目录
1、ollama
定义: ollama 是一个本地的大模型运行框架
下载地址:Ollama
ollama的一些操作命令:
# 拉取大模型llama3
ollama pull llama3
# 运行大模型llama3,若ollama下没有模型,则先下载再运行。之后就可以在命令行问问题,或者使用其他方式使用大模型的能力
ollama run llama3
# 查看ollama下的大模型列表
ollama list
# 删除大模型llama3
ollama rm llama3
# 复制大模型
ollama cp llama3 my-model
# 查看大模型详细信息
ollama show llama3
# 更多操作,详见 https://github.com/ollama/ollama使用的方式:
- 命令行
- 运行大模型之后,直接问问题
- 运行大模型之后,直接问问题
- WebUI:
- 例如:open-webui
- 地址:https://github.com/open-webui/open-webui
- docker启动命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main - 访问地址:
-
- 其他方式

2、fastgpt
定义:FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
docker快速部署参考:Docker Compose 快速部署 | FastGPT
快速部署:
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
# pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
# milvus 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-zilliz.yml修改配置:
config.json:
config.json 修改 llmModels(大语言模型) 和 vectorModels (向量模型)的配置。
例如:大语言模型我使用了qwen2:latest,则有如下配置:
"llmModels": [
{
"model": "qwen2:latest", // 模型名(对应OneAPI中渠道的模型名)
"name": "qwen2:latest", // 模型别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 16000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 13000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": false, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
}
]向量模型我使用了m3e,则有如下配置:
"vectorModels": [
{
"model": "m3e",
"name": "m3e(测试专用)",
"price": 0,
"defaultToken": 500,
"maxToken": 1800
}
]在fastgpt中,大语言模型和向量模型都可以配置多个。
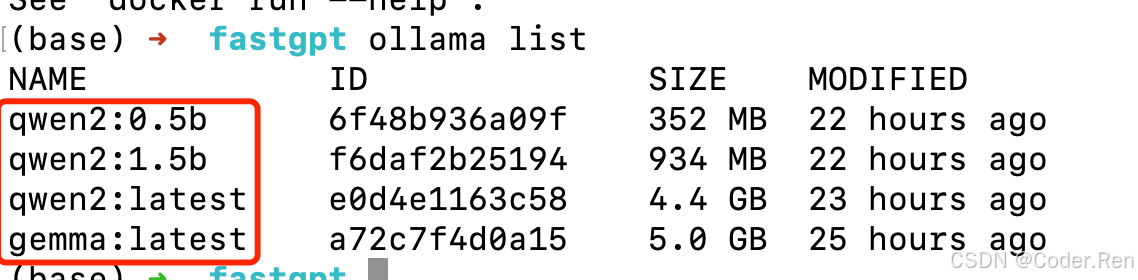
大语言模型的名称可以查询ollama下的模型列表(ollama list)找到:
上面的m3e向量模型在ollama中没有,所以我们需要下载和运行。命令如下:
# 使用CPU运行
docker run -d --name m3e -p 6008:6008 registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
# nvida-docker 使用GPU
docker run -d --name m3e -p 6008:6008 --gpus all registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api可以根据自己电脑是否有GPU运行的条件决定使用哪个启动命令。
docker-compose.yml:
docker-compose.yml 需要修改如下内容:(若其他镜像配置的端口有冲突&#x