import java.util.LinkedList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Reg {
public String content = "";
public List userRegList = new LinkedList();
public List userCommonList = new LinkedList();
public List userOneToOneList = new LinkedList();
//传入的参数为构造的字符串长度
public void initContent(int count) {
//选用StringBuffer,可以选用String一试,体现双方拼接字符串的效率差异
StringBuffer sb = new StringBuffer();
for (int i = 0; i < count / 20; i++) {
//为了简化,统一用一小段来循环
sb.append("abc href=\"abcd\"abce");
}
this.content = sb.toString();
}
//使用正则表达式方式
public void useRegCode() {
Pattern p = Pattern.compile("href=\"[^\"]*\"", Pattern.CANON_EQ);
Matcher match = p.matcher(this.content);
while (match.find()) {
userRegList.add(match.group(0));
}
}
// 主要使用字符串中提供的find函数来实现
public void useCommonCode() {
int i = 0;
int index = 0;
while ((index = content.indexOf("href=\"", i)) != -1) {
int endIndex = content.indexOf("\"", index + 6);
i = endIndex + 1;
userCommonList.add(content.substring(index, endIndex + 1));
}
}
// 一个一个字符地去遍历判断
public void useOneToOneCode() {
int length = content.length();
for (int i = 0; i < length; i++) {
//这里的实现有点依赖了目标的头字符了,为了简单忽略
if (content.charAt(i) == 'h' && i + 5 < length
&& content.substring(i, i + 5).equals("href=")) {
int j = i + 6;
boolean match = false;
for (; j < length; j++) {
if (content.charAt(j) == '\"') {
match = true;
break;
}
}
j++;
if (match) {
userOneToOneList.add(content.substring(i, j));
}
i = j;
}
}
}
//消耗时间记录,为了避免前后程序的干扰,在具体测试中,一个一个来测试记录时间
public static void main(String[] args) {
Reg r = new Reg();
r.initContent(8000000);
// 使用OneToOne
long t5 = System.currentTimeMillis();
r.useOneToOneCode();
long t6 = System.currentTimeMillis();
System.out.println("你的程序运行了:" + (int) ((t6 - t5) / 1000) + "秒"
+ ((t6 - t5) % 1000) + "毫秒");
// 使用正则表达式
long t3 = System.currentTimeMillis();
r.useRegCode();
long t4 = System.currentTimeMillis();
System.out.println("你的程序运行了:" + (int) ((t4 - t3) / 1000) + "秒"
+ ((t4 - t3) % 1000) + "毫秒");
// 使用find
long t1 = System.currentTimeMillis();
r.useCommonCode();
long t2 = System.currentTimeMillis();
System.out.println("你的程序运行了:" + (int) ((t2 - t1) / 1000) + "秒"
+ ((t2 - t1) % 1000) + "毫秒");
}
}
测试过程中,每种方式单独运行,数据量为8000000字符,数据如下,纵坐标单位为毫秒,横坐标单位为次,如图1.1
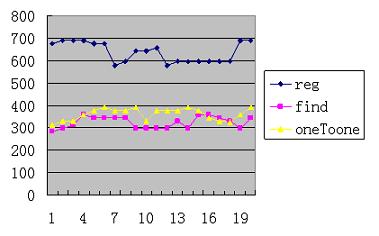
图1.1
当数据量小的时候如800字符到8个字符,使用正则表达式大约需25毫秒(猜想,所用时间消耗在正则式的解释中),而其它两种方式不足1毫秒,若数据量为80000字符,使用正则表达式大约需45毫秒,而其它两种方式大约为14毫秒。
通过这次测试,正则表达式在开发coding中,阅读和防止出bug上有很大好处,但是其性能依然值得注意。