TiDB 是一篇 Real-time HTAP 分布式数据库工业实现的论文。这里做一些简单的翻译和简化。
ABSTRACT
Hybrid Transactional and Analytical Processing(HTAP) 需要隔离处理事务性和分析性查询,以解决它们之间的冲突。为了实现这一点,有必要为这两种类型的查询维护不同的数据副本。然而,在存储系统中为分布式副本提供一致的视图是非常有挑战性的,分析性请求从事务性工作负载中高效地读取一致的、最新的数据,并保持高可用性。
(简要了解HTAP、OLTP、OLAP的概念,参考:浅谈“HTAP” - 腾讯云开发者社区-腾讯云)
为了应对这一挑战,本文扩展了基于复制状态机的一致性算法,为HTAP工作负载提供一致的副本。基于这一想法,我们提出了一个基于raft的HTAP数据库:TiDB。在数据库方面,设计了一个由行存储和列存储组成的多存储系统。基于Raft算法构建行存储。它是可伸缩的,可以实现来自事务性请求的高可用性更新。具体来说,它异步复制Raft日志给学习者,这些学习者将元组的行格式转换为列格式,形成实时可更新的列存储。此列存储允许分析查询有效地读取新鲜和一致的数据,并且与行存储上的事务具有很强的隔离性。在这个存储系统的基础上,我们构建了一个SQL引擎来处理大规模分布式事务和昂贵的分析查询。SQL引擎最优地访问数据的行格式和列格式副本。我们还有一个强大的分析引擎,TiSpark,帮助TiDB连接到Hadoop生态系统。综合实验表明,TiDB在CH-benCHmark下实现了独立的高性能测试。
1. INTRODUCTION
阐述了RDBMS(关系型数据库)、NoSQL系统(牺牲ACID 事务换取弹性扩展能力)、NewSQL系统(针对OLTP的读写,提供与NoSQL相同的可扩展性和性能,同时能支持满足ACID特性的事务)、OLAP系统(比如一些 SQL-on-Hadoop systems)的出现背景。
这些系统都秉承着“one size dose not fit all”的范式,对于不同的使用场景(OLAP和OLTP)使用不同的数据模型和技术。但是,多系统对于开发、部署、运维都是代价较高的,而且实时分析最新数据的需求也很强烈。这使得混合OLTP和OLAP的系统(HTAP)在工业和学术界都得以发展。HTAP系统应该像NewSQL系统一样实现可伸缩性、高可用性和跨界一致性。此外,HTAP系统需要在新鲜度和隔离性两个额外要求下有效地读取最新的数据,保证OLTP和OLAP请求的吞吐量和延迟。
新鲜度表示分析请求处理到的数据有多近,分析最新的实时的数据有很大的商业价值。然而,一些HTAP方案没有保证新鲜度,例如基于Extraction-Transformation-Loading(ETL)操作的方案。通过ETL操作,OLTP系统提供一批最新的数据给OLAP,但是ETL会耗费几个小时或者几天的时间,所以它无法提供实时的分析。ETL操作也可以被流式处理替代,然而,因为缺少统一的管理模型,保证语义一致性变得十分复杂。与多个系统交互也会带来额外的开销。
隔离性表示保证OLTP和OLAP请求的独立性。一些内存数据库能够在分析请求时读取最新的数据,但不能在OLTP和OLAP上都保证高性能,因为他们在数据同步和接口上消耗较大。实验表明,可以运行分析请求的系统,它的OLTP吞吐量会显著下降。为了保证隔离性,将OLTP和OLAP请求运行在不同的硬件资源上是必要的。要这么做需要解决的基本问题是维护一个最新的从OLTP工作负载到OLAP请求的副本。为了保证高可用性,还要保证数据在不同副本间的一致性。而高可用性是可以通过一些众所周知的一致性算法来实现,例如Paxos和Raft。它们基于复制状态机来同步副本。通过扩展这些一致性算法来实现HTAP工作负载间的一致性是可行的。据我们所知,这个想法目前还没被研究过。
根据这个想法,我们提出一种基于Raft算法的HTAP数据库:TiDB。它为Raft算法引入了专用节点(称为learners)。Learner节点从leader节点异步复制事务日志,为OLAP查询构造新的副本。Learners还将日志中的行格式元组转换为列格式,以便副本更适合于分析性查询。对于在leader节点上运行的事务查询,日志复制带来的开销很小。而且这种复制的延迟很短,可以保证OLAP的数据新鲜度。我们使用不同的数据副本分别处理OLAP和OLTP请求,以避免它们相互干扰。我们还可以基于行格式和列格式的数据副本优化HTAP请求。基于Raft协议,TiDB提供了高可用性、可伸缩性和数据一致性。
TiDB提供了一种创新的解决方案,可以帮助基于共识算法的NewSQL系统发展为HTAP系统。NewSQL系统通过复制它们的数据库,如谷歌Spanner和CockroachDB,确保了OLTP请求的高可用性、可伸缩性和数据持久性。它们通过通常来自一致算法的复制机制跨数据副本同步数据。基于日志复制,NewSQL系统可以提供专门用于OLAP请求的柱状副本,这样它们就可以单独支持HTAP请求,比如TiDB。
我们认为我们的贡献如下:
- 我们提出建立一个基于共识算法的HTAP系统,并实现了一个基于raft的HTAP数据库TiDB。它是一个开源项目[7],为HTAP工作负载提供高可用性、一致性、可伸缩性、数据新鲜度和隔离性。
- 我们将学习者角色引入Raft算法,为实时OLAP查询生成一个柱状存储。
- 我们实现multi-Raft存储系统和优化其读写,这样系统提供高性能当扩展到多个节点。
- 我们为大规模HTAP查询定制了一个SQL引擎。引擎可以最佳地选择使用基于行的存储或基于列的存储。
- 我们使用HTAP基准CH-benCHmark对TiDB关于OLTP、OLAP和HTAP的性能进行了全面的测试。
2. RAFT-BASED HTAP
TiDB 扩展了 Raft 算法,保证OLTP到OLAP数据一致性和新鲜度,同时保持了工作负载的独立性。
传统的Raft算法,任意follower都可以成为leader,followers数量增加还影响性能。所以我们增加了 learner 角色,learner 只异步接收 Raft Group 的 Raft 日志,它不参与 Raft 协议来提交日志或选举领导人。Leader对learner的日志同步是强制的、实时的。实验表明,在数据的复制过程中,TiFlash的 Learner 节点对 TiKV 的性能开销非常小。 (参考:读 TiDB 论文有感 | 数据强一致性且资源隔离的 HTAP 数据库 - 知乎)
事务性请求需要高效的数据更新,分析性请求例如聚合需要读取部分列、但非常多行。基于行格式可以利用索引提高对事务性请求的性能,基于列格式可以利用数据压缩和向量化提高处理效率。Learner 角色接受到数据后,将行格式元组转换为列式数据存储,达到了数据在 TiDB 集群中同时行存储和列存储的目的。我们还可以优化查询计划,只访问其中一种存储方式或者同时访问行列存储。
为了生产应用,我们还克服了很多工程挑战,包括:1. 怎样构建支持高并发读写的可扩展的Raft存储系统。数据增加时怎样扩容,怎样解决传统Raft leader耗时的瓶颈。2. 怎样快速同步日志,并进行行列转化。3. 怎样优化查询计划。在后续章节中,会对此做详细介绍。
3. ARCHITECTURE
下图是TiDB的架构图。TiDB支持MySQL协议,可被兼容MySQL的客户端访问。它有三个核心组成部分:分布式存储层、位置驱动(PD,Placement Driver)和计算引擎层。
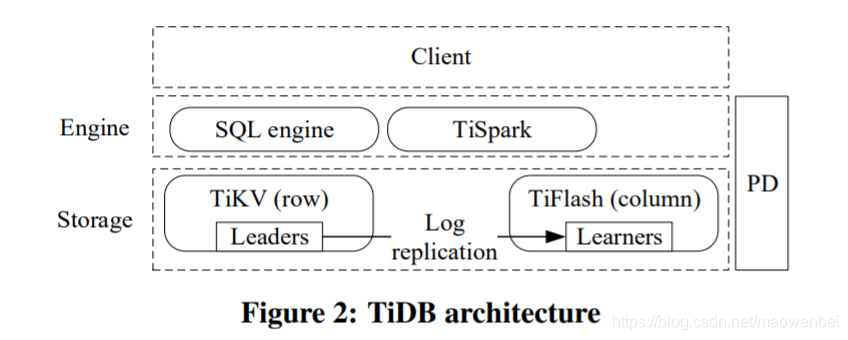
分布式存储层分为行存储(TiKV)和列存储(TiFlash)。逻辑上,TiKV中的数据是以key-value map的形式存储的。key由table ID和row ID构成,value是实际的行数据。为了水平扩展,我们把这个map分为连续的region。每个region有多个备份来保证高可靠性。Raft算法用于维持每个region的多个备份之间的一致性,形成一个Raft组。不同Raft组的leader节点,把数据从TiKV同步到TiFlash。TiKV和TiFlash可以部署在不同的物理资源上,以保证处理事务性请求和分析性请求时的隔离性。
位置驱动(PD,Placement Driver)用于管理regions,包括提供每个key的region和物理位置,自动移动region以平衡工作负载。PD还提供严格增长、全局唯一的时间戳。PD可以由多个PD成员组成,以提高鲁棒性和性能。PD没有持久状态,在启动时,PD成员从其他成员和TiKV节点收集所有必要的数据。
计算引擎层是无状态的,并且是可扩展的。我们的定制SQL引擎有一个基于成本的查询优化器和一个分布式查询执行器。TiDB实现了基于Percolator[33]的两阶段提交(2PC)协议,以支持事务处理。查询优化器可以根据查询选择从TiKV或TiFlash读取数据。
TiDB的体系结构满足了HTAP数据库的要求。TiDB的每个组件都被设计为具有高可用性和可伸缩性。存储层使用Raft算法来实现数据副本之间的一致性。TiKV和TiFlash之间的低延迟复制使分析查询可以获得新数据。查询优化器,加上TiKV和TiFlash之间的强一致性数据,提供了快速的分析查询处理,而对事务处理的影响很小。
除了上述组件外,TiDB还集成了Spark,这有助于将存储在TiDB中的数据与HDFS进行集成。TiDB拥有一组丰富的生态系统工具,可以将数据导入到TiDB,也可以从TiDB导出数据,还可以将数据从其他数据库迁移到TiDB。
4. MULTI-RAFT STORAGE
存储层有两个引擎:基于行存储的TiKV和基于列存储TiFlash。架构如下:
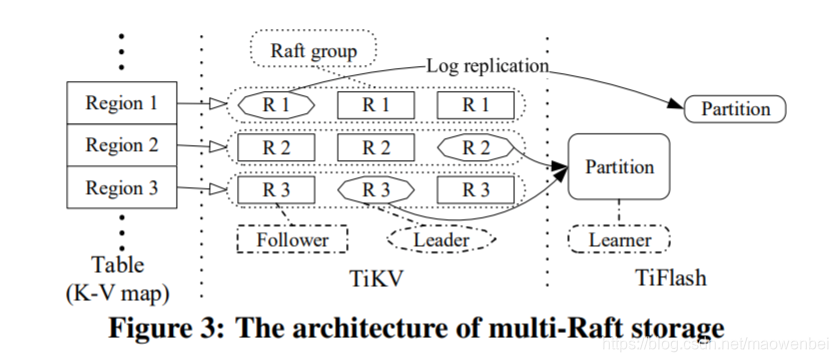
4.1 Row-based Storage (TiKV)
TiKV之间使用传统的Raft进行备份的,数据持久化到RocksDB,leader来处理对应区域的读写请求。在处理读写请求时,从leader到它的followers的基本Raft算法步骤如下:
(1)一个区域的leader节点接受SQL引擎的请求;(2)leader把请求追加到日志;(3)leader把新的日志条目发送给它的followers,这些条目会追加到followers的日志中;(4)leader等待它的followers响应。如果满足法定节点数的响应成功,leader提交请求并应用到本地;(5)leader把结果返回给客户端,接着处理下一个请求。
传统的Raft流程保证了数据的一致性和高可用性。但是,因为操作是顺序的,性能不高。4.1章主要介绍了怎样优化操作,达到高读写吞吐,以解决第2章中列出的挑战1。
1. 从Leaders 到 Followers 的优化。
通过以下方法提高传统Raft算法的并行度:传统算法步骤2和3的leader日志追加和发送日志给followers同时进行;日志缓存在leader,批量发送给followers;发送日志给followers后,leader不等待响应,假设它成功并继续用预测的index发送新日志;如果发生错误,leader调整日志index,重发复制请求;针对传统算法第4步,leader用一个新线程异步处理应用请求的操作。
2. 加速客户端读请求。
从TiKV的leaders读数据时,必须满足线性化,即每次读请求返回的数据都必须是最新的。为了满足这个条件,Raft会给读请求也生成一条日志,等这条日志被应用了才会返回结果。但是,同步日志的操作是昂贵的,我们要避免日志同步来提高性能。
考虑到leader选举机制,一个Raft组内的leader是会变化的,TiKV实施了以下几种读取优化:
(1)read index,当leader收到一个读请求,记录当前最新的提交index并且发送心跳请求确认自己仍然是leader。在它是leader的情况下,只要这个read index被应用了,就可以响应读请求。
(2)lease read,leader和followers达成一个租赁期限,在此期间不做选举,leader可以不经过followers响应任意读请求。
(3)follower read,当follower收到一个读请求,它向leader获取最新的read index,当本地已应用的index大于它,就可以响应请求。这种方式可以通过增加follower数量提高读请求的性能。
3. 管理大量的区域(Region)。
因为大量区域分布在一群服务器上,它们会动态变化,区域可能会集中到某些服务器。我们用Placement Driver(PD)平衡不同服务器上的区域。规定每个区域必须有至少3个备份在不同TiKV实例来保障高可用性。同时监控每台服务器上的工作服在,在不影响服务的情况下,把热点区域移动到不同的服务器上。
发送心跳、管理元数据,会消耗大量网络和存储资源。然而,如果一个Raft组没有工作量,是不需要心跳的。根据区域的工作量,我们调整了心跳请求的发送频率,这减小了遇到网络延迟、高负载节点等运行问题的可能性。
4. 动态的区域分割和合并。
大的区域很容易过热,影响访问速度,应该被分割为小区域以改善工作量分布。另一方面,有些区域可能较小而且较少访问,却仍然需要心跳和元数据,需要被合并。为了维护region的有序性,我们只合并连续区域。PD根据对workload的监控,向TiKV发送分割和合并的指令。
4.2 Column-based Storage (TiFlash)
TiDB中还包含了列存储(TiFlash)。TiFlash由一些learner节点构成,它们从Raft group接收日志,转化为列格式。它们不参与Raft协议选举,对TiKV的影响较小。
用户通过SQL语句 “ALTER TABLE x SET TiFLASH REPLICA n” 来建立列格式的备份,其中x是被备份的表名,n是备份数量,默认1。TiFlash中的每个表被分为多个分区,每个分区包含一个连续范围的元组,对应TiKV中多个连续的区域。更大的区域便于范围扫描。
当TiFlash初始化开始,关联区域的Raft leaders开始复制它们的数据到新的learners。如果数据很多,会发送快照。当初始化完成,TiFlash实例开始监听Raft组的更新。当learners收到一包日志,它把日志应用到本地:重放日志、改变数据行列格式、更新本地存储。接下来详细描述TiFlash怎样快速应用日志,保持与TiKV的一致性,以解决第2章中列出的挑战2。
- 日志重放
- 任务同步
- Columnar Delta Tree
- 读操作
5. HTAP ENGINES
为解决第二章提出的第三个挑战,处理大量的事务性请求和分析性请求,我们提出了一个SQL引擎来评估请求。这个SQL引擎优化了Percolator模型,实现了分布式集群中的乐观和悲观锁定。 计算层有两个引擎:SQL Engine 和 TiSpark。
5.1 Transactional Processing
5.2 Analytical Processing
5.3 Isolation and Coordination
8. CONCLUSION
我们提供了一个可用于生产的HTAP数据库:TiDB。TiDB建立在TiKV之上,TiKV是一个分布式的、基于行的存储,它使用Raft算法。我们引入了用于实时分析的柱状学习器,它从TiKV异步复制日志,并将行格式数据转换为列格式。TiKV和TiFlash之间的这种日志复制以很小的开销提供了实时数据一致性。TiKV和TiFlash可以部署在单独的物理资源上,以有效地处理事务性和分析性查询。TiDB可以在扫描事务性和分析性查询的表时,以最佳方式选择它们进行访问。实验结果表明,TiDB在HTAP的CH-benCHmark测试中表现良好。TiDB提供了一个通用的解决方案,将NewSQL系统发展为HTAP系统。