全文链接:https://tecdat.cn/?p=37060
本文旨在通过应用多种机器学习技术,对交易所的历史数据进行深入分析和预测。我们帮助客户使用了遗传算法GA优化的支持向量回归(SVR)、自适应神经模糊推理系统(ANFIS)等方法,对数据进行了特征选择、数据预处理、模型训练与评估。实验结果表明,这些方法在预测证券交易所指数(ISE)方面具有显著效果,为投资者和市场分析师提供了有价值的参考。
引言
股票指数(ISE)的波动直接影响投资者的决策。因此,准确预测ISE的走势对于市场参与者至关重要。本文利用机器学习技术,通过构建多种预测模型,对ISE的历史数据进行了详细分析,以期提高预测的准确性和实用性。
数据准备与预处理
数据集描述
本文使用的数据集来源于证券交易所,包含了一系列可能影响ISE指数波动的经济指标。数据集以CSV格式存储,通过Pandas库进行读取和处理。
pd.read_csv('Is.csv', delimiter=';')
#print(df.head())
return DataPrepare(df)
#data, target = ReadData()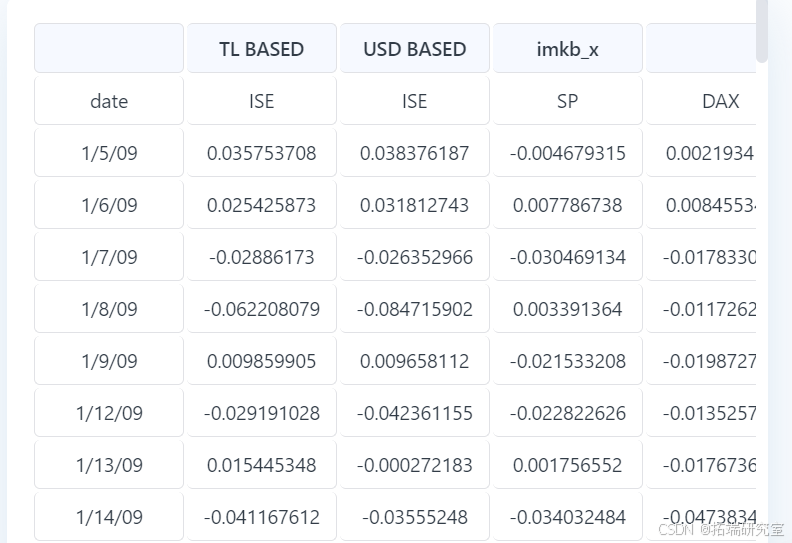
# 重新加载数据,跳过可能包含重复列标题的行
df = pd.read_csv(file_path, delimiter=';', skiprows=[0, 1])
# 显示数据的前几行以确认结构
df.head()
# 重命名列名以反映数据的实际含义
df.columns = ['Date', 'ISE', 'ISE_USD', 'SP', 'DAX', 'FTSE', 'NIKKEI', 'BOVESPA', 'EU', 'EM']
# 将日期列转换为日期类型
df['Date'] = pd.to_datetime(df['Date'], format='%d-%b-%y')
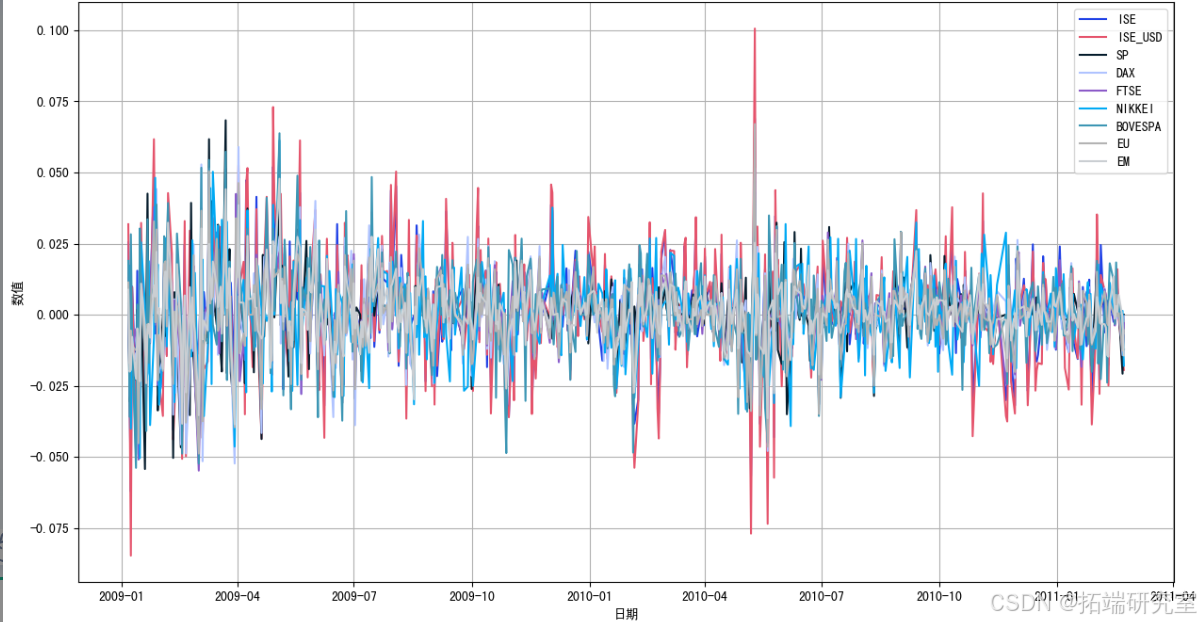
# 绘制时间序列图
plt.figure(figsize=(15, 8))
for col in df.columns[1:]:
plt.plot(df['Date'], df[col], label=col)
plt.title('时间序列数据可视化 - 证券交易所')
plt.xlabel('日期')
plt.ylabel('数值')
plt.legend()
plt.grid(True)
plt.show()
# 重命名列名以反映数据的实际含义
df.columns = ['Date', 'ISE', 'ISE_USD', 'SP', 'DAX', 'FTSE', 'NIKKEI', 'BOVESPA', 'EU', 'EM']
# 将日期列转换为日期类型
df['Date'] = pd.to_datetime(df['Date'], format='%d-%b-%y')
# 绘制时间序列图
plt.figure(figsize=(15, 8))
for col in df.columns[1:]:
plt.plot(df['Date'], df[col], label=col)
plt.title('时间序列数据可视化 - 证券交易所')
plt.xlabel('日期')
plt.ylabel('数值')
plt.legend()
plt.grid(True)
plt.show()
数据预处理步骤
- 列名与索引处理:将第一行数据作为列名,并删除该行。同时,调整列名以匹配数据含义,如将“ISE”列重命名为“ISE.TL”和“ISE.USD”。
- 日期处理:将日期列转换为时间戳格式,以便进行时间序列分析。
- 特征与目标分离:将ISE指数作为目标变量,其余经济指标作为特征变量。
特征选择与降维
特征选择
通过随机森林回归模型进行特征选择,设定阈值为0.25,筛选出对目标变量影响较大的特征。该方法有效减少了模型的复杂度,提高了预测效率。
数据标准化
使用MinMaxScaler对数据进行标准化处理,确保所有特征在同一量纲下,避免因量纲差异导致的预测偏差。
模型构建与训练
支持向量回归(SVR)
采用RBF核函数的SVR模型对数据进行训练,通过调整C和epsilon参数优化模型性能。此外,还尝试使用遗传算法(GA)对SVR的参数进行全局优化,进一步提升预测精度。
自适应神经模糊推理系统(ANFIS)
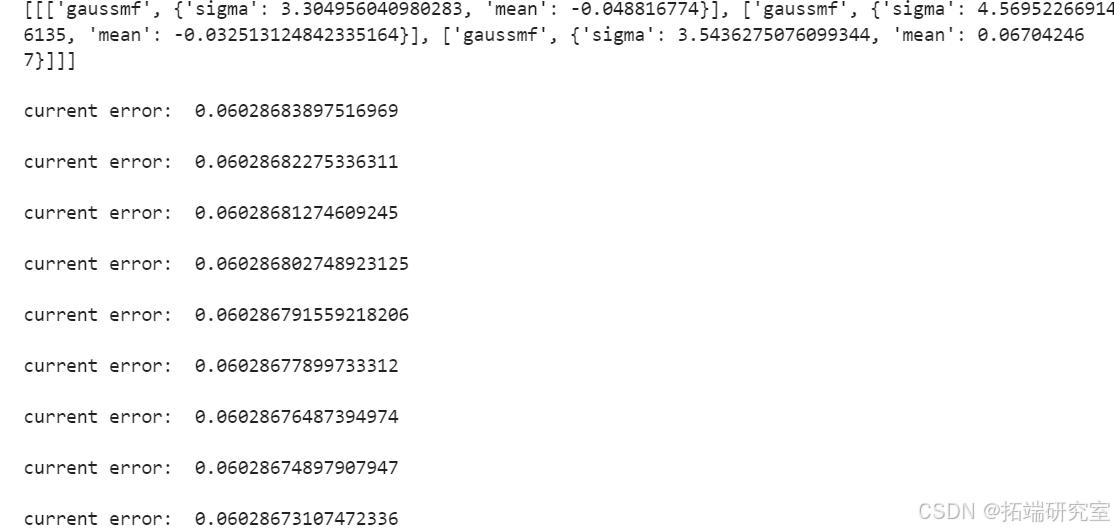
构建ANFIS模型,通过构造高斯型隶属函数并训练模型,实现对ISE指数的模糊推理预测。同样,使用遗传算法对隶属函数的sigma参数进行优化,提高模型的适应性和准确性。
模型评估
评估指标
采用解释方差得分(explained variance score)、R²得分(r2_score)和均方根误差(RMSE)作为模型评估指标,全面衡量模型的预测性能。
实验结果
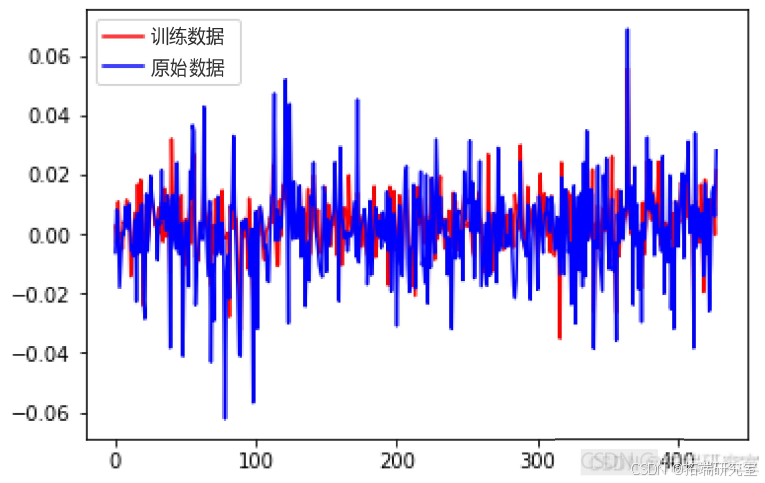
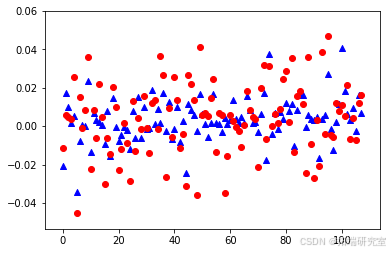
- SVR模型:在遗传算法优化参数后,SVR模型的预测性能显著提升,尤其是在解释方差得分和R²得分方面表现优异。
SVMEvaluate(svr_model, x_test, y_test)-
-
遗传算法优化
SVMGA() print(datetime.now()-start) SVM_ACO_Points

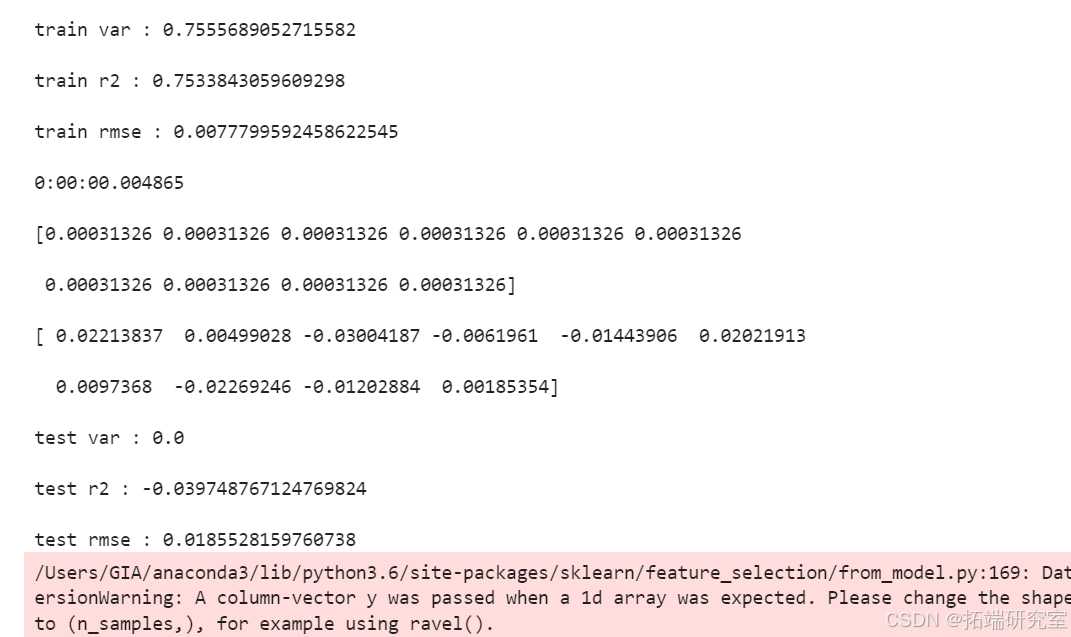
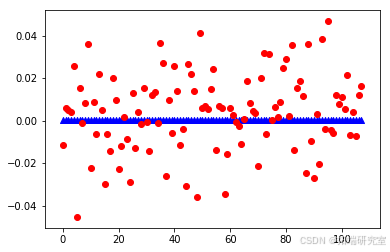
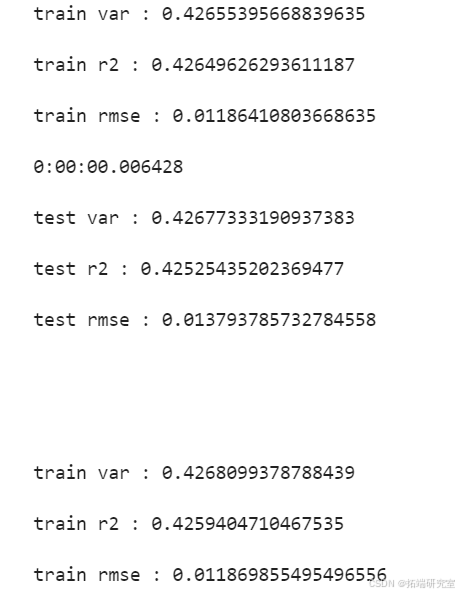
SVMEvaluate(svr_model, x_test, y_test)
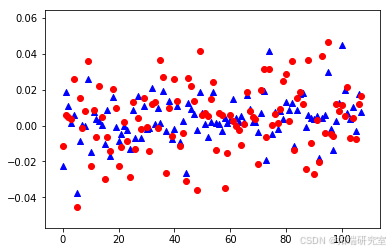
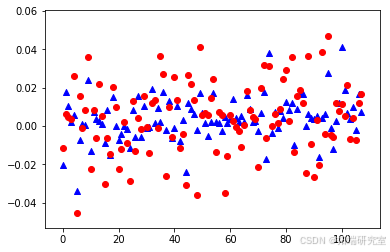
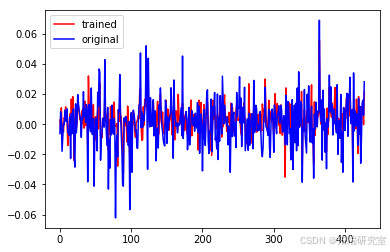
- ANFIS模型:通过遗传算法优化隶属函数参数,ANFIS模型在模糊推理预测中展现了良好的适应性和准确性,特别是在处理非线性关系时表现突出。
ANFISEvaluate(anf, x_test, y_test)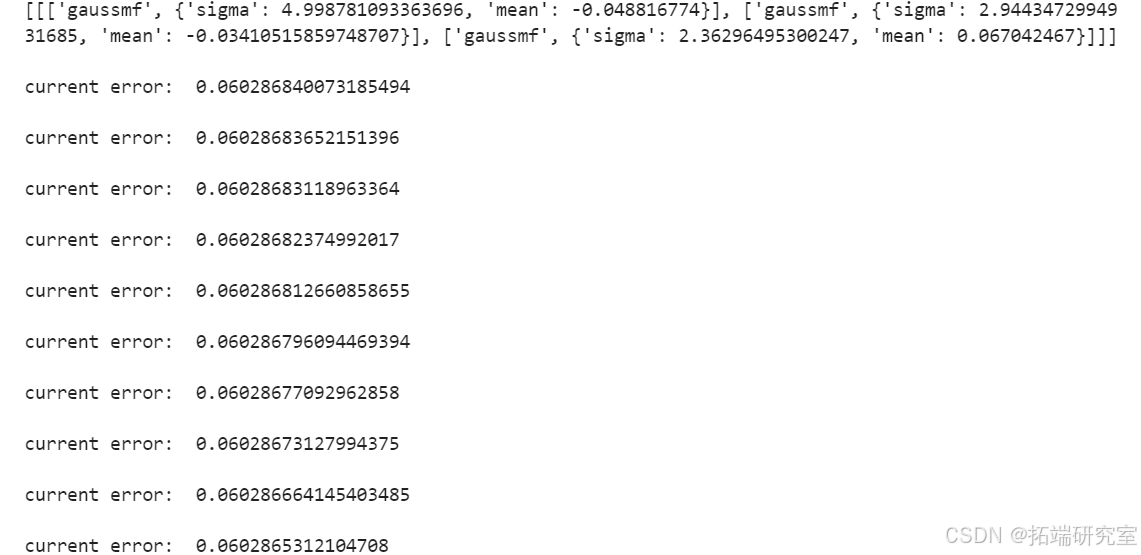
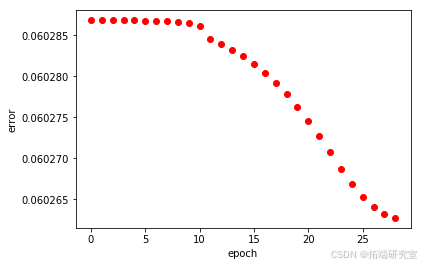
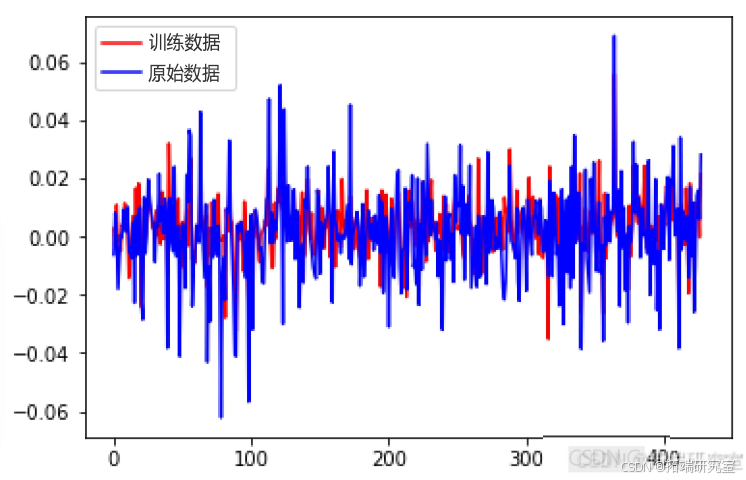
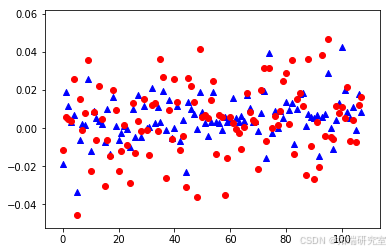
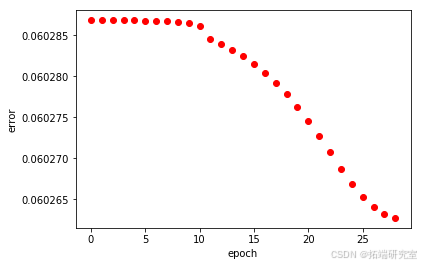
ANFIS模型:遗传算法优化后的ANFIS
ANFISGA()
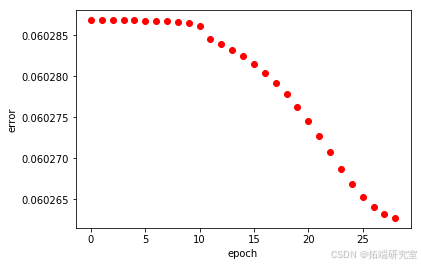
print(datetime.now()-start)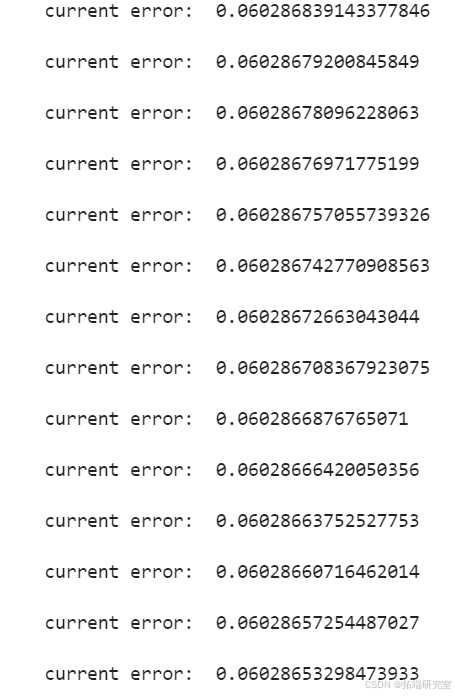
结论与展望
本文通过应用多种机器学习技术,对证券交易所的历史数据进行了深入分析和预测。实验结果表明,SVR和ANFIS模型在预测ISE指数方面具有显著效果。未来工作可以进一步探索更多先进的机器学习算法,如深度学习模型,以及结合更丰富的数据源,以进一步提高预测的准确性和实用性。同时,也可以考虑将预测结果应用于实际的投资决策中,为投资者提供更为精准的市场分析服务。
参考文献
[1]阚子良,蔡志丹.基于优化参数的LS-SVM模型的股票价格时间序列预测[J].长春理工大学学报(自然科学版).2018,(1).
[2]郝知远.基于改进的支持向量机的股票预测方法[J].江苏科技大学学报(自然科学版).2017,(3).DOI:10.3969/j.issn.1673-4807.2017.03.015 .
[3]傅航聪,张伟.机器学习算法在股票走势预测中的应用[J].软件导刊.2017,(10).DOI:10.11907/rjdk.171549 .
[4]郝知远.基于数据挖掘方法的股票预测系统[D].2017.
[5]张建宽,盛炎平.支持向量机对股票价格涨跌的预测[J].北京信息科技大学学报(自然科学版).2017,(3).DOI:10.16508/j.cnki.11-5866/n.2017.03.008 .
[6]毕军龙.基于股指涨跌预测的投资策略[D].2016.
[7]Kumar, Deepak,Meghwani, Suraj S.,Thakur, Manoj.Proximal support vector machine based hybrid prediction models for trend forecasting in financial markets[J].Journal of computational science.2016,17(Nov. Pt.1).1-13.DOI:10.1016/j.jocs.2016.07.006 .
[8]尹小琴.基于支持向量机的混合时间序列模型的研究与应用[D].2016.
[9]朱磊.基于支持向量机的股价预测研究--以上证50成分股为例[D].2016.
[10]冯华萍.基于支持向量机的股票价格预测算法研究及应用[D].2016.