爬虫
Python 爬虫是一种自动化工具,用于从互联网上抓取网页数据并提取有用的信息。Python 因其简洁的语法和丰富的库支持(如 requests、BeautifulSoup、Scrapy 等)而成为实现爬虫的首选语言之一。
Python爬虫获取浏览器中的信息,实际上是模仿浏览器上网的行为。上一篇中,我们尝试着爬取了一个网站页面的文本内容,完成获取信息需要完成四步:
- 指定url
- 发送请求
- 获取你想要的数据
- 数据解析
这次我们来试试用同样的方法爬取网站页面的图片看看可以成功吗?
爬取图片
我们来试试爬取下面网页,每本书的封面图片:
https://book.douban.com/tag/%E6%97%85%E8%A1%8C
指定url
打开开发者控制台,找到页面的url:
url = "https://book.douban.com/tag/%E6%97%85%E8%A1%8C"
发送请求
进行UA伪装给自己一个访问身份,requests()发送请求:
import fake_useragent
import requests
head = {
"User-Agent": fake_useragent.UserAgent().random
}
response = requests.get(url, headers=head)
获取想要的数据
#以文本形式,接受获得来的数据
res_text = response.text
数据解析
from lxml import etree
tree = etree.HTML(res_text) #将获取来的数据解析
定位想要内容的位置
#属性定位,定位到所有的li
li_list = tree.xpath("//ul[@class='subject-list']/li")
遍历所有的li标签,定位拿取图片的位置:
我们可以看到,在li标签中,图片的存放是链接形式的,拿取到链接后我们要再次向它的位置进行访问:
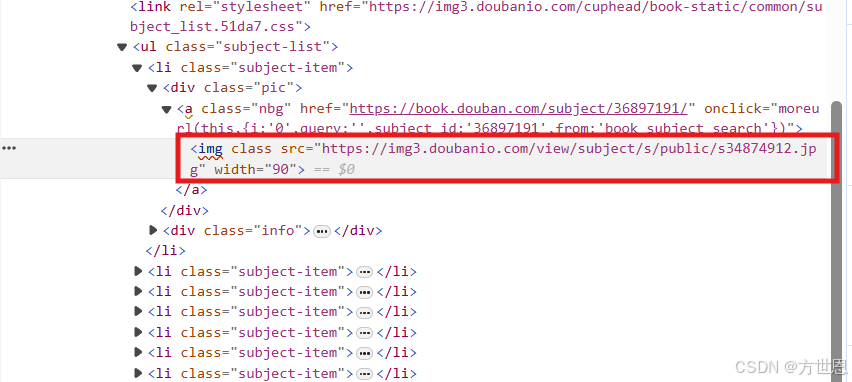
for li in li_list: #遍历每一个li标签
pic_url = "".join(li.xpath("./div[1]/a/img/@src")) #拿到图片链接
pic_res = requests.get(pic_url,headers=head) #发送请求
pic_content = pic_res.content #图片的存储,用content接收
存放图片
拿到图片内容后,我们要将它们存放起来:
如何快速建立一个文件夹呢?
os.path 是 Python 标准库 os 模块中的一个子模块,它提供了丰富的函数用于处理文件路径。这些函数可以帮助你执行路径的拼接、分割、查询等操作,而不需要担心操作系统的差异(例如,Windows 和 UNIX/Linux 在路径表示上的差异)。
import os.path #导入包
使用:
pic_name = 0 #给存放的名字编号取名
if not os.path.exists("./picLib"): #os.path.exists:检查path是否存在
os.mkdir("./picLib") #如果不存在,创建一个"./picLib"
with open(f"./picLib/{pic_name}.jpg", "wb") as fp:
#{pic_name}.jpg,每次遍历pic_name都发生变化,故此让存放的图片名字不一样
fp.write(pic_content)
pic_name += 1
完整代码实现
import os.path
import fake_useragent
import requests
from lxml import etree
if __name__ == '__main__':
# 1、UA伪装
head = {
"User-Agent": fake_useragent.UserAgent().random
}
pic_name = 0
url = f"https://book.douban.com/tag/%E6%97%85%E8%A1%8C"
# 2、发出请求
response = requests.get(url, headers=head)
# 3、获取数据
res_text = response.text
tree = etree.HTML(res_text)
# 4、数据解析
li_list = tree.xpath("//ul[@class='subject-list']/li")
# print(li_list)
if not os.path.exists("./picLib"):
os.mkdir("./picLib")
for li in li_list:
pic_url = "".join(li.xpath("./div[1]/a/img/@src"))
pic_res = requests.get(pic_url,headers=head)
pic_content = pic_res.content
with open(f"./picLib/{pic_name}.jpg", "wb") as fp:
fp.write(pic_content)
pic_name += 1
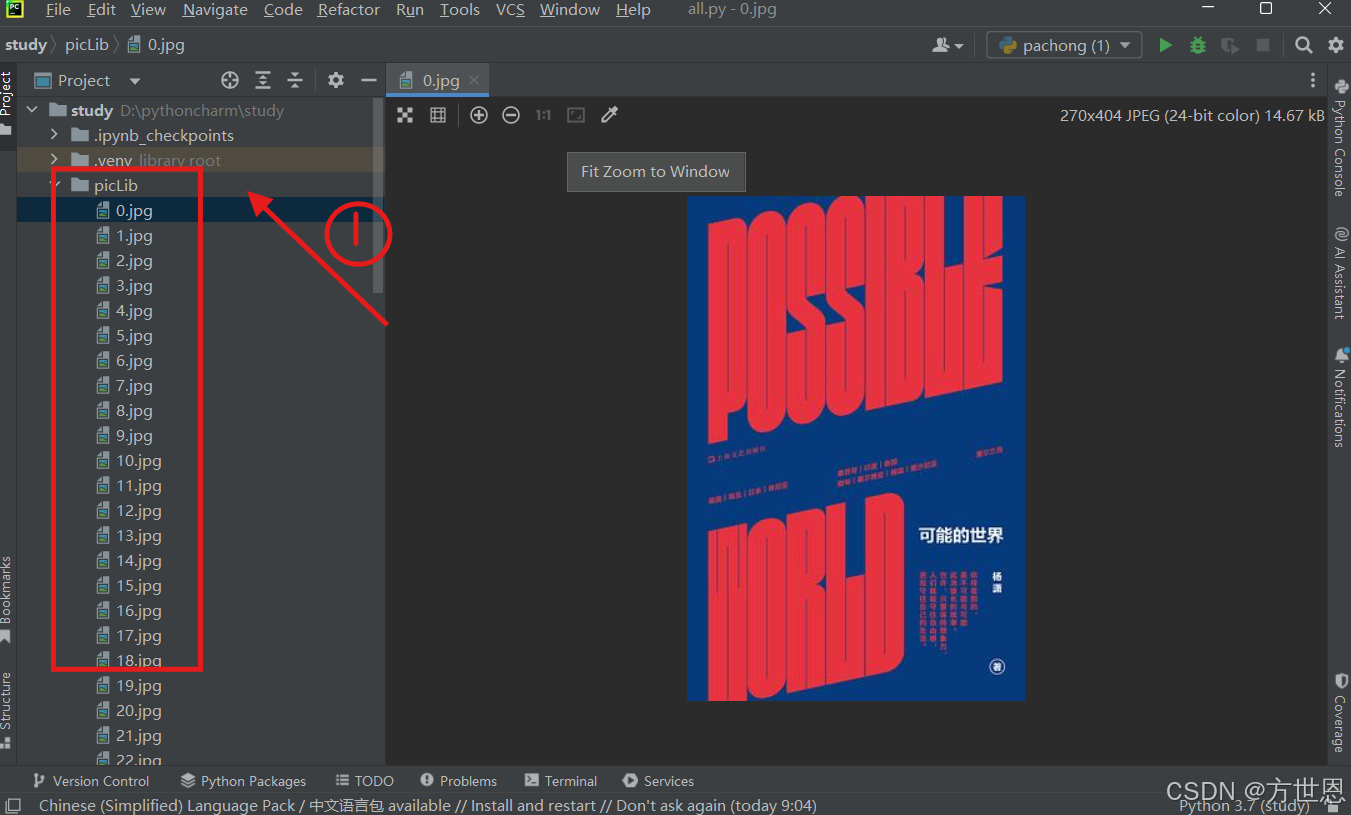
爬取成功显示:
找到创建的文件夹,点击查看图片,图片已经存放进去。
总结
本篇介绍了,如何爬取网页内的图片信息:
- 指定url
- 发送请求
- 获取你想要的数据
- 数据解析
特别注意:
在开发者控制台中,图片的存放是链接形式的,拿取到链接后我们需要再次向它的位置进行访问(发送请求)、获取想要的数据。