全文链接:https://tecdat.cn/?p=36990
原文出处:拓端数据部落公众号
分析师:Qi Zhang
背景
基于游戏进行学习能让学校变得有趣,这种教育方法能让学生在游戏中学习,使其变得有趣和充满活力。尽管基于游戏的学习正在越来越多的教育环境中使用,但能用应用数据科学和学习分析原理来改进基于游戏学习的数据集仍然有限。
大多数基于游戏的学习平台没有充分利用知识追踪来支持个别学生。知识追踪方法是在在线学习环境和智能辅导系统的背景下开发和研究的。但教育游戏中对知识追踪的关注较少。
数据
本次使用了时间序列API。测试数据将分组交付,不允许访问未来的数据。目的是利用在线教育游戏生成的时间序列数据来判断玩家是否会正确回答问题。共有三个问题检查点(level 4, level 12, and level 22),每个检查点都有许多问题。在每个检查点,您都可以访问该部分之前的所有测试数据。
任务
本次比赛的目标是实时预测学生在游戏学习过程中的表现。您将开发一个在最大的开放游戏日志数据集上的模型。
评价指标
使用F1 score作为评价指标,用来计算参赛者提交结果的成绩,具体计算方式如下:
F_1=2/(recall(-1)+precision(-1) )=2tp/(2tp+fp+fn).
数据探索
数据文件达到了4.74GB,需要先理解每个字段的意义,在了解每个字段的意义后才能更好地进行特征组合及后续建模。
字段类别含义
train.csv与test.csv中的字段及含义
session_id:每个游戏段所对应的唯一ID,例如:20090312431273200
index:每个session中一系列事件的索引:0、1、2…
elapsed_time:从这个游戏段开始到这个事件发生时所过去的时间(单位毫秒)
event_name:事件类型名称,例如:cutscene_click
name:事件名称,例如:basic
level:事件发生的游戏级别(0-22)
page:事件中笔记本的第几页(仅仅在笔记本相关事件中出现)
room_coor_x:相对于游戏房间的点击x轴坐标(仅适用于点击事件)
room_coor_y:相对于游戏房间的点击y轴坐标(仅适用于点击事件)
screen_coor_x:参考玩家屏幕的点击x轴坐标(仅适用于点击事件)
screen_coor_y:参考玩家屏幕的点击y轴坐标(仅适用于点击事件)
hover_duration:悬停发生的时间(以毫秒为单位)(仅适用于悬停事件)
text:玩家在此事件中看到的文本,例如:What cha doing over there, Jo?
fqid:事件的完全限定 ID,例如:intro
room_fqid:事件发生的房间完全ID,例如:tunic.historicalsociety.closet
text_fqid:文本的完全ID,例如tunic.historicalsociety.closet.intro
fullscreen:玩家是否全屏玩游戏0/1
hq:玩家是否开启高清模式玩游戏0/1
music:玩家是否在游戏中打开声音0/1
level_group:该数据行属于哪一组级别以及哪组问题(0-4、5-12、13-22)
train_labels.csv字段及含义
session_id:每个游戏段所对应的唯一ID的问题,例如:20090312431273200_q1代表了序列为20090312431273200第一个问题的回答情况。
correct:每个序列对应问题回答正确与否,即我们需要进行预测的值
统计特征
我们根据每个玩家所有序列中下一个elapsed_time和上一个的差值得到elapsed_time_diff,代表该玩家在进行某个事件所花费的时间。在去除字段hq、music和music后可以发现 ‘event_name’, ‘name’, ‘fqid’, ‘room_fqid’, 'text_fqid’为分类字段,‘page’, ‘room_coor_x’, ‘room_coor_y’, ‘screen_coor_x’, ‘screen_coor_y’, ‘hover_duration’, 'elapsed_time_diff’为数值字段。
根据ONELUX的开源代码,我们得到包含event_name 、name 、fqid、room_fqid、text_fqid所有值的列表,MATSAMAN也给出了一个包含游戏文本中所有语气词的列表DIALOGS = [‘that’, ‘this’, ‘it’, ‘you’, ‘find’, ‘found’, ‘Found’, ‘notebook’, ‘Wells’,‘wells’,‘help’,‘need’, ‘Oh’,‘Ooh’,‘Jo’, ‘flag’, ‘can’,‘and’,‘is’,‘the’,‘to’]。
基于比pandas占用内存更小的polars库,我们可以构造特征:
模型训练
对于每个玩家需要预测的18个问题,我们均使用五折训练,一共需要训练18*5个模型,其中level_group为0-4对应问题1、2、3,level_group为5-12对应问题4-13,level_group为13-22对应问题14-18。本次比赛选取的模型均为树模型,包括LightGBM、XGBoost和CatBoost。
LightGBM模型训练
Lgb超参数我们设置为:
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'binary_logloss',
'learning_rate': 0.05,
'alpha': 8,
'max_depth': 4,
'subsample': 0.8,
'colsample_bytree': 0.5,
'random_state': 42
}
以下是lgb的训练代码:
pred_lgb = np.zeros((df1.shape[0], 18))
n_splits = 5
kf = KFold(n_splits=n_splits)
for q in range(1, 19):
if q <= 3:
grp = '0-4'
df = df1
FEATURES = FEATURES1
elif q <= 13:
grp = '5-12'
df = df2
FEATURES = FEATURES2
elif q <= 22:
grp = '13-22'
df = df3
FEATURES = FEATURES3
lgb_params['n_estimators'] = estimators_lgb[q - 1]
for fold, (train_idx, val_idx) in enumerate(kf.split(df)):
df_train = df.iloc[train_idx] #.reset_index(drop=True)
train_users = df_train.index.values
train_y = targets[targets['session'].isin(list(train_users))].loc[targets.q == q].set_index('session')
df_val = df.iloc[val_idx] #.reset_index(drop=True)
val_users = df_val.index.values
val_y = targets[targets['session'].isin(list(val_users))].loc[targets.q == q].set_index('session')
clf = LGBMClassifier(**lgb_params)
clf.fit(df_train[FEATURES].astype('float32'), train_y['correct'], verbose=0)
clf.booster_.save_model(f'LGBM_question{q}_fold{fold}.lgb')
XGB模型训练
使用GroupKFold进行分组抽样,同时构建模型字典存储xgb模型
gkf = GroupKFold(n_splits=5)
oof = pd.DataFrame(data=np.zeros((len(ALL_USERS),18)), index=ALL_USERS)
models = {}
进行模型训练:
for q in range(1, 19):
print(f"question{q}")
if q <= 3:
grp = '0-4'
df = df1
FEATURES = FEATURES1
elif q <= 13:
grp = '5-12'
df = df2
FEATURES = FEATURES2
elif q <= 22:
grp = '13-22'
df = df3
FEATURES = FEATURES3
for i, (train_index, test_index) in enumerate(gkf.split(X=df, groups=df.index)):
print('Fold:',i+1)
xgb_params = {
'objective' : 'binary:logistic',
'eval_metric':'logloss',
'learning_rate': 0.05,
'max_depth': 4,
'n_estimators': 1000,
'early_stopping_rounds': 50,
'tree_method':'hist',
'subsample':0.8,
'colsample_bytree': 0.4}
train_x = df.iloc[train_index] #.reset_index(drop=True)
train_users = train_x.index.values
train_y = targets[targets['session'].isin(list(train_users))].loc[targets.q == q].set_index('session')
valid_x = df.iloc[test_index] #.reset_index(drop=True)
valid_users = valid_x.index.values
valid_y = targets[targets['session'].isin(list(valid_users))].loc[targets.q == q].set_index('session')
clf = XGBClassifier(**xgb_params)
clf.fit(train_x[FEATURES].astype('float32'), train_y['correct'], eval_set=[ (valid_x[FEATURES].astype('float32'), valid_y['correct']) ], verbose=0)
clf.save_model(f'XGB_question{q}_fold{i}.xgb')
print(f'{q}({clf.best_ntree_limit}), ',end='')
models[f'{grp}_{i}_{q}'] = clf
oof.loc[valid_users, q-1] = clf.predict_proba(valid_x[FEATURES].astype('float32'))[:,1]
Cat训练
模型训练:
for q in range(1, 19):
print(f"question{q}")
if q <= 3:
grp = '0-4'
df = df1
FEATURES = FEATURES1
elif q <= 13:
grp = '5-12'
df = df2
FEATURES = FEATURES2
elif q <= 22:
grp = '13-22'
df = df3
FEATURES = FEATURES3
for i, (train_index, test_index) in enumerate(gkf.split(X=df, groups=df.index)):
print('Fold:',i+1)
cat_params = {
'iterations': 1000,
'early_stopping_rounds': 90,
'depth': 5,
'learning_rate': 0.02,
'loss_function': "Logloss",
'random_seed': 222222,
'metric_period': 1,
'subsample': 0.8,
'colsample_bylevel': 0.4,
'verbose': 0,
'l2_leaf_reg': 20,
}
train_x = df.iloc[train_index] #.reset_index(drop=True)
train_users = train_x.index.values
train_y = targets[targets['session'].isin(list(train_users))].loc[targets.q == q].set_index('session')
valid_x = df.iloc[test_index] #.reset_index(drop=True)
valid_users = valid_x.index.values
valid_y = targets[targets['session'].isin(list(valid_users))].loc[targets.q == q].set_index('session')
clf = CatBoostClassifier(**cat_params)
clf.fit(train_x[FEATURES].astype('float32'), train_y['correct'],
eval_set=[ (valid_x[FEATURES].astype('float32'), valid_y['correct']) ],
verbose=0)
clf.save_model(f'Cat_question{q}_fold{i}.cbm')
models[f'{grp}_{i}_{q}'] = clf
oof.loc[valid_users, q-1] = clf.predict_proba(valid_x[FEATURES].astype('float32'))[:,1]
模型本地cv
构建真实正确率df:
true = oof.copy()
for k in range(18):
# GET TRUE LABELS
tmp = targets.loc[targets.q == k+1].set_index('session').loc[ALL_USERS]
true[k] = tmp.correct.values
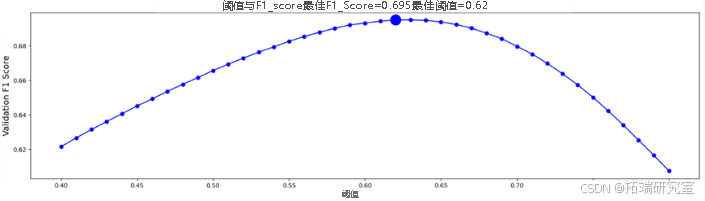
绘制阈值和F1分数
plt.figure(figsize=(20,5))
plt.plot(thresholds,scores,'-o',color='blue')
plt.scatter([best_threshold], [best_score], color='blue', s=300, alpha=1)
plt.xlabel('Threshold',size=14)
plt.ylabel('Validation F1 Score',size=14)
plt.title(f'Threshold vs. F1_Score with Best F1_Score = {best_score:.3f} at Best Threshold = {best_threshold:.3}',size=18)
plt.show()
其中基础xgb模型为:
可以基础xgb的最佳阈值为0.62,本地cv为0.695,Public Score为0.695,Private Score为0.696,其中Private Score为本次竞赛最后所看的分数。
基础模型分数
CV Public Score Private Score
LGB 0.693 0.693 0.694
XGB 0.695 0.695 0.696
Cat 0.696 0.697 0.695
从基础单模来看,XGB在私榜上获得了最高的分数,Cat在本地交叉验证和公榜获得了较高的分数。
分数提升
在开源代码的特征上,我们使用了三种树模型建立了基础框架,在后续的比赛过程中,我们会在这三个框架上不断增加新的技巧以及特征构建,以此来获得更高的分数。
问题准确率分布
参考GUSTHEMA的代码,我们可以发现问题正确率的分布规律,容易发现问题2和问题18中学生基本能够回答出所有问题,而使用基本模型对这两个问题进行预测得到的f1分数往往是这18个问题中最低的。我们使用trick,直接预测问题2和问题18的correct为1,可以提升最后的分数。
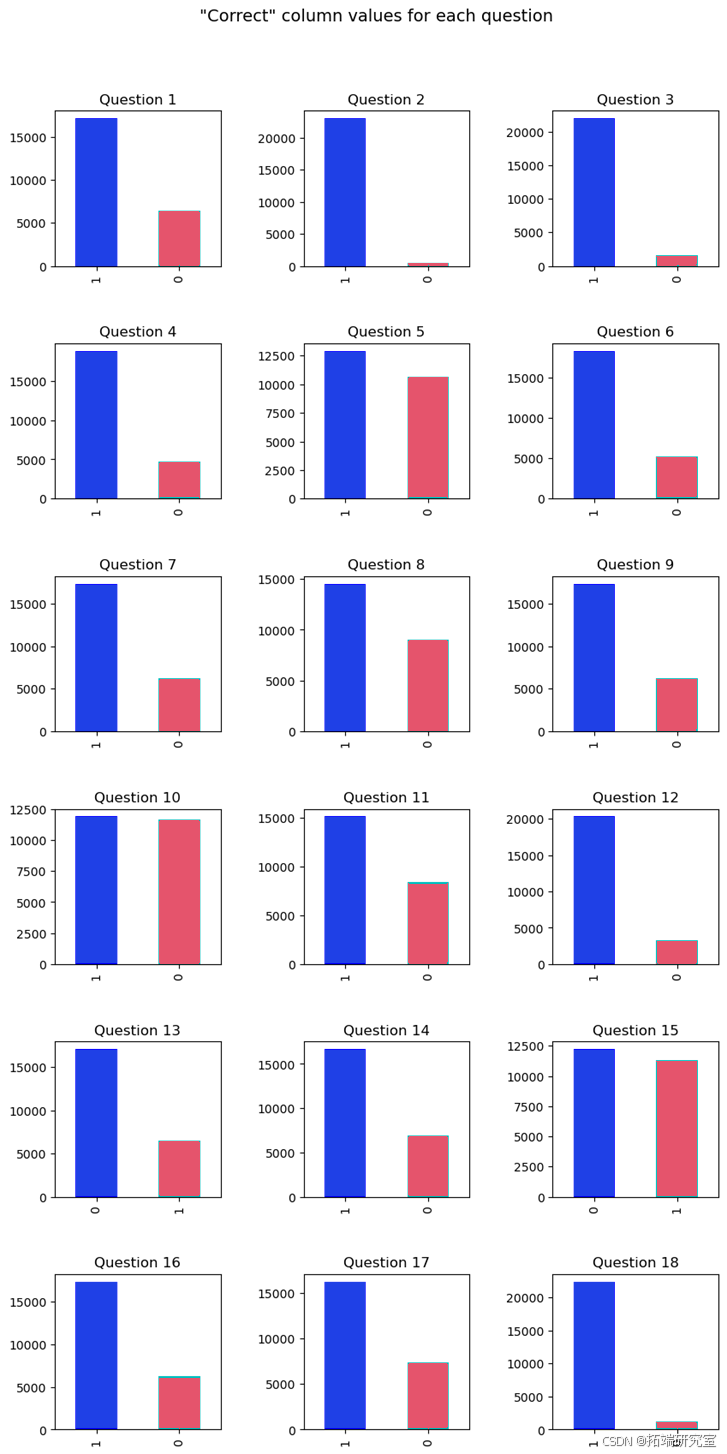
除了直接预测问题2和18的correct为1以外,我们还可以使用一个较低的阈值来保留问题为0的可能性,比如:
mask = sample_submission.session_id.str.contains(f'q{q}')
sample_submission.loc[mask,'correct'] = int( avg_p > 0.1)
数据集合并
我们注意到在提交时,由于我们获得的测试集是一个个level_group得到的,无法在预测前几个问题时获得后面level_group的数据集,但我们能够通过合并之前得到level_group的测试集来获得更多的数据,提高后续问题准确率。在模型训练时候,我们将原数据集按照三个level_group进行拆分后分别进行训练,但如果我们对于第二个level_group:5-12,我们将其与第一个level_group进行合并,然后将最后一个level_group:13-22与之前两个合并。这样在训练时候,后面的问题可以使用更多的数据进行训练,能够提高f1 score,其中训练集的划分为:
df1 = df.filter(pl.col("level_group")=='0-4')
df2 = df.filter((pl.col("level_group")=='5-12') | (pl.col("level_group")=='0-4'))
df3 = df
在提交时,我们需要对得到的数据集进行合并来预测后续问题,我们通过计数器counter来记录当前获得测试集是哪个level_group的,如果是第一个,则用temp_1来存储获得的测试集,当测试集为后续level_group时,将其合并起来,具体代码如下:
limits = {'0-4':(1,4), '5-12':(4,14), '13-22':(14,19)}
counter = 0
for (test, sample_submission) in iter_test:
test = test.sort_values(by = 'index')
session_id = test.session_id.values[0]
grp = test.level_group.values[0]
a,b = limits[grp]
if counter % 3 == 0:
print(test.level_group.values[0], 'FEATURES1')
temp_1 = test
FEATURES = FEATURES1
test = (pl.from_pandas(temp_1)
.sort(["session_id", "elapsed_time"])
.drop(["fullscreen", "hq", "music"])
.with_columns(columns))
test = feature_engineer_04(test)
test = test[FEATURES]
elif counter % 3 == 1:
print(test.level_group.values[0], 'FEATURES2')
temp_2 = pd.concat([temp_1, test])
FEATURES = FEATURES2
test = (pl.from_pandas(temp_2)
.sort(["session_id", "elapsed_time"])
.drop(["fullscreen", "hq", "music"])
.with_columns(columns))
test = feature_engineer_512(test)
test = test[FEATURES]
elif counter % 3 == 2:
print(test.level_group.values[0], 'FEATURES3')
temp_3 = pd.concat([temp_2, test])
FEATURES = FEATURES3
test = (pl.from_pandas(temp_3)
.sort(["session_id", "elapsed_time"])
.drop(["fullscreen", "hq", "music"])
.with_columns(columns))
test = feature_engineer_1322(test)
test = test[FEATURES]
for q in range(a,b):
if q == 2:
mask = sample_submission.session_id.str.contains(f'q{q}')
sample_submission.loc[mask,'correct'] = 1
elif q == 18:
mask = sample_submission.session_id.str.contains(f'q{q}')
sample_submission.loc[mask,'correct'] = 1
else:
total_p = 0
print(f'question{q}', list_contains_all_elements(test.columns, top500_features_list[q-1]))
temp_test = test[top500_features_list[q-1]]
for i in range(5):
clf = models[f'{grp}_{i}_{q}']
p = clf.predict_proba(temp_test.astype('float32'))[0,1]
total_p = total_p + p
avg_p = total_p / 5
mask = sample_submission.session_id.str.contains(f'q{q}')
sample_submission.loc[mask,'correct'] = int( avg_p > best_score)
env.predict(sample_submission)
counter += 1
在使用了“额外”的数据集对模型进行训练和提交后,可以发现除了第一个level_group以外,后续的其他level_group对应问题的分数均有了提高。公榜的分数均提升了至少0.001。
改变抽样方式
开源代码通常使用的抽样方式为分组抽样:
gkf = GroupKFold(n_splits=5)
然而我们本身就需要对这些问题进行分组预测,这样的抽样方式并就没有什么意义,我们将原来的分组抽样改成基于训练样本correct分布的分层抽样,代码如下:
skf = StratifiedKFold(n_splits=5, shuffle=False)
我们使用的是五折分层抽样,并没有打乱顺序,如果需要打乱顺序可以将shuffle为False改为True同时加入参数random_state=42(其中数字随意)。使用五折分层抽样意味着每次抽样会将correct为“0”和“1”的数据各留出1/5作为验证集,这五次抽样的验证集的并集是整个训练集。
通过改变抽样方式,我们能够略微提升模型分数。
特征筛选
特征筛选的目的是减少特征空间的维度,提高模型的性能、减少过拟合的风险,并增加对数据的理解和解释能力。
通过选择与预测目标相关性较高的特征,可以提高机器学习模型的预测性能。不相关或冗余的特征可能会引入噪声或干扰,导致模型性能下降。特征筛选可以剔除这些无关或冗余的特征,使模型更专注于重要的特征,从而提高预测准确性。
过多的特征可能导致模型过于复杂,容易出现过拟合的问题。过拟合指的是模型过度拟合训练数据,无法很好地泛化到新数据。通过特征筛选,可以减少特征的数量,降低模型的复杂性,从而减少过拟合的风险。
通过减少特征的数量,可以降低机器学习模型的计算资源需求和训练时间开销。在大规模数据集和复杂模型的情况下,特征筛选可以显著提高计算效率,加快模型训练和推断的速度。
我们在lgb的框架上筛选重要性为前500的特征:
dfs = []
top500_features_list = []
for q in range(1, 19):
# USE THIS TRAIN DATA WITH THESE QUESTIONS
print(f"question{q}")
if q <= 3:
grp = '0-4'
df = df1
n = 400
FEATURES = FEATURES1
elif q <= 13:
grp = '5-12'
df = df2
n = 500
FEATURES = FEATURES2
elif q <= 22:
grp = '13-22'
df = df3
n = 700
FEATURES = FEATURES3
temp = targets.loc[targets['question'] == q]
top500_features_list包含了每个问题的前500重要性的特征,后续重新训练时候读入特征,得到lgb模型:
clf.fit(train_x[top500_features_list[q-1]].astype('float32'), train_y['correct'], eval_set=[ (valid_x[top500_features_list[q-1]].astype('float32'), valid_y['correct']) ], verbose=0)
我们在lgb模型的框架下得到:
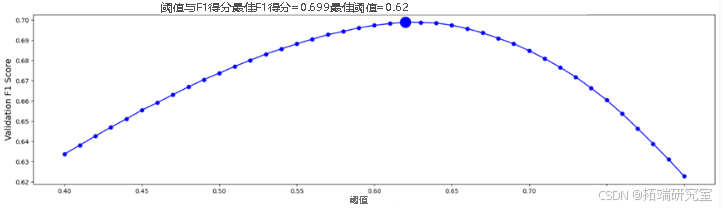
可以看到本地交叉验证cv分数达到0.699,而公榜分数为0.698,私榜分数达到了0.701。由于该模型的公榜分数较低,被我们放弃。
XGB+GPU
虽然比赛规定不能使用GPU和Internet我们可以使用GPU进行训练,在得到模型后infer得到submission,其中XGB只需要修改一行代码即可
将tree_method从原来的hist改为gpu_hist即可。
其中cv分数为0.696,公榜分数为0.699,私榜分数为0.698.
特征工程
在进行大量特征实验后,加入了很多分位数特征与elapsed_time_diff更细精度的特征:
`
`[pl.col("elapsed_time_diff").filter(pl.col('text').str.contains(c)).quantile(0.3).alias(f'quantile0.3&word_max_{c}') for c in DIALOGS if f'quantile0.3&word_max_{c}' in all_fea],
*[pl.col("elapsed_time_diff").filter(pl.col('text').str.contains(c)).quantile(0.5).alias(f'quantile0.5word_max_{c}') for c in DIALOGS if f'quantile0.5word_max_{c}' in all_fea],
*[pl.col("elapsed_time_diff").filter(pl.col('text').str.contains(c)).quantile(0.65).alias(f'quantile0.65word_max_{c}') for c in DIALOGS if f'quantile0.65word_max_{c}' in all_fea],
*[pl.col("elapsed_time_diff").filter(pl.col('text').str.contains(c)).quantile(0.8).alias(f'quantile0.8word_max_{c}') for c in DIALOGS if f'quantile0.8word_max_{c}' in all_fea],
…
*[pl.col("elapsed_time_diff").filter((pl.col("event_name")==e)&(pl.col("name")==n)&(pl.col("room_fqid")==r)).sum().alias(f"etd&name{n}&eventname{e}&room{r}") for e in event_name_feature for n in name_feature for r in room_lists if f"etd&name{n}&eventname{e}&room{r}" in all_fea],
*[pl.col("elapsed_time_diff").filter((pl.col("event_name")==e)&(pl.col("name")==n)&(pl.col("level")==l)).sum().alias(f"etd&name{n}&eventname{e}&level{l}") for e in event_name_feature for n in name_feature for l in LEVELS if f"etd&name{n}&eventname{e}&level{l}" in all_fea],
*[pl.col("elapsed_time_diff").filter((pl.col("room_fqid")==r)&(pl.col('text').str.contains(d))).sum().alias(f"etd&room{r}&diag{d}") for d in DIALOGS for r in room_lists if f"etd&room{r}&diag{d}" in all_fea],
*[pl.col("elapsed_time_diff").filter((pl.col("text_fqid")==t)&(pl.col('text').str.contains(d))).sum().alias(f"etd&text{t}&diag{d}") for d in DIALOGS for t in text_lists if f"etd&text{t}&diag{d}" in all_fea],
XGB需要大量的特征进行尝试,所有特征在筛选之前加起来大约1万多个,在polars库和GPU的使用下,时间还算可控。我们最终得到本地CV分数为0.7,公榜分数为0.7,私榜分数为0.698.
模型融合
我们舍去了耗费时间很长的Cat以及cv和公榜分数相差较大的lgb,也由于时间有限,我们融合的模型均为XGB+GPU模型。
融合的三个模型的特征工程有所差别,特征选取数量有所区别。我们将分数最好的单模给予权重0.7,剩下两个按照分数设置权重为0.2和0.1。同时将问题2、18和12的correct直接设置为1,问题13的预测correct直接设置为0.
最终得到公榜分数为0.702,私榜分数为0.7.这个融合方案也是最后拿到银牌方案。
关于分析师

Qi Zhang是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在复旦大学完成了硕士学位,专注深度学习、机器学习、数据分析等领域。擅长Python。
