
智能算力中心万卡GPU集群架构深度分析
自ChatGPT发布,科技界大模型竞赛如火如荼。数据成新生产要素,算力成新基础能源,大模型成新生产工具,“AI+”转型势不可挡。模型参数量突破万亿,对算力需求升级,超万卡集群成基建竞赛标配。超万卡集群缩短训练时间,加速迭代,助力市场趋势应对。
在超万卡集群中,高效稳定地训练大模型面临双重挑战:确保集群算力最大化、网络稳定及快速故障处理。这些问题已成为行业关注焦点。
第一章: 超万卡集群背景与趋势
1.1 大模型驱动智能算力爆发式增长
,
自ChatGPT亮相,大模型时代风起云涌,模型更迭迭起,Scaling Law验证不断,AI发展赋能数字经济。数据量与参数规模呈指数级增长:BERT的1.1亿参数,在GPT-3的1750亿参数下显得渺小。
先进模型如MOE引领参数规模迈向万亿,未来2-3年,AI技术进步与算力提升将推动Scaling Law延续,助力参数规模冲击十万亿级!
大模型技术飞速发展,催生超长序列应用、文生视频等创新应用,多领域智能化能力显著,"Al+"革命性影响生产生活。
大模型新纪元开启,ChatGLM、LLaMA、Gemini 等领军发布,激荡科技界探索新高。Sora 多模态文生视频模型横空出世,点燃行业热浪,推动技术、规模与应用创新,迈向新爆点!
AI革命推动产业飞跃,却呼唤巨量算力与能源。GPT-3训练,其电力消耗相等于121个美国家庭全年用电。
GPT-4,拥有16个专家模型及1.8万亿参数,训练需25000个A100,耗时90-100天。其大模型对算力、空间、能源需求巨大,推动新一代智算设施设计升级。新型智算中心(NICC)将实现更高密度算存、无阻塞网络连接及并行计算,相关技术迈向新高峰。
1.2 超万卡集群的建设正在提速
在人工智能新时代,算力助力企业创新与转型。顶尖科技公司积极构建千卡至超万卡的强大计算集群,这不仅彰显其在前沿领域的科技实力,更昭示其对未来科技趋势的深远布局。
全球科技巨头如Google、Meta、Microsoft,正借助超万卡集群,加速基座大模型、智能算法研发和生态服务创新,引领技术前沿。
Google全新A3虚拟机,搭载26000块Nvidia H100 GPU,并构建TPUv5p 8960卡集群,打造超级计算机实力。
Meta于2022年发布16,000块Nvidia A100的AI研究超级集群,2024年初再添两个24576块Nvidia H100集群,助力下一代生成式AI模型训练。
国内通信巨头、头部互联网企业及AI企业共同推动超万卡集群技术革新。作为算力基建主力,运营商凭借强大机房资源,加速建设智算中心,引领行业升级。
此举措为运营商大模型研发提供坚实算力,并带来高品质智算服务,助力政府、高校及企业。随着智算中心发展,运营商在连接技术创新与行业应用中扮演关键角色,引领社会数字化与智能化转型。
头部互联网巨头如字节跳动、阿里巴巴、百度等,正引领技术创新,加速构建超万卡集群,以推动云计算、大数据分析和人工智能等领域的突破。字节跳动打造了12288卡Ampere架构集群,研发MegaScale系统训练大语言模型。这些集群的强大算力不仅加速企业自身数字化,更助力国内科技产业创新升级。
AI巨头正加速建设超万卡集群,以应对大规模模型训练与复杂算法的挑战。以科大讯飞为例,2023年已建成首个支持大模型训练的超万卡集群“飞星一号”,为AI研究提供强大算力,并在智算服务商业应用上抢占先机。
AI初创企业青睐灵活租用模式,借助超万卡集群强大计算力,实现应用投入平衡,降低投资门槛,加速产品研发与迭代。
无论是通信巨头、互联网翘楚、AI研发巨擘还是初创新贵,都在借助超万卡集群加速AI技术革新。随着集群建设深入,这一趋势将深刻塑造智算产业未来。
第二章: 超万卡集群面临的挑战
超万卡集群建设正起步,英伟达GPU助力,但国产Al芯片性能与生态构建待提升。构建领先国产生态的超万卡集群,挑战重重。
2.1 极致算力使用效率的挑战
实证研究显示,在大模型分布式训练中,集群规模线性增加不必然导致算力线性提升。优化卡间、节点间网络及软硬件适配,是提升集群极致算力的核心挑战。
我们评估集群有效算力,关键在于“GPU 利用率”与“集群线性加速比”。GPU利用率受制于芯片架构、内存瓶颈、互联带宽等多因素;而线性加速比则取决于节点通信、并行框架与资源调度。优化两者,将显著提升训练效率,降低成本。在超万卡集群,需采用系统工程,精细化网络设计,软硬件整合优化,以全面提升算力效率。
2.2 海量数据处理的挑战
训练千亿模型需PB级数据集多协议处理,万亿模型训练对checkpoint性能需求高达10TB/s。现有智算存储系统在协议、数据管理和吞吐性能上挑战重重。
在协议处理层面,传统智算存储系统依赖分立存储池,按块、文件、对象等协议构建,导致数据频繁拷贝,拖慢处理效率,消耗存储空间,并提升运维复杂度。
在数据管理层面,传统智算存储依赖人工冷热分类及集群迁移,导致跨系统数据迁移效率低下,额外占用带宽和计算资源。为应对超万卡集群大模型训练需求,需采用协议融合、自动分级等技术,实现高效数据共享与处理。
2.3 超大规模互联的挑战
在模型规模突破万亿量级后,数据处理和计算需求远超单机单卡极限,多机多卡协同训练成为关键。以部署1.8万亿GPT-4的超万卡集群为例,大模型训练中的每轮迭代都需前向和反向传播算法,这对集群的扩展性和网络性能提出了严峻挑战。
在Scale Out互联层面,网络需承载DP和PP流量,参数面带宽需达200-400Gbps,数据面需配置100Gbps带宽,确保数据读取不拖训练后腿。
此外,参数面网络还需要应对因多租户多任务并行训练通信特征不规整、上下行 ECMP (Equal Cost Multi Path) 选路不均衡而引发的高速大象流的交换冲突和拥塞在 Scale up 互联层面,由于 MoE 专家并行和张量并行 (Tensor Parallel,TP)的通信无法被计算掩盖,不仅要求卡间互联带宽达到几百甚至上千 GB的量级,而且应突破当前单机8卡的限制,以支持更大参数量的模型训练。此外,Scaleup 互联还需要保持高频度、低时延、无阻塞的通信模式。
2.4 集群高可用和易运维挑战
维护千万器件挑战重重:超万卡集群由数千台服务器、交换机与存储设备,及数万光纤与光模块构建。训练任务中千万元器件高速运转,硬件失效率与规模导致故障频发,故障模式复杂,管理难度大。系统故障定位复杂,万亿模型训练需精密配合,问题定界定位尤为困难。
硬件故障定位耗时1-2天,复杂应用故障或需数十天。提升快速定位能力,需结合运维经验,系统积累与持续改进。
高负荷运行下故障频发:万亿大模型训练耗时百天,需7x24小时满负荷。硬件MTBF随集群扩大而缩短,导致训练中断频仍。业界超万卡集群稳定运行仅数日,断点续训恢复慢,严重影响效率。超万卡集群亟需高效、快速、低影响的自动断点续训功能。
2.5 高能耗高密度机房设计的挑战
随着芯片TDP功率升至400~700W,单柜功率激增至40KW甚至60KW,集群功耗跃至数十至上百MW,机房亟需升级功率及散热能力。
在超万卡集群中,高速光模块的集成度高,易受灰尘影响。为保障设备稳定运行,机房需优化制冷通风,确保设备侧高洁净度,降低故障率。
以1.8万卡智算集群为例,布线需求高达10万级,对走线架提出全新挑战。超万卡集群迫切需求高压直流供电、高效液冷散热及超大规模网络技术。机房建设需提前规划供电制冷、承重等配套设施,确保超万卡集群快速部署与稳定运行。
第三章: 超万卡集群的核心设计原则和总体架构
3.1 超万卡集群的核心设计原则
在算力与大数据融合的大模型时代,构建超万卡集群非算力简单堆叠,需实现数万GPU卡如超级计算机般高效协同。
超万卡集群的总体设计应遵循以下五大原则:
致力于构筑顶尖集群算力:融合Scale-up与Scale-out技术,单节点峰值卓越,单集群规模突破万卡,构建超万卡集群,奠定强大算力基石。
依托庞大算力集群,采用DP/PP/TP/EP等并行策略,持续优化算力,实现卓越计算通信比,显著提升模型开发效率。
实现长稳可靠训练:自动检测修复软硬件故障,千万器件满载运行系统。持续提升平均故障间隔时间,降低平均修复时间,自动续训。支持千亿稠密、万亿稀疏大模型百天稳定训练,确保系统稳定与鲁棒。
坚守灵活算力供应:赋能集群智能调度,确保弹性算力与隔离技术并行,精准调配训练与推理资源,保障单集群大作业与多租户并行训练性能均衡。
引领绿色低碳新潮流:全面应用液冷技术,实现万卡集群高效能,FLOPs/W能效比突破,PUE降至1.10以下。
3.2 超万卡集群的总体架构设计
四层一域架构,万卡集群高效运营:机房配套、基础设施、智算平台、应用使能,智算运营与运维域协同,打造卓越计算环境。
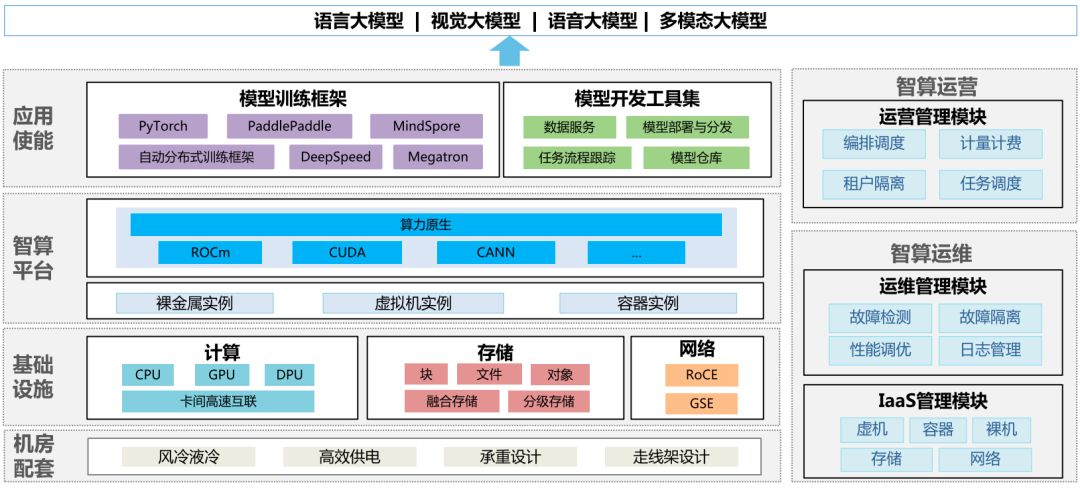
图1面向超万卡集群的新型智算总体架构设计
基础设施层: 算、网、存三大硬件资源有机配合,达成集群算力最优。
面向算力,CPU、GPU、DPU 三大芯片协同,最大化发挥集群计算能力;
网络独立组网,参数、数据、业务、管理全面覆盖。大带宽RoCE交换及二层无阻塞CLOS组网,满足大象流需求。负载均衡、多租安全隔离,安全高效。
面向存储,引入融合存储和分级存储支持无阻塞数据并发访问。
智算平台,以K8s为核心,支持裸金属与容器集群资源。纳管集群资源,实现大规模自动化故障管理,确保高效训练与稳定运行。
应用使能层:融合开源框架,优化分布式训练,面向未来自动框架设计,实现通信与计算优化、算子融合与网络高效调优。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-