一、awk概述
AWK是一种解释执行的编程语言,它支持条件判断、循环控制等。被设计用来专门处理文本数据。AWK的名称是由它们的设计者的姓氏的首个字母组成的 --- Afred Aho, Peter Weinberger与Brain Kernighan。
由GNU/Linux发布的AWK版本通常被称为GNU AWK,由自由软件基金(Free Software Foundation, FSF)负责开发维护的。目前总共有如下几种不同的AWK版本:
- AWK --- 这个版本是AWK最原始的版本,它由AT&T实验室开发。
- NAWK --- New AWK是AWK的改进增强版本。
- GAWK --- 即GNU AWK,所有的GNU/Linux发行版都包括GAWK,且GAWK完全兼容AWK与NAWK。Linux中最常用的还是GAWK。

1.1 AWK的典型应用场景
其实AWK可以做非常多的工作。下面只是其中的一小部分:
- 文本处理
- 生成格式化的文本报告
- 进行算术运算
- 字符串操作等。
既然AWK也可以做文本处理,它和之前我们学习的grep、sed有啥区别呢?其实grep、sed、awk被称为Linux中的“三剑客”。让我们来看一下这“三剑客”的特长:
| grep | 更适合单纯的查找或匹配文本。 |
| sed | 更适合编辑匹配到的文本。 |
| awk | 更适合格式化文本,对文本进行较复杂格式处理。 |
二、awk工作流程
- 接下来我们一起学习一下AWK是如何工作的。要想成为AWK专家,你必须的了解其内部工作的原理。
- AWK执行的流程非常简单:读(Read)、执行(Execute)与重复(Repeat)。下面的流程图描述出了AWK的工作流程:
- 读(Read)
AWK从输入流(文件、管道或标准输入)中读取一行,然后将其存入内存中。
- 执行(Execute)
对于每一行的输入,所有的AWK命令按顺序执行。
- 重复(Repeat)
一直重复上述两个过程,直到文件结束。
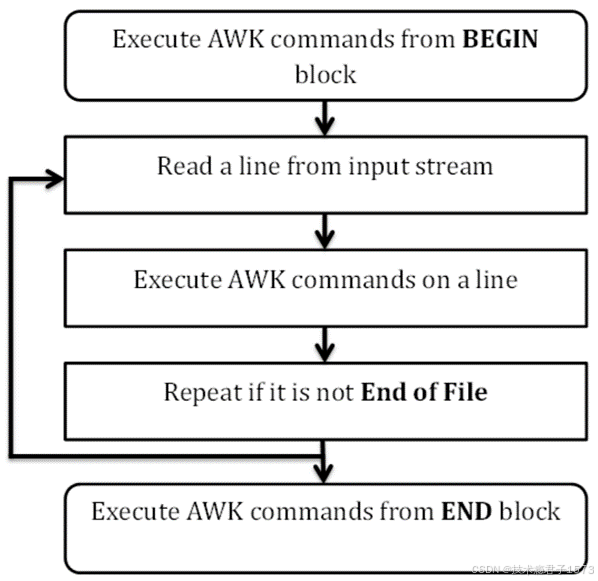
从上图我们已经了解了AWK程序的工作流程。接下来我们来一起学习一下AWK程序的结构。
- 开始块(BEGIN block)
顾名思义,开始块就是在程序启动的时候执行的代码部分,并且它在整个过程中只执行一次。一般情况下,我们在开始块中初始化一些变量。BEGIN是AWK的关键字,因此它必须是大写的。不过,开始块部分是可选的,你的程序可以没有开始块部分。
- 主体块(Body Block)
对于每一个输入的行,都会执行一次主体部分的命令。默认情况下,对于输入的每一行,AWK都会执行命令。注意:在主体块部分,没有关键字存在。
- 结束块(END Block)
它是在程序结束时执行的代码。END也是AWK的关键字,它也必须大写。与开始块相似,结束块也是可选的。
- 接下来,我们看一个简单的示例,感知一下AWK的BEGIN块的特性:
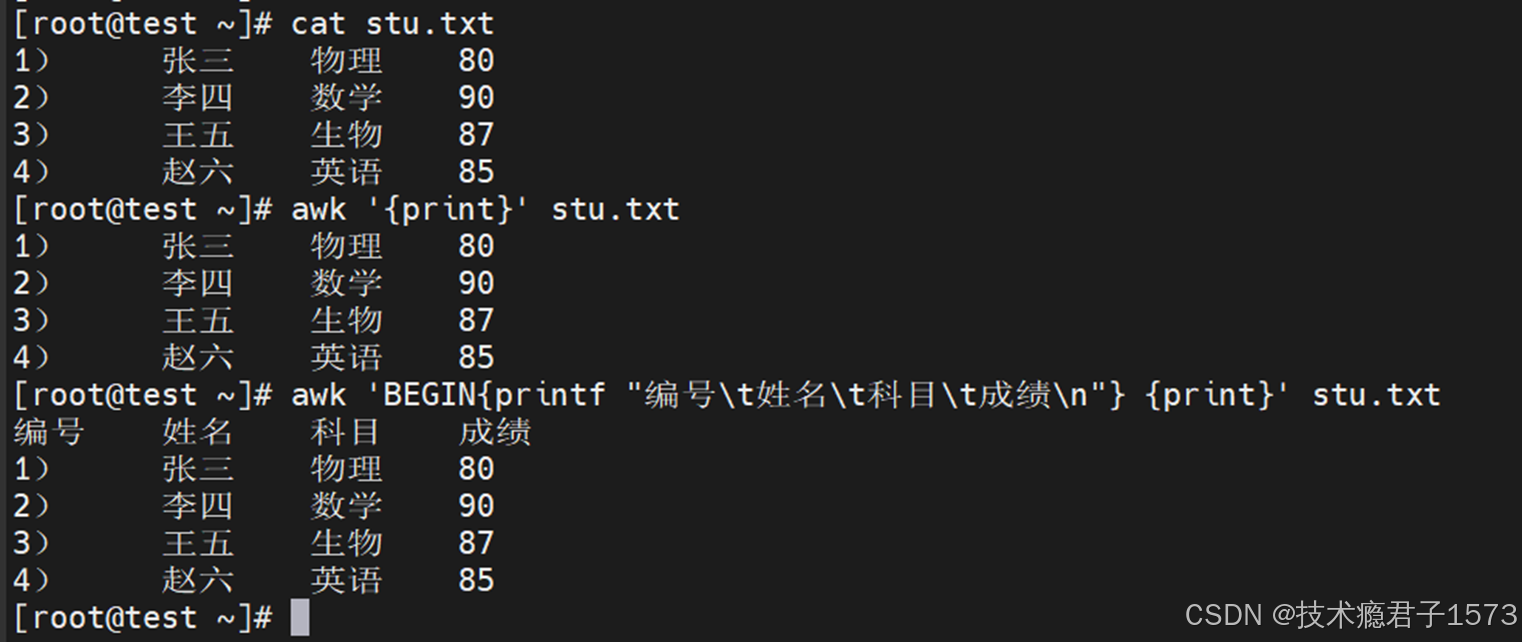
过程:程序启动时,AWK在开始块中输出表头信息。在主体块中,AWK每读入一行就将读入的内容输出到标准输出流中,一直到整个文件被全部读入为止。
三、awk基本语法
AWK的基本语法如下:
awk [options] ' Pattern{Action} '<file>
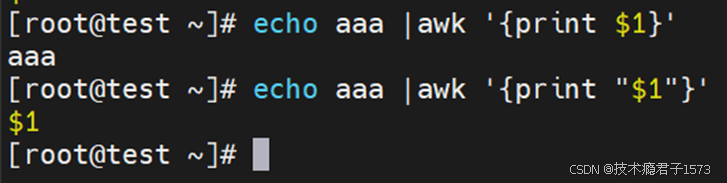
- 对于上面的这个语法,我们先从必选参数action来解释,从字面上理解就是动作,awk擅长文本格式化,并且将格式化以后的文本输出,所以awk中最常用的动作就是print和printf。
- 先看一些简单的示例,认识一下Action。
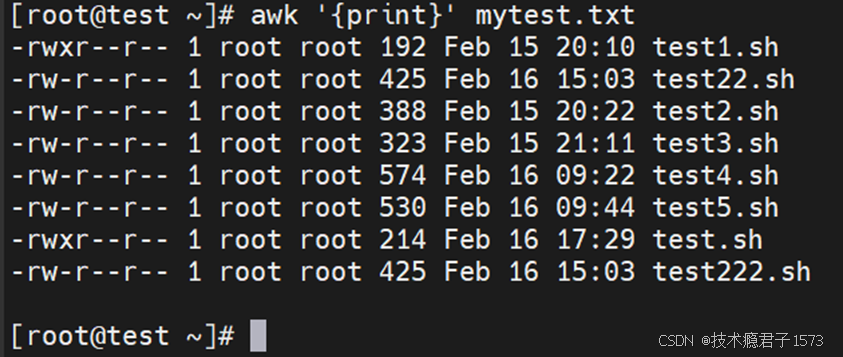
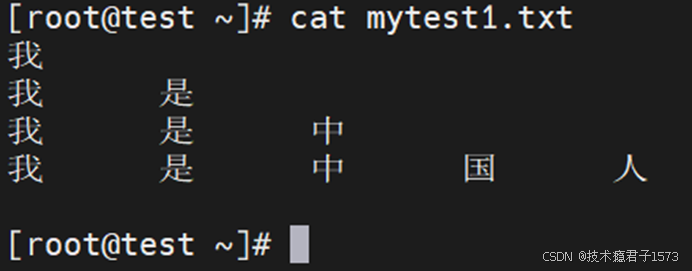
下图,我们只是使用awk执行了一个打印的动作,将mytest.txt文件内容的内容给打印出来。
接下来,我们看看类似的一个场景:
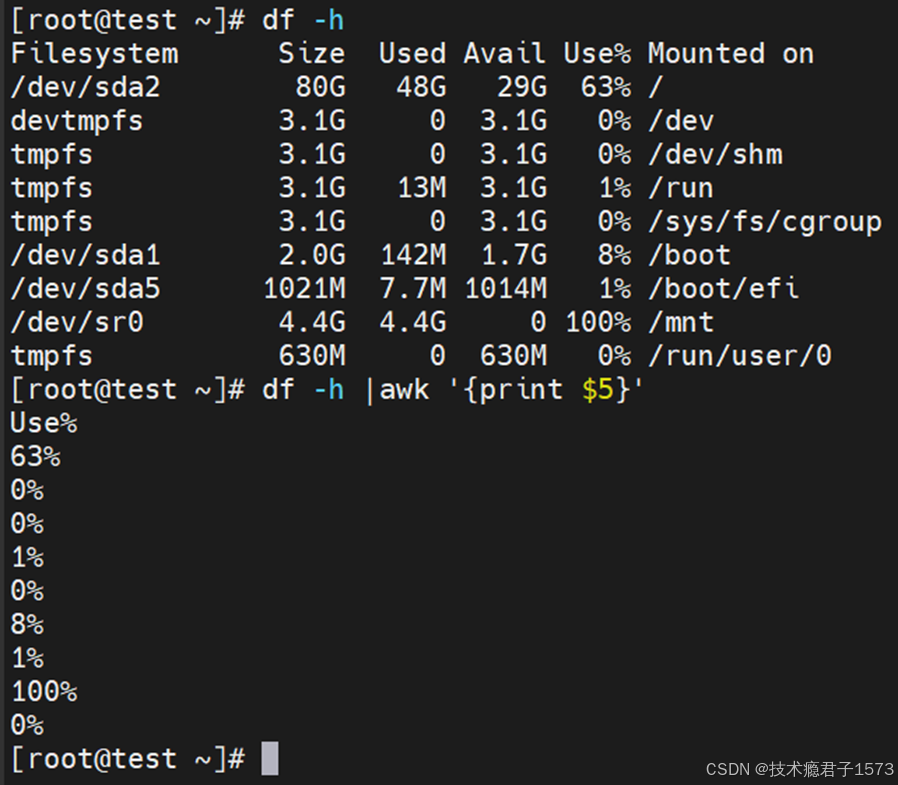
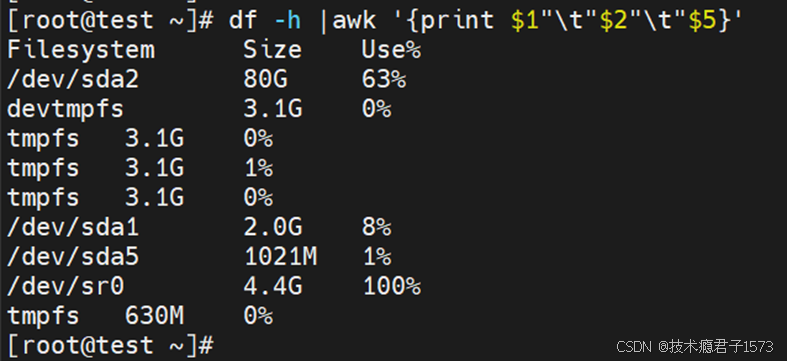
下图的awk '{print $5}',表示输出信息的第5列数据,$5表示将当前行按照分隔符分割后的第5列,不指定分隔符时,默认使用空格作为分隔符。当有连续多个空格时,awk自动将连续的空格理解为一个分隔符。
Awk是逐行处理的,逐行处理的意思就是说,当awk处理一个文本时,会一行一行进行处理,处理完当前行,再处理下一行,awk默认以“换行符”为标记,识别每一行,也就说,每次遇到“回车换行”,就认为是当前行的结束,新的一行的开始,awk会按照用户指定的分隔符去分割当前行,如果没有指定分隔符,默认使用空格作为分隔符。

我们也可以一次输出多个指定的列:
下图,呈现了两种输出方式。特别是:printf中可以格式化输出的字符串,确保输出是等宽字符显示。

- 上面我们讲了最常用的语法中的Action:print/printf。现在,我们来认识一下语法中的Pattern,也就是我们说的模式。其实在AWK的工作流程中,我们已经介绍过了两种特殊模式:BEGIN和END。
- 接下来,我们重点AWK中的普通模式:Pattern,其实就是选择的条件,由于awk是逐行处理文件的,也就是说,AWK会先处理完当前行,再处理下一行,当不指定任何条件,AWK会一行一行的处理文本中的每一行。如果指定了条件,只有满足“条件”的行才会被处理,不满足“条件”的行就不会被处理。
- 来看一个很简单的示例:使用一个简单的“条件”:如果被处理的行正好有4列字段,那么被处理的行满足“条件”,执行相应的动作。
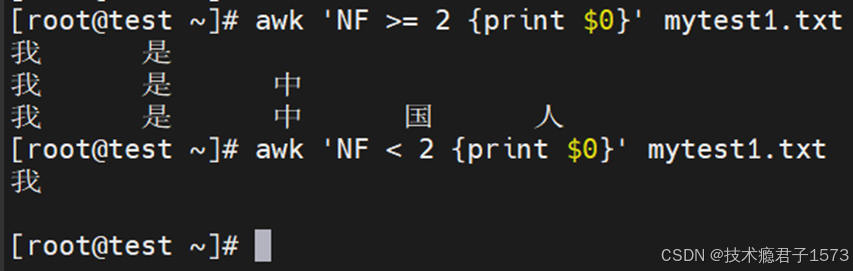
- 上面的示例中,我们在模式中,用到了关系的表达式 – 关系操作符。当关系运算符得出的结果为“真”时,则满足条件,表示与指定的模式匹配。
- 下面来了解一下AWK中的关系运算符:
| 关系运算符 | 含义 |
| <、<= | 小于、小于等于 |
| ==、!= | 等于、不等于 |
| >、>= | 大于,大于等于 |
| ~、!~ | 与对应的正则匹配则为真、与对应的正则不匹配则为真。 |
- 上面使用了关系表达式的示例中,其实已经使用了“模式”,这种模式就是“关系表达式模式”,模式被匹配,对应的行就打印输出。
- 学习到这里,估计有人会问刚开始只有print动作指令,这种称为什么模式呢?-- 空模式: 就是没有使用任何模式,每执行一行都执行了指定的动作。
- 有人可能会问,既然AWK支持正则表达式,有没有所谓的正则模式呢?答案是有的。
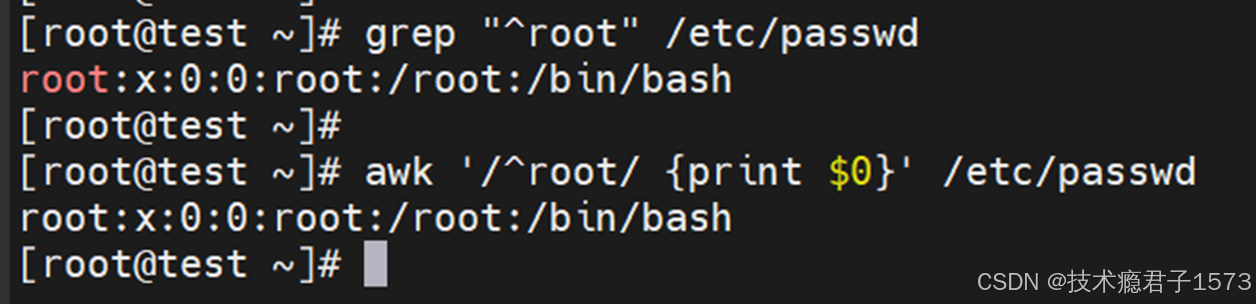
- 在awk命令中,正则表达式被放入两个斜线中:/正则表达式/。来看这个示例:从/etc/passwd文件中找出以root开头的行。
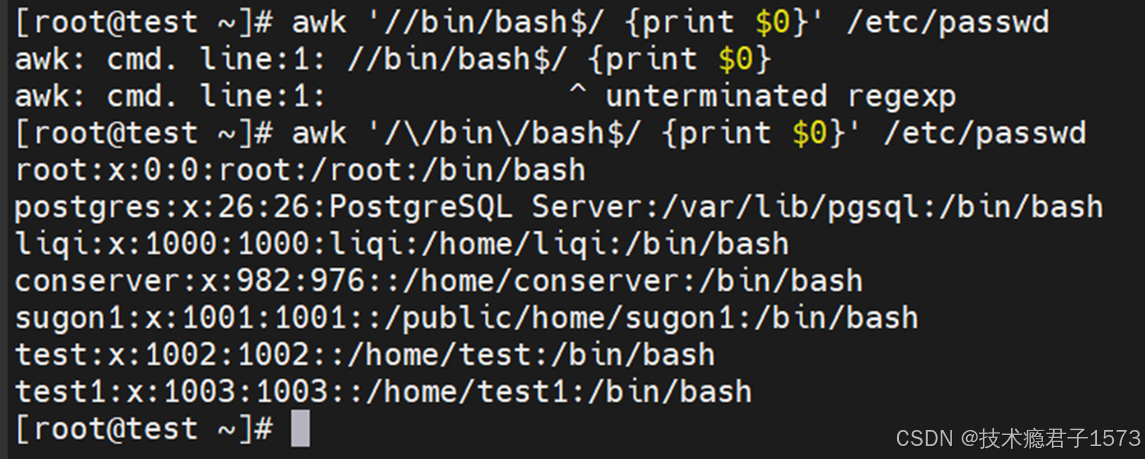
行范围模式 – 它表示,从被正则表达式1匹配到的行开始,到被正则表达式2匹配到的行结束,之间的所有行都会执行对应的动作。
备注:行范围模式,它对应的是一个范围以内的所有行,需要注意的是,在行范围模式中,不管是正则表达式1,还是正则表达式2,都是以第一次匹配到的行为准。
基本语法:awk '/正则表达式1/,/正则表达式2/{Action} '<file>
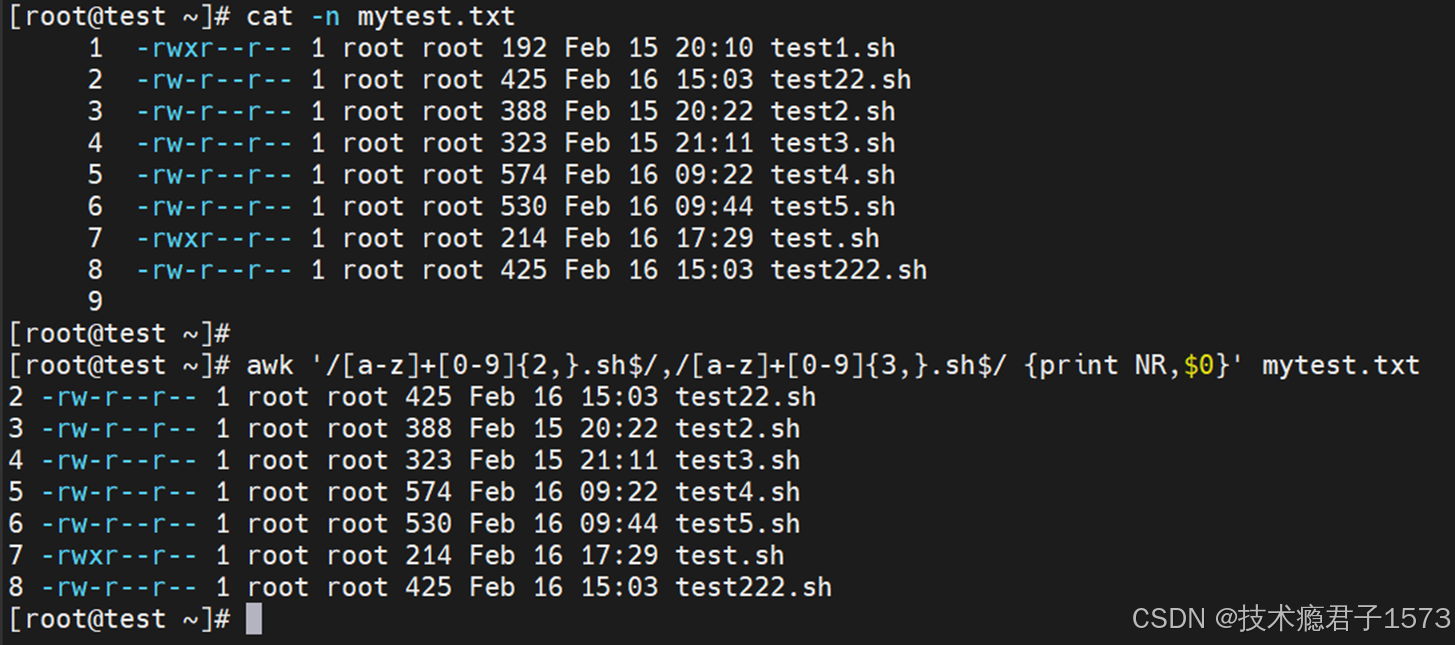
来看这个示例:
接下来,让我们学习一下AWK基本语法中的[Options]可选参数。最常用的是:
- -F, 用于指定输入分隔符;
- -v varname=value 变量名区分字符大小写, 用于设置变量的值。
下面通过一些示例来学习一下这两个常用的参数用法:

注意:第二个例子是一个三元表达式的基本用法。在BEGIN块中,变量定义与动作之间需要用分号“;”隔开。
Awk –F: 指定分隔符。来看一些示例:
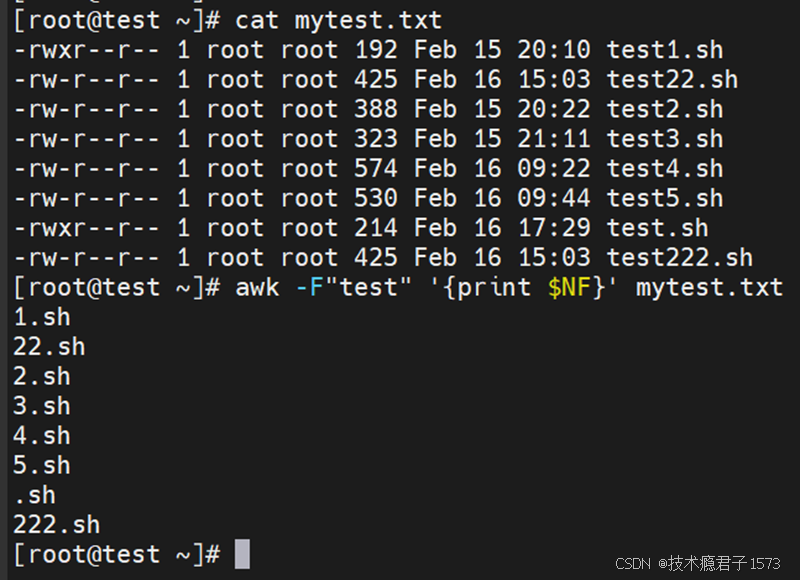

备注:FS: Field Separator, 字段分割符,默认是任何空格。OFS: Output Field Separator, 输出记录分隔符。
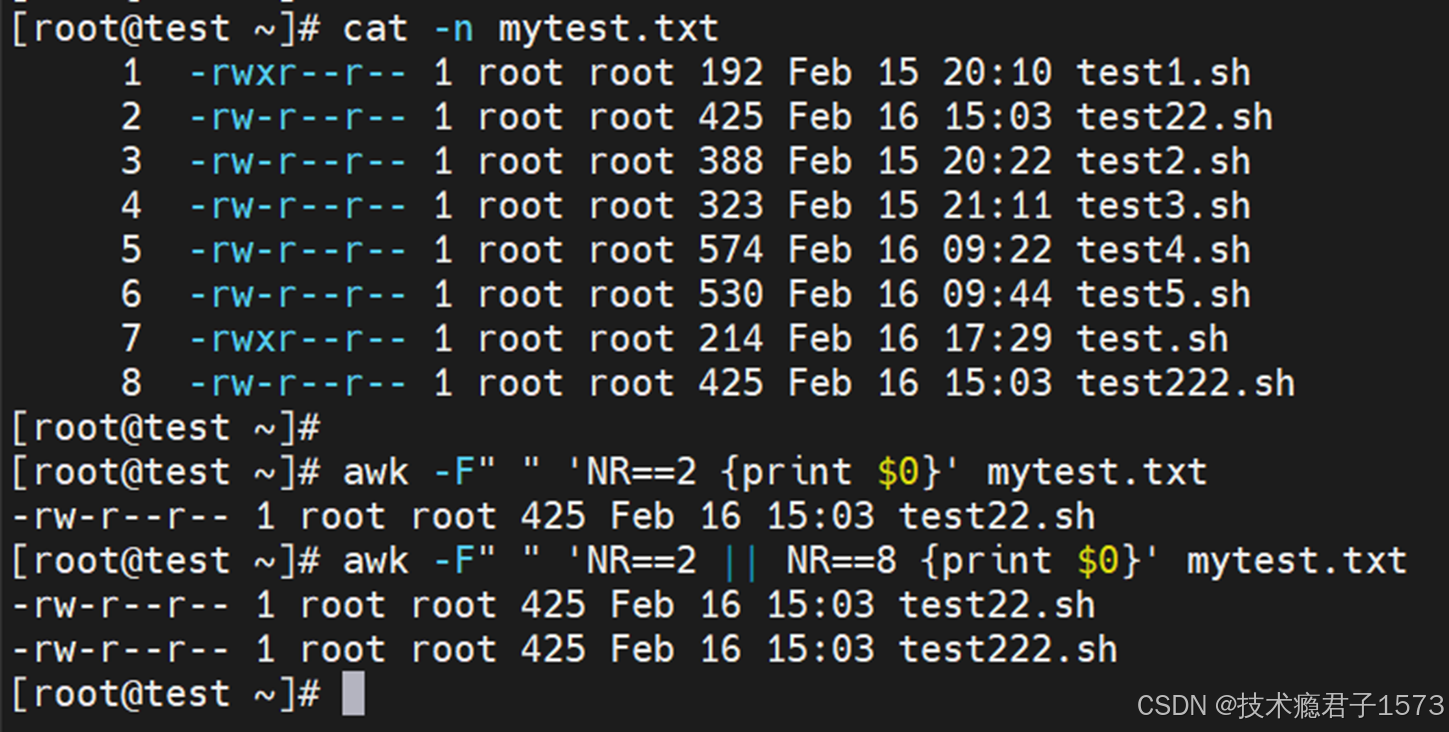
内置变量NR与-F结合的示例:NR:Number of Record,已读取的记录数。
四、常用示例
awk if语句:必须用在{}中,且比较内容用()括起来。
列出、统计登录shell为bash的用户:

统计uid小于等于500和大于500的用户个数:

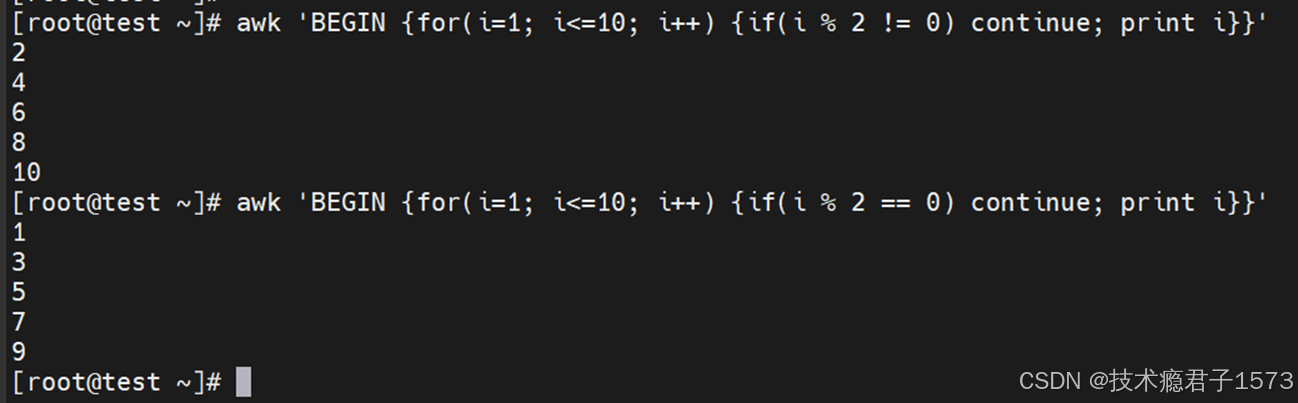
awk for语句: continue的作用和其它语言类似:跳出“当前”循环。
打印1-10的奇数、偶数序列:
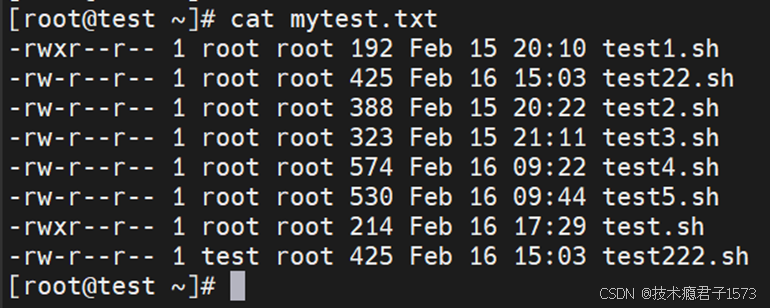
统计家目录下不同用户的普通文件的大小。


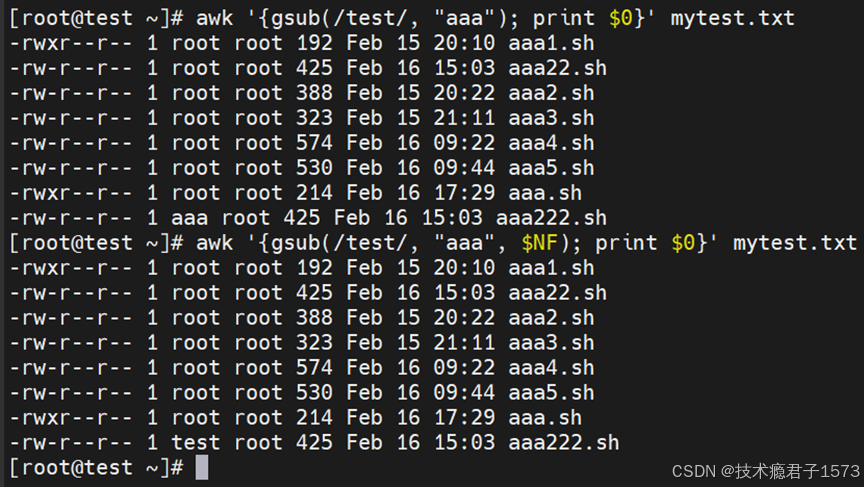
备注:gsub匹配所有的符合模式的字符串,相当于sed 's//g'。
ØAWK官网文档:https://www.gnu.org/software/gawk/manual/gawk.html
