Redis 集群模式
Replication+Sentinel
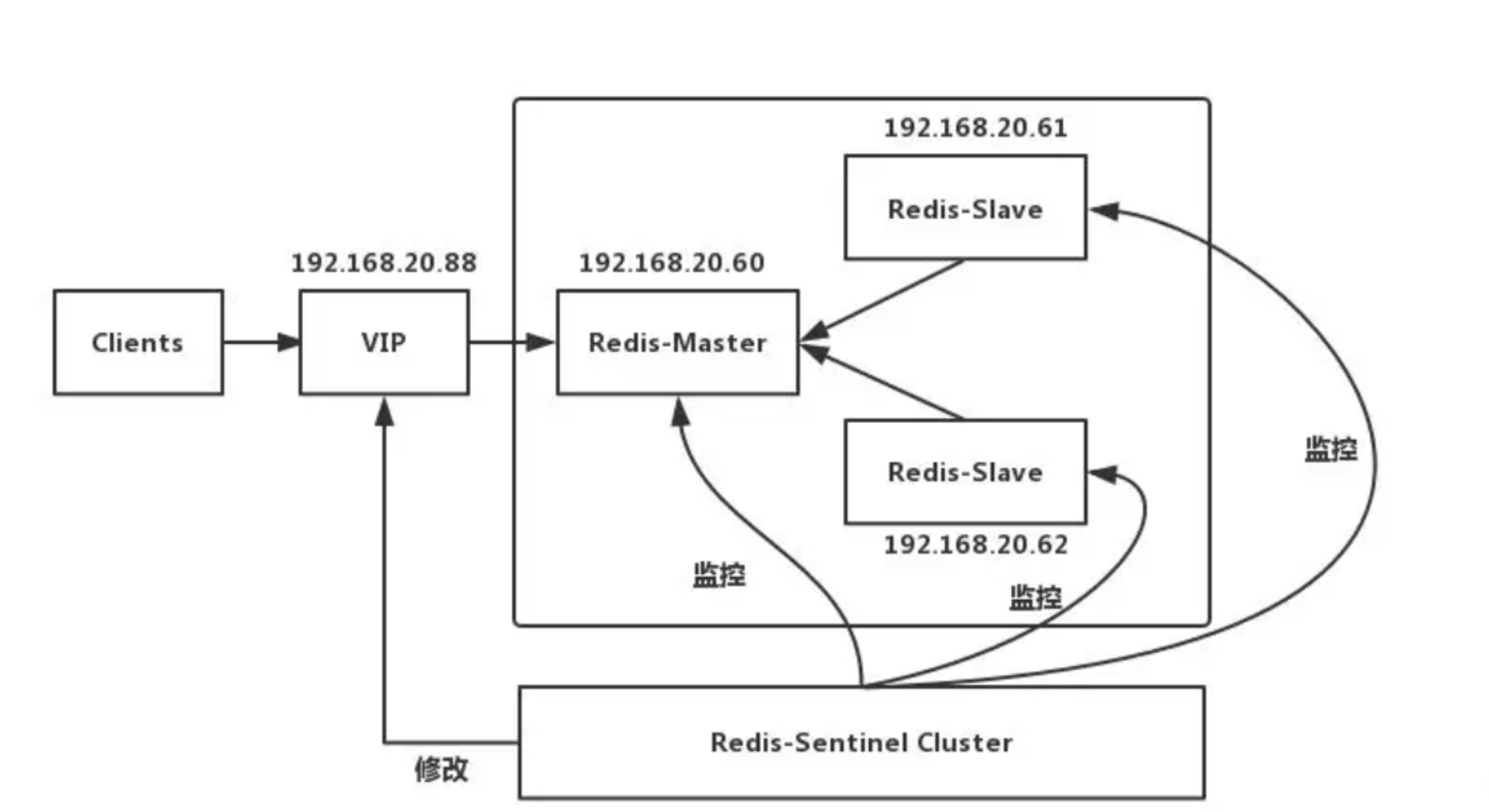
这里Sentinel的作用有三个:
- **监控:**
Sentinel 会不断的检查主服务器和从服务器是否正常运行。 - 通知: 当被监控的某个
Redis服务器出现问题,Sentinel通过API脚本向管理员或者其他的应用程序发送通知。 - 自动故障转移: 当主节点不能正常工作时,
Sentinel会开始一次自动的故障转移操作,它会将与失效主节点是主从关系的其中一个从节点升级为新的主节点,并且将其他的从节点指向新的主节点。
工作原理
当Master宕机的时候,Sentinel会选举出新的Master,并根据Sentinel中client-reconfig-script脚本配置的内容,去动态修改VIP(虚拟IP),将VIP(虚拟IP)指向新的Master。
缺陷
- 主从切换的过程中会丢数据
- Redis只能单点写,不能水平扩容
Proxy+Replication+Sentinel
这里的Proxy目前有两种选择:Codis和Twemproxy。
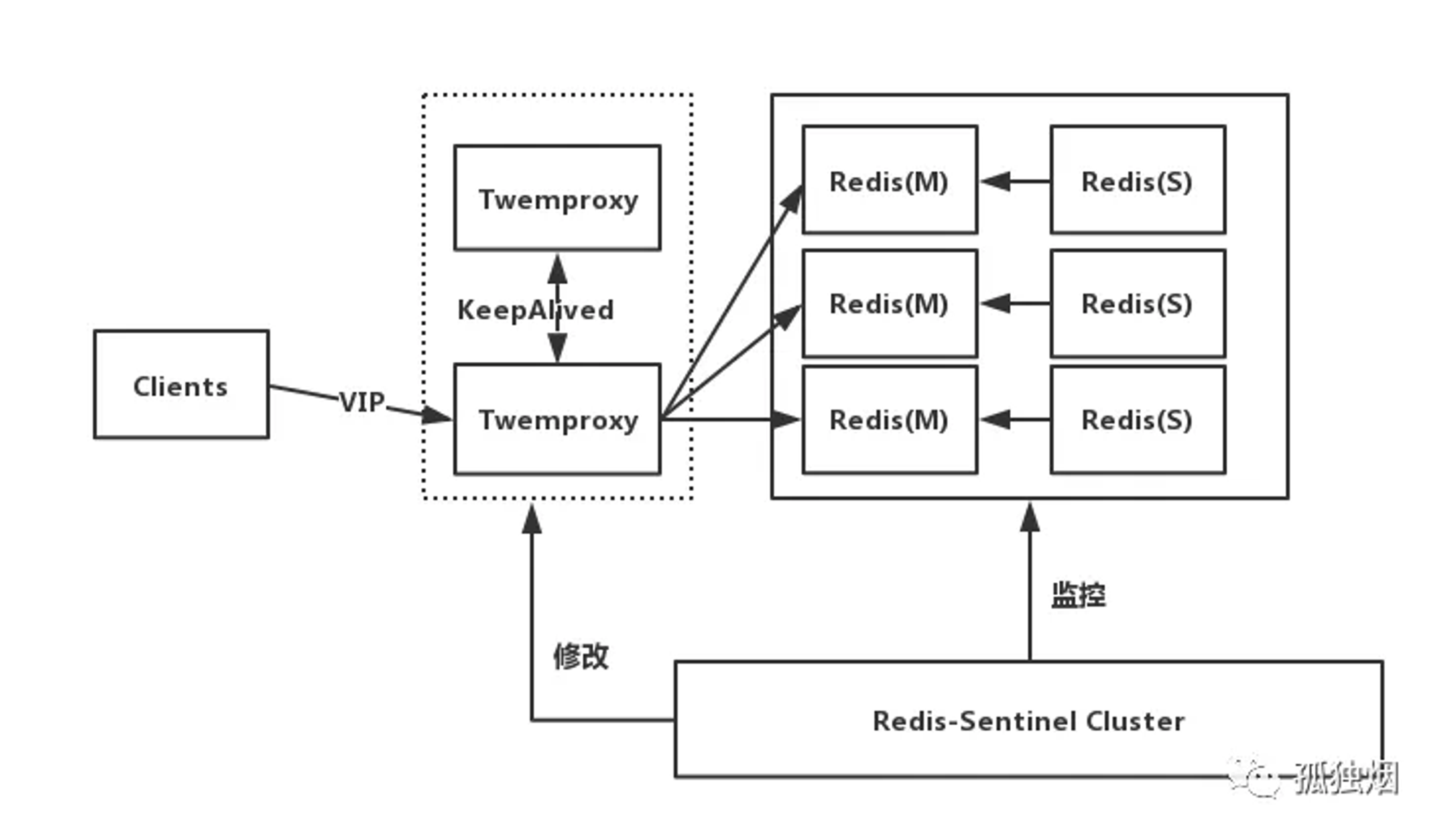
工作原理
- 前端使用
Twemproxy+KeepAlived做代理,将其后端的多台Redis实例分片进行统一管理与分配 - 每一个分片节点的
Slave都是Master的副本且只读 -
Sentinel持续不断的监控每个分片节点的Master,当Master出现故障且不可用状态时,Sentinel会通知/启动自动故障转移等动作 -
Sentinel 可以在发生故障转移动作后触发相应脚本(通过client-reconfig-script 参数配置 ),脚本获取到最新的Master来修改Twemproxy配置
缺陷
- 部署结构超级复杂。
- 可扩展性差,进行扩缩容需要手动干预。
- 运维不方便。
Redis Cluster
Redis Cluster 是Redis的集群实现,内置数据自动分片机制,集群内部将所有的key映射到16384个Slot中,集群中的每个Redis Instance负责其中的一部分的Slot的读写。集群客户端连接集群中任一Redis Instance即可发送命令,当Redis Instance收到自己不负责的Slot的请求时,会将负责请求Key所在Slot的Redis Instance地址返回给客户端,客户端收到后自动将原请求重新发往这个地址,对外部透明。
为什么RedisCluster会设计成16384个槽呢?
-
如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大 。
- 在消息头中,最占空间的是 myslots[CLUSTER_SLOTS/8]。当槽位为65536时,这块的大小是: 65536÷8=8kb因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
-
redis的集群主节点数量基本不可能超过1000个 。
- 集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者,不建议redis cluster节点数量超过1000个。那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
-
槽位越小,节点少的情况下,压缩率高。
- Redis主节点的配置信息中,它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中,会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。而16384÷8=2kb
工作原理
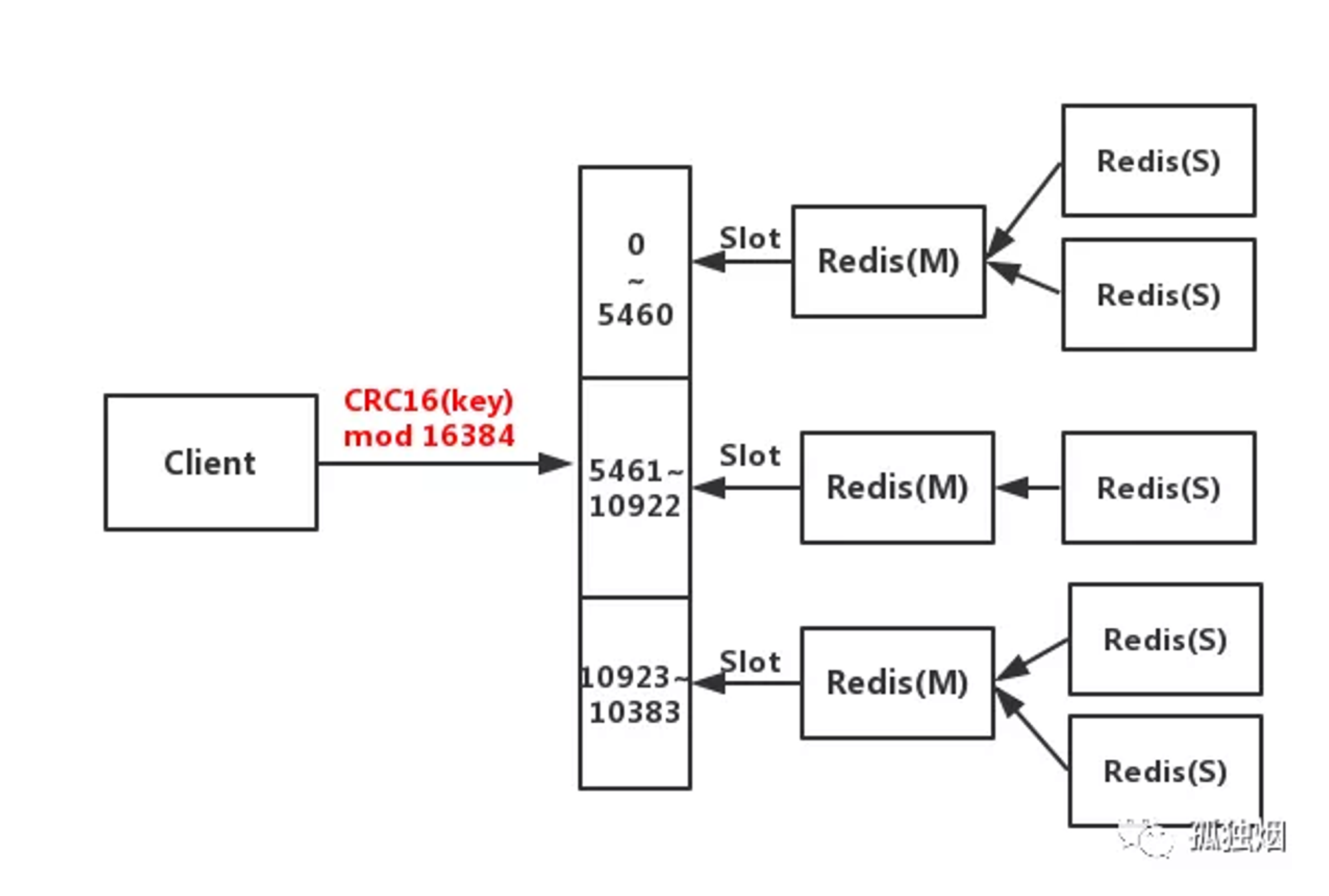
- 客户端与Redis节点直连,不需要中间
Proxy层,直接连接任意一个Master节点 - 根据公式
HASH_SLOT=CRC16(key) mod 16384,计算出映射到哪个分片上,然后Redis会去相应的节点进行操作
优点
-
高可用性:
- 支持主从复制和故障转移,可以在主节点故障时自动将主节点的角色转移到从节点,实现无缝的服务恢复。
- 通过数据冗余,即使部分节点不可用,集群仍能继续运行并提供服务。
-
可扩展性:
- 支持动态扩展,可以根据需要添加新的节点,以增加存储容量和处理能力。
- 数据按照哈希槽均匀分布,允许数据随着节点数量的增加而自动再分布,以保持负载均衡。
-
高性能:
- 通过数据分片,将数据分散存储在多个节点中,利用并行处理能力,提高系统的整体吞吐量和响应速度。
- 单个节点的性能与集群模式下相当,得益于优化的网络通信和数据访问机制。
-
数据分布均衡:
- 采用哈希槽和一致性哈希算法,可以将数据均匀地分布在不同的节点上,减少热点数据对单一节点的压力。
-
管理方便:
- 提供集群管理工具如
redis-trib,简化了节点的添加、删除、数据迁移等操作,降低了运维成本。 - 具有自我修复的能力,能够在检测到故障后自动恢复,减少了人工干预的需求。
- 提供集群管理工具如
-
无中心架构:
- Redis Cluster 采用去中心化的架构,不存在单点故障,增强了系统的稳定性和可靠性。
-
读写分离:
- 从节点可以承担读取操作,提高了读取性能,同时也为高并发读操作提供了支持。
-
降低成本:
- 能够利用商品级硬件构建大规模的分布式存储系统,相比于专用的高可用解决方案,具有成本效益。
-
适应性:
- 可以根据业务需求调整集群规模,灵活应对流量变化或数据增长。
缺点
-
管理和配置的复杂性:
- 集群的配置和维护比单个 Redis 实例要复杂得多,需要管理多个节点、槽位分配、节点间通信和数据复制。
- 故障恢复过程自动进行,但这同样增加了系统复杂性,尤其是在节点故障时,可能需要手动干预来恢复服务。
-
数据一致性问题:
- Redis Cluster 不保证强一致性,而是采用最终一致性模型。在某些场景下,如网络分区或故障转移期间,客户端可能会看到过期的数据。
- 读写分离虽然提高了性能,但在读取从节点数据时可能会遇到数据延迟问题。
-
功能限制:
- Redis Cluster 不支持所有 Redis 命令,尤其是那些涉及跨槽或多键操作的命令。例如,事务(Transactions)、Lua 脚本、某些集合操作等在集群环境下受限或行为不同。
- 一些高级数据结构和命令可能无法在集群中使用,或者只能在单个节点内使用。
-
数据迁移和重新平衡:
- 当集群需要重新平衡或扩展时,数据迁移过程可能会导致源节点和目标节点的暂时阻塞,影响性能。
- 数据迁移和重新平衡操作需要谨慎计划,以避免对在线服务产生负面影响。
-
网络延迟和带宽:
- 集群内部的节点间通信增加了网络开销,特别是在地理分布广泛的集群中,网络延迟可能成为性能瓶颈。
- 节点间频繁的心跳和状态更新通信可能会消耗较多的带宽资源。
-
监控和故障诊断难度:
- 集群模式下的去中心化架构使得监控和故障排查变得更加困难,需要额外的工具和策略来确保集群的健康状态。
- 集群的去中心化设计使得问题定位和解决可能比单节点环境更加复杂。
-
存储成本和效率:
- 由于需要数据复制以实现高可用性,存储成本会相应增加。
- 存储效率可能不如单节点环境,因为每个键可能需要在多个节点上存储。