前言
福彩双色球的玩法和规则是双色球投注区分为红色球号码区和蓝色球号码区,红色球号码从1-33,蓝色球号码是从1-16。投注方法是,从红色区选出6个不重复的号码再加上蓝色区的一个号组成一个投注组。双色球通过摇奖器确定中奖号码,摇奖时先摇出6个红色球号码,再摇出1个蓝色球号码。如果所选的七个号码与摇出的七个号相同,则是一等奖。
想对规则有更深的理解可以直接访问中国福利彩票官网。
一、概率
双色球的摇奖过程是从33个球里面先取出6个球和再从16个球里面取出一个球,取红球时它的计算过程是取第一个球有33种情况,当第一个球被取走后,到取第二个球有33-1种情况,一直到取第6个球的时候有33-6+1种情况。如果取出的球还要按排列顺序来组合的话,比如(1,2,3)和(3,2,1)在排列中是不一样,则计算公式如下:
使用阶乘表示:
但双色球并不考虑顺序的组合问题,则要把用排列计算得出的结果除以重复计算的次数,计算所有组的方式:
使用阶乘表示:
那么双色球最终的计算是:
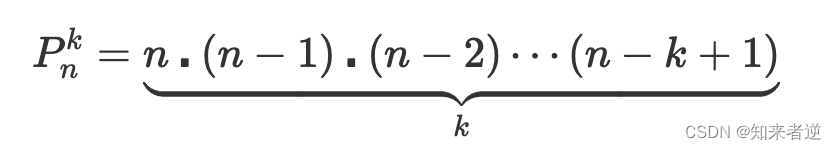
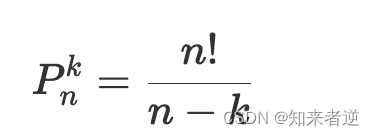
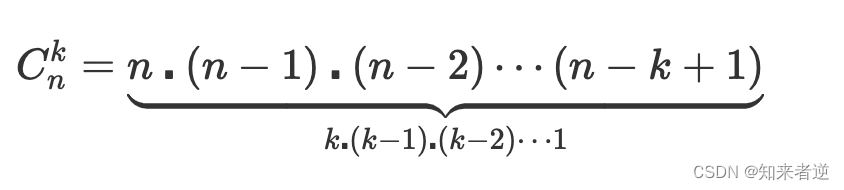
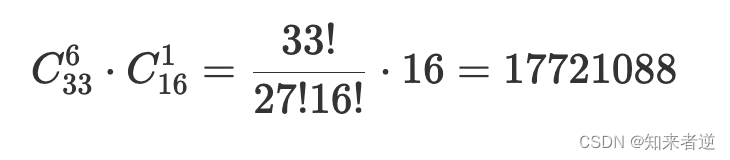
•一等奖(6+1)中奖概率为:红球33选6乘以蓝球16选11/17721088=0.0000056%;
•二等奖(6+0)中奖概率为:红球33选6乘以蓝球16选0=15/17721088=0.0000846%;
•三等奖(5+1)中奖概率为:红球33选5乘以蓝球16选1=162/17721088=0.000914%;
•四等奖(5+0、4+1)中奖概率为:红球33选5乘以蓝球16选0=7695/17721088=0.0434%;
•五等奖(4+0、3+1)中奖概率为:红球33选4乘以蓝球16选0=137475/17721088=0.7758%;
•六等奖(2+1、1+1、0+1)中奖概率为:红球33选2乘以蓝球16选1=1043640/17721088=5.889%;
二、统计
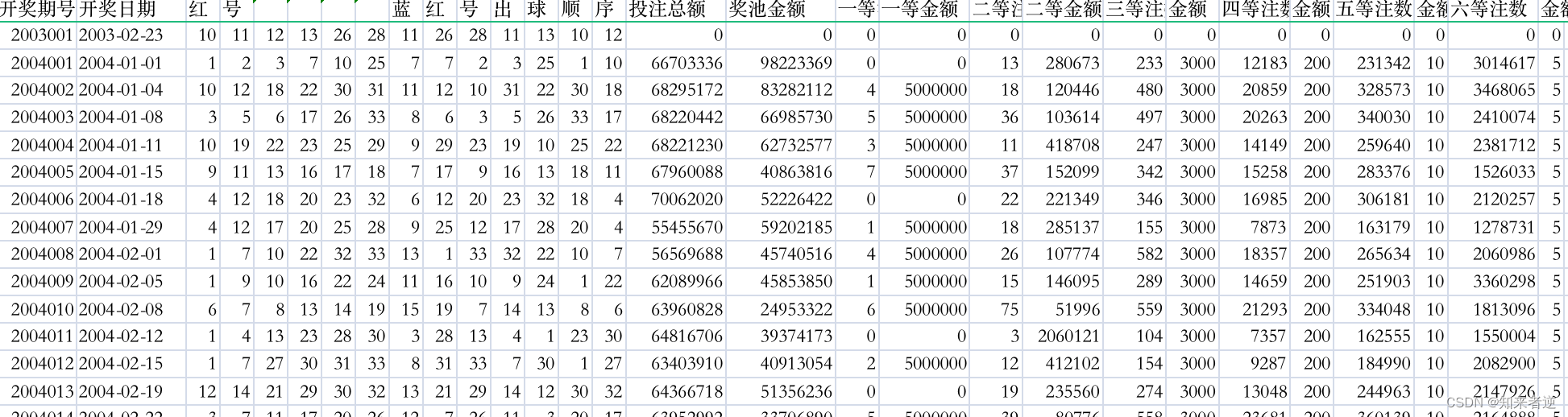
双色球是2003年正式开售的,一年能开出150期左右,到2022年,差不多有3000期左右,统计这3000多期的开奖结果,是不是可以找到某些规律呢?这里把从第一级到最后的一期的所有数据都收集在一个表里面了,借助python就可以对中奖号码组进行统计。
数据的存放格式如下:
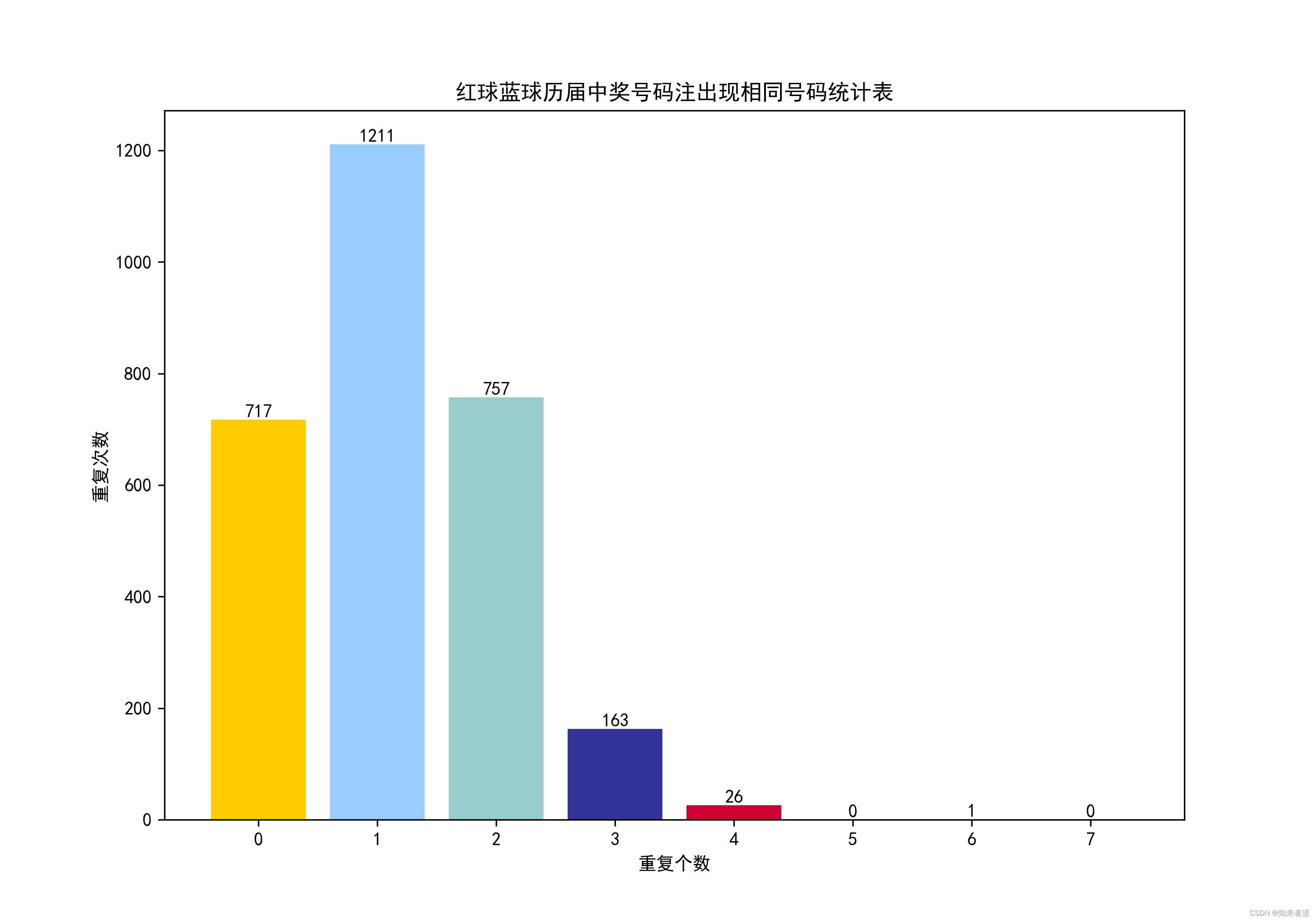
1. 重叠计算
使用Python计算所有往期的中奖号码组出现的重叠次数,
对比两注数据的相同个数
def comparison_list(a,b):
k = 0
if len(a) == 6:
for i in range(len(a)):
for j in range(len(b)):
if a[i] == b[j]:
k = k + 1
elif len(a) == 7:
for i in range(len(a)-1):
for j in range(len(b)-1):
if a[i] == b[j]:
k += 1
if a[6] == b[6]:
k += 1
return k
# 只统计蓝球区的重复注数
def stat_blue_ball(data):
blue = copy.deepcopy(data)
indexs = []
for i in range(len(blue)):
blue[i].pop()
for i in range(len(blue)-1):
indexs.append(comparison_list(blue[i],blue[i+1]))
b = [0 for _ in range(7)]
for i in range(len(b)):
b[i] = indexs.count(i)
return b
# 统计整注的重复占比率
def stat_all_ball(list):
indexs = []
for i in range(len(list) - 1):
indexs.append(comparison_list(list[i], list[i + 1]))
all = [0 for _ in range(8)]
for i in range(len(all)):
all[i] = indexs.count(i)
return all
统计发现,这么多期开奖结果,有4个数重叠的只有26次,6个数重叠就只有一对,从来没有开出过与旧的中奖号一模一样的一组数,所以,如果选出来的这组数,与往期中的某期的开奖号码重叠的号码太多了,那么中奖的机率会大的降低。
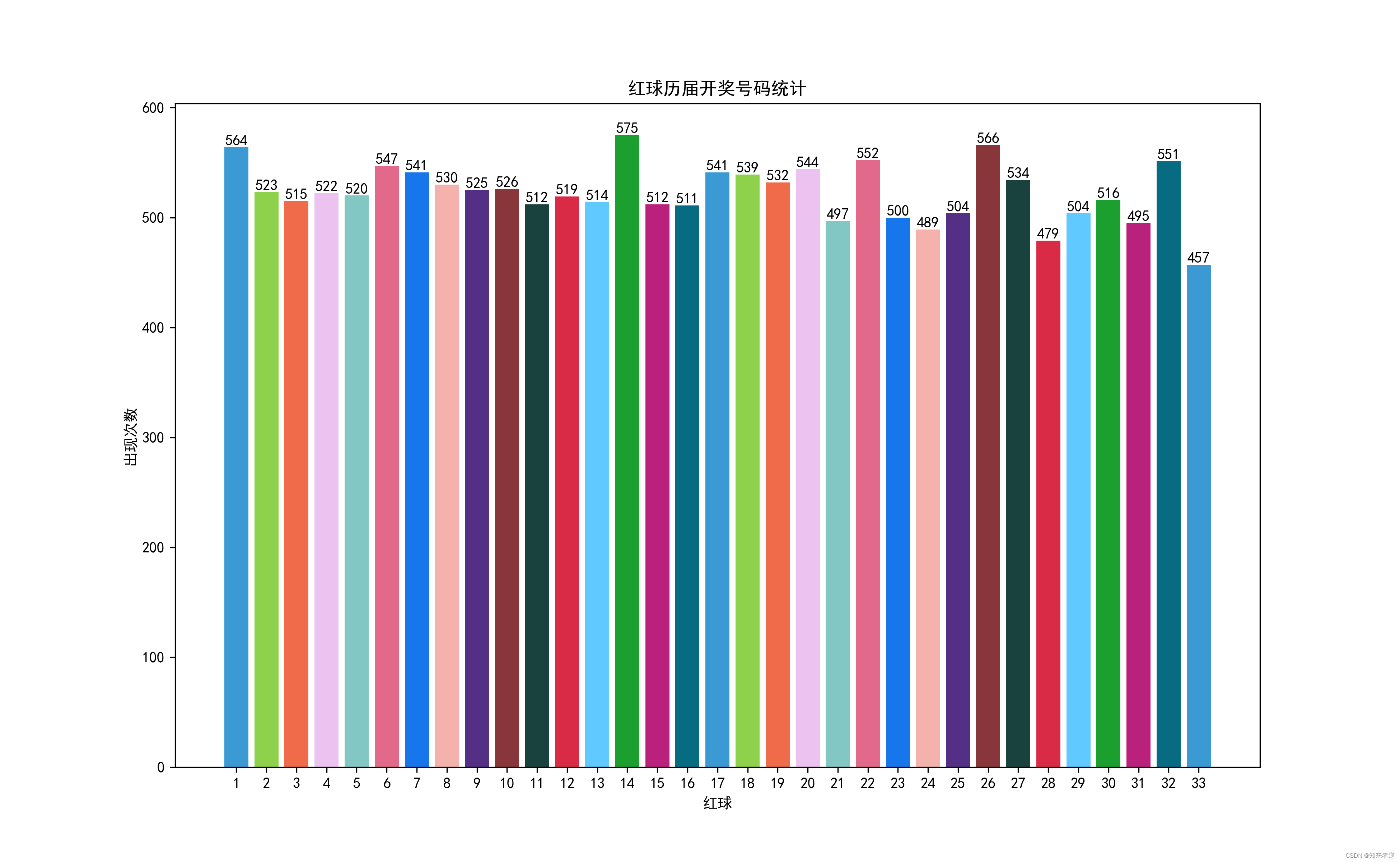
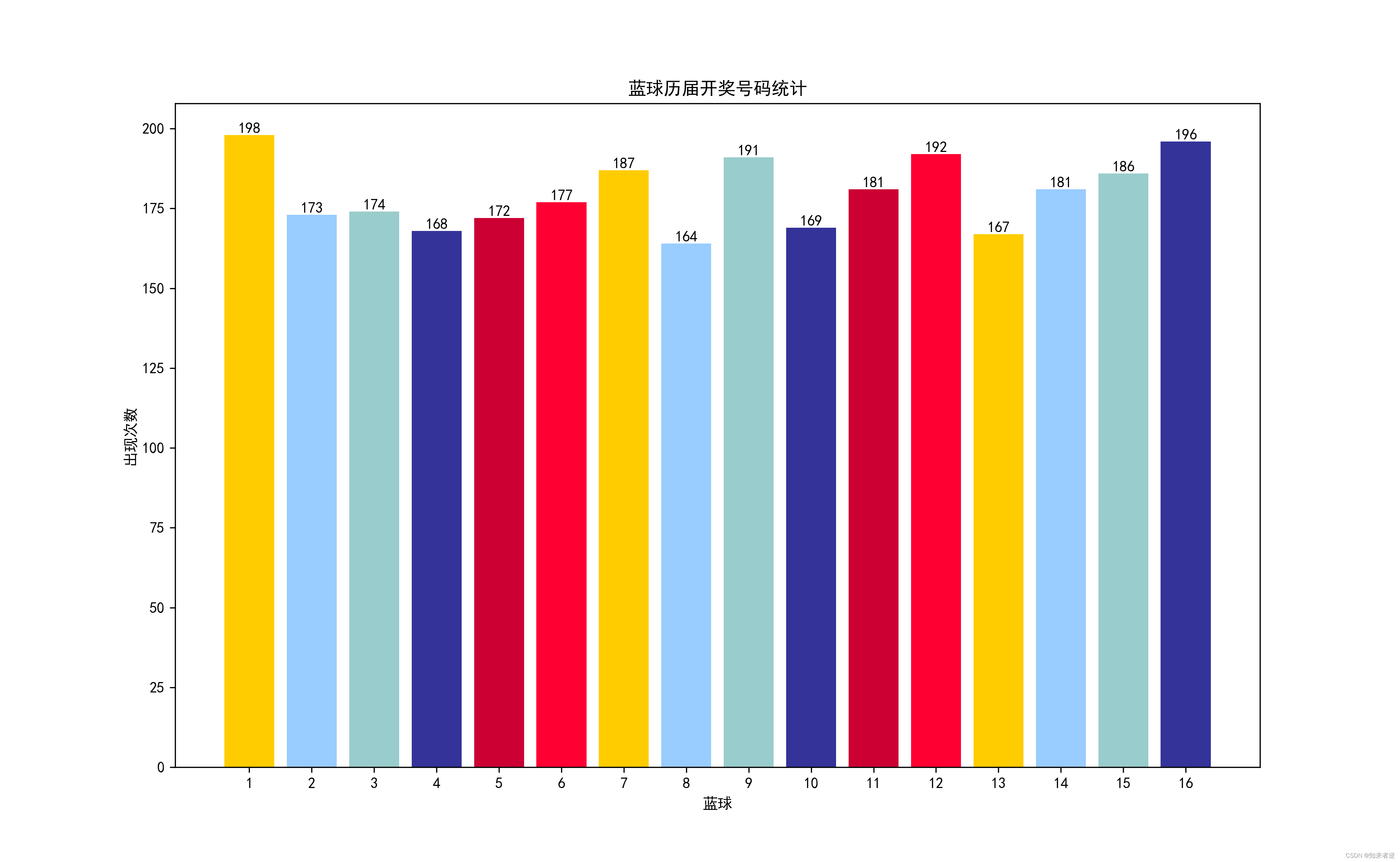
2.统计每个号码出现的次数
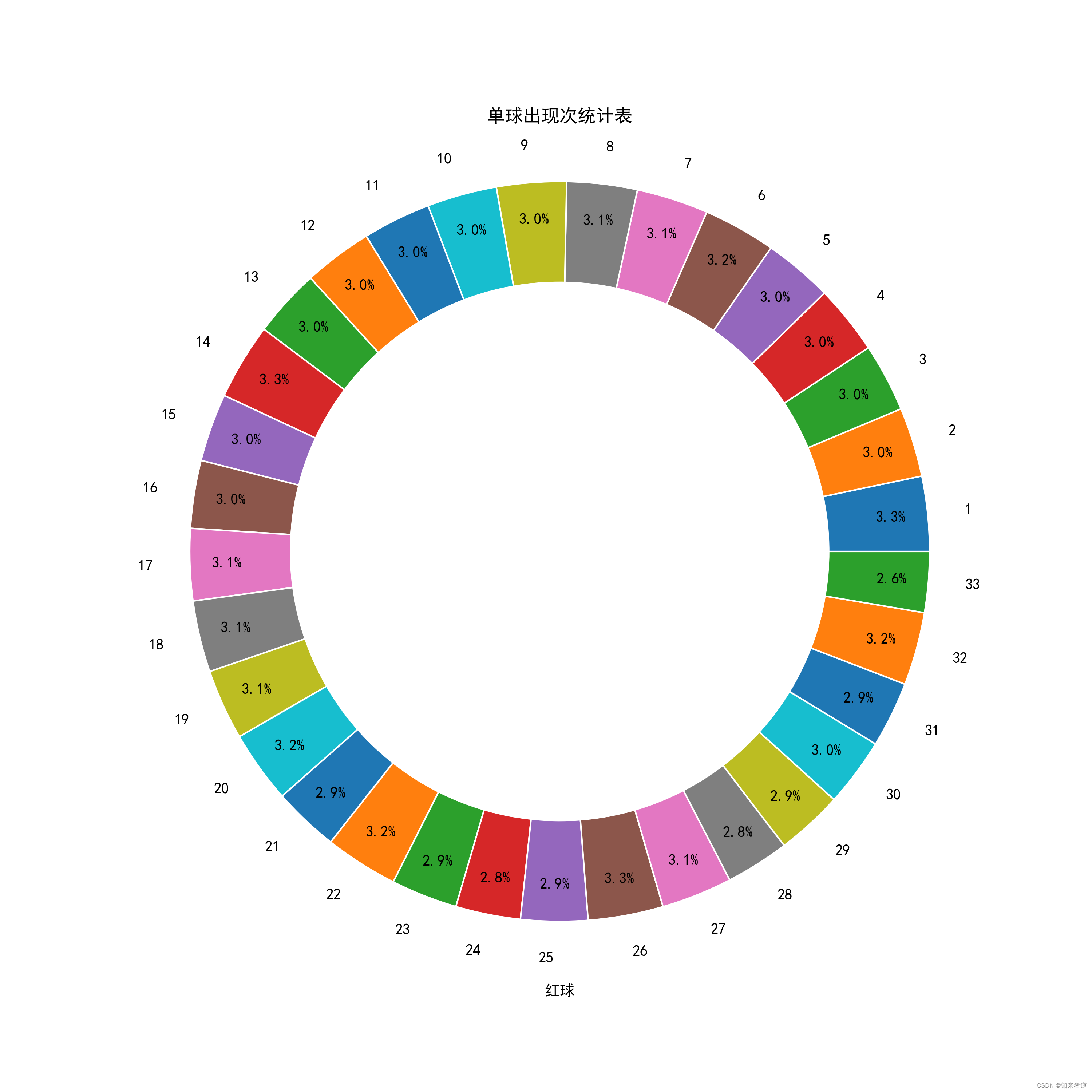
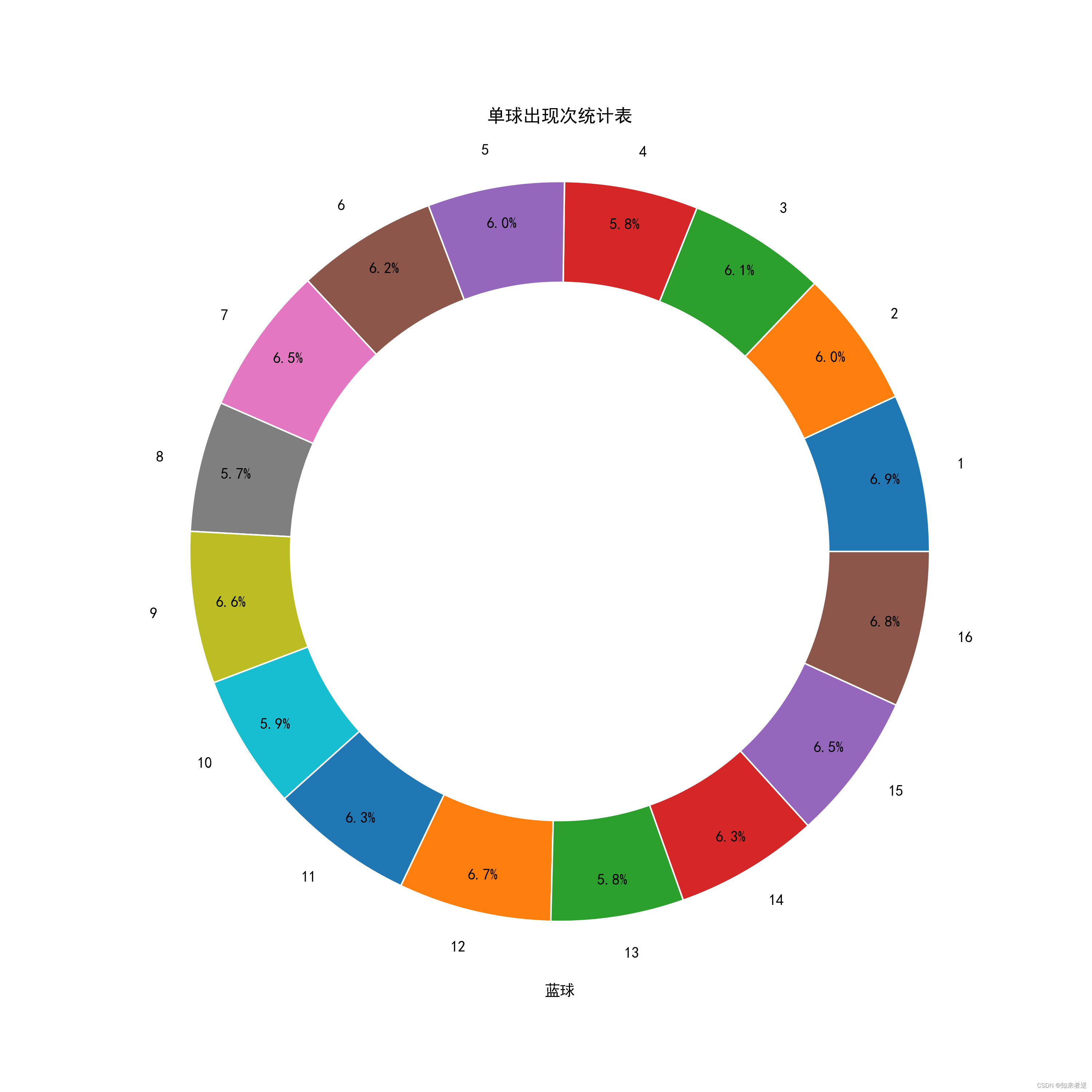
统计显示,红球区27是出现最多的数字,33是出现最少的数字,但出现最多的数字与出现最少的数字并不相差很大。
def occurrences(list,name,colors):
y_data = list
x_data = []
for i in range(len(y_data)-1):
x_data.append(str(i+1))
y_data.pop(0)
fig, ax = plt.subplots(figsize=(13, 8))
ax.bar(x=x_data, height=y_data, color=colors)
for i in range(len(y_data)):
plt.text(i, y_data[i], y_data[i], ha='center', va= 'bottom') # 显示y轴数据
# 设置图片名称
plt.title(name+'历届开奖号码统计')
# 设置x轴标签名
plt.xlabel(name)
# 设置y轴标签名
plt.ylabel("出现次数")
plt.savefig(name + "统计图.png", dpi=300)
# 显示
# plt.show()
红球出现次数统计图:
蓝球出现次数统计图:
3.环比图
统计出现次数概率
def percentage(rad,name):
data = rad
pie_labels = []
for i in range(len(data)):
pie_labels.append(str(i+1))
fig, ax = plt.subplots(figsize=(10, 10))
ax.pie(data, radius=1.1, pctdistance=0.9,labels=pie_labels, wedgeprops=dict(width=0.3, edgecolor="w"),
autopct='%1.1f%%')
plt.title("单球出现次统计表")
# 设置x轴标签名
plt.xlabel(name)
plt.savefig(name+"百分比图.png", dpi=300)
# plt.show()
红球区
蓝球区
三、预测
有很多老彩民喜欢研究双色球的预测,而且还分了不同的预测流派,像黄金分割选号、尾数分布选号、相减排除等等方法,是于预测的结果如何,见仁见智了。一般老彩民的预测往往以年或月为单位,进行综合计算后,预测出下期可能开的号码组,但人脑的计算能力与所接受的数据广度是有限的,双色球是2003年正式开售的,到现在2022年大概开了3000多期,那么从以这3000多期为样本,是否能计算出中奖号码的规律?
在过去的10年里,机器学习解决了很多科研难题,那么使用用机器学习来预测双色球走向,是否能比老彩民做得更好,它是否能解决这种无规律数据的预测呢?这种无规律的数据要使用卷积神经网络,显然不是最好的解决方法,毕竟是无规律数据,那根本就是没有特征可以提取,这里只能选择使用长短期记忆(Long short-term memory, LSTM)记忆网络,毕竟是要从历史的数据中学习到可能存在的规律。
四、LSTM
长短期记忆网络(Long short-term memory, LSTM)是一种特殊的RNN模型,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题,相比普通的RNN,LSTM能够在更长的序列中有更好的表现。RNN(Recurrent Neural Network)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,它能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
1.RNN
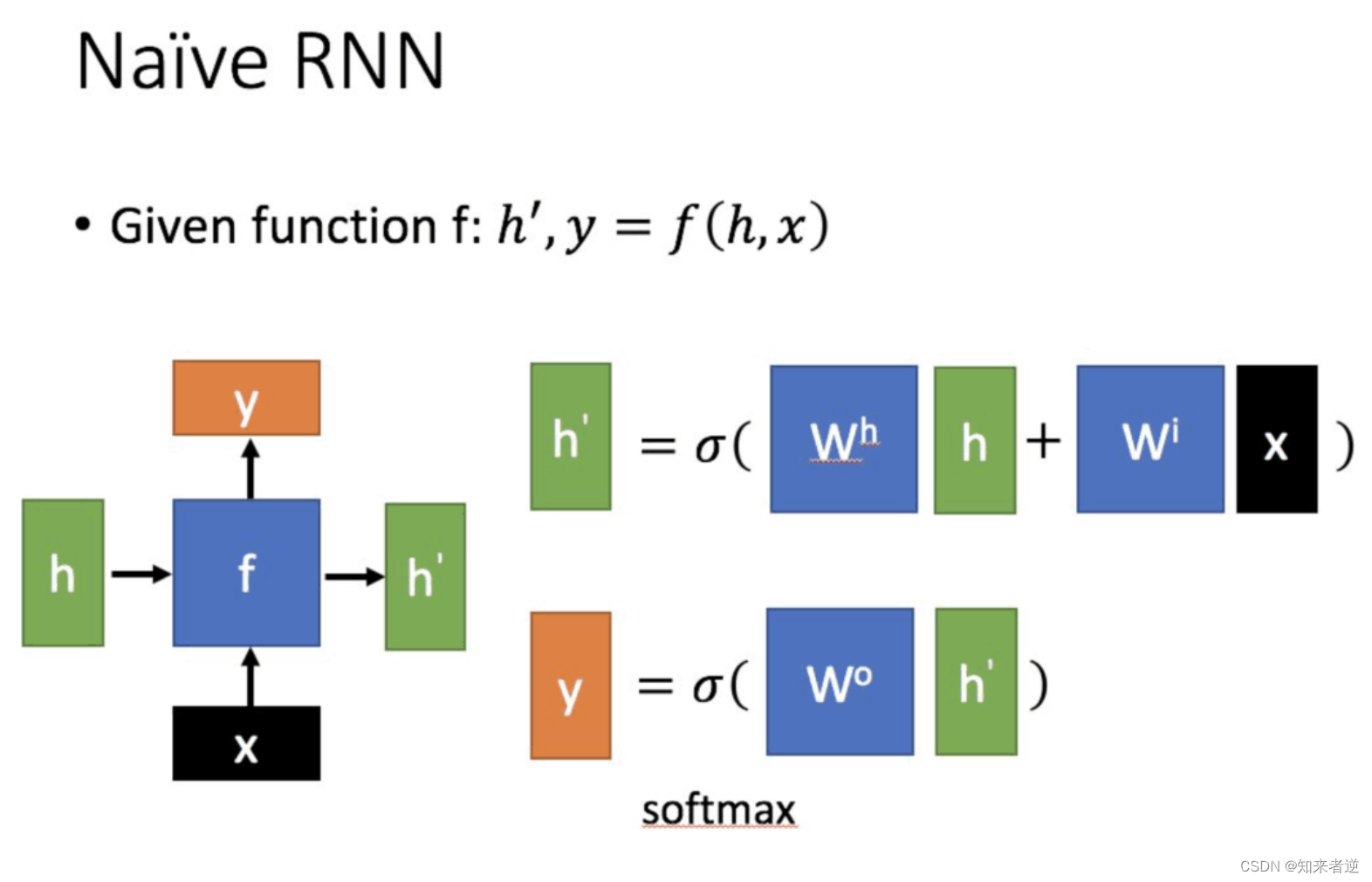
Rnn网络结构
x为当前状态下数据的输入, h表示接收到的上一个节点的输入。
y为当前节点状态下的输出, h`而为传递到下一个节点的输出。
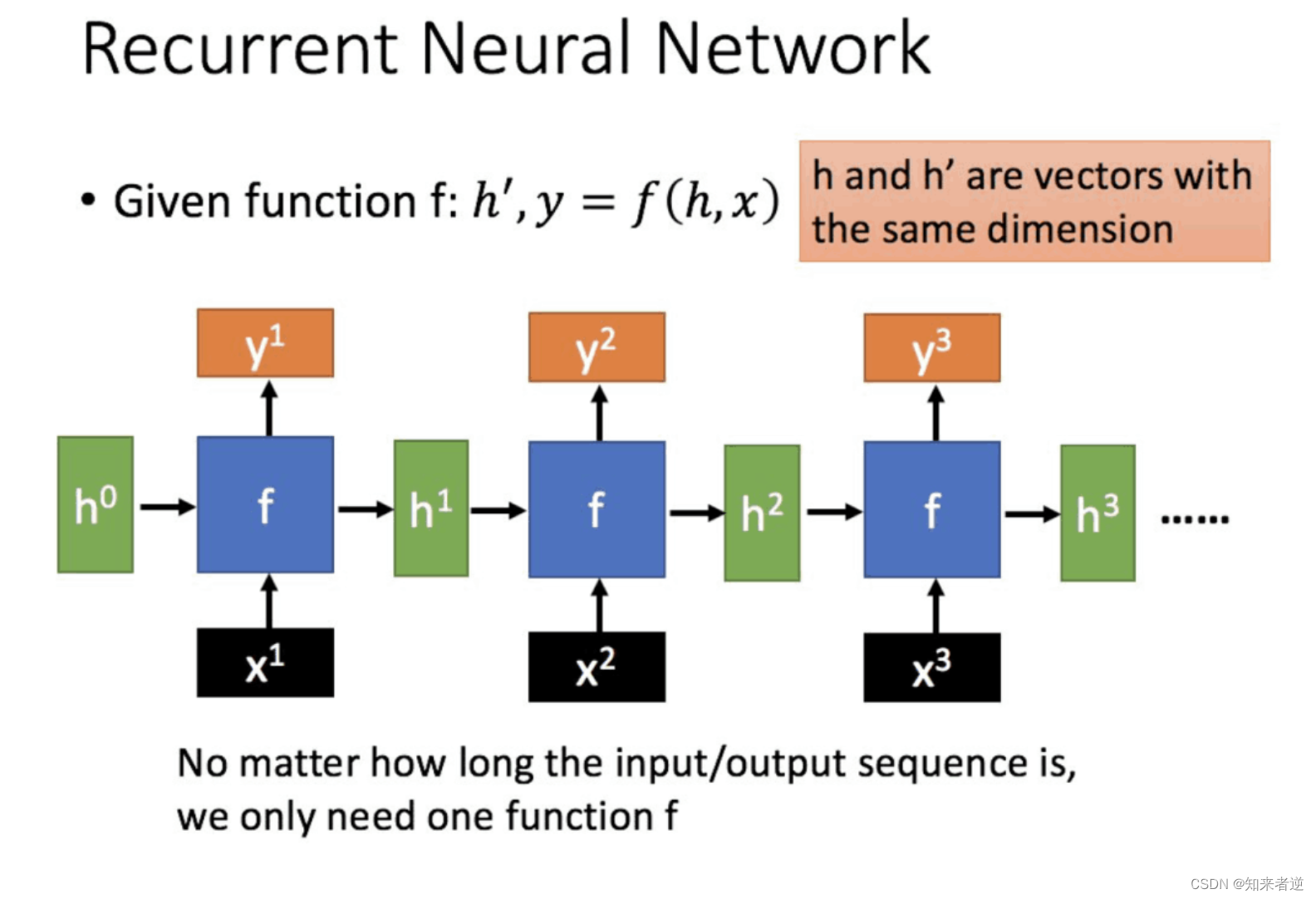
从公式可以得到,输出 h’ 与 x 和 h 的值都相关。而 y 则常常使用 h’ 投入到一个线性层(主要是进行维度映射)然后使用softmax进行分类得到需要的数据。对这里的y如何通过 h’ 计算得到往往看具体模型的使用方式。通过序列形式的输入,就可以得到如下形式的RNN。
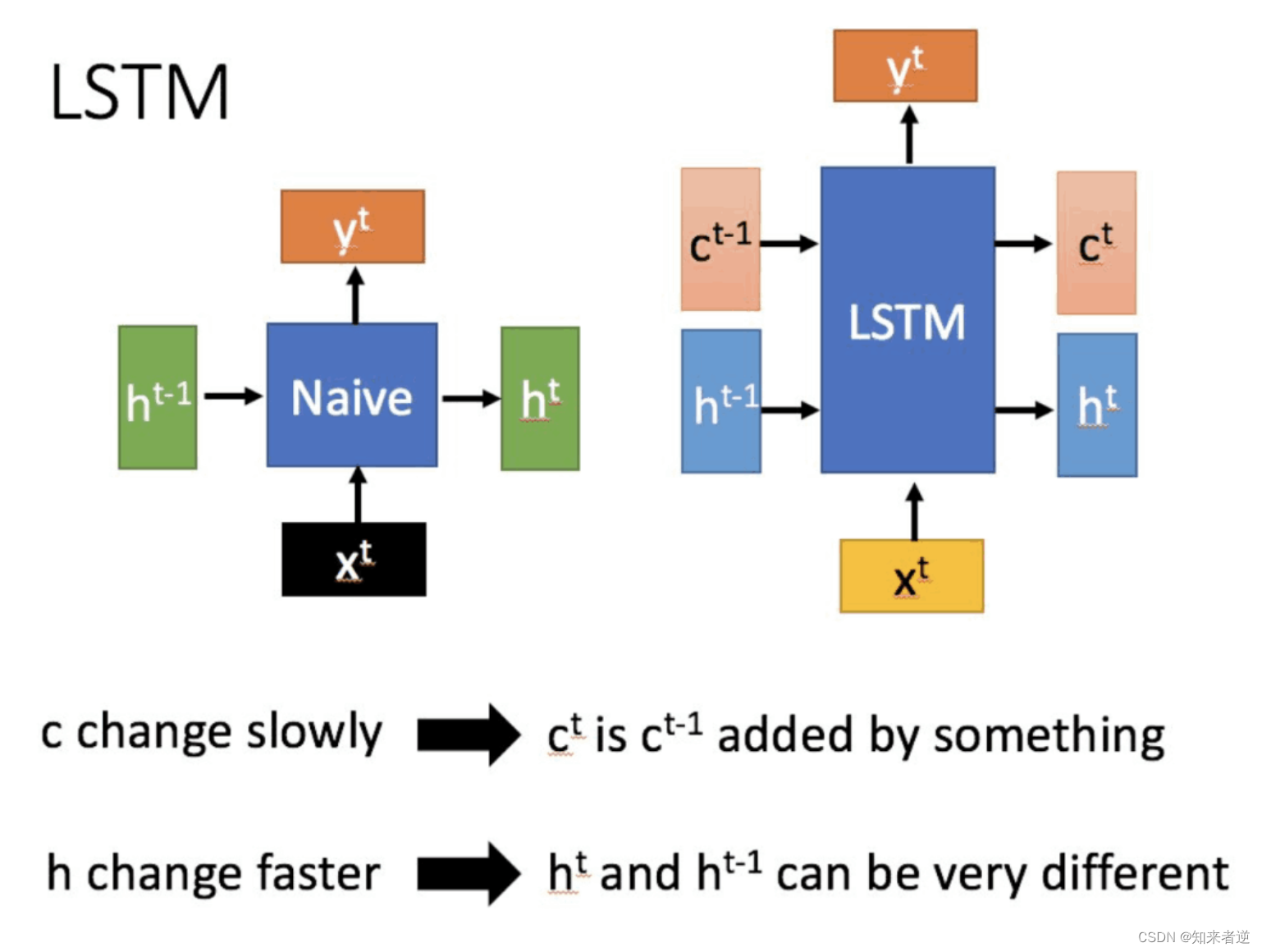
2. LSTM网络结构
右边是LSTM,与左边RNN的比较:
相比RNN只有一个传递状态 ht ,LSTM有两个传输状态,一个 ct(cell state),和一个 ht(hidden state)。RNN中的 ht等价于LSTM中的ct。其中对于传递下去的 改变得很慢,通常输出的 是上一个状态传过来的 加上一些数值。而ht则在不同节点下往往会有很大的区别。
未完待续