一、Map Reduce主要阶段

二、词频统计示例
0.MapReduce 词频统计(Word Count)示例图
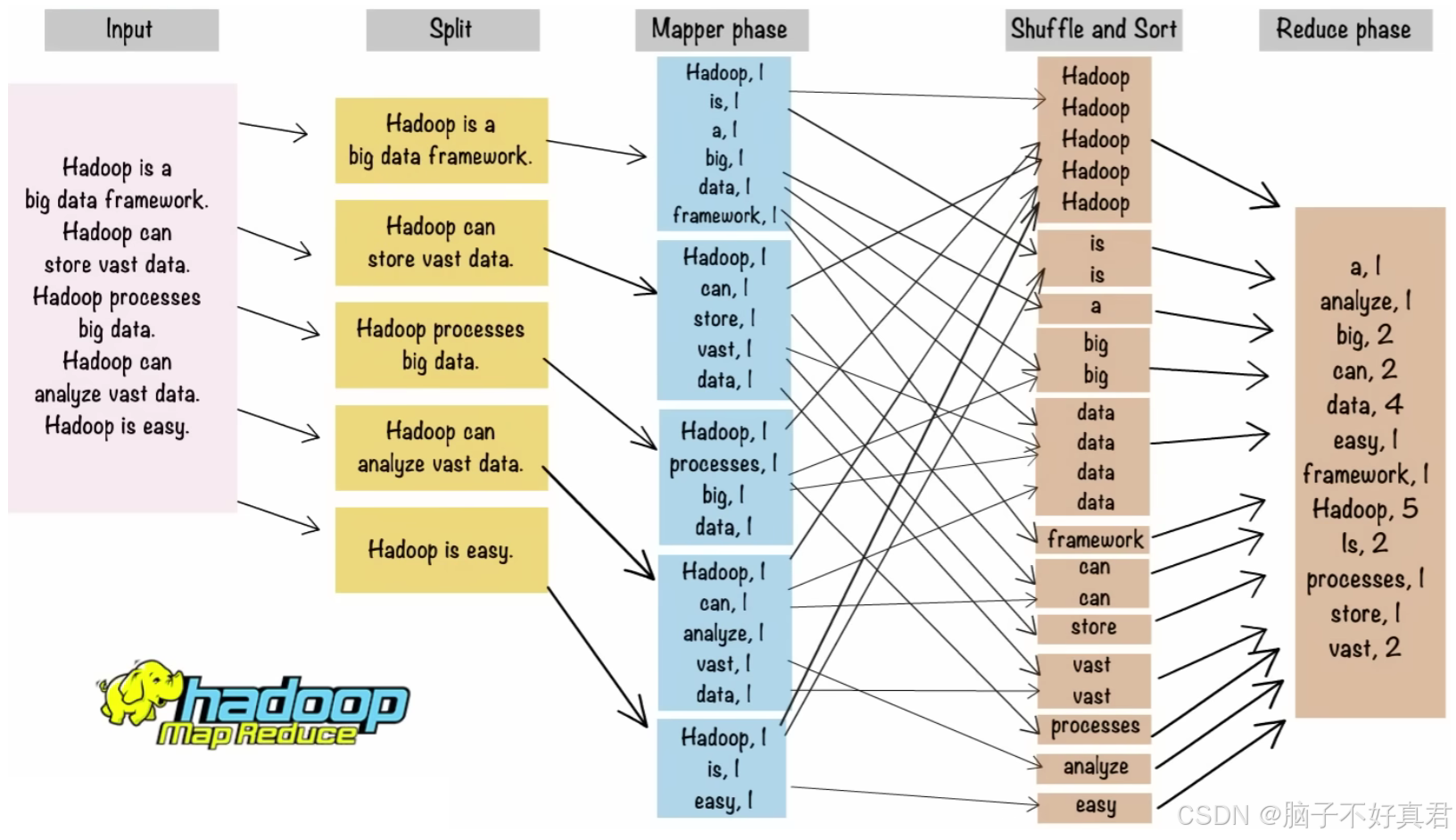
1. Input 阶段(输入阶段)
输入数据是一段文本,如下:
Hadoop is a big data framework.
Hadoop can store vast data.
Hadoop processes big data.
Hadoop can analyze vast data.
Hadoop is easy.
2. Split 阶段(数据分割阶段)
输入数据被切分为更小的部分,每个部分对应一行文本。
作用:将输入数据分配给不同的 Mapper 任务,实现并行处理。
Split 1: Hadoop is a big data framework.
Split 2: Hadoop can store vast data.
Split 3: Hadoop processes big data.
Split 4: Hadoop can analyze vast data.
Split 5: Hadoop is easy.
3. Mapper Phase(映射阶段)
每个 Mapper 任务读取一个输入块,应用用户定义的 Map 函数。
Map 函数会将输入文本解析为单词,并为每个单词输出一个键值对(Key-Value Pair),形式为 <单词, 1>。
例如:
- 输入:Hadoop is a big data framework.
- 输出:<Hadoop, 1>, <is, 1>, <a, 1>, <big, 1>, <data, 1>, <framework, 1>
作用:Map 阶段的任务是将原始数据转化为键值对,并提取有用信息。
Mapper 输出:
Split 1: <Hadoop, 1>, <is, 1>, <a, 1>, <big, 1>, <data, 1>, <framework, 1>
Split 2: <Hadoop, 1>, <can, 1>, <store, 1>, <vast, 1>, <data, 1>
Split 3: <Hadoop, 1>, <processes, 1>, <big, 1>, <data, 1>
Split 4: <Hadoop, 1>, <can, 1>, <analyze, 1>, <vast, 1>, <data, 1>
Split 5: <Hadoop, 1>, <is, 1>, <easy, 1>4. Shuffle and Sort 阶段(洗牌和排序阶段)
洗牌(Shuffle):
将 Mapper 阶段输出的键值对,根据键(单词)进行分组。
所有相同键的键值对被发送到同一个 Reducer 任务。
例如:来自不同 Mapper 的 <Hadoop, 1> 被收集到一起:<Hadoop, [1, 1, 1, 1, 1]>
排序(Sort):
对每个键值对按照键排序(升序)。
图中展示了 Hadoop、is、a 等单词被分组和排序。
作用:实现数据分布和排序,为 Reduce 阶段的处理做好准备。
5. Reduce Phase(归约阶段)
Reduce 函数对每个键及其关联的值列表进行聚合计算。
示例:
- 输入:<Hadoop, [1, 1, 1, 1, 1]>
- Reduce 计算:对列表中的值进行累加:1 + 1 + 1 + 1 + 1 = 5
- 输出:<Hadoop, 5>
其他 Reduce 结果:
- <is, 2>
- <a, 1>
- <big, 2>
- <data, 4>
- <framework, 1>
- <easy, 1>
作用:Reduce 阶段将分组后的数据进行汇总、聚合、统计,生成最终结果。
6. output阶段(输出阶段)
a, 1
analyze, 1
big, 2
can, 2
data, 4
easy, 1
framework, 1
Hadoop, 5
is, 2
processes, 1
store, 1
vast, 2
