一、Jieba分词简介
(一)什么是中文分词?
- 中文文本的特点:连续无空格,需根据上下文确定词语边界。
- 分词的重要性:影响后续任务如信息检索、机器翻译、文本分类等。
(二)Jieba分词库
- Jieba分词是一款功能强大的中文分词工具,广泛应用于中文文本处理领域。
- Jieba分词结合了基于规则和基于统计的方法,通过构建大规模的前缀词典,实现了高效、准确的分词。
- Jieba分词支持三种分词模式:
- 精确模式
- 全模式
- 搜索引擎模式
二、jieba分词的实践
(一)安装与导入
1. 安装
pip install jieba2. 导入
import jieba
# 词性标注
import jieba.posseg as pseg (二)Jieba分词模式详解
1. 精确模式
适合文本分析,分词结果精准。
import jieba
text = "我喜欢学习自然语言处理"
words = jieba.lcut(text)
print(words)
# 输出: ['我', '喜欢', '学习', '自然语言处理']2. 全模式
输出所有可能的词语,冗余较多。
words = jieba.lcut(text, cut_all=True)
print(words)
# 输出: ['我', '喜欢', '学习', '自然', '自然语言', '语言', '语言处理', '处理']3. 搜索引擎模式
适合搜索引擎构建倒排索引。
words = jieba.lcut_for_search(text)
print(words)
输出: ['我', '喜欢', '学习', '自然', '语言', '自然语言', '处理', '语言处理']解释:在搜索引擎模式下,“自然语言处理”被切分成了“自然语言”和“语言处理”,而没有像全模式那样将其切分成更多冗余的部分。这个方式适合构建索引时,能够增加更多的查询匹配可能性。
(三)词性标注
Jieba分词还支持词性标注功能,即为每个词语添加对应的词性标记,如名词、动词、形容词等。这有助于更好地理解文本的语义信息。
words = pseg.cut("我爱北京天安门")
for word, flag in words:
print(f'{word} {flag}')
# 输出:我 r
# 爱 v
# 北京 LOC
# 天安门 LOC(四)关键词提取
Jieba分词提供了基于TF-IDF算法和TextRank算法的关键词提取功能,可以用于文本摘要、主题识别等场景。
基于TF-IDF的关键词提取:
通过计算每个词的 TF-IDF 值,extract_tags 方法会选择 TF-IDF 值高的词作为关键词。(extract:提炼)
import jieba.analyse as anls
keywords = anls.extract_tags("我爱北京天安门", topK=3)
print(keywords)
# 输出:['北京', '天安门', '爱']text:要分析的文本。
topK = 3:返回文本中 TF-IDF 值 前 3 个关键词。
【补充TF-IDF相关知识】
1. TF-IDF 的计算方式
TF-IDF 是两个部分的乘积:TF(词频) 和 IDF(逆文档频率)。
TF(Term Frequency):
- TF 是某个词在单个文档中出现的频率,表示该词对当前文档的重要性。
- 公式:

IDF(Inverse Document Frequency):
- IDF 反映的是一个词语在整个语料库中的重要性。如果某个词语在所有文档中都出现得很频繁(例如“的”、“是”等),那么它的 IDF 值就会非常低;而如果一个词只出现在少数几个文档中,那么它的 IDF 值就会很高。
- 公式:

2. TF-IDF 的作用
TF-IDF 值是 TF 和 IDF 的乘积。它用于衡量一个词在某个文档中的重要性,同时也考虑了该词在整个语料库中的普遍性。
- 如果 TF 很高,并且 IDF 也很高,那么该词就被认为是这个文档中非常重要的词。
- 如果 TF 很高,但 IDF 很低,说明该词在整个语料库中出现得非常频繁,可能是某些常见的连接词、助词等,这些词并不特别具有区分性。
- 如果 TF 很低,IDF 很高,那么该词可能在某些文档中是罕见的,但在语料库中出现的频率也很低,这样的词通常不是非常具有代表性。
3. 为何高 TF 和高 IDF 的词才是关键词?
- TF 反映了词语在当前文档中的重要性。
- IDF 反映了词语在整个语料库中的独特性。如果一个词语在很多文档中都出现,那么它对区分文档的作用就比较小,因此它的 IDF 值低,TF-IDF 也会低。
- 因此,高 TF 和高 IDF 的词语通常就是比较关键的,因为它们既能代表当前文档的主题,又在语料库中较为稀有。
基于TextRank的关键词提取:
TextRank 是一种图算法,灵感来源于 PageRank(Google 搜索引擎的排序算法),主要用于计算词语的重要性。
TextRank 解释:
- TextRank 算法通过构建一个词图,将每个词看作一个节点,节点之间的边表示词语的关系(例如相邻关系)。
- 算法会根据词语之间的连接关系计算每个词的 PageRank 值,值越高的词语被认为越重要。
TextRank 主要优势在于:
- 无需外部语料库:与 TF-IDF 不同,TextRank 是通过词与词之间的关系进行计算的。
- 适用于短文本:即使是短小的文本,TextRank 也能有效提取关键词。
keywords = anls.textrank("我爱北京天安门", topK=3, withWeight=False)
print(keywords)
# 输出:['北京', '天安门', '爱'](五)自定义词典
- 加载自定义词典以提高分词准确率。
- 调整词典:用户可以在自定义词典中指定词语的词频和词性,以便更好地控制分词结果。
1. 自定义一个词典
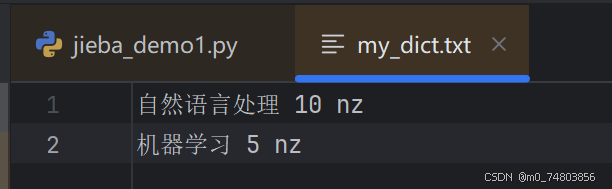
“10”为优先级;“nz”为词性。
2. 加载自定义词典
# 4. 自定义词典
# 加载自定义词典
jieba.load_userdict("my_dict.txt")
text_user = jieba.lcut(text)
print(f"自定义词典后的分词结果:{text_user}")输出结果:
自定义词典后的分词结果:['我', '爱', '自然语言处理', '、', '机器学习', '及', '人工智能']与自定义之前相比,自然语言处理和机器学习被分为两个完整术语。