对于数据库整体的性能问题,AWR的报告是一个非常有用的诊断工具。
一般来说,当检测到性能问题时,会收集覆盖了发生问题的时间段的AWR报告。但是最好只收集覆盖1个小时时间段的AWR报告-如果时间过长,那么AWR报告就不能很好的反映出问题所在。 还应该收集一份没有性能问题的时间段的AWR报告,作为一个参照物来对比有问题的时间段的AWR报告。这两个AWR报告的时间段应该是一致的,比如都是半个小时的,或者都是一个小时的。
在处理性能问题时,最关注的是数据库正在等待什么。 当进程因为某些原因不能进行操作时,它需要等待。花费时间最多的等待事件是我们最需要关注的,因为降低它,我们能够获得最大的好处。
top event
AWR报告中的"Top 10 Timed Events"部分就提供了这样的信息,可以只关注主要的问题。
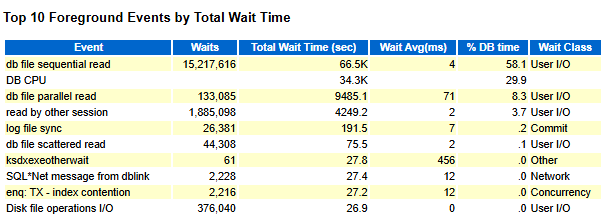
Top 10 Events部分包含了一些跟Events(事件)相关的信息。它记录了这期间遇到的等待的总次数,等待所花费的总时间,每次等待的平均时间;这一部分是按照每个Event占总体call time的百分比来进行排序的。
根据Top 10 Events部分的信息的不同,接下来需要检查AWR报告的其他部分,来验证发现的问题或者做定量分析。
等待事件需要根据报告期的持续时间和当时数据库中的并发用户数进行评估。如:10分钟内1000万次的等待事件比10个小时内的1000万等待更有问题;10个用户引起的1000万次的等待事件比 10,000个用户引起的相同的等待要更有问题。
就像上面的例子,将近60%的时间是在等待IO相关的事件。
事件"db file sequential read"一般是由不能做多块读的操作引起的单块读(如读索引),属于逻辑读。
事件"db file parallel read"一般是由并行I/O请求的操作引起的多块读,属于物理读。
其他30%的时间是花在使用或等待CPU time上。过高的CPU使用经常是性能不佳的SQL引起的(或者这些SQL有可能用更少的资源完成同样的操作);对于这样的SQL,过多的IO操作也是一个症状。
在以上基础上,将调查是否这个等待事件是有问题的。若有问题,解决它;若是正常的,检查下个等待事件。
过多的IO相关的等待一般会有两个主要的原因:
1.数据库做了太多的读操作
2.每次的IO读操作都很慢
3.是否数据库做了大量的读操作: 上面的图显示了在这段时间里顺序读操作大于1500万,这些操作是否过多取决于报告的时间是1小时或1分钟。可以检查AWR报告的elapsed time。
如果这些读操作确实是太多了,接下来需要检查AWR报告中 部分的信息,因为读操作都是由SQL语句发起的。
4.是否是每次的IO读操作都很慢: 上面的图显示了在这段时间里顺序读操作平均的等待时间是小于4ms的, 至于4ms是快还是慢取决于底层的硬件设备;一般来讲小于20ms的都可以认为是可以接受的。
其他IO相关信息
还可以在AWR报告"Tablespace IO Stats"部分得到更详细的信息
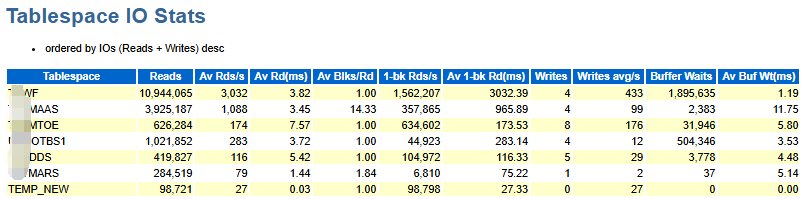
如上图,Av Rd(ms)的指标。如果它高于20ms并且同时有很多读操作的,可能要开始从OS的角度调查是否有潜在的IO问题。
注:对于一些比较空闲的tablespace/files,例如users表空间,可能会得到一个比较大的Av Rd(ms)值;对于这样的情况,我们应该忽略这样的tablespace/files;因为这个很大的值可能是由于硬盘自旋(spin)引起的,没有太大的参考意义。比如对于一个有1500万次读操作而且很慢的系统,引起问题的基本不可能是一个只有几百次read的tablespace/file。
分析过程
虽然高"db file sequential read"等待可以是I/O相关的问题,但是很多时候这些等待也可能是正常的;实际上,对一个已经性能很好的数据库系统,这些等待事件往往在top 10等待事件里,因为这意 味着您的数据库没有那些真正的“问题”。
诀窍是能够评估引起这些等待的语句是否使用了最优的访问路径。如果"db file sequential read"过多,则表明也许是这些SQL语句使用了selectivity不高的索引从而导致访问了过多不必要的索引块或者使用了错误的索引。这些等待可能说明SQL语句的执行计划不是最优的。
top sql
接下来就需要通过AWR来检查这些top SQL是否可以进一步的调优,可以查看AWR报告中 SQL Statistics 的部分.
上面的例子显示了30%的时间花在了等待或者使用CPU上,也需要检查 SQL statistics 部分来进一步的分析。 需要注意,接下来的分析步骤取决于我们在TOP 10部分的发现。在上面的例子里,1个top wait event表明问题可能与SQL语句执行计划不好有关,所以接下来要去分析"SQL Statistics"部分。
同样的,因为并没有看到latch相关的等待,latch在这个例子里并没有引发严重的性能问题;那么接下来就完全不需要分析latch相关的信息。
一般来讲,如果数据库性能很慢,TOP 10等待事件里"CPU", "db file sequential read" 和"db file scattered read" 比较明显(不管它们之间的顺序如何),是需要检查Top SQL (by logical and physical reads)部分;调用SQL Tuning Advisor或者手工调优这些SQL来确保它们是有效率的运行。
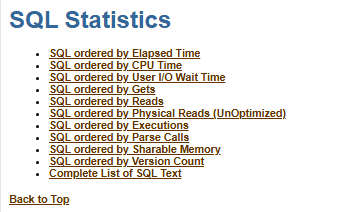
根据Top 10 部分的Top Wait Event不同,需要检查不同的SQL statistic。
这个例子里,Top Wait Event是"db file sequential read"和CPU;因此最需要关心的是SQL ordered by CPU Time, Gets。
应该从"SQL ordered by gets"入手,因为引起高buffer gets的SQL语句一般是需要调优的对象。
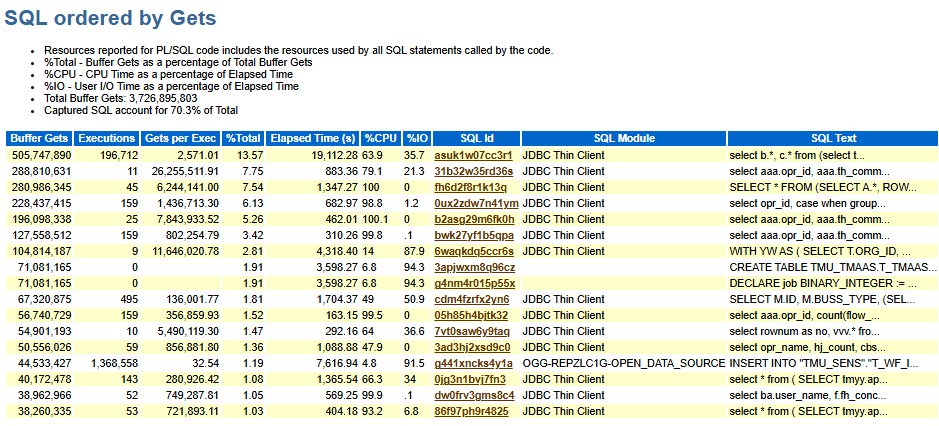
分析过程
-> Total Buffer Gets: 3,726,895,803 这是一个一个小时的AWR报告,3,726,895,803是一个很大的值;所以需要进一步分析这个SQL是否使用了最优的执行计划
-> Individual Buffer Gets 上面的例子里单个的SQL的buffer get非常多,最少的那个都是1亿。这几个SQL指向了两个不同的引起过多buffers的原因: 1.单次执行buffer gets过多 SQL_ID为'31b32w35rd36s'和'fh6d2f8r1k13q'、'b2asg29m6fk0h'的SQL语句总共被执行了81次,但是每次执行引起的buffer gets超过7.6亿。这几个SQL应该是主要的需要调优的候选者。
2.执行次数过多 SQL_ID 'asuk1w07cc3r1' 每次执行只是引起2,571次buffer gets,减少这条SQL每次执行的buffer get可能并不能显著减少总共的buffer gets。这条语句的问题是它执行的太频繁了,19万次。 SQL_ID 'g441xncks4y1a' 每次执行只是引起32次buffer gets,减少这条SQL每次执行的buffer get可能并不能显著减少总共的buffer gets。这条语句的问题也是它执行的太频繁了,136万次。
改变这两条SQL的执行次数可能会更有意义。第一个SQL看起来是在一个循环里面被调用,如果可以让它一次处理的数据更多也许可以减少它执行的次数。第二个是ogg的插入语句,可以修改ogg的相关参数让它一次性插入更多的数据。
注意:对于某些非常繁忙的系统来讲,以上的数字可能都是正常的。这时候需要把这些数字跟正常时段的数字作对比,如果没有什么太大差别,那么这些SQL并不是引起问题的元凶(虽然通过调优这些SQL仍然可以受益)。
其他信息
AWR报告中有很多不同的部分用来分析各种不同的问题。如果特定的问题并没有出现,那么分析 AWR报告的这些部分并不能有很大的帮助。 下面的信息可能会提到一些可能的问题,这些都是需要具体问题具体分析。
load profile
根据Top等待事件的不同,"Load Profile"可以提供一些有用的背景资料或潜在问题的细节信息。
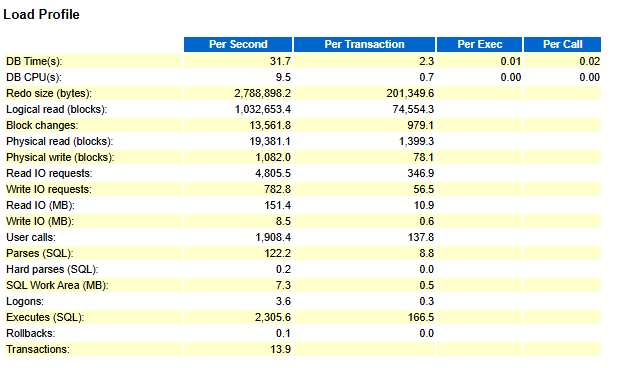
如果检查AWR report是为了一般性的性能调优,那么可以看Redo size 和physical writes.
此外,hard parse的次数要少于soft parse.
如果mutex等待事件比较严重,如"library cache: mutex X",那么查看所有parse的比率会更有用。
把Load Profile部分跟正常时候的AWR报告做比较会更有用,比如,比较redo size, users calls, 和 parsing这些性能指标。
Instance Efficiency Percentages

从我们的这个例子来看,最有用的信息是%Non-Parse CPU,它表明几乎所有的CPU都消耗在了Execution而不是Parse上,所以调优SQL会对性能有改善。
99.82% 的soft parse比率显示hard parse的比例很小,这是可取的。
Execute to Parse %只有94%,说明cursor重用不是很好,也侧面说明了top event的"db file sequential read"过多,表明这些SQL语句使用了selectivity不高的索引从而导致访问了过多不必要的索引块或者使用了错误的索引。
我们总是期望这里的值都是接近100%,但是因为应用的不同,如果这个部分的参数的某些值很小,也是可以认为没有问题的;如在数据仓库环境,hard parse因为使用了物化视图或histogram而变得很高。所以,重要的是,需要把这部分信息和正常时候的AWR报告做比较来判断是否有问题。
Latch Activity
在这个例子里,并没有看到很高的latch相关的等待,所以这部分的信息可以忽略。
但是如果latch相关的等待很严重,我们需要查看Latch Sleep Breakdown 部分sleeps很高的latch。
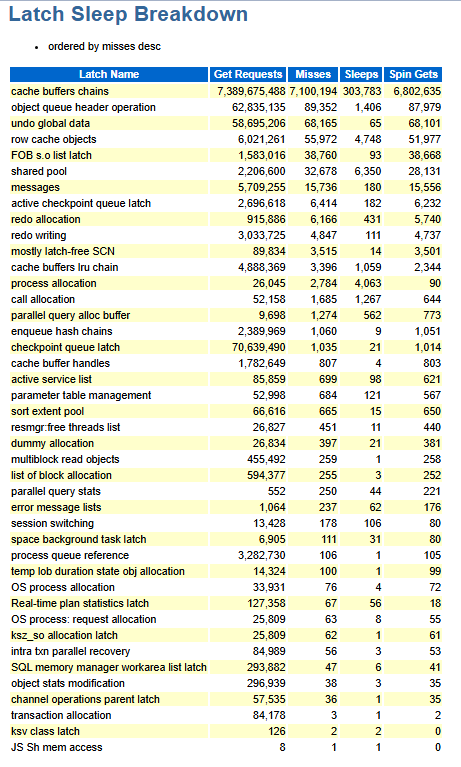
这里top latch是cache buffers chains. Cache Buffers Chains latches是用来保护buffer caches中的buffers。在读取数据时,这个latch是正常需要获得的。Sleep的数字上升代表session在读取buffers时开始等待这个latch。争用通常来自于不良的SQL要读取相同的buffers。
在这个例子里,虽然读取buffer的操作发生了73亿次,但是只sleep了303,783次,可以认为是比较低的。AvgSlps/Miss(Sleeps/ Misses)也比较低。这表明当前Server有能力处理这样多的数据,所以没有发生Cache BuffersChains latch的争用。
这里可以提一下最高sleeps的latch -- cache buffers chains
在Oracle数据库中,"cache buffers chains" 是一个用于管理缓冲区的机制。缓冲区是内存中的区域,用于存储数据块的副本,以便在需要时快速读取或写入数据。
定义
-
Hash Chain 结构:Oracle 使用一个内部的哈希算法将所有的缓冲区分配到不同的哈希桶(Hash Bucket)中。每个哈希桶中包含一个哈希链表(Hash Chain List),也称为 "cache buffers chain"。这个链表通过缓冲区头(Buffer Header)将缓冲区连接起来。 -
Buffer Header:缓冲区头包含数据块的概要信息,如文件号、块地址、状态等。
引发的等待事件 "latch: cache buffers chains"
-
原因:当多个会话同时访问或修改同一个缓冲区时,Oracle 会使用 "cache buffers chains" 互斥体(Latch)来确保数据的一致性和完整性。如果多个进程同时尝试访问同一个哈希链表中的缓冲区,就会发生竞争,导致 "latch: cache buffers chains" 等待事件。 -
常见场景: -
高并发访问相同数据块:多个会话同时访问相同的数据块。 -
热点块或热点链:某个缓冲区或哈希链表被频繁访问。
-
解决方法
-
优化SQL语句:减少对热点数据块的访问频率。 -
增加缓冲区大小:通过增加缓冲区的大小来减少对同一个缓冲区的竞争。 -
调整哈希桶数量:通过调整哈希桶的数量来分散竞争。
这些措施可以帮助减少 "latch: cache buffers chains" 等待事件的发生,从而提高数据库的性能.
值得注意的wait events
CPU time events
CPU变为top wait event并不总是代表出现了问题。但是如果同时数据库性能比较慢,那么就需要进一步分析了。首先,检查AWR报告的“ SQL ordered by CPU Time ”部分,看是否某个特定的SQL使用了大量的CPU。
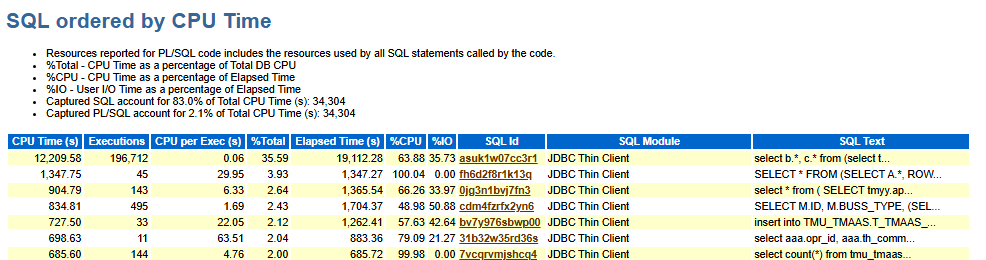
分析过程
-> Total CPU Time (s): 34,304
它代表CPU time。但是这个数字是否有问题取决于整个报告的时间。
Top SQL使用的CPU是 12,209秒,整个CPU时间占DB Time的35.59%,执行了196,712次。
采取措施
一旦确定了使用最高 CPU 的 SQL 语句,请调查这种使用的原因。 查看执行次数,看看这是否适合该语句。 过多的执行可能表明该语句被过于频繁地调用,并且可能为一组行而不是逐行执行它(比如批量执行它)。 每次执行的 CPU 量是否过多,这可能表明语句本身效率低下。 此外,请查看 AWR 报告中的其他 SQL 统计信息,以查看所讨论的 SQLID 是否显示任何这些值的过多值,然后适当地处理该语句。
其他潜在的CPU相关的问题
1.检查是否有其他等待事件与高CPU 事件同时出现 如cursor: pin S问题可能引起高CPU使用:High CPU usage when there are "cursor: pin S" waits
2.数据库以外的CPU使用率过高 如果一个数据库以外的进程使用了过多CPU,那么数据库进程能够获得的CPU就会减少,数据库性能就会受到影响。在这种情况下,运行OSWather或者其他的OS工具去发现是哪个进程使用了过多CPU
3.诊断CPU使用率
1.High CPU Utilization 'Log file sync' waits
当一个user session commit或rollback时,log writer进程会把redo从log buffer中写入redo logfile文件。AWR报告会帮助我们来确定是否存在这方面的问题,并且确认是否是由物理IO引起。如果”log file sync”事件比较严重。
2.Buffer busy waits 当一个session从buffer cache读取一个buffer时,如果这个buffer处于busy的状态(由于其它session正在向其中读取数据,或者是由于这个buffer被 其它的session以不兼容模式持有),那么这个session就会等待这个事件。
3.Waits for 'Cursor: mutex/pin' 如果发现了一些像"Cursor: pin S wait on X" 或"Cursor: mutex X" 类的mutex等待,那么可能是由于parsing引起的问题。检查"SQL ordered by Parse Calls" 和"SQL ordered by Version Count"部分的Top SQL,这些SQL可能引起这类的问题。
本文由 mdnice 多平台发布