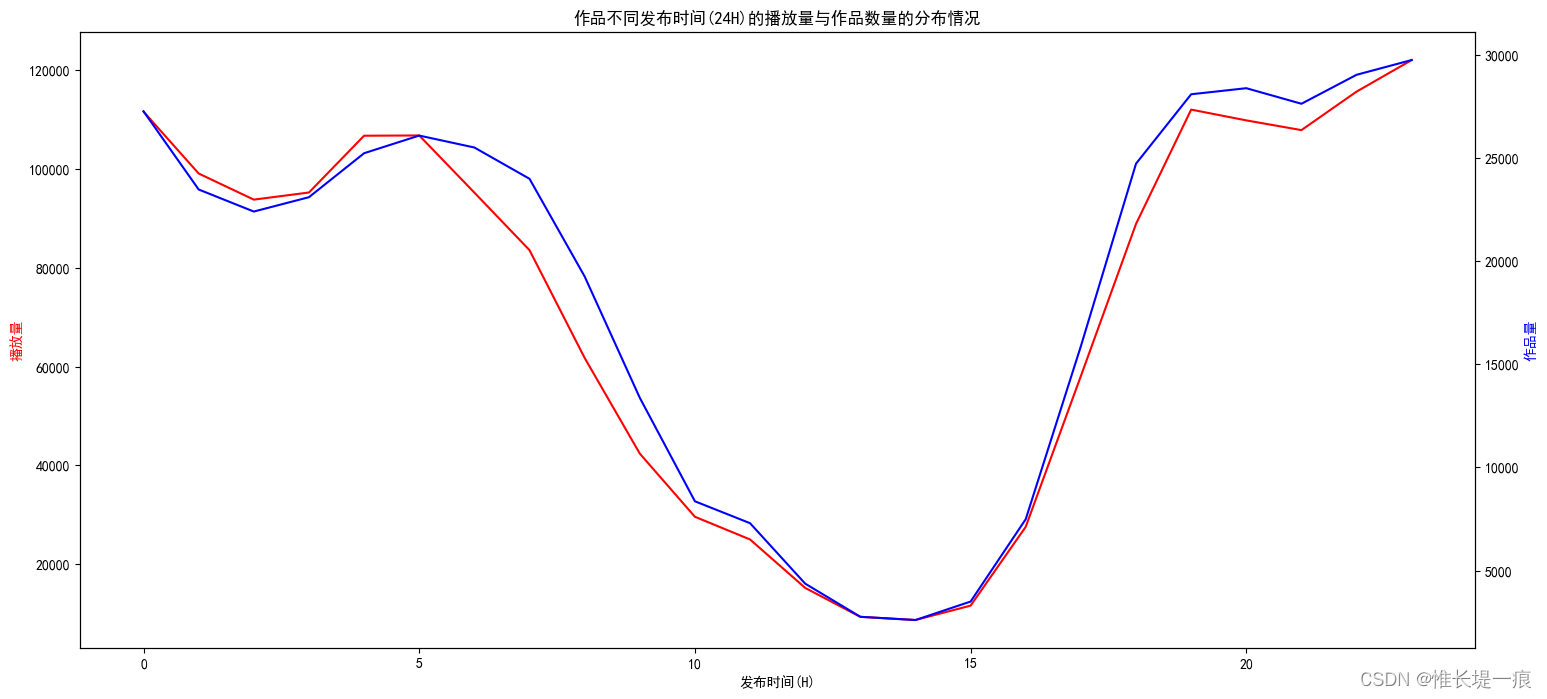
"""绘图"""
fig, ax1 = plt. subplots( figsize= ( 18 , 8 ) )
color = 'red'
ax1. set_title( '作品不同发布时间(24H)的播放量与作品数量的分布情况' )
ax1. set_xlabel( '发布时间(H)' )
ax1. set_ylabel( '播放量' , color= color)
ax1. plot( data_time. index, data_time. values, color= color)
ax2 = ax1. twinx( )
color = 'blue'
ax2. set_ylabel( '作品量' , color= color)
ax2. plot( data_time_item. index, data_time_item. values, color= color)
增加推广活动: 吸引新用户, 维持老用户 增加作者激励机制: 刺激作者发布作品 可以考虑拓展流量渠道: 吸引新用户加入 渠道: 0 背景音乐: 数量排名前十的背景音乐ID分别是:22、220、25、68、110、33、468、57、43、238 作品时长: 最好在7-12S左右, 不要超过22左右 作品发布时间: 19-0-5, 在这个时间段内发布作品流量池会比较大 积极参加平台活动