文章目录
创建yaml
使用kubectl创建一个yaml文件
root@node1 home]# kubectl create deployment web --image=nginx -o yaml --dry-run > web.yaml
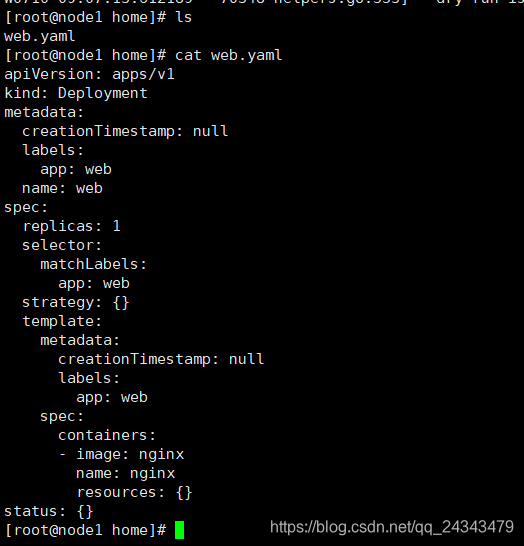
使用kubectl get创建一个yaml文件
[root@node1 home]# kubectl get deploy nginx -o=yaml > nginx.yaml
Pod基本概念概述
- pod是k8s系统中的最小部署单元
- pod是由一个或多个容器组成。
- 一个pod中容器共享网络命名空间
- 每个pod都有一个根容器(pause容器)用来管理pod中的用户业务容器
Pod存在意义
- 创建容器使用docker,一个docker对应一个应用程序,一个容器运行一个应用程序
- Pod是多进程设计,运行多个应用程序
- 一个pod有多个容器,一个容器里面运行一个应用程序
- Pod存在未了亲密性应用
- 两个应用直接进行校核
- 网络之间调用
- 两个应用需要频繁调用
Pod实现机制
共享网络
由于容器本身之间相互隔离,通过linux namespace、group组实现隔离。pod要实现共享网络机制,需要具备同一个pod里面的容器共享namespace
如何解决同一个pod里面的容器共享namespace?
pod中有一个pause(info容器),创建pod时会自动创建,用来管理其他业务容器,创建业务容器时,将业务容器加入到info容器中,info容器会独立出ip mac port,让所有业务容器放到同一个namespace中
共享存储
引入数据卷概念Volumn,使用数据卷进行持久化存储
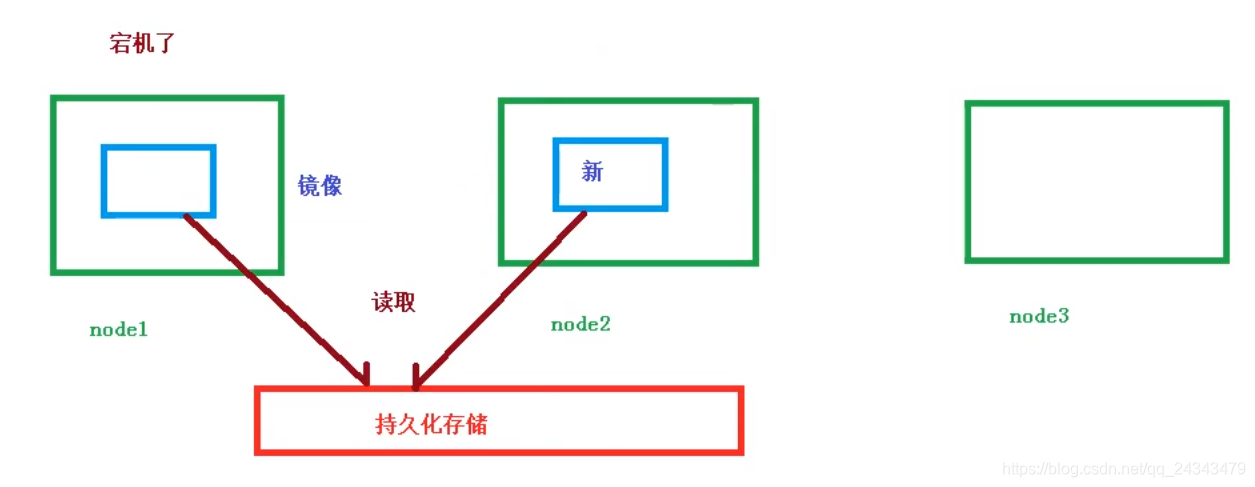
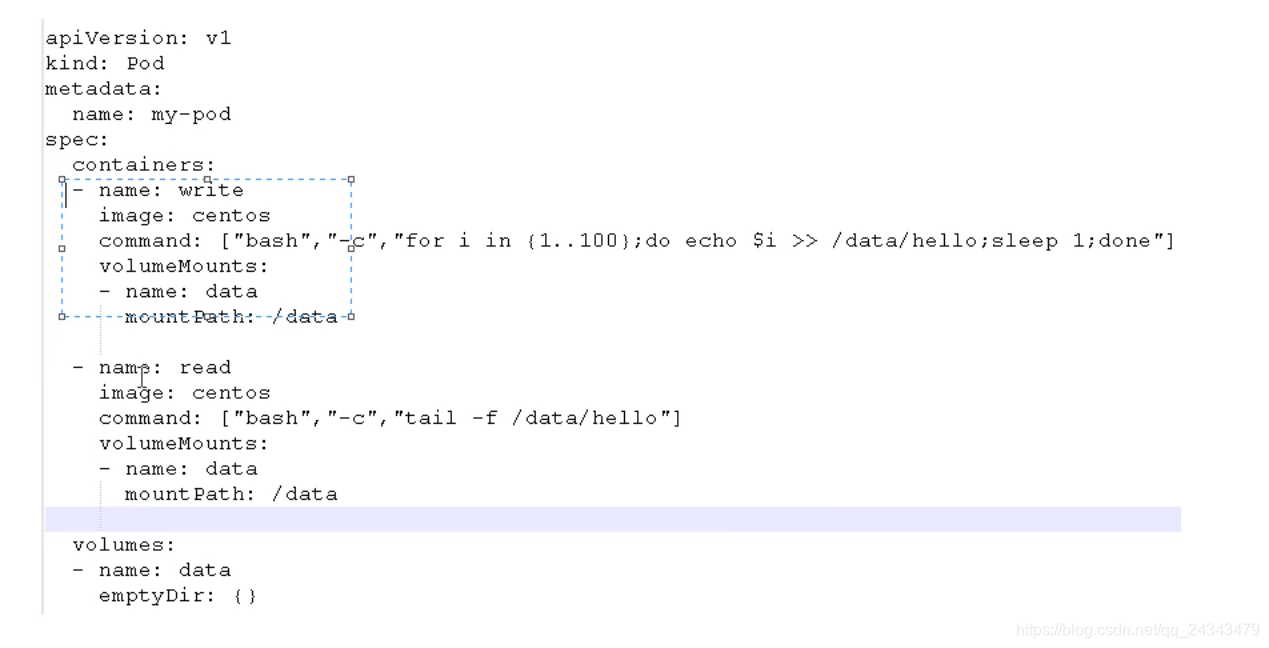
操作实例
镜像拉取策略
apiVersion: v1
king: Pod
metadata:
name: mypod
spec:
containers:
- name: nginx
image: nginx:1.14
imagePullPolicy: Always
- IfNotPresent: 默认值,镜像在宿主机上不存在时才拉取
- Always: 每次创建Pod都会重新拉取一次镜像
- Never: Pod永远不会主动拉取这个镜像
Pod资源限制
sepc:
containers:
- name: db
image: mysql
- resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m
-
spec.containers[].resources.limits.cpu
在运行过程中容器所能使用的最大CPU -
spec.containers[].resources.limits.memory
在运行过程中容器所能使用的最大内存 -
spec.containers[].resources.requests.cpu
容器所能申请的最少CPU -
spec.containers[].resources.requests.memory
容器所能申请的最少内存。500m == 0.25c
Pod重启机制
apiVersion: v1
kind: Pod
metadata:
name: dns-test
spec:
containers:
- name: busybox
image: busybox:1.28.4
args:
- /bin/sh
- -c
- sleep 36000
restartPolicy: Never
- Always: 当容器终止退出后,总是重启容器,默认策略
- OnFailure: 当容器异常退出(退出状态码非0)时,才重启容器。
- Never: 当容器终止退出,从不重启容器
Pod健康检查
- livenessProbe
存活检查,如果检查失败,将杀死容器,根据Pod的restartPolicy来操作 - readinessProbe
就绪检查,如果检查失败,Kubernates会把Pod从service endpoints中剔除
Probe三种检查方法:
- httpGet
发送HTTP请求,返回200-400范围状态码为成功 - exec
执行shell命令返回状态码是0为成功 - tcpSocket
发起TCP Socket建立成功
Pod创建流程
1. pod创建
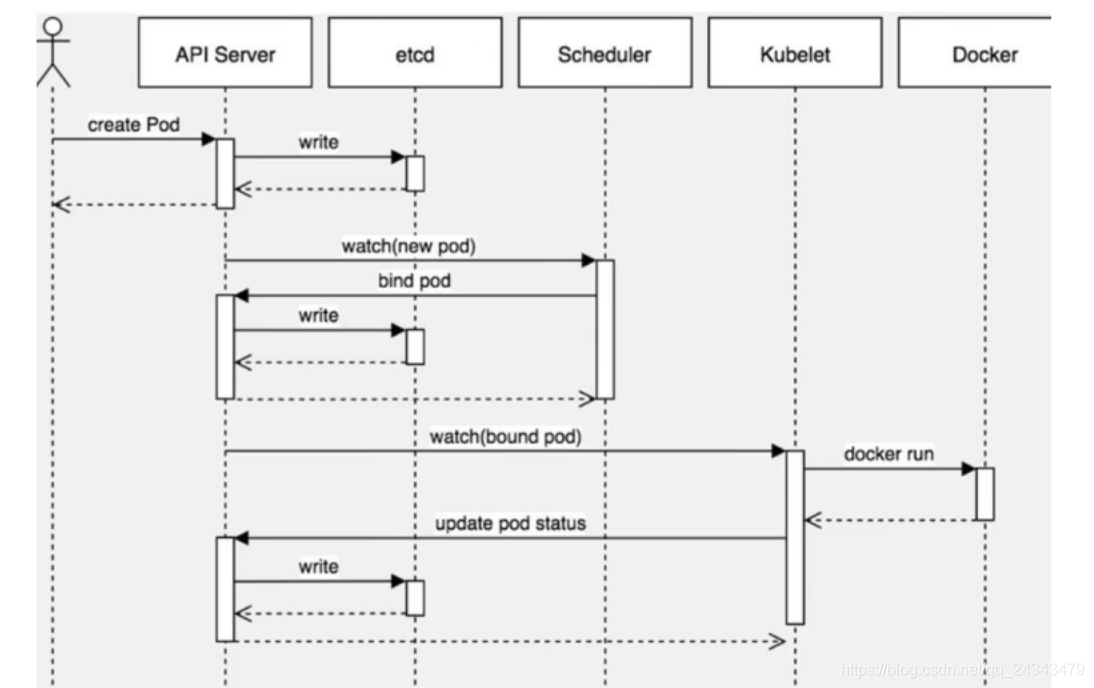
- create pod --> apiServer --> 写入etcd
- Scheduler监控apiServer是否有需要创建的pod,通过调度算法把pod调度到具体的node节点,
- kubelet --> api Server -->读取etcd拿到分配给当前节点pod --> docker创建容器
2.影响Pod调度的属性
- pod资源限制对pod调用产生影响
根据request找到足够node节点进行调度 - 节点选择器标签对pod调用产生影响
spec:
nodeSelector:
env_role: develop
containers:
- name: nginx
image: nginx:1.15
需要对node节点加标签
[root@node1 home]# kubectl label node node2 env_role=develop
node/node2 labeled
查看节点标签
[root@node1 home]# kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
node2 Ready <none> 5d19h v1.19.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,env_role=develop,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux
node3 Ready <none> 5d17h v1.19.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node3,kubernetes.io/os=linux
[root@node1 home]#
删除节点标签

[root@node1 home]# kubectl label nodes node2 env_role-
- 节点亲和性影响Pod调度
nodeAffinity和nodeSelector基本一样,根据节点上标签约束来决定Pod调度到那个节点上
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requireDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: env_role
operator: In
values:
- develop
- test
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: group
oprator: In
values:
- otherprod
containers:
- name: webdemo
image: nginx
(1)硬亲和性
requireDuringSchedulingIgnoredDuringExecution 必须满足
(2)软性和性
preferredDuringSchedulingIgnoredDuringExecution 尝试满足
oprator主要支持操作
In、NotIn、Exists、Gt、Lt、DoesNotExists
- 污点和污点容忍
Taint污点,节点不做普通分配,
- NoSchedule
节点一定不会被调用 - PreferNoSchedule
节点尽量不会被调用 - NoExecute
不会调度,并且还会驱逐Node上已有的Pod
查看节点污点情况
[root@node1 home]# kubectl describe node node2 | grep Taint
Taints: <none>
[root@node1 home]#
为节点添加污点
[root@node1 home]# kubectl taint node node2 env_role=yes:NoSchedule
node/node2 tainted
[root@node1 home]# kubectl describe node node2 | grep Taint
Taints: env_role=yes:NoSchedule
[root@node1 home]#
演示
[root@node1 home]# kubectl delete deployment nginx
[root@node1 home]# kubectl get pods -o wide
[root@node1 home]# kubectl create deployment nginx --image=nginx
[root@node1 home]# kubectl scale deployment nginx --replicas=3
[root@node1 home]# kubectl get pods -o wide
最后创建的pod都在node3节点上,应为node2节点已经被设置为污点节点不可用。
为节点取消污点

[root@node1 home]# kubectl describe node node2 | grep Taint
Taints: env_role=yes:NoSchedule
[root@node1 home]# kubectl taint node node2 env_role:NoSchedule-
node/node2 untainted
[root@node1 home]# kubectl describe node node2 | grep Taint
Taints: <none>
[root@node1 home]#
污点容忍
spec:
tolerations:
- key: "env_role"
operator: "Equal"
value: "yes"
effect: "NoSchedule"
设置污点容忍,创建pod可能会在node2上创建也有可能不会创建
Pod相关命令
[root@node1 home]# kubectl get pods,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-6799fc88d8-dz64w 1/1 Running 0 5d14h
[root@node1 home]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-6799fc88d8-dz64w 1/1 Running 0 5d16h 10.244.0.2 node2 <none> <none>
[root@node1 home]#