Apache Airflow是面向开发人员使用的,以编程方式编写、调度和监控的数据流程平台。可伸缩性是其关键特性之一,Airflow支持使用不同的执行器来执行任务。在本文中,我们将深入探讨如何利用这些执行器在Airflow中有效地扩展任务执行。

理解Airflow中的执行者
执行器是运行任务的机制。Airflow带有几个执行器,每个执行器都有自己的长处和理想的用例。核心执行者有:
- SequentialExecutor:这是默认的执行器,每次运行一个任务。它适用于简单的工作流和测试目的。
- LocalExecutor: LocalExecutor允许在调度程序所在的同一台机器上运行任务,支持使用多任务并行处理。
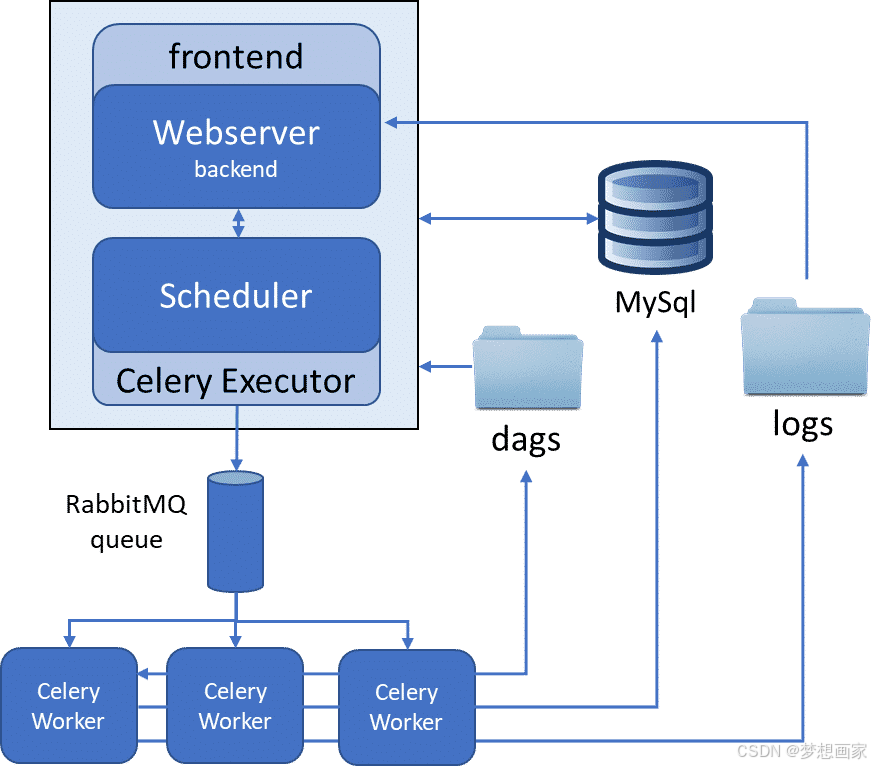
- CeleryExecutor:使用CeleryExecutor执行分布式任务。它利用一个异步分布式任务队列Celery在多个worker上执行任务。
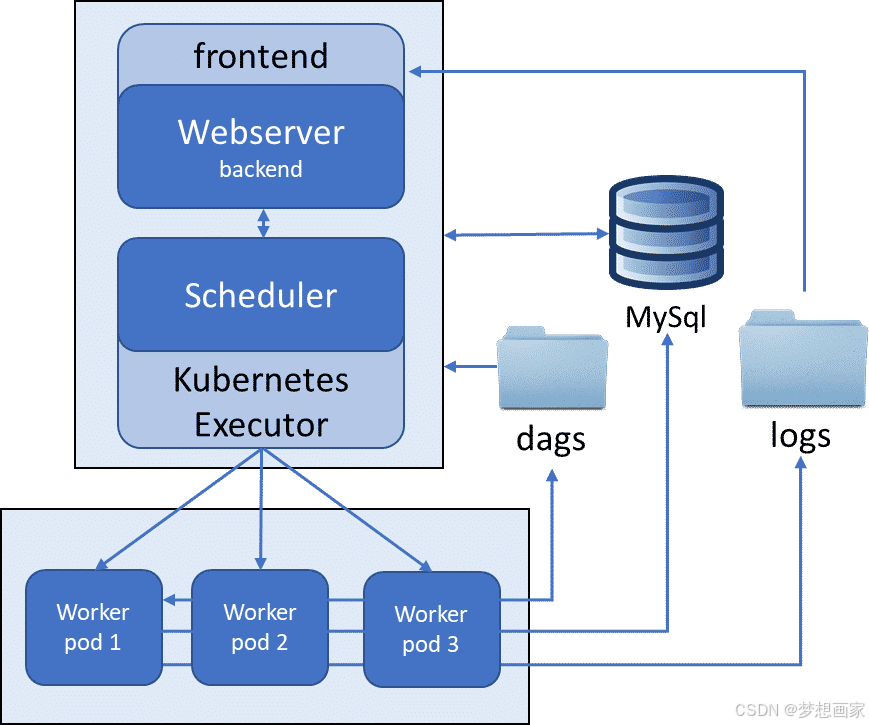
- KubernetesExecutor: 在Kubernetes集群内的单独pod中运行每个任务,提供出色的可伸缩性和任务之间的隔离。
用LocalExecutor扩展执行
LocalExecutor是超越SequentialExecutor限制扩展任务执行的绝佳起点。要配置它,请在airflow.cfg中设置执行器:
[core]
executor = LocalExecutor
另外,通过在同一配置文件中设置parallelism来定义允许的并行任务数:
[core]
parallelism = 10

用CeleryExecutor进行分布式执行
对于需要跨多台机器分布式执行的更复杂的工作流,CeleryExecutor是最好的选择。它需要像RabbitMQ或Redis这样的代理和像SQL数据库的在后端保存结果。配置方法如下:
[core]
executor = CeleryExecutor
[celery]
broker_url = your-broker-url
result_backend = db+your-database-connection-string
要向外扩展,只需运行以下命令添加更多的worker:
airflow celery worker
用Kubernetes实现隔离和可扩展性
KubernetesExecutor通过在Kubernetes集群的pod中执行每个任务,进一步提高了可伸缩性和隔离性。这允许动态资源分配和健壮的可伸缩性。通过更新airflow.cfg配置它:
[core]
executor = KubernetesExecutor
你还需要定义与集群相关的Kubernetes上下文和其他配置。
自定义执行器
在某些情况下,你可能需要编写自定义执行程序。例如,如果你希望与内置执行器不支持的特定基础设施或专有服务进行更紧密的集成。编写自定义执行器涉及到继承BaseExecutor类并实现所需的方法。
总结
选择正确的执行者对于优化工作流执行在Airflow至关重要。当扩展执行或处理更复杂的工作流时,从LocalExecutor转换到CeleryExecutor或Kubernetes executor可以提供必要的资源和灵活性。了解Airflow执行器及相关配置,你可以使Airflow流程保持健壮、可扩展、易维护。