完整代码:(数据处理部分)
# 代码6-1
import pandas as pd
data_raw = pd.read_csv('media_index.csv', encoding='gbk', header='infer')
payevents = pd.read_csv('mmconsume_payevents.csv', sep=',',
encoding='gbk', header='infer')
print(data_raw.shape, payevents.shape)
# 代码6-2
media = pd.read_csv('media_index.csv', encoding='gbk', header='infer')
# 将“-高清”替换为空
media['station_name'] = media['station_name'].str.replace('-高清', '')
# 过滤特殊线路、政企用户
media = media.loc[(media.owner_code != 2)&(media.owner_code != 9)&
(media.owner_code != 10), :]
print('查看过滤后的特殊线路的用户:', media.owner_code.unique())
media = media.loc[(media.owner_name != 'EA级')&(media.owner_name != 'EB级')&
(media.owner_name != 'EC级')&(media.owner_name != 'ED级')&
(media.owner_name != 'EE级'), :]
print('查看过滤后的政企用户:', media.owner_name.unique())
# 对开始时间进行拆分
# 检查数据类型
type(media.loc[0, 'origin_time'])
# 转化为时间类型
media['end_time'] = pd.to_datetime(media['end_time'])
media['origin_time'] = pd.to_datetime(media['origin_time'])
# 提取秒
media['origin_second'] = media['origin_time'].dt.second
media['end_second'] = media['end_time'].dt.second
# 筛选数据
ind1 = (media['origin_second'] == 0) & (media['end_second'] == 0)
media1 = media.loc[~ind1, :]
# 基于开始时间和结束时间的记录去重
media1.end_time = pd.to_datetime(media1.end_time)
media1.origin_time = pd.to_datetime(media1.origin_time)
media1 = media1.drop_duplicates(['origin_time', 'end_time'])
# 隔夜处理
# 去除开始时间,结束时间为空值的数据
media1 = media1.loc[media1.origin_time.dropna().index, :]
media1 = media1.loc[media1.end_time.dropna().index, :]
# 创建星期特征列
media1['星期'] = media1.origin_time.apply(lambda x: x.weekday()+1)
dic = {1:'星期一', 2:'星期二', 3:'星期三', 4:'星期四', 5:'星期五', 6:'星期六', 7:'星期日'}
for i in range(1, 8):
ind = media1.loc[media1['星期'] == i, :].index
media1.loc[ind, '星期'] = dic[i]
# 查看有多少观看记录是隔天的,隔天的进行隔天处理
a = media1.origin_time.apply(lambda x :x.day)
b = media1.end_time.apply(lambda x :x.day)
sum(a != b)
media2 = media1.loc[a != b, :].copy() # 需要做隔天处理的数据
def geyechuli_xingqi(x):
dic = {'星期一':'星期二', '星期二':'星期三', '星期三':'星期四', '星期四':'星期五',
'星期五':'星期六', '星期六':'星期日', '星期日':'星期一'}
return x.apply(lambda y: dic[y.星期], axis=1)
media1.loc[a != b, 'end_time'] = media1.loc[a != b, 'end_time'].apply(lambda x:
pd.to_datetime('%d-%d-%d 23:59:59'%(x.year, x.month, x.day)))
media2.loc[:, 'origin_time'] = pd.to_datetime(media2.end_time.apply(lambda x:
'%d-%d-%d 00:00:01'%(x.year, x.month, x.day)))
media2.loc[:, '星期'] = geyechuli_xingqi(media2)
media3 = pd.concat([media1, media2])
media3['origin_time1'] = media3.origin_time.apply(lambda x:
x.second + x.minute * 60 + x.hour * 3600)
media3['end_time1'] = media3.end_time.apply(lambda x:
x.second + x.minute * 60 + x.hour * 3600)
media3['wat_time'] = media3.end_time1 - media3.origin_time1 # 构建观看总时长特征
# 清洗时长不符合的数据
# 剔除下次观看的开始时间小于上一次观看的结束时间的记录
media3 = media3.sort_values(['phone_no', 'origin_time'])
media3 = media3.reset_index(drop=True)
a = [media3.loc[i+1, 'origin_time'] < media3.loc[i, 'end_time'] for i in range(len(media3)-1)]
a.append(False)
aa = pd.Series(a)
media3 = media3.loc[~aa, :]
# 去除小于4S的记录
media3 = media3.loc[media3['wat_time'] > 4, :]
# 保存贴标签用
media3.to_csv('media3.csv', na_rep='NaN', header=True, index=False)
# 查看连续观看同一频道的时长是否大于3h
# 发现这2000个用户不存在连续观看大于3h的情况
media3['date'] = media3.end_time.apply(lambda x :x.date())
media_group = media3['wat_time'].groupby([media3['phone_no'],
media3['date'],
media3['station_name']]).sum()
media_group = media_group.reset_index()
media_g = media_group.loc[media_group['wat_time'] >= 10800, ]
media_g['time_label'] = 1
o = pd.merge(media3, media_g, left_on=['phone_no', 'date', 'station_name'],
right_on=['phone_no', 'date', 'station_name'], how='left')
oo = o.loc[o['time_label'] == 1, :]
# 代码6-3
payevents = pd.read_csv('mmconsume_payevents.csv', sep=',',
encoding='gbk', header='infer')
payevents.columns = ['phone_no', 'owner_name', 'event_time', 'payment_name',
'login_group_name', 'owner_code']
# 过滤特殊线路、政企用户
payevents = payevents.loc[(payevents.owner_code != 2
)&(payevents.owner_code != 9
)&(payevents.owner_code != 10), :] # 去除特殊线路数据
print('查看过滤后的特殊线路的用户:', payevents.owner_code.unique())
payevents = payevents.loc[(payevents.owner_name != 'EA级'
)&(payevents.owner_name != 'EB级'
)&(payevents.owner_name != 'EC级'
)&(payevents.owner_name != 'ED级'
)&(payevents.owner_name != 'EE级'), :]
print('查看过滤后的政企用户:', payevents.owner_name.unique())
payevents.to_csv('payevents2.csv', na_rep='NaN', header=True, index=False)
了解项目背景
1、随着科技的发展,现在人们观看电视节目的方式越来越多,给人们带了很多便利。人们不仅可以使用传统的电视机观看电视节目,而且可以通过网络观看电视节目,这样使得运营商、用户、网络之间产生了一些交互关系。为了更改的为用户提供服务,并提高收益和收视率,需要对广电数据进行分析。
2、目前某广播电视网络运营集团已建成完整覆盖广东省各区(县级市)的有线传输与无线传输互为延伸、互为补充的广电宽带信息网络,实现了城区全程全网的双向覆盖,为广大市民提供有线数字电视、互联网接入服务、高清互动电视、移动数字电视、手机电视、信息内容集成等多样化、跨平台的信息服务。
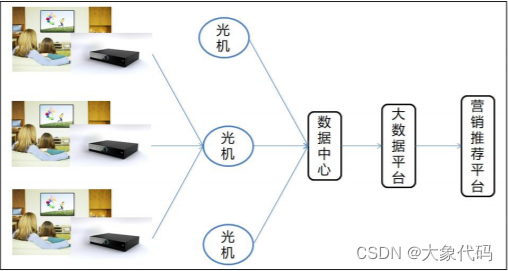
3、每个家庭收看电视节目都需要通过机顶盒进行收视节目的接收和交互行为(如点播行为、回看行为)的发送,并将交互行为数据发送至每个区域的光机设备(进行数据传递的中介),光机设备会汇集该区域的信息数据,再发送至数据中心进行整合、存储。信息数据的收集过程如图所示。
4、由于已建成的大数据平台积累了大量用户基础信息和用户观看记录信息等数据,所以在此基础上进一步挖掘出数据价值,可以提升客户体验,并提出精准的营销建议,采取有效应对措施,实现增加用户黏度,从而使用户与企业之间建立稳定交互关系,实现客户链式反应增值。
熟悉数据情况
1、在大数据平台中存有用户的基础信息(安装地址等)、订单数据(产品订购、退订信息)、工单数据(报装、故障、投诉、咨询等工单信息)、收费数据(缴费、托收等各渠道支付信息)、账单数据(月租账单收入数据)、双向互动电视平台收视行为数据(直播、点播、回看、广告的收视数据)、用户上网设备的指标状态数据(上下行电平、信噪比、流量等),共7种数据。
2、由于每个用户收视习惯、兴趣爱好存在差异性,本次抽取了2000个样本用户在2018年5月12日至2018年6月12日的收视行为信息数据和收费数据,并对两份数据表进行脱敏处理。
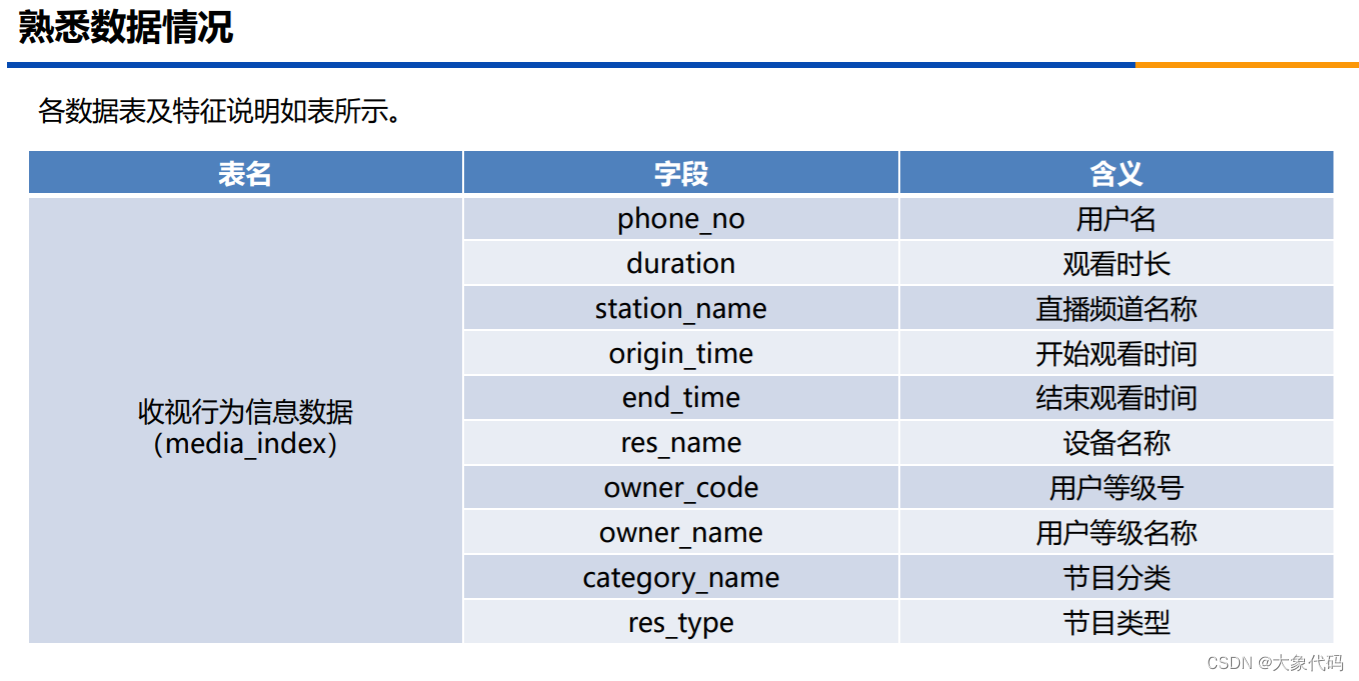
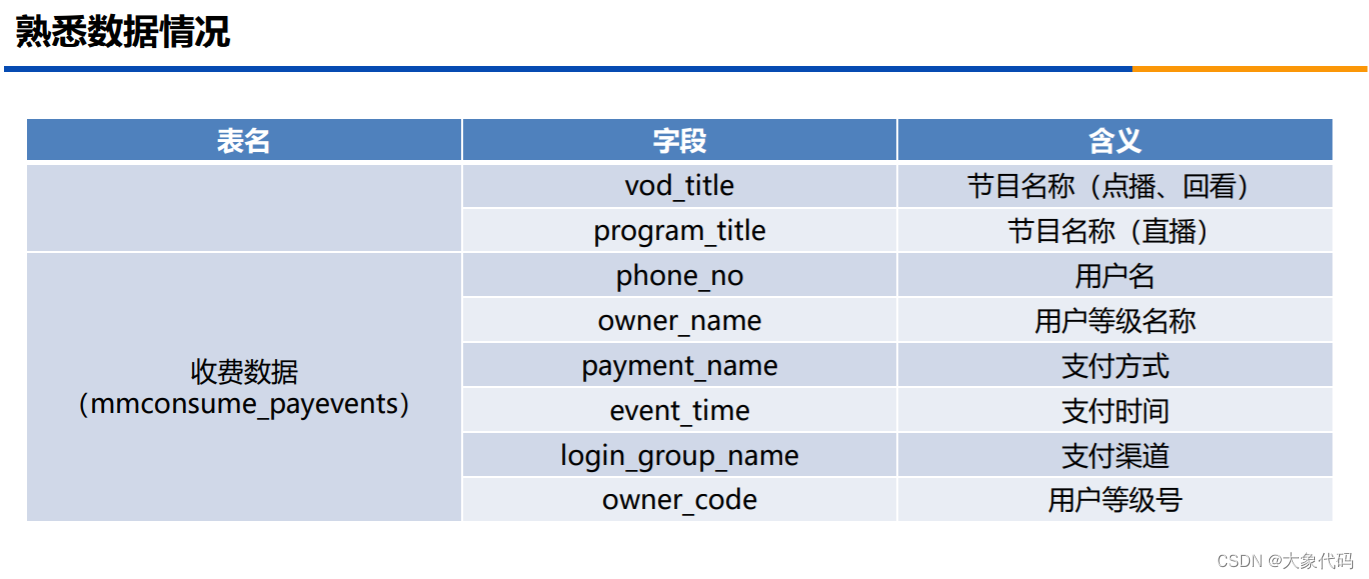
3、各数据表及特征说明如表所示。
熟悉项目流程
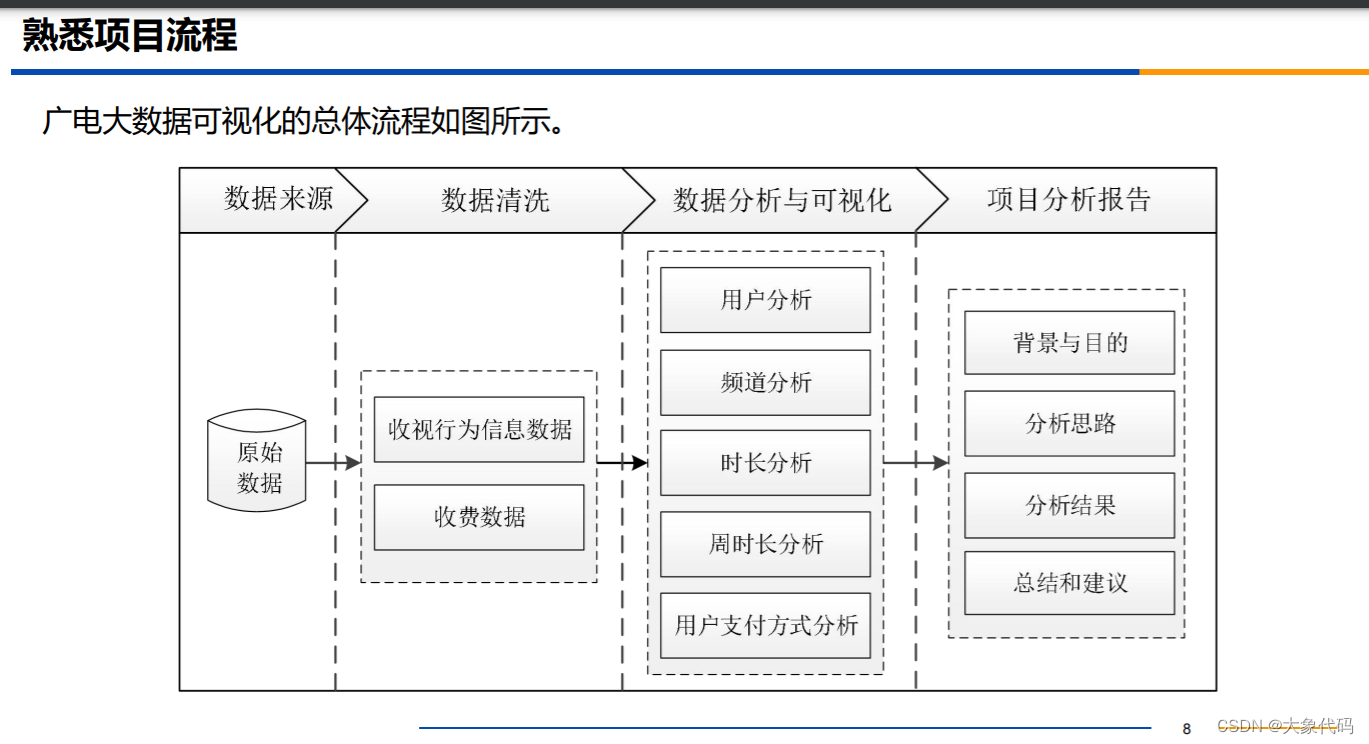
如何将丰富的电视产品与用户个性化需求实现最优匹配,是广电行业急需解决的重要问题。用户对电视产品的需求不同,在挑选搜寻想要的信息过程中,需要花费大量的时间,这种情况的出现造成了用户的不断流失,对企业造成巨大的损失。广电大数据可视化的主要步骤如下。
1、抽取2000个用户在2018年5月12日至2018年6月12日的收视行为信息数据和收费数据
2、对抽取的数据进行数据清洗
3、对清洗后的数据进行可视化分析,包括用户分析、频道分析、时长分析、周时长分析和用户支付方式分析等
4、撰写项目分析报告
 读取与处理广播电视数据
读取与处理广播电视数据
读取数据
1、在项目的原始数据中可能会出现部分噪声数据,如重复值、异常值、冗余数据等,将会对后续的可视化分析结果造成影响。因此,需要在Python中读取广播电视数据,并对数据进行清洗。
2、通过pandas库中的read_csv()函数读取用户收视行为数据和收费数据。结果如表所示。

清洗数据
1、通过读取数据的运行结果可知,用户收视行为数据和收费数据存在的数据量相对较多,其中可能存在一定的缺失值、异常值等数据,且不同的数据存在的问题可能会不一致。
2、因此需要根据不同数据中存在的不同情况,分别对行为信息数据和收费数据进行清洗处理 。
1、收视行为信息数据
1、在用户的收视行为信息数据(media_index)中存在直播频道名称(station_name)中含有“-高清”字段,如“江苏卫视-高清”与“江苏卫视”等。由于本项目中暂不分开考虑是否为高清频道的情况,所以需要将直播频道名称中“-高清”字段替换为空。“广州电视”与“广州电视-高清”
2、从业务角度分析,该广电运营商主要面向的对象是众多的普通家庭,而收视行为信息数据中存在特殊线路和政企类的用户,即用户等级号(owner_code)为02、09、10的数据与用户等级名称(owner_name)为EA级、EB级、EC级、ED级、EE级的数据。因为特殊线路主要是起到演示、宣传等作用,这部分数据对于分析用户行为意义不大,并且会影响分析结果的准确性,所以需要将这部分数据删除。而政企类数据暂时不做分析,同样也需要删除。
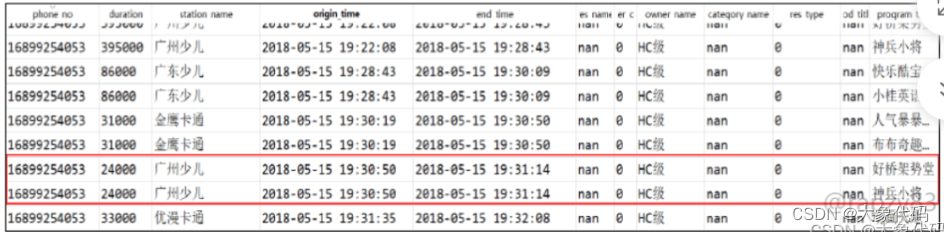
3、在收视行为信息数据中存在有同一用户开始观看时间(origin_time)结束观看时间(end_time)重复的记录数据,而且观看的节目不同,如图所示,这可能是由于数据收集设备导致的。经过与广电运营商的业务人员沟通之后,默认保留第一条收视记录,因此需要基于数据中开始观看时间(origin_time)和结束时间(end_time)的记录进行去重。
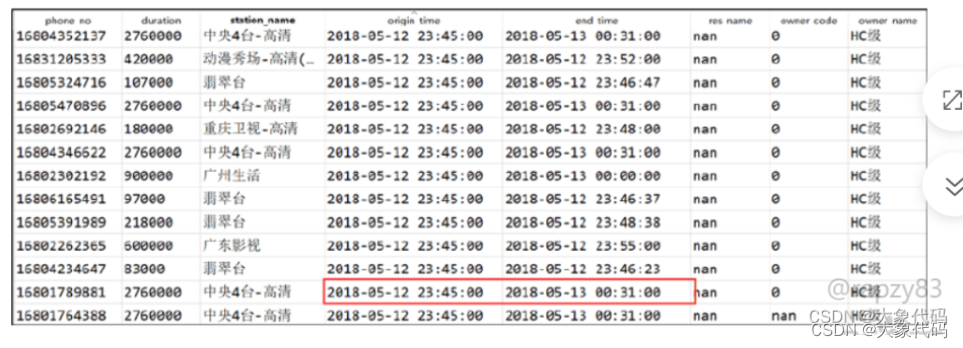
4、在收视行为信息数据中存在跨夜的记录数据,如开始观看时间和结束观看时间分别为05-12 23:45:00和05-13 00:31:00,如图所示。
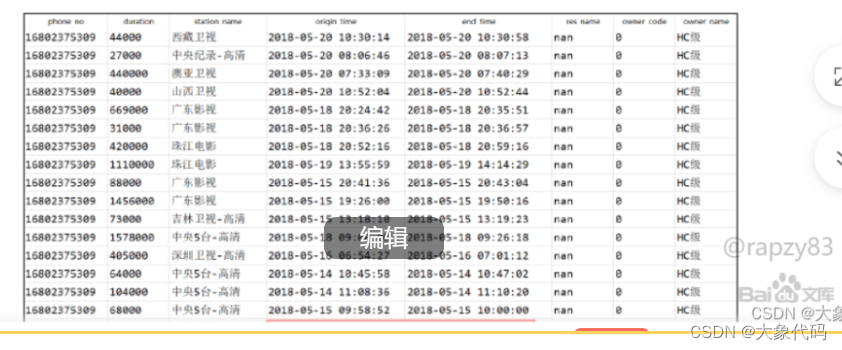
7、最后,发现数据有下次观看的开始观看时间小于上一次观看的结束观看时间的记录,这种异常数据的产生是由于数据收集设备异常导致的,需要进行删除处理
8、综合上述业务数据处理方法,清洗收视行为信息数据的具体步骤如下。
- 将直播频道名称(station_name)中“-高清”替换为空
- 删除特殊线路的用户,用户等级号(owner_code)为02、09、10的数据
- 删除政企用户,用户等级名称(owner_name)为EA级、EB级、EC级、ED级、EE级的数据
- 基于数据中开始观看时间(origin_time)和结束观看时间(end_time)的记录去重
- 隔夜处理,将跨夜的收视数据分成两天即两条收视数据
- 删除观看同一频道累计连续观看小于4秒的记录
- 删除直播收视数据中开始观看时间和结束时间的单位秒为00的收视数据
- 删除下次观看记录的开始观看时间小于上一次观看记录的结束观看时间的记录
代码:3分钟左右
# 读取数据
import pandas as pd
data_xin = pd.read_csv('media_index.csv', encoding='gbk', header='infer')
data_shou = pd.read_csv('mmconsume_payevents.csv', sep=',',encoding='gbk', header='infer')
#GBK编码是中文编码,UTF-8编码是多字符集编码,支持多国语言
#header:是否将原数据集中的第一行作为表头,默认是,并将第一行作为变量名称:如果原始数据中没有表头,该参数需要设置成None
# header='infer'默认以第一行作为标题, header=None不要以第一行作为标题
# sep分隔符。 csv文件的分隔符就是,可以默认。
print(data_xin.shape,data_shou.shape)#shape:读取矩阵或数组的长度
# 信息数据
# 1、将“-高清”替换为空
data_xin['station_name'] = data_xin['station_name'].str.replace('-高清', '')
#一.replace():替换函数
#基本用法:对象.replace(rgExp,replaceText,max)
#其中,rgExp和replaceText是必须要有的,max是可选的参数,可以不加。
#rgExp是指 String 对象或文字;replaceText是一个String 对象或字符串文字;max是一个数字。
# 对于一个对象,在对象的每个rgExp都替换成replaceText,从左到右最多max次。
# 2、过滤特殊线路、政企用户
media = data_xin.loc[(data_xin.owner_code != 2)&(data_xin.owner_code != 9)&(data_xin.owner_code != 10), :]
print('查看过滤后的特殊线路的用户:', media.owner_code.unique())
media = media.loc[(media.owner_name != 'EA级')&(media.owner_name != 'EB级')&
(media.owner_name != 'EC级')&(media.owner_name != 'ED级')&
(media.owner_name != 'EE级'), :]
print('查看过滤后的政企用户:', media.owner_name.unique())
#data.loc[(data['A']==0)&(data['B']==2)] #提取data数据(多个筛选条件)
#data.loc[:,:]:提取所有数据
#unique():去除其中重复的元素,并按元素由大到小返回一个新的无元素重复的元组或者列表
#第三步的前提操作
# 对开始时间进行拆分
# 检查数据类型:origin_time:开始观看时间
time = media.loc[0, 'origin_time']#取“origin_time”列中的第一个数
type(time)#type:类型
#loc就是location,而iloc就是integer location。顾名思义,后者参数只能是整数。
#.loc先行后列,中间用逗号(,)分割,例如取 a 和 A 对应的数据:df.loc['a','A']
#----------------------------------------------------------------
# 转化为时间类型:Pandas日期数据处理函数 to_datetime()
# 将时间格式的字符串转换为标准的时间
media['end_time'] = pd.to_datetime(media['end_time'])
media['origin_time'] = pd.to_datetime(media['origin_time'])
#to_datetime函数可以用来批量处理日期数据转换,可以将日期数据转换成你需要的各种格式
#----------------------------------------------------------------
# 提取秒
#提取时间中的秒,将其赋给新列秒
#dt:日期时间数据
#python的日期抽取:dt.hour、dt.minute、dt.second、dt.microsecond:获取时、分、秒、微秒
media['origin_second'] = media['origin_time'].dt.second
media['end_second'] = media['end_time'].dt.second
# 筛选数据
#“~”符号在这里是取反的意思,表示对 df[col].isin(list) 这句返回的值取反
a = (media['origin_second'] == 0) & (media['end_second'] == 0)
media1 = media.loc[~a, :]#所有的列
# 3、基于开始时间和结束时间的记录去重
# to_datetime:将时间格式的字符串转换为标准的时间
#drop_duplicates 是 pandas 库中的一个函数,用于删除数据框中的重复行。
# 该函数默认会对整个数据框进行重复行的删除,也可以通过指定特定的列来确定重复行。
media1.end_time = pd.to_datetime(media1.end_time)
media1.origin_time = pd.to_datetime(media1.origin_time)
media1 = media1.drop_duplicates(['origin_time', 'end_time'])
# 第四步的前提处理:隔夜处理
# 去除开始时间,结束时间为空值的数据
#Python处理数据中的空值(缺失值)时用到的dropna()函数
#index:索引
media1 = media1.loc[media1.origin_time.dropna().index, :]
media1 = media1.loc[media1.end_time.dropna().index, :]
# 创建星期特征列
#lambda函数也叫匿名函数
#apply():当一个函数的参数存在于一个元组或者一个字典中时,用来间接的调用这个函数,并肩元组或者字典中的参数按照顺序传递给参数
#datetime.weedak()方法的返回值为[0,6]之间的整数,分别代表周一到周日
media1['星期'] = media1.origin_time.apply(lambda x: x.weekday()+1)
rq = {1:'星期一', 2:'星期二', 3:'星期三', 4:'星期四', 5:'星期五', 6:'星期六', 7:'星期日'}#字典
for i in range(1, 8):#表示从1到9循环遍历,每次循环的变量名为i
# 筛选出数据框 media1 中星期为 i 的行,并返回这些行的索引。其中的 : 表示返回所有列的数据
xq = media1.loc[media1['星期'] == i, :].index
#这行代码是在 Pandas 库中的 DataFrame 对象 media1 的 xq 行的“星期”列中插入 rq 列表中第 i 个元素的值。
# 具体来说,它是在 DataFrame 的 xq 行的“星期”列中将值设置为 rq[i]
media1.loc[xq, '星期'] = rq[i]
# 4、查看有多少观看记录是隔天的,隔天的进行隔天处理
#象 media1 中 origin_time 列的日期取出来,并转换为 day(即日期中的天数)的操作
b = media1.origin_time.apply(lambda x :x.day)
c = media1.end_time.apply(lambda x :x.day)
sum(b != c)
# copy()浅度复制:复制的数会随着被复制数的嵌套序列的元素的改变而改变;功能:将一个列表复制给另一个列表
media2 = media1.loc[b != c, :].copy() # 需要做隔天处理的数据
def geyechuli(x):
dic = {'星期一':'星期二', '星期二':'星期三', '星期三':'星期四', '星期四':'星期五',
'星期五':'星期六', '星期六':'星期日', '星期日':'星期一'}
#axis=0 表示按照行的方向;axis=1 表示按照列的方向
return x.apply(lambda y: dic[y.星期], axis=1)
media1.loc[b != c, 'end_time'] = media1.loc[b != c, 'end_time'].apply(lambda x:
pd.to_datetime('%d-%d-%d 23:59:59'%(x.year, x.month, x.day)))
media2.loc[:, 'origin_time'] = pd.to_datetime(media2.end_time.apply(lambda x:
'%d-%d-%d 00:00:01'%(x.year, x.month, x.day)))
media2.loc[:, '星期'] = geyechuli(media2)
media3 = pd.concat([media1, media2])#concat:拼接
media3['origin_time1'] = media3.origin_time.apply(lambda x:
x.second + x.minute * 60 + x.hour * 3600)
media3['end_time1'] = media3.end_time.apply(lambda x:
x.second + x.minute * 60 + x.hour * 3600)
media3['wat_time'] = media3.end_time1 - media3.origin_time1 # 构建观看总时长特征
# 清洗时长不符合的数据
# 6、剔除下次观看的开始时间小于上一次观看的结束时间的记录
#sort_values()将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
#phone_no:用户名
media3 = media3.sort_values(['phone_no', 'origin_time'])
#resert_index()函数:drop: 重新设置索引后是否将原索引作为新的一列并入DataFrame,默认为False
media3 = media3.reset_index(drop=True)
d = [media3.loc[i+1, 'origin_time'] < media3.loc[i, 'end_time'] for i in range(len(media3)-1)]
#df.append()可以将其他DataFrame附加到调用方的末尾,并返回一个新对象.它是最简单、最常用的数据合并方式
d.append(False)
e = pd.Series(d)#构造一维数组
media3 = media3.loc[~e, :]#~:相反的值;d:下次观看的开始时间小于上一次观看的结束时间的记录
# 5、去除小于4S的记录:wat_time:总时长
media3 = media3.loc[media3['wat_time'] > 4, :]
# 保存贴标签用
media3.to_csv('media3.csv', na_rep='NaN', header=True, index=False)
# 查看连续观看同一频道的时长是否大于3h
# 发现这2000个用户不存在连续观看大于3h的情况
media3['date'] = media3.end_time.apply(lambda x :x.date())
media_group = media3['wat_time'].groupby([media3['phone_no'],
media3['date'],
media3['station_name']]).sum()
media_group = media_group.reset_index()
media_g = media_group.loc[media_group['wat_time'] >= 10800, ]#3h=10800s
media_g['time_label'] = 1
o = pd.merge(media3, media_g, left_on=['phone_no', 'date', 'station_name'],
right_on=['phone_no', 'date', 'station_name'], how='left')
oo = o.loc[o['time_label'] == 1, :]结果
2、收费数据
对于收费数据(mmconsume-payevents),只需删除特殊线路和政企类的用户即可,具体步骤如下。
- 删除特殊线路的用户,用户等级号(owner_code)为02、09、10的数据
- 删除政企用户,用户等级名称(owner_name)为EA级、EB级、EC级、ED级、EE级的数据
代码:
# 收费数据
#GBK编码是中文编码,UTF-8编码是多字符集编码,支持多国语言
#header:是否将原数据集中的第一行作为表头,默认是,并将第一行作为变量名称:如果原始数据中没有表头,该参数需要设置成None
# header='infer'默认以第一行作为标题, header=None不要以第一行作为标题
# sep分隔符。 csv文件的分隔符就是,可以默认。
payevents1 = pd.read_csv('mmconsume_payevents.csv', sep=',',encoding='gbk', header='infer')
#这行代码的作用是将一个 DataFrame 中的列名重新命名为指定的列名。
#具体来说,这个 DataFrame 中包含了电话号码、所有者姓名、事件时间、支付名称、登录组名称和所有者代码等信息,
#而这行代码将这些列名依次改为了 phone_no、owner_name、event_time、payment_name、login_group_name 和 owner_code。
#这样做的好处是使得数据更加易于理解和操作,可以方便地进行数据分析和处理。
#t_aa63affcd82ddfe013a1984425829dd740d86fc4_10003630_0_1.phone_no:原列名
payevents1.columns = ['phone_no', 'owner_name', 'event_time', 'payment_name',
'login_group_name', 'owner_code']#相当于重命名
# 过滤特殊线路、政企用户
payevents2 = payevents1.loc[(payevents1.owner_code != 2
)&(payevents1.owner_code != 9
)&(payevents1.owner_code != 10), :] # 去除特殊线路数据
print('查看过滤后的特殊线路的用户:', payevents2.owner_code.unique())
payevents3 = payevents2.loc[(payevents2.owner_name != 'EA级'
)&(payevents2.owner_name != 'EB级'
)&(payevents2.owner_name != 'EC级'
)&(payevents2.owner_name != 'ED级'
)&(payevents2.owner_name != 'EE级'), :]
print('查看过滤后的政企用户:', payevents3.owner_name.unique())
payevents3.to_csv('payevents3.csv', na_rep='NaN', header=True, index=False)
结果:

绘制可视化图片
matplotlib:绘制代码
# 代码6-4
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import seaborn as sns
import re
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文
plt.rcParams['axes.unicode_minus'] = False # 设置正常显示符号
media3 = pd.read_csv('media3.csv', header='infer')
# 用户观看总时长
m = pd.DataFrame(media3['wat_time'].groupby([media3['phone_no']]).sum())
m = m.sort_values(['wat_time'])
m = m.reset_index()
m['wat_time'] = m['wat_time'] / 3600
m['id'] = m.index
ax = sns.barplot(x='id', y='wat_time', data=m)
ax.xaxis.set_major_locator(ticker.MultipleLocator(250))
ax.xaxis.set_major_formatter(ticker.ScalarFormatter())
plt.xlabel('观看用户(排序后)')
plt.ylabel('观看时长(小时)')
plt.title('用户观看总时长')
plt.show()
# 代码6-5
# 所有收视频道名称的观看时长与观看次数
media3.station_name.unique()
pindao = pd.DataFrame(media3['wat_time'].groupby([media3.station_name]).sum())
pindao = pindao.sort_values(['wat_time'])
pindao = pindao.reset_index()
pindao['wat_time'] = pindao['wat_time'] / 3600
pindao_n = media3['station_name'].value_counts()
pindao_n = pindao_n.reset_index()
pindao_n.columns = ['station_name', 'counts']
a = pd.merge(pindao, pindao_n, left_on='station_name', right_on ='station_name', how='left')
fig, ax1 = plt.subplots()
ax2 = ax1.twinx() # 构建双轴
sns.barplot(a.index, a.iloc[:, 1], ax=ax1)
sns.lineplot(a.index, a.iloc[:, 2], ax=ax2, color='r')
ax1.set_ylabel('观看时长(小时)')
ax2.set_ylabel('观看次数')
ax1.set_xlabel('频道号(排序后)')
plt.xticks([])
plt.title('所有收视频道名称的观看时长与观看次数')
plt.show()
# 收视前15频道名称的观看时长,由于pindao已排序,取后15条数据
sns.barplot(x='station_name', y='wat_time', data=pindao.tail(15))
plt.xticks(rotation=45)
plt.xlabel('频道名称')
plt.ylabel('观看时长(小时)')
plt.title('收视前15的频道名称')
plt.show()
# 代码6-6
# 工作日与周末的观看时长比例
ind = [re.search('星期六|星期日', str(i)) != None for i in media3['星期']]
freeday = media3.loc[ind, :]
workday = media3.loc[[ind[i]==False for i in range(len(ind))], :]
m1 = pd.DataFrame(freeday['wat_time'].groupby([freeday['phone_no']]).sum())
m1 = m1.sort_values(['wat_time'])
m1 = m1.reset_index()
m1['wat_time'] = m1['wat_time'] / 3600
m2 = pd.DataFrame(workday['wat_time'].groupby([workday['phone_no']]).sum())
m2 = m2.sort_values(['wat_time'])
m2 = m2.reset_index()
m2['wat_time'] = m2['wat_time'] / 3600
w = sum(m2['wat_time']) / 5
f = sum(m1['wat_time']) / 2
plt.figure(figsize=(8, 8))
plt.subplot(211) # 参数为:行,列,第几项 subplot(numRows, numCols, plotNum)
colors = 'lightgreen','lightcoral'
plt.pie([w, f], labels = ['工作日', '周末'], colors=colors, shadow=True,
autopct='%1.1f%%', pctdistance=1.23)
plt.title('周末与工作日观看时长占比')
plt.subplot(223)
ax1 = sns.barplot(m1.index, m1.iloc[:, 1])
# 设置坐标刻度
ax1.xaxis.set_major_locator(ticker.MultipleLocator(250))
ax1.xaxis.set_major_formatter(ticker.ScalarFormatter())
plt.xlabel('观看用户(排序后)')
plt.ylabel('观看时长(小时)')
plt.title('周末用户观看总时长')
plt.subplot(224)
ax2 = sns.barplot(m2.index, m2.iloc[:, 1])
# 设置坐标刻度
ax2.xaxis.set_major_locator(ticker.MultipleLocator(250))
ax2.xaxis.set_major_formatter(ticker.ScalarFormatter())
plt.xlabel('观看用户(排序后)')
plt.ylabel('观看时长(小时)')
plt.title('工作日用户观看总时长')
plt.show()
# 代码6-7
# 周观看时长分布
n = pd.DataFrame(media3['wat_time'].groupby([media3['星期']]).sum())
n = n.reset_index()
n = n.loc[[0, 2, 1, 5, 3, 4, 6], :]
n['wat_time'] = n['wat_time'] / 3600
plt.figure(figsize=(8, 4))
sns.lineplot(x='星期', y='wat_time', data=n)
plt.xlabel('星期')
plt.ylabel('观看时长(小时)')
plt.title('周观看时长分布')
plt.show()
# 付费频道与点播回看的周观看时长分布
media_res = media3.loc[media3['res_type'] == 1, :]
ffpd_ind = [re.search('付费', str(i)) != None for i in media3.loc[:, 'station_name']]
media_ffpd = media3.loc[ffpd_ind, :]
z = pd.concat([media_res, media_ffpd], axis=0)
z = z['wat_time'].groupby(z['星期']).sum()
z = z.reset_index()
z = z.loc[[0, 2, 1, 5, 3, 4, 6], :]
z['wat_time'] = z['wat_time'] / 3600
plt.figure(figsize=(8, 4))
sns.lineplot(x='星期', y='wat_time', data=z)
plt.xlabel('星期')
plt.ylabel('观看时长(小时)')
plt.title('付费频道与点播回看的周观看时长分布')
plt.show()
# 代码6-8
# 设置Matplotlib正常显示中文和负号
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取csv文件
pay = pd.read_csv('payevents2.csv')
sns.countplot(x='payment_name', data=pay)
plt.xticks(rotation=80)
plt.xlabel('支付方式')
plt.ylabel('总数')
plt.title('用户支付方式总数对比')
plt.show()绘制可视化图形
1、根据读取与处理广播电视数据只能简单的对数据进行了解,并不能明确的看出数据中蕴含的信息
2、因此,需要对清洗后的数据进行可视化分析,清晰的展示出广播电视数据中用户的观看信息,为运营商决策提供一定的参考
绘制用户分析图
- 分布分析是用户在特定指标下的频次、总额等的归类展现,它可以展现出单个用户对产品(电视)的依赖程度,从而分析出客户观看电视的总时长、所购买不同类型的产品数量等情况,帮助运营人员了解用户的当前状态。如观看时长(20小时以下、20小时~50小时、50小时以上等区间)等分布情况
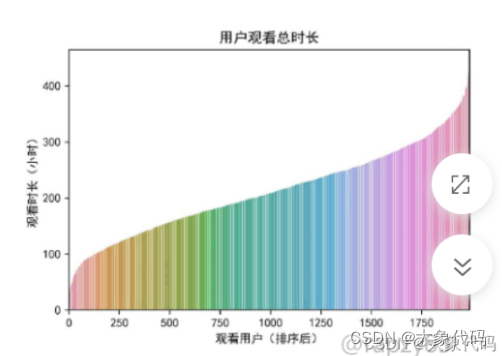
- 三网融合让人们可以便捷的获取新闻资讯,各种平台终端更是触手可及,同时工作节奏的加快,忙碌的人们是否还花时间订购收看广电节目?因此需要探索用户的观看总时长分布情况。计算所有用户在一个月内的观看总时长并且排序,从而对用户观看总时长分布进行可视化分布。
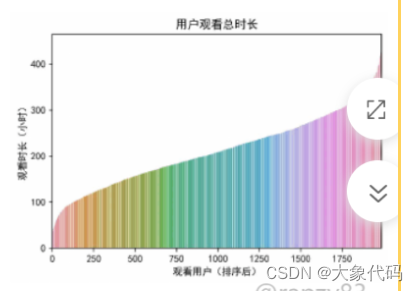
import pandas as pd
import pyecharts.options as opts
from pyecharts.charts import Bar
media3 = pd.read_csv('media3.csv', header='infer')
#数据处理
media3_sum = media3['wat_time'].groupby([media3['phone_no']]).sum()
m = pd.DataFrame({'phone_no': media3_sum.index, 'wat_time': media3_sum.values})
m = m.sort_values(['wat_time'])
m['wat_time'] = m['wat_time'] / 3600
m['id'] = m.index
#绘图
bar = (
Bar()
.add_xaxis(m['id'].tolist())
.add_yaxis('观看时长', m['wat_time'].tolist())
.set_global_opts(
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter='{value}'),
name='观看时长',
name_location='center',
name_gap=50
),
yaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter='{value}小时'),
name='用户数',
name_location='center',
name_gap=30
),
title_opts=opts.TitleOpts(title='用户观看总时长'))
.set_series_opts(
label_opts=opts.LabelOpts(position='top', formatter='{c}小时',is_show=False)
)
)
bar.render("1.html")
绘制频道分析图
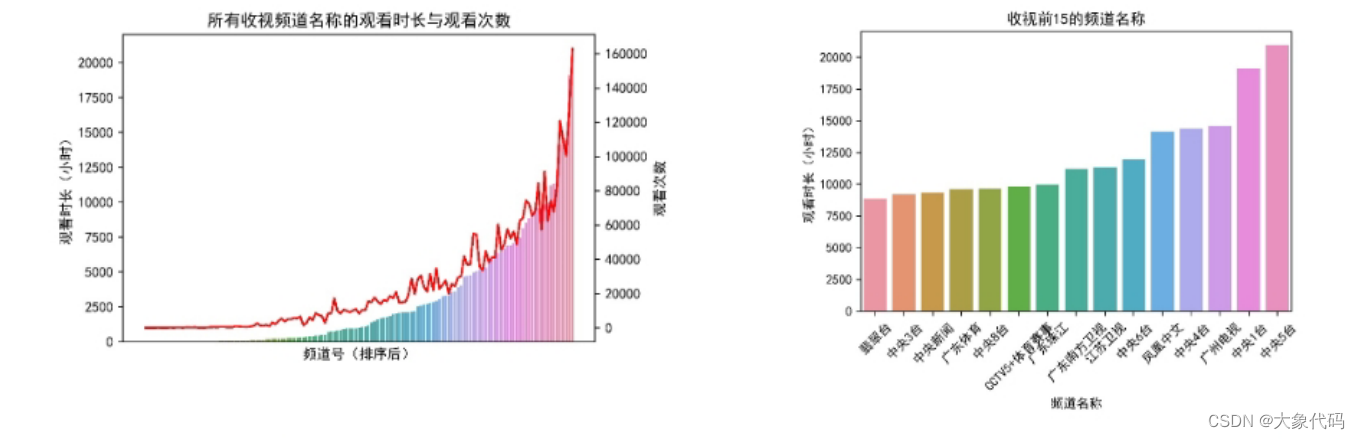
贡献度分析又称帕累托分析,它的原理是帕累托法则又称20/80定律。同样的投入放在不同的地方会产生不同的效益。例如,对一个公司而言,80%的利润常来自于20%最畅销的产品,而其他80%的产品只产生了20%的利润。为更好的了解观众最热衷哪些节目或哪些频道最受欢迎,提高收视率,因此需要对所有收视频道名称的观看时长与观看次数进行贡献度分析。
绘制时长分析图
- 对比分析是指将两个相互联系的指标进行比较,从数量上展示和说明研究对象规模的大小、水平的高低、速度的快慢和各种关系是否协调,特别适用于指标间的横纵向比较、时间序列的比较分析。在对比分析中,选择合适的对比标准是十分关键的步骤。当选择合适的对比标准时,才能做出客观的评价;当选择不合适的对比标准时,评价可能得出错误的结论。
- 对比分析主要有两种形式:静态对比和动态对比。静态对比,是指在同一时间条件下对不同总体指标进行比较,如不同部门、不同地区、不同国家的比较,也称为“横比”;动态对比,是指在同一总体条件下对不同时期指标数据的比较,也称为“纵比”。
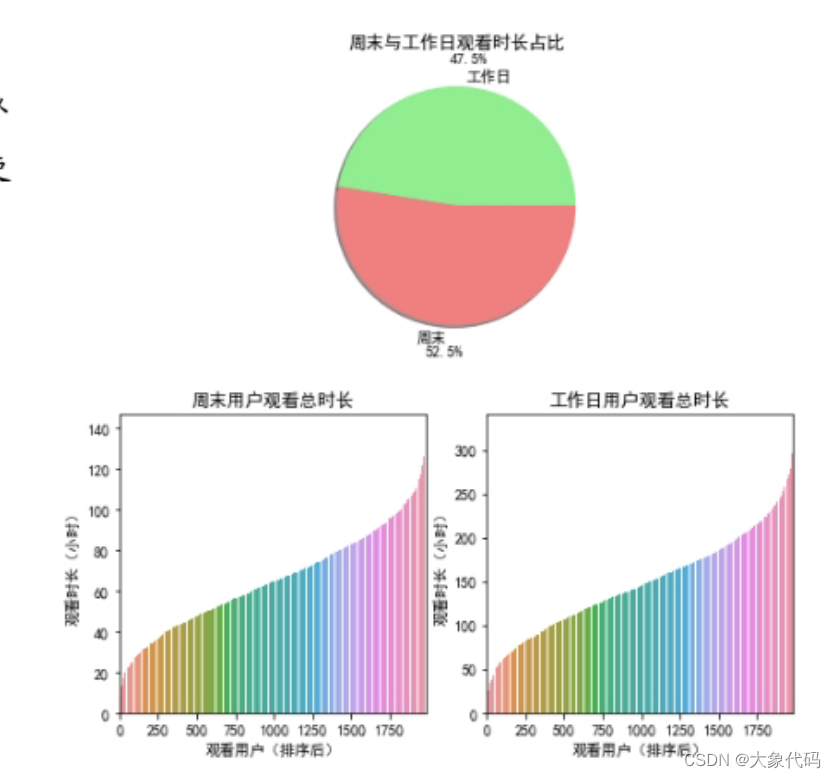
- 将工作日(5天)与周末(2天)进行划分,使用饼图展示所有用户的观看总时长的占比分布(计算观看总时长时需要除以天数),并对所有用户在工作日和周末的观看总时长的分布使用柱状图进行对比。
绘制周时长分析图
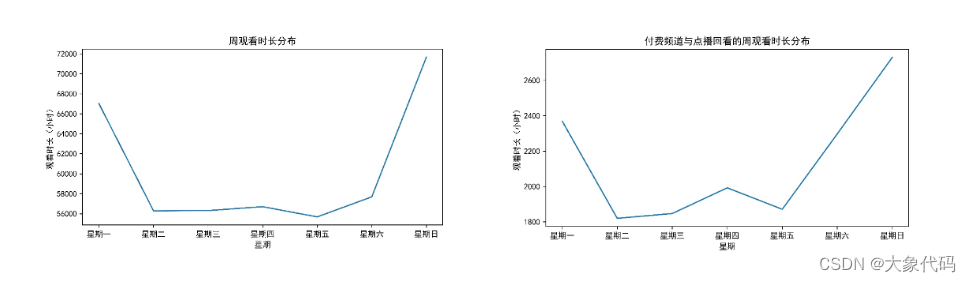
为了使运营商清楚的了解在一周时间内每天的观看时长,从而有针对性的投放受欢迎的节目,增加用户的使用黏度。需要分别绘制了频道周观看时长分布图以及付费频道与点播回看的周观看时长分布图。
绘制用户支付方式分析图
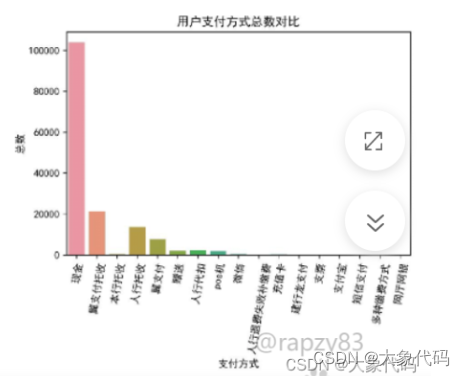
传统广播电视企业如果在互联网时代脱颖而出,那么不仅要在电视节目以及电视节目投放安排上进行分析,还要开发一些产品的周边服务,为用户带来全新的体验。通过绘制用户支付方式分析图,观察用户的支付方式情况,从而方便传统广播电视企业为用户开展一些便民服务,吸引更多的用户使用,增加收益。
项目分析报告
- 通过对收视行为信息数据和收费数据的进行清洗和可视化分析,已经初观察出用户的观看时长走势分布、收视频道的排名、工作日与周末收视观看占比、点播回看的总体情况以及用户付费方式。
- 了解更清晰的展示项目的结果,需要撰写项目分析报告,帮助开发者掌握广电大数据可视化的项目分析结果,给决策部门提供一个完整规范的方案,并帮助企业灵活调整经营决策。
- 分析报告包括了背景与目的、分析思路、分析结果、总结与建议,其模板如第一章撰写项目分析报告示例图所示。由于前面已经介绍过本项目的背景与目的,所以此处将不再重复介绍。
背景与目的
新零售智能销售设备以线上经营的理念,
了解销售的整体情况,为新零售智能销售设备商家提供相关的建议。
分析思路
- 收集大数据平台上的数据进行读取,清楚的熟悉数据的结构
- 根据项目的分析目的对收集到的数据进行清洗,包括对收视行为信息数据、账单与收费数据、订单数据和用户状态数据进行清洗处理
- 根据清洗后数据进行可视化分析,包括用户分析、频道分析、时长分析、周时长分析和用户支付方式分析
分析结果
由图可知,大部分用户的观看总时长主要集中在100小时~400小时之间。且随着收视用户的增多,电视节目的观看时长也在稳步增长。一个月平均每天观看10小时左右,这说明用户对广电节目有一定的依赖性,同时也说明了广电节目对用户有一定的吸引力,但仍然有一定的增长空间。
分析结果
由图可知,随着观看各频道次数增多,观看时长也在随之增多,且后面近28%的频道带来了80%的观看时长贡献度。出现这种情况的原因可能是也部分频道具有地方特色,或播放的节目比较受欢迎。
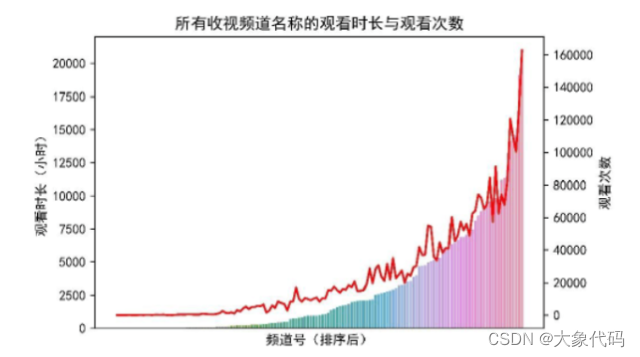
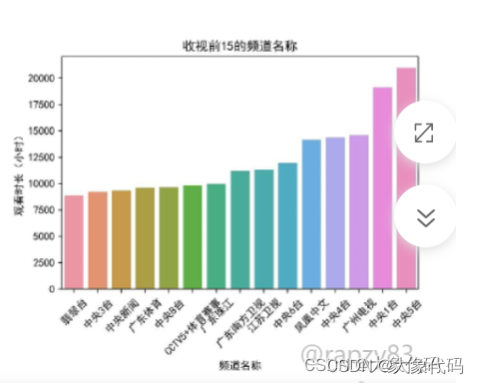
由图可知,排名前15的频道名称为翡翠台、中央3台、中央新闻、广东体育、中央8台、CCTV5+体育赛事、广东珠江、广东南方卫视、江苏卫视、中央6台、凤凰中文、中央4台、广州电视、中央1台、中央5台。其中,广东体育、广东珠江、广东南方卫视、广州电视都相对具有地方特色,而翡翠台则是广东话(粤语)广播为主的综合娱乐频道,也相对符合广东人民的喜好。同时这也从侧面证明了所有收视频道名称的观看时长与观看次数图的分析结果。
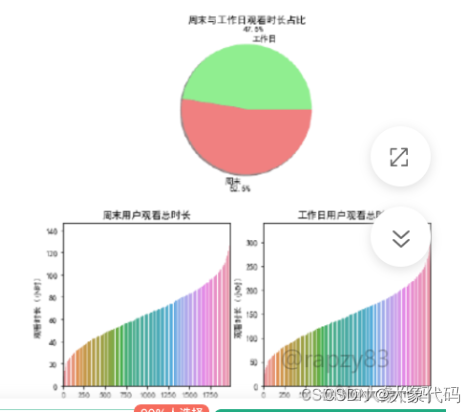
由图可知,周末的观看时长占观看总时长的52.5%,而工作日的观看时长的占比为47.5%;周末观看的用户时长集中在20小时~100小时之间,工作日观看的用户时长集中在50小时~250小时之间。虽然在比例图中,周末与工作日的比例相差不大,但是在分布图中工作日的观看总时长仍比周末的观看总时长多,并且两者分布图形状相似。出现这种情况的原因可能是因为周末用户可支配的时间更多,有更多的时间可用于观看电视节目。但是周末只有2天,工作日有5天,所以工作日的观看总时长会比周末的观看总时长多。
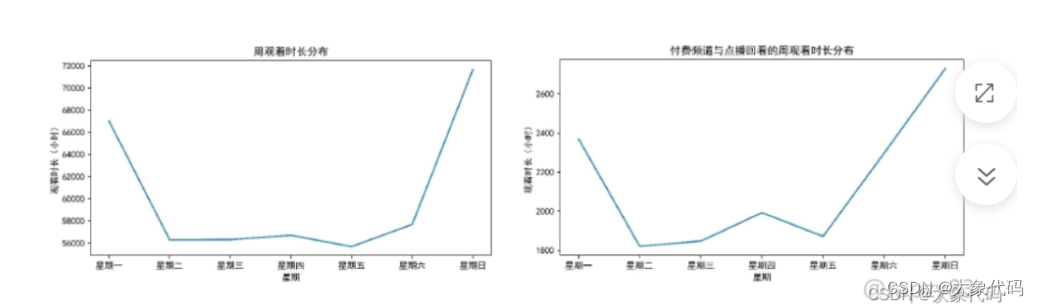
由以下两图可知,在一周中,周一、周六、周日的观看时间较长,其中周日观看时间最长。这说明人们更喜欢在周末且倾向于付费观看,在周二到周五忙于工作,无暇顾及电视节目,可能在周末点播回看。
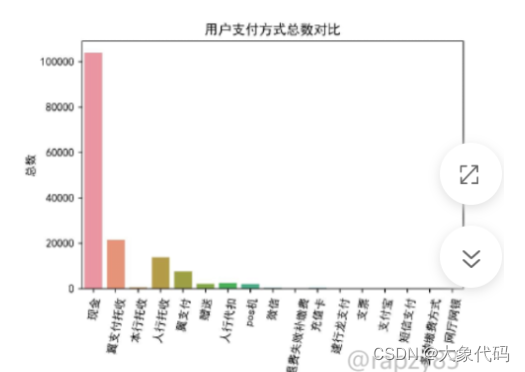
由图可知,大多数用户选择现金支付,其次是翼支付托收、人行托收,选择网厅网银、短信支付、支付宝、支票、建行龙支付、微信等方式的用户极少。说明用户还是受传统思想影响,倾向于使用现金支付,但是现金携带不便,也带来一定的安全隐患。同时加强宣传,引导用户选择掌上支付,业务也加强集成,方便终端绑定,一键式便捷支付。
总结与建议
通过对广电大数据可视化分析,提出以下总结与建议。
- 大部分用户的观看总时长主要集中在100小时~300小时之间且随着用户观看各频道次数增多,观看时长也在随之增多。因此,可以适当的更改不同频道的节目单,添加频道的吸引力,从而增多用户观看各频道次数和时长。
- 用户观看时长前15名的频道分别为翡翠台、中央3台、中央新闻、广东体育、中央8台、CCTV5+体育赛事、广东珠江、广东南方卫视、江苏卫视、中央6台、凤凰中文、中央4台、广州电视、中央1台、中央5台。针对这个现象,并且周末的观看时长略高于工作日。针对这个现象,经营者可以在用户观看时长前15名的频道中将用户喜好的节目投放时间把控在周末进行播放,从而提高用户的观看兴趣,增加用户黏度。从而增加收视率。
- 大多数用户选择现金支付。针对这个现象,经营者可以加大线上缴费服务推广宣传,吸引更多的用户,付费频道可以在周日提供更多的节目吸引用户消费,增加收益。
小结
- 本章基于广播电视数据,包括用户的收视行为信息数据和收费数据,介绍了数据清洗的方法。
- 并从用户分析、频道分析、时长分析、周时长分析和用户支付方式分析5个方面对广播电视数据进行可视化分析。
- 从而根据可视化结果,撰写项目分析报告。