一、多进程基础操作
1、安装插件pytest-xdist
该插件实现进程级别的并发
pip install pytest-xdist -i Simple Index
2、使用插件
该插件主要使用的是插件提供的pytest执行时的命令行参数,所以我们要在pytest.ini中增加addopts中增加参数
*指定并发进程个数
-n 2 #指定两个进程并发
-n auto #根据当前电脑cpu自动生成最大进程个数
[pytest]
; -n 2 --dist=loadfile
addopts = -sv --alluredir ./report/data --clean-alluredir -n 2 --dist=loadfile
testpaths = ./testcases
python_files = test_*.py
python_classes = Test*
python_functions = test_*
log_cli = true
log_format = %(asctime)s %(levelname)s [%(name)s] [%(filename)s (%(funcName)s:%(lineno)d)] - %(message)s
log_date_format = %Y-%m-%d %H:%M:%S3、执行日志
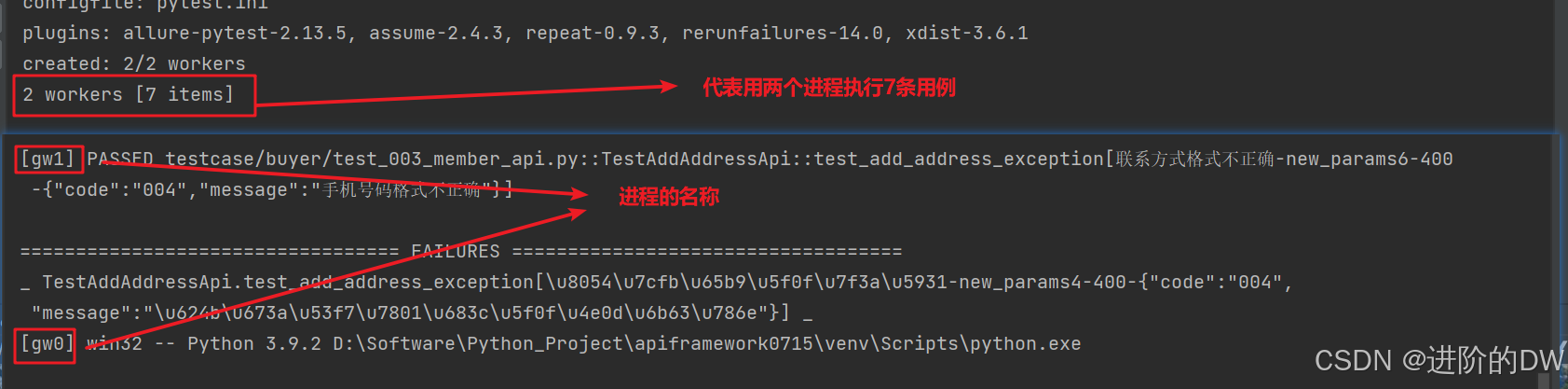
4、pytest-xdist用例分配的机制
~~~默认以测试用例为最小单位,两个进程都会收集到所有用例,执行的时候都会去判断用例是否已经被分配或者被某个进程标记,如果没有我就执行他,如果已经分配那么我就继续判断下一条,对于流程性的用例来说,这样就会造成执行失败的情况
~~~指定分配机制对于pytest-xdist来说,还有一个参数叫做--dist,可以指定多个进程并发时测试用例分配的维度,默认分配是按照用例,如果用例之间存在关联,他们没有被分配到同 一个进程,必然会失败,因此我们设计用例时,将有关联的用例放在同一个测试文件中,并且将分配机制改成按照测试文件进行分配,
--dist=loadfile
--dist=each,每个进程都执行所有用例
二、多进程并发时,问题处理
问题一:多进程并发可能会造成业务或者数据上的冲突
比如你的项目同一个用户不能同时登录,那么多进程并发可能会造成用户登录失败
比如一个用户在多进程去操作订单,比如A进程取消订单,B进程又针对订单进行发货,那么业务就冲突了
解决方案:让不同的进程使用不同的用户
这个方案首先要考虑的是如何区分不同的进程,我们可以通过pytest-xdist提供的进程名称或者id来区分,实际上pytest-xdist插件提供了一个fixture叫做worker_id,会返回当前进程的id或者名称,因此我们用他来得到当前进程的id,比如第一个进程id就是gw0,第二个就是gw1,依次类推
修改之前的buyer_login这个fixture
@pytest.fixture(scope="session",autouse=True)
def buyer_login(worker_id): #这个work_id是pytest-xdist自带的,需要先安装pytest-xdist
#如果没有使用多进程,work_id就是master
if worker_id == "gw0" or worker_id == "master":
resp = BuyerLoginApi("user1","password1").send()
elif worker_id == "gw1":
resp = BuyerLoginApi("user2", "password2").send()
BaseBuyerApi.buyer_token = resp.json()['access_token']
BaseBuyerApi.uid = resp.json()['uid']问题二:多进程并发时的日志文件冲突
之前我们把日志都记录在同一个本地文件中,并发时,可能会产生日志文件的冲突,或者说记录到的日志分不清是哪个进程
解决思路:针对每个进程都去记录自己的日志文件,可以根据worker_id来插件不同的日志文件
import logging.handlers
from path_manager import project_path
class GetLogger:
# 整个框架其实只需要一个日志对象即可,可以用单例模式实现
# 把logger定义成类属性,默认值是None
logger = None
# 类方法中完成上面logger属性的实例化过程
@classmethod
def get_logger(cls,worker_id="master"):
if cls.logger is None:
# 创建日志名称apiautotest,这个值是自定义的
cls.logger = logging.getLogger('apiautotest')
# 设置日志级别,debug/info/waring/error/critical
# 级别从左到右初步升高
cls.logger.setLevel(logging.DEBUG) # 设置为DEBUG,意味着比他高的级别的日志都会被记录
# 定义日志的一种格式
fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s (%(funcName)s:%(lineno)d)] - %(message)s"
fm = logging.Formatter(fmt)
# 创建日志处理器,把日志存储到文件,按照一定的规则
tf = logging.handlers.TimedRotatingFileHandler(
filename=f'{project_path}/logs/requests_{worker_id}.log',
when='H',# 间隔多长时间去生成新的日志文件,时间单位
interval=1,# 间隔的时间数量
backupCount=3,# 除了最新的日志文件外,最多保留3个之前的日志文件
encoding='utf-8'
)
# 将日志输出到控制台上
logging.basicConfig(level=logging.DEBUG,format=fmt)
# 在处理器tf中添加格式
tf.setFormatter(fm)
# 在日志对象添加处理器
cls.logger.addHandler(tf)
return cls.logger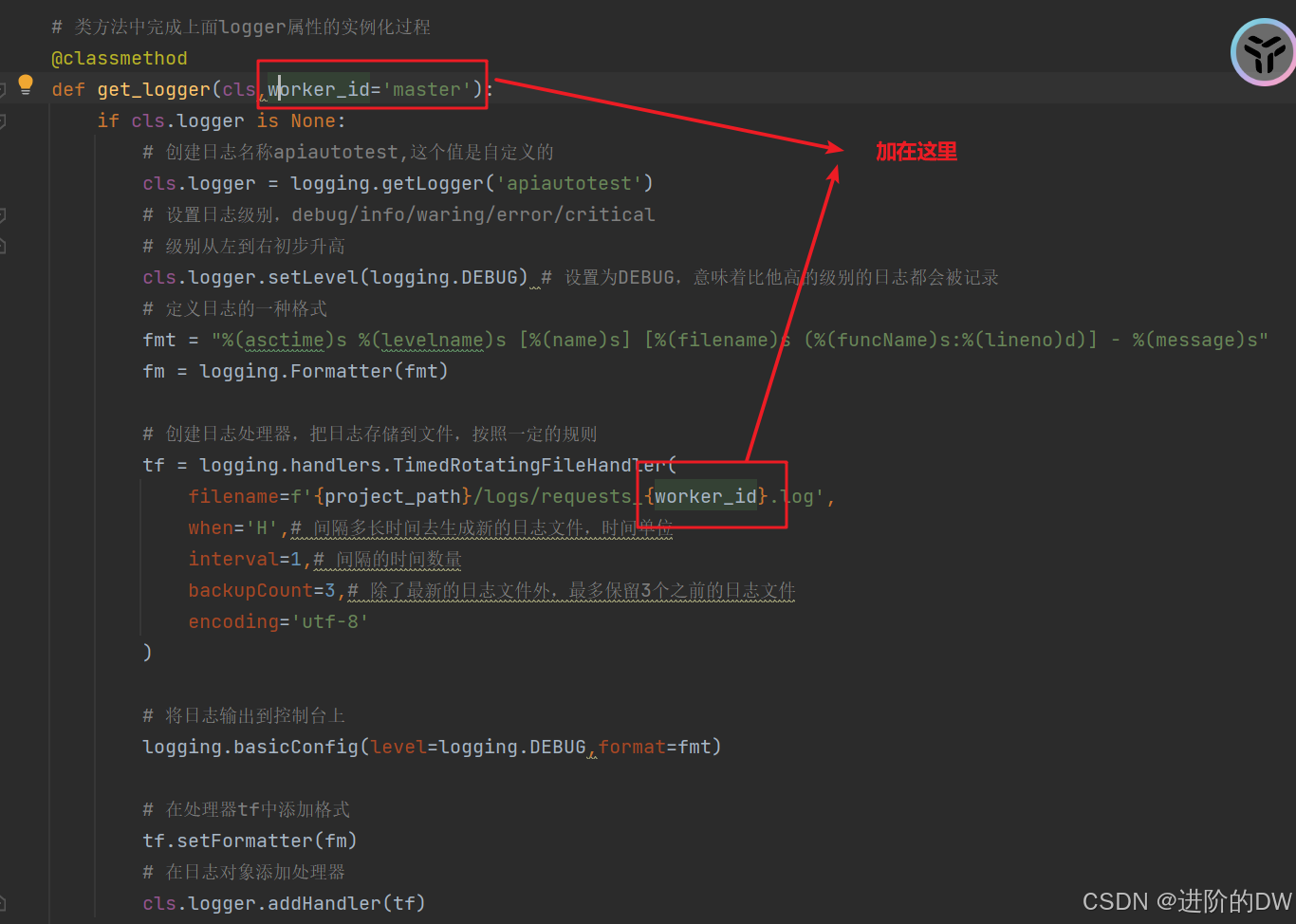
修改conftest中日志初始化
@pytest.fixture(scope='session',autouse=True)
def aaloggger_init(worker_id):
GetLogger.get_logger(worker_id).info('日志初始化成功')
问题3:多进程并发时--dist=each测试报告的问题
当多进程并发时,指定--dist==each,执行完成后测试报告的用例数量不对,比如一共10条用例,两个进程执行测试报告里面就应该有20条用例的数据,但是测试报告上面依然是10条
原因可能是allure-pytest这个库,统计用例信息时是根据用例的节点名称或者节点id进行统计的,虽然同一个用例在不同的进程里面进行,但是对allure-pytest来说就是一条用例。对于这个问题可以修改allure-pytest的源码,但是不好实现,因为熬集成在jenkins上,自动安装依赖库,不可能持续集成的环境中每次去修改源码
解决方法:可以修改pytest测试用例的节点名称或者节点id,和进程id挂钩,将他们拼接成新的节点名称或者节点id
from typing import List
# 重写pytest内置的钩子函数,来解决在pycharm控制台上看到的中文乱码
def pytest_collection_modifyitems(config:"Config",items:List['Item']):
# items对象是pytest收集到的所有测试用例对象
try:
addopts =config.getini('addopts')
# -sv --alluredir ./report/data --clean-alluredir -n 2 --dist=each
if '--dist=each' in addopts:
# 此时说明你要用的是多进程并发,我要得到当前的worker_id
worker_id = config.workerinput.get('workerid')
else:
worker_id = None
except:
worker_id = None
for item in items:
# item就代表一条用例
if worker_id:
item._nodeid = item._nodeid.encode('utf-8').decode('unicode-escape')+worker_id
item.originalname = item.originalname.encode('utf-8').decode('unicode-escape')+worker_id
else:
item._nodeid = item._nodeid.encode('utf-8').decode('unicode-escape')