JOIN是关系数据库中常用运算,用于把多个表进行关联,关联条件一般是判断某个关联字段的值是否相等。随着关联表的增多或者关联条件越来越复杂,无论理解查询含义、实现查询语句,还是在查询的性能方面,可以说JOIN都是最具挑战的SQL运算,没有之一。
特别是JOIN的性能,一直是个老大难问题。下面我们将基于数据计算中间件(DCM)——集算器,来提供一些提升运算性能的方法。
当然,我们不是介绍如何在写SQL语句时怎么写JOIN,也就是我们假设已经对查询需求有了正确的理解并且能正确地实现SQL。这种情况下,要提升性能,就必须从最基本的提升数据IO配合算法及并行等手段做起。正因如此,如果数据仍然存储在数据库中,那也没什么好办法提速,因为数据库的IO效率很低,又几乎无法并行,即使把运算写得再精巧也无济于事。所以,要提高性能,一定要把数据搬出数据库,我们下面的讨论都是基于这个思路,而集算器正是实现这个思路的利器,甚至神器!
把数据表搬出数据库存储到集算器的集文件中很简单,只要用两行代码:
A | |
1 | =db.cursor("select * from 订单表") |
2 | =file("Order.btx").export@b(A1) |
这两行代码把数据库里订单表的数据导出到集文件Order.btx。
因为数据库IO性能不佳,而且数据量也可能很大,所以这个“搬家”动作可能时间也不短,但还好是一次性的。后面我们的计算都将从集文件中取数。
1判断JOIN的类型
在将数据搬出数据库后,我们需要首先判断JOIN的类型,然后才能采取有针对性的优化措施。
JOIN运算大家都很熟悉,按照SQL的语法定义划分,包括INNER JOIN(内连接)、LEFT JOIN(左连接)、RIGHT JOIN(右连接)、FULL JOIN(全连接)几个类型,这是根据在运算中对空值的处理规则进行划分的。而我们的分析和优化,则会从更贴近需求的语义角度出发,根据各个表的主键参与关联的情况进行划分,总体来说有这么三种:外键表、同维表、主子表。
外键表
当表A的某些字段与表B的主键关联,B称为A的外键表,A表中与B表主键关联的字段称为A指向B的外键。此时A表也称为事实表,B表也称为维表。
表A:Order订单表 | |
ID | 订单编号 |
CustomerID | 客户编号 |
SellerID | 销售编号 |
OrderDate | 订购日期 |
Amount | 订单金额 |
表B:Customer客户表 | |
ID | 客户编号 |
Name | 客户名称 |
Area | 所在区域 |
表C:seller销售人员表 | |
ID | 员工编号 |
Name | 姓名 |
Age | 年龄 |
…… | |
这是一个典型的例子,订单表的客户编号与客户表的主键客户编号进行关联,此时A指向B是多对一的关系,即A表有可能存在多条记录指向B表的同一条记录。
这种情况,我们可以把外键字段(例子中的“CustomerID”)的值理解成指向外键表中对应记录的“指针”,而外键表中对应的记录就可以理解成一个对象,而外键表的字段就可以理解为对象的属性, “指针”的作用只是用于找到外键表中对应那条记录。例子中对表A和表B做关联,一定是想获得某些订单的客户的姓名或所在区域等详细信息,这样,如果能写成customerID.name和customerID.area就会更容易理解,这种语法在集算器中也得到了完美的支持。
同时,表A还可以有多个外键表,例如表A的销售编号(SellerID)可以指向一个销售人员信息表C,从而获得该订单销售人员的属性信息。
同维表
表A的主键与表B的主键关联,A和B相互称为同维表。同维表是一对一的关系,JOIN、LEFT JOIN和FULL JOIN的情况都会有,例如:员工表和经理表。
表A:employee员工表 | |
ID | 员工编号 |
Name | 姓名 |
Salary | 工资 |
表B:manager客户表 | |
ID | 编号 |
Allowance | 补贴 |
…… | |
这两个表的主键都是员工编号ID,也就是经理也是员工之一,不过因为经理比普通员工多了一些属性,所以需要另用一个经理表来保存。对于这种一对一的情况,逻辑上可以简单地看成一个表来对待。同维表JOIN时两个表都是按主键关联,相应记录是唯一对应的。
主子表
表A的主键与表B的部分主键关联,A称为主表,B称为子表。主子表是一对多的关系,只有JOIN和LEFT JOIN,不会有FULL JOIN,如:订单和订单明细。
表A:Order订单表 | |
ID | 订单编号 |
CustomerID | 客户编号 |
OrderDate | 订购日期 |
…… | |
表B:OrderDetail订单明细表 | |
ID | 订单编号 |
NO | 订单序号 |
Product | 订购产品 |
Price | 价格 |
…… | |
表A的主键是ID,表B的主键是ID和NO,表A里的一条记录会对应表B里的多条记录。此时,可以把订单明细表里的相关记录看成是订单表的一条记录的属性,该属性的取值是一个集合,而且常常需要使用聚合运算把集合值计算成单值。例如查询每个订单的总金额,可以描述为:
SELECT ID, SUM(OrderDetail.Price) FROM Order
显然,主子表关系是不对等的,而且从两个方向的引用都有意义。从主表引用子表的情况就是通过聚合运算得到一个单值,而从子表引用主表则和外键表类似。
那么,这样划分三种JOIN运算,外键表、同维表、主子表,有什么用处呢?当然是为了优化性能!对于需要优化的JOIN运算,在准确判断是哪种类型基础上,后面的优化才会更加有效。另外,有必要说明一下,这里提到的表A和表B不要求必须是一个实体表,也可能是一个子查询产生的“逻辑表”。
下面我们就开始针对这三种类型以及实际的业务情况进行分析和提速。
2全内存时的外键表
如果所有参与运算的数据都能装入内存,那么就可以使用“外键指针化”技术来实现外键式JOIN运算的优化。
2.1单个外键
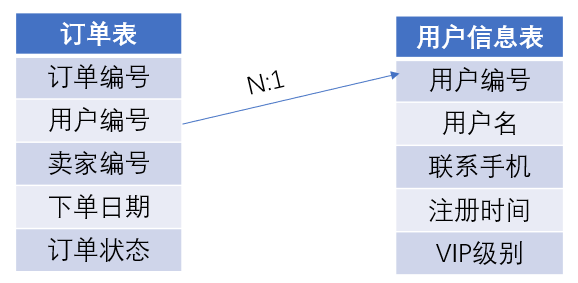
以上面的订单表和客户表为例,要查询每一笔订单的客户名称和所在地区:
我们需要查询所有订单的订单编号、用户名、用户级别和下单时间, SQL是这么写的:
SELECT 订单编号,用户名,VIP级别,下单时间 FROM 订单表,用户信息表 WHERE 订单表.用户编号 = 用户表.用户编号
用集算器实现则是这样:
A | |
1 | =file("用户信息表").import@b() |
2 | =A1.keys(用户编号) |
3 | =A1.index() |
4 | =file("订单表").import@b() |
5 | =A4.switch(用户编号,A3:用户编号) |
6 | =A5.new(订单编号, 用户编号.用户名:用户名, 用户编号.VIP级别:用户级别, 下单时间) |
A1,从集文件中查询用户数据;
A2,设置用户信息表的键为用户编号;
A3,以用户编码字段建立索引;
A4,从集文件中查询订单数据;
A5,关联,在A4订单表的用户编码字段上建立指向用户信息表记录的指针;
A6,外键指针化之后,将外键表字段作为用户名、用户级别属性使用。
实际有效运算的也就是A5和A6这两格,别的都是数据准备。
再来看一个例子,这次需要计算各个VIP级别用户的订单的总数,SQL是这么写的:
SELECT VIP级别,count(订单编号) 订单数 FROM 订单表,用户信息表 WHERE 订单表.用户编号 = 用户表.用户编号 GROUP BY VIP级别
使用集算器则是这样的:
A | |
1 | =file("用户信息表").import@b() |
2 | =A1.keys(用户编号) |
3 | =A1.index() |
4 | =file("订单表").import@b() |
5 | =A4.switch(用户编号,A3:用户编号) |
6 | =A5.new(订单编号, 用户编号.用户名:用户名, 用户编号.VIP级别:用户级别, 下单时间) |
7 | =A5.groups(用户编号.VIP级别; count(订单编号):订单数) |
这个计算跟上一个例子的处理步骤大部分都一样,只是在上一个例子的计算后接着再执行一下A7,对关联的结果进行汇总,能这么做是因为外键的指针关联在上一次计算里已经完成,这里可以对A5的结果进行复用。实际使用中这两个计算放在一个DFX文件里执行,所以整个过程只需要进行一次关联。
这也是集算器的另一大特点,可以对中间计算结果进行复用,从而提高整体查询性能。复用的次数越多,性能的优化就越明显。这一点在SQL中就做不到,两个查询要执行两次SQL语句,每次执行都要做一次关联,整体性能自然就差了。
此外,还可能存在多字段外键的情况,事实表的多个字段关联到一个维表,这种情况略有些复杂,在以后的篇章中再做详细介绍。
2.2一层多个外键
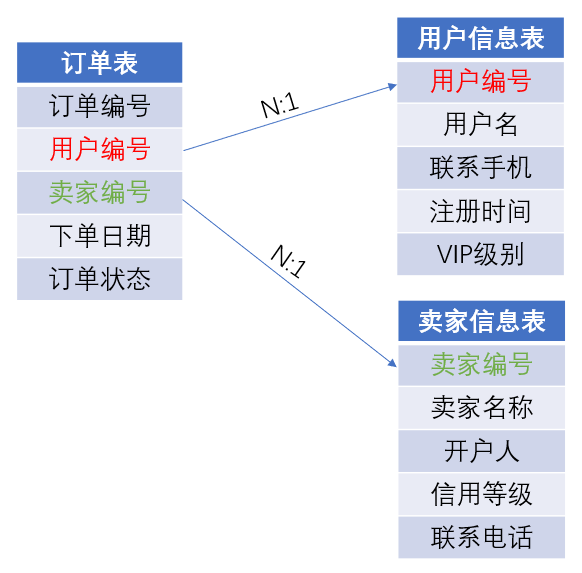
下面再看一个多外键的例子,假设数据库中有订单表、用户信息表、卖家信息表三个表:
我们需要按照用户级别和卖家信用等级来汇总订单数量,SQL是这么写的:
SELECT VIP级别 用户级别, 信用等级 卖家等级,count(订单编号) 订单数
FROM 订单表,用户信息表,卖家信息表
WHERE 订单表.用户编号 = 用户表.用户编号 AND 订单表.卖家编号 = 用户表.卖家编号
GROUP BY VIP级别, 信用等级
使用集算器则是这样:
A | |
1 | =file("订单表").import@b() |
2 | =file("用户信息表").import@b().keys(用户编号).index() |
3 | =file("卖家信息表").import@b().keys(卖家编号).index() |
4 | =A1.switch(用户编号,A2:用户编号;卖家编号,A3:卖家编号) |
5 | =A4.groups(用户编号.VIP级别:用户级别,卖家编号.信用等级:卖家等级;sum(订单编号):订单数) |
A1,中查询订单数据;
A2,中查询用户数据;
A3,中查询卖家数据;
A4,一次性关联用户信息表、卖家信息表这两个维表;
A5,对关联的结果进行汇总。
2.3多层外键
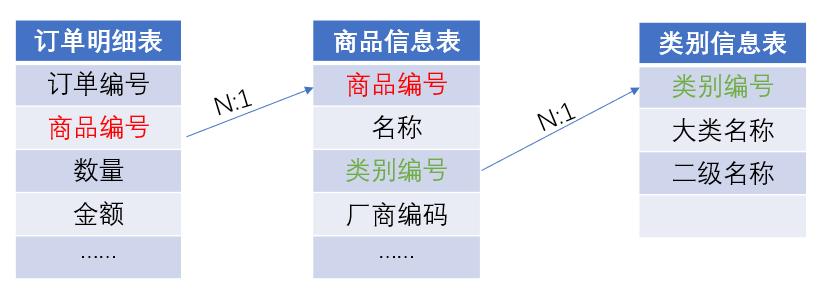
外键表还可能会有多层的情况,下面这个例子中,假设数据库中有订单明细表、商品信息表、类别信息表三个表:
我们要查询按照商品的大类名称汇总的售出商品数量,SQL是这么写的:
SELECT 大类名称, SUM (商品编号) 商品数
FROM 订单明细表,商品信息表,类别信息表
WHERE 订单明细表.商品编号 = 商品信息表.商品编号 AND 商品信息表.类别编号 = 类别信息表.类别编号
GROUP BY 大类名称
使用集算器则是这样:
A | |
1 | =file("订单明细表").import@b() |
2 | =file("商品信息表").import@b().keys(商品编号).index() |
3 | =file("类别信息表").import@b().keys(类别编号).index() |
4 | =A2.switch@i(类别编号,A3:类别编号) |
5 | =A1.switch@i(商品编号,A4:商品编号) |
6 | =A5.groups(商品编号.类别编号.大类名称:大类名称;sum(数量):商品数) |
A1,查询订单明细数据;
A2,查询商品信息数据;
A3,查询类别信息数据;
A4,通过switch函数在A2建立指向类别信息记录的指针,实现关联;
A5,通过switch函数在A1建立指向商品信息记录的指针,实现关联,这样就得到了一个三层关联;
A6,对关联的结果进行汇总。
用外键指针化的办法解决JOIN,对事实表遍历一次就可以解析所有外键。而数据库的HASH JOIN算法每执行一次(意味着遍历一次数据)只能解析掉一个JOIN。
同时,如果全部使用内存,这个指针一旦建立后就可以复用,如果我们还要针对这个关联情况再次计算 ,就不需要再去建立关联了。而数据库SQL则不行,还要再做HASH JOIN,即便是基于SQL体系的内存数据库,在这方面也做不快。
2.4并行计算
外键指针化之后,还可以通过并行方式进一步优化性能。对已经装入内存的事实表,我们可以对它进行分段访问,从而以并行计算的方式明显地提升计算的性能。
还是用上面多外键的情形为例,仍然是按照用户级别和卖家信用等级汇总订单数量,我们来看看如何用集算器实现并行访问事实表:
A | |
1 | =file("订单表").import@b() |
2 | =A1.cursor@m(4) |
3 | =file("用户信息表").import@b().keys(用户编号).index() |
4 | =file("卖家信息表").import@b().keys(卖家编号).index() |
5 | =A2.switch(用户编号,A3:用户编号;卖家编号,A4:卖家编号) |
6 | =A5.groups(用户编号.VIP级别:用户级别,卖家编号.信用等级:卖家等级;sum(订单编号):订单数) |
这段代码和前面的基本一样,只是对订单表这个事实表的访问方式有所不同。A2使用@m选项把订单表数据分为了4段,得到一个多路游标,后面的计算都是基于这个多路游标进行的。groups函数内部会自动判断,如果A2是多路游标那么就会自动进行计算。这里分为4段游标,是假定CPU的个数是4个,实际使用中可以根据CPU的数量来决定分几段。
并行在单任务时有很明显的效果,主要是因为充分利用了CPU资源,如果并发较多时没有太多空闲的CPU可用,那么意义就不大了。
3半内存时的外键表
外键指针化的前提是事实表和维表都可以装入内存,但实际业务中涉及的数据量可能很大,那就不能采用这种方法了。
3.1维表内存化
如果只是事实表很大,而维表仍然可以全部装入内存,那么仍然可以采用上面的外键指针化方法处理,只要修改一下对事实表的访问,使用游标的方式取从集文件里分批取数进行处理即可。不过因为这种指针是在游标取数时才临时建立的,所以就不象全内存时那样可以复用已经建立过的指针了。
我们仍然按照用户级别和卖家信用等级汇总订单数量,而订单表太大无法导入内存,那么用集算器实现如下:
A | |
1 | =file("订单表") |
2 | =A1.cursor@b() |
3 | =file("用户信息表").import@b().keys(用户编号).index() |
4 | =file("卖家信息表").import@b().keys(卖家编号).index() |
5 | =A2.switch(用户编号,A3:用户编号;卖家编号,A4:卖家编号) |
6 | =A5.groups(用户编号.VIP级别:用户级别,卖家编号.信用等级:卖家等级;sum(订单编号):订单数) |
这个实现跟外键指针化的实现原理相同,只不过订单表的数据没有一次性导入内存,而是通过游标的方式访问。由于事实表会不断增长,所以事实表很大而维表较小会是实际业务中常见的情况。
这是个多外键的例子。多层外键的情况和单层外键类似,只是在内存化某外键表时,该表的外键表也必须内存化,从而可以事先建立内存的外键指针。临时基于游标建立的外键关联只会针对最下层的外键表。
游标也可以实现并行计算,上面的代码只要改成这样:
A | |
1 | =file("订单表").cursor@bm(;4) |
2 | =file("用户信息表").import@b().keys(用户编号).index() |
3 | =file("卖家信息表").import@b().keys(卖家编号).index() |
4 | =A1.switch(用户编号,A2:用户编号;卖家编号,A3:卖家编号) |
5 | =A4.groups(用户编号.VIP级别:用户级别,卖家编号.信用等级:卖家等级;sum(订单编号):订单数) |
把来自集文件的订单表数据分成4段游标取出,在执行groups函数就会以并行的方式进行计算了。这里之所以可以进行分段取数,是因为数据已经导出到集文件中了,如果数据仍然在数据库中则无法做到这一点的,这也是我们为什么要把数据导出到集文件的原因之一。
如果维表太大也无法装入内存怎么办?这种情况就要使用集群或者优化过的外存HASH JOIN技术了,后面的篇章中我们会详细讲解。
3.2外键序号化
外键序号化的思路是,如果维表的主键是从1开始的自然数,那么就可以用序号直接定位维表记录,而不再需要计算和比对HASH值了。这可以看做是在外存实现了外键指针化,从而进一步提升性能。按照外键序号化思路,前面订单表和用户表的关联处理可以改成这样:
A | |
1 | =file("用户信息表").import@b() |
2 | =file("订单表").cursor@b() |
3 | =A2.switch(用户编号,A1:#) |
4 | =A3.new(订单编号, 用户编号.用户名:用户名, 用户编号.VIP级别:用户级别, 下单时间) |
A1,将客户表全部导入内存;
A2,将订单表使用游标导入;
A3,在A2订单表中把用户编号的值作为序号,用这个序号去用户信息表找相应的记录,建立关联;
A4,通过外键属性化的方式,将外键表字段作为用户名、用户级别属性使用。
3.3序号化准备
但维表的主键不一定是序号值,那么就无法直接使用外键序号化进行性能优化。这时,可以把维表的主键转换成序号后再使用外键序号化。处理的步骤是这样的:
1)新建一个键值-序号对应表,保存维表的键值和自然序号的对应关系;
2)把维表的键值替换为自然序号,得到一个新的维表文件;
3)把事实表里的外键值修改为序号,修改的依据是键值-序号对应表,修改后得到一个新的事实表;
这样就得到了新的维表和事实表文件,旧的表文件也可以删除了。
如果维表增加了新数据,那么就按照如下步骤处理:
1)先追加键值-序号对应表;
2)再把新数据追加到新的维表,追加时依据键值-序号对应表;
3)最后追加事实表,追加时依据键值-序号对应表;
当完成了外键的序号化以后就可以使用外键序号化的方式来提高性能了。序号化这种方法适用于维表基本不变的情况,事实表数据则可以不断追加。
下面仍以订单表、用户信息表为例来说明一个序号化的具体实现:
1)新建一个用户信息表的键值-序号对应表,保存到集文件中,同时生成一个用户信息表文件;
A | |
1 | =db.query("select *,0 AS NEW_ID from 用户信息表 order by 用户编号") |
2 | =A1.run(#:NEW_ID) |
3 | =file("OldKey_NewID").export@b(A2, 用户编号, NEW_ID) |
4 | =file("用户信息表").export@b(A2, NEW_ID:用户编号, 用户名,联系手机,VIP级别) |
A1从数据库的用户信息表取出所有字段,并增加一个用来保存序号的字段NEW_ID;
A2将NEW_ID赋值为从1开始的自然数;
A3是保存旧的用户编号和序号到集文件;
A4用NEW_ID字段值作为用户编号字段的值,其它字段不改变,把数据保存到用户信息表文件。
2)根据订单表,得到新的订单表;
A | |
1 | =file("OldKey_NewID ").import@b() |
2 | =db.cursor("select * from 订单表") |
3 | =A2.switch(用户编号,A1:用户编号) |
4 | =A3.run( 用户编号.NEW_ID:用户编号) |
5 | =file("新订单表").export@ba(A4) |
A1把对应关系表导入内存;
A2用游标从订单表取出数据;
A3把订单表里的用户编号字段根据对应表进行替换;
A4把替换后的用户编号字段的值做一个转换(A3得到的用户编号字段值是记录类型,所以在A4转变为字段);
A5把游标数据导出到新订单表文件里(实际中可能要分多次导出);
通过这两步,就可以完成对数据库里已有数据的序号化,并导出到用户信息表、订单表这两个集文件,同时还得到了一个键值-序号对应表文件,命名为OldKey_NewID。
前面提到过,序号化适用于维表数据基本不变的情况,如果维表变化了,那就需要重造这些数据后再使用序号化。不过,如果能够明确知道事实表和维表上新追加的数据(例如通过时间等条件),那么也可以用下面的办法来实现。
1)先追加用户信息表和键值-序号对应文件;
A | |
1 | =db.query("select *,0 AS NEW_ID from 用户信息表 where 注册时间>’2018-01-01’ order by 用户编号") |
2 | =file("用户信息表").cursor@b().skip() |
3 | =A1.run(A2+#:NEW_ID) |
4 | =file("OldKey_NewID").export@ab(A3, 用户编号, NEW_ID) |
5 | =file("用户信息表").export@ab(A3, NEW_ID:用户编号, 用户名,联系手机,VIP级别) |
A1得到用户信息表要追加的新数据,这里是从数据库里取2018年以来新注册的用户数据;
A2得到用户信息表已有记录条数;
A3填写新数据里的NEW_ID值,从A2开始继续计数;
A4把用户编号和序号追加到键值-序号对应的文件;
A5追加新数据到用户信息表文件。
3)追加订单表;
A | |
1 | =db.query("select * from订单表 where 下单时间>=’2018-01-01’ order by 订单编号") |
2 | =file("OldKey_NewID").cursor@b() |
3 | =A1.switch(用户编号,A2:用户编号) |
4 | =A3.run( 用户编号.NEW_ID:用户编号) |
5 | =file("订单表").export@ba(A4) |
A1得到订单表要追加的新数据的游标,这里是从数据库取出2018年以来的订单作为新数据;
A2是得到键值序号的对应表;
A3把新数据游标里的用户编号字段根据对应表进行替换;
A4把替换后的用户编号字段的值做一个转换;
A5使用循环方式从游标取数,追加到订单表文件,这个过程和用户信息表的追加是类似的。
上面是一个单外键做序号化的例子,对多外键的序号化处理也是一样的,只是有多个维表要处理。如果是多层外键,那么上层的就没有必要做序号化了,只要对最下层的维表做个序号化就可以了,因为上层已经全内存指针化了。
外键序号化处理本质是优化了查找外键的方法,把外键值作为序号直接去维表找记录,所以经过外键序号化的数据仍然可以使用并行计算,实现方式跟前面讲的一样,在此不再详述。
4同维表和主子表
在这里我们把同维表和主子表两种情况一起来分析,因为这两种情况的提速手段是一样的,那就是有序归并。
4.1有序归并
我们先看简单的情况,如果两个表对关联键都已经是有序的,那么就可以直接使用归并算法来处理关联。来看一个例子,
订单表 |
订单编号 |
用户编号 |
卖家编号 |
下单日期 |
订单明细表 |
订单编号 |
商品编号 |
数量 |
金额 |
卖家信息表 |
卖家编号 |
名称 |
…… |
用户信息表 |
用户编号 |
用户名 |
…… |
此时订单表是主表,订单明细表是子表,这是一个典型的一对多的情况,现在要查询订单及其明细,那么就要把两个表按照订单编号字段进行关联。先来看一下数据量不大时的例子,计算目标是汇总每个卖家的销售额:
A | |
1 | =file("订单表").import@b() |
2 | =file("订单明细表").import@b() |
3 | =join@m(A1:订单,订单编号;A2:明细,订单编号) |
4 | =A3.groups(订单.卖家编号 :卖家编号; sum(明细.金额):总销售额 ) |
A1将订单表全部导入内存。
A2将订单明细表全部导入内存。
A3通过有序归并算法(@m选项)对两个表按照订单编号关联。
A4对join的结果进行分组汇总。
集算器的join操作的结果与SQL不同,SQL里join的结果是两个表的字段,而集算器join的结果是把两个表的记录作为结果字段,所以做groups时的语法需要写成“字段.子字段”这样(类似“对象.属性”),例如访问卖家编号就要写成“订单.卖家编号”。
如果数据很大无法导入内存,则可以使用游标方式进行有序归并。
A | |
1 | =file("订单表").cursor@b() |
2 | =file("订单明细表"). cursor@b() |
3 | =joinx(A1:订单,订单编号;A2:明细,订单编号) |
4 | =A3.groups(订单.卖家编号:卖家编号; sum(明细.金额):总销售额 ) |
注意,这里进行有序归并的前提是订单表、订单明细表已经是对订单编号字段有序的。
A1将订单表通过游标导入;
A2将订单明细表通过游标导入;
A3通过有序归并算法对两个游标按照订单编号关联;
A4对joinx的结果进行分组汇总。同样地,joinx的结果的字段也是记录,所以在groups时对卖家编号的访问语法就变成了订单.卖家编号,对金额的访问语法就成了明细.金额。
有序归并还可以和游标外键一起使用,例如我们要计算消费总金额大于1000的用户名:
A | |
1 | =file("订单表").cursor@b() |
2 | =file("订单明细表"). cursor@b() |
3 | =file("用户信息表"). import@b() |
4 | =A1.switch@i(用户编号, A3:用户编号) |
5 | =joinx(A4:订单,订单编号;A2:明细,订单编号) |
6 | =A5.groups(订单.用户编号.用户名; sum(明细.金额):总额) .select(总额>1000) |
A1将订单表通过游标导入;
A2将订单明细表通过游标导入;
A3将用户信息表导入内存;
A4使用用户编号字段和用户信息表做外键关联;
A5通过有序归并算法对两个游标按照订单编号关联;
A6 通过用户名字段(订单.用户编号.用户名)进行分组汇总,并选出总额大于1000的。
4.2有序归并的数据准备
不过,如果数据事先没有按主键有序呢?那么就需要事先进行排序。同维表和主子表可以在数据准备阶段就做好排序,这是因为对于同维表或主子表的关联,用到的字段都是那一个(一组),即主键(的部分);而对于外键表,事实表有可能要跟多个维表做关联,每次关联的字段都可能是不同的,而一个表是不可能同时对所有的外键都有序的。
因此,对于数据库中并不保证次序的原始数据,我们可以在做数据外置时同时进行排序。本节将描述如何排序以及排序后如何有序地更新数据。
先看原始数据的导出。如果要排序的同维表或主子表的数据源都是数据库,那么就用数据库排序。如果数据源不是数据库,那么可以使用集算器的sortx函数进行排序。排序后用export函数保存到一个新的文件里。如果要采用分段并行,还要注意在导出的时候加上选项@z。处理流程是这样的:
A | |
1 | =db.query("select * from 订单表 order by 订单编号").cursor() |
2 | =file("订单表").export@z(A1;订单编号) |
3 | =db.query("select * from 订单明细表order by 订单编号").cursor() |
4 | =file("订单明细").export@z(A1;订单编号) |
A1,从数据库将订单表通过游标导入,并且排序;
A2,将排序后的游标数据写入集文件;
A3、A4同样将数据库的订单明细表排序后写入集文件。
再来看看如果这两个表又追加了新数据时该怎么处理,我们仅以订单表的追加为例:
A | |
1 | =file("订单表"). cursor @b() |
2 | =db.query("select * from 订单表 where 下单日期>=’2018-01-01’ order by 订单编号").cursor() |
3 | =[A1,A2].mergex(订单编号) |
4 | =file("新订单表").export@z(A1;订单编号) |
A1,将订单表通过游标导入;
A2,从数据库中将2018年以来产生的新数据取出;
A3,两个游标按照订单编号字段进行有序归并;
A4,将归并后的游标数据写入新的文件。
后续使用时用新的文件替换旧的订单表文件,这样就完成了新增数据和历史数据的有序归并,就可以按照有序的情况进行处理了。
新增数据和历史数据的混合,是个有序归并的过程,并不需要全部重新排序,只是把数据再读写一遍,时间成本并不高。
4.3并行计算
如果数据量确实特别大,频繁重写的成本太高,这时可以每隔一个相对合适的周期才重写所有数据,未到周期点时先把数据保存到一个较小文件,到了周期节点再把小文件和历史全文件做归并,具体的周期根据实际业务来设定。这样就会有两个文件:历史全文件和周期内小文件。可以使用多路游标来一起访问这两个文件。
例如,可以计划每隔一个月才重写所有数据,每天追加的数据合在一个当月的小文件中,在月中只用这个小文件和当日数据归并,到了月末才把当月文件和历史全文件全部归并,这样就能够减少全量归并的次数,减少总的处理时间。这种方式下两个文件就是历史文件和当月文件。
当然,还可以保留以前每个月的文件,作为历史数据不再改动,然后使用多路游标来访问这多套数据,这样性能可能会更好。这是以日期为例的情况,还可以根据其它的字段来进行分段方案的设计,比如按地区等。
下面用每个月保留一个文件的方法来举例说明,先实现对当日新产生的数据的处理,仍然以订单表为例:
A | |
1 | =file("订单表8月").import@b().cursor() |
2 | =db.query("select * from 订单表 where 下单日期>=’2018-08-XX’ order by 订单编号").cursor() |
3 | =[A1,A2].mergex(订单编号) |
4 | =file("新订单表8月").export@z(A1;订单编号) |
A1,将8月份的订单表月文件通过游标导入;
A2,从数据库中将2018年8月某一天以来产生的新数据取出;
A3,两个游标按照订单编号字段进行有序归并;
A4,将归并后的游标数据写入新的8月份的文件。
处理后得到每个月份的订单表集文件,同理也可以得到每个月份的订单明细表的集文件。每个月份的两个集文件(订单和明细)都是根据订单时间产生的,对应的主子表记录(订单及其对应订单明细)都在同一月份的文件中,这样就可以并行地针对每个月的数据做有序归并来实现主子表连接,进一步提速。仍以统计卖家销售总额为例,下面是具体实现:
A | |
1 | =12.(file("订单表"/~/"月").cursor@b()) |
2 | =12.(file("订单明细表"/~/"月").cursor@b()) |
3 | =12.(joinx(A1(#):订单,订单编号;A2(#):明细 ,订单编号)) |
4 | =A3.mcursor() |
5 | =A4.groups(订单.卖家编号 :卖家编号; sum(明细.金额):总销售额 ) |
A1,创建12个月份的订单表游标;
A2,创建12个月份的订单明细表游标;
A3,使用joinx对12个月份数据进行归并,得到游标;
A4,合并为多路游标;
A5,对多路游标进行分组汇总。
5综合案例
实际业务中,多表关联运算十分常见,外键表、同维表、主子表这几种关联类型可能会混合出现。下面我们来看一个综合案例。
5.1表结构和查询目标
某电商平台中和订单编号这个字段相关的有6个表,主要表结构如下:
订单表 | 订单明细表 | 订单优惠表 | 订单发货表 | 订单支付表 | 订单评价表 |
订单编号 | 订单编号 | 订单编号 | 订单编号 | 订单编号 | 订单编号 |
用户编号 | 商品编号 | 优惠类型 | 快递编码 | 支付渠道 | 评分 |
卖家编号 | 数量 | 优惠金额 | 支付时间 | 评论时间 | |
下单时间 | 金额 | 是否分期 | 评价 | ||
订单状态 | |||||
1:N | 1:N | 1:1 | 1:1 | 1:1 |
他们都靠订单编号字段进行关联,下面是订单表和另外5个表的对应关系:
用户信息表 | 用户地址信息表 |
用户编号 | 用户编号 |
用户名 | 省 |
手机 | 市 |
注册时间 | 区县 |
VIP级别 | 地址 |
1:1 |
用户表和用户地址表,这两个表是按照用户编号字段1对1的关系,这是同维表情况。
商品信息表 | 类别信息表 |
商品编号 | 类别编号 |
名称 | 大类名称 |
类别编号 | 二级名称 |
厂商编号 | |
1:1 |
商品信息表和类别信息表是通过类别编码进行关联,这是外键表的情况。
卖家信息表 |
卖家编号 |
开户行 |
联系 |
名称 |
信用级 |
最后还有一个卖家信息表。这里一共有11个表,假设要做这样一个查询:现在想知道江浙沪三省的VIP用户在6月份内从5星级卖家那里购买的所有电脑类商品的详情,并且要求只统计那些优惠总金额大于100元、用户评分4分以上的使用邮政配送的订单,而且这些订单不能是分期付款的。
使用SQL实现:
SELECT * FROM
订单表,
(SELECT用户编号 FROM 用户信息表 用户,用户地址信息表 地址 WHERE 用户.用户编号=地址.用户编号 AND 用户.VIP级别>0 AND (地址.省=江苏 OR 地址.省=浙江 OR 地址.省=上海) ) 用户,
(SELECT卖家编号 FROM 卖家信息表 WHERE 卖家信息表.等级=5) 卖家,
(SELECT订单编号 FROM 订单优惠表 GROUP BY 订单编号 HAVING SUM(优惠金额)>100 ) 优惠,
(SELECT订单编号 FROM 订单发货表 WHERE 快递编码=1) 快递,
(SELECT订单编号 FROM 订单支付表 WHERE 是否分期=false) 支付,
(SELECT订单编号 FROM 订单评价表 WHERE 评分>=4) 评价,
(SELECT订单编号 FROM 订单明细表,(SELECT * FROM 商品信息表 JOIN 类别信息表 ON 商品信息表.类别编号=类别信息表.类别编号 WHERE 大类名称='电脑') WHERE 订单明细表.商品编号=商品信息表.商品编号) 明细
WHERE
订单表.用户编号=用户.用户编号
AND 订单表.卖家编号=卖家.卖家编号
AND 订单表.订单编号=优惠.订单编号
AND 订单表.订单编号=快递.订单编号
AND 订单表.订单编号=支付.订单编号
AND 订单表.订单编号=评价.订单编号
AND 订单表.订单编号=明细.订单编号
5.2分析关联类型
这个SQL看上去似乎很清楚,理解起来也不难,但是性能却可能惨不忍睹。为了优化查询的性能,我们需要先对这个查询进行拆分,得到以下几个子步骤:
P1=对用户表、用户地址表关联,得到江浙沪三省VIP用户的用户编号,这是同维表情况;
P2=卖家信息表取游标,条件是信用级别=5,得到卖家编码;
P3=对订单优惠表按照订单编号分组,按条件(优惠总金额>=100元)过滤;
P4=订单发货表取游标,条件是快递编码=1(邮政快递编码);
P5=订单支付表取游标,条件是是否分期=false;
P6=订单评价表取游标,条件是评分>=4;
P7=商品信息表和类别信息表用类别编码做外键关联,用条件(大类=电脑)过滤;
P8=订单明细表通过商品编号字段对P7做外键关联;
P9=订单表依次对P1、P2做外键关联;
这时P3、P4、P5、P6、P8、P9这几个子查询都是同维或者主子表的关系,对它们通过订单编码字段做有序归并,就得到了需要查询的结果。
5.3数据预处理
得到关联类型后就可以有针对性地进行预处理。
首先,对无序的同维表、主子表进行排序处理,比如订单发货表、订单支付表、订单评价表通常是无序的,就要先对这些表进行排序;
第二步,还可以对外键表进行外键序号化,比如卖家信息表是订单表的外键表,就可以外键序号化。
5.4查询实现
用户信息表很大,但查询目标是VIP级别的用户,符合VIP这个条件的用户并不多,进行过滤后就可以装入内存,所以P1子查询可以全部装入内存;同样,用户地址信息表作为用户信息表的同维表也很大,但属于江浙沪三省的用户并不多,经过过滤后可以全部导入内存。把这两个同维表关联后,然后再完成订单表的关联计算,来看看这个子查询的写法:
A | |
1 | =file("用户信息表").cursor@b().select(VIP级别>=1) |
2 | =file("用户地址信息表").cursor@b().select(省=="江苏"||省=="浙江"||省=="上海") |
3 | =joinx(A1:用户信息,用户编号;A2,用户编号).new(用户信息.用户编号:用户编号).fetch() |
4 | =file("订单表").cursor@t().select(year(下单时间)==2018 && month(下单时间)==6) |
5 | =A4.switch@i(用户编号,A3:用户编号) |
6 | =A5.new(订单编号.订单编号:订单编号, 订单编号.卖家编号:卖家编号,用户编号.用户编号:用户编号).fetch() |
7 | return A6 |
A1,得到用户信息表的游标,并按条件过滤;
A2,得到用户地址信息表的游标,并按条件过滤;
A3,对A1、A2按照用户编号字段进行有序归并,返回的结果只取用户编号;
A4,得到订单表的游标,并按条件过滤;
A5,把A4和A3做外键关联;
A6,返回结果只取订单编号、卖家编号和用户编号字段;
A7,返回执行结果;
把这个脚本保存为P9.dfx。
接下来实现商品信息表和类别信息表的关联。类别信息表是商品信息表的外键,这个表很大无法装入内存。但是大类是电脑的类别信息就不多了,所以用大类等于电脑这个条件先过滤一下后就可以装入内存。下面是个子查询,把大类是电脑的所有商品的编码全部导入内存:
A | |
1 | =file("类别信息表").import@b().select(大类名称=="电脑") |
2 | =file("商品信息表").cursor@b().select(VIP级别>=1) |
3 | =A2.switch@i(商品编号,A1:商品编号) |
4 | =A3.new(商品编号).fetch() |
5 | return A4 |
A1,得到类别信息表的数据,并按条件过滤后取出;
A2,得到商品信息表游标,并按条件过滤;
A3,把A2的商品编号字段替换为A1的对应记录;
A4,结果只取商品编号字段;
A5,返回执行结果;
这个脚本保存为P7.dfx。
上面是两个子查询的处理,整个查询的实现是这样:
A | |
1 | =file("订单优惠表").cursor@b().group(订单编号;sum(优惠金额):优惠总额).select(优惠总额>=100) |
2 | =file("订单发货表").cursor@b().select(快递编码==1) |
3 | =file("订单支付表").cursor@b().select(是否分期==false) |
4 | =file("订单评价表").cursor@b().select(评分>=4) |
5 | =file("卖家信息表").import@b() |
6 | =call("P9.dfx") |
7 | =A6.switch@i(卖家编号,A5:#).select(卖家编号.信用级==5).sort(订单编号) |
8 | =call("P7.dfx") |
9 | =file("订单明细表").cursor@b() |
10 | =A9.switch@i(商品编号,A8:商品编号) |
11 | =joinx(A7:订单,订单编号; A10:明细,订单编号; A1,订单编号;A2,订单编号;A3,订单编号;A4,订单编号) |
A1,得到订单优惠表游标;
A2,得到订单发货表游标;
A3,得到订单支付表游标;
A4,得到订单评价表游标;
A5,得到卖家信息表数据(这里认为卖家信息表的数据可以导入内存);
A6,调用P9.dfx;
A7,把A6的结果的卖家编号替换成卖家信息表里的对应记录,按条件(信用级=5)进行过滤,并排序;
A8,调用P7.dfx,得到大类是电脑的所有商品的编码;
A9,得到订单明细表游标;
A10,把订单明细表的商品编号替换成A8结果里的对应记录;
A11,对A7、A10、A1、A2、A3、A4进行有序归并;
5.5查询技巧
技巧一:如果维表在内存中放不下,先别着急,可以看看总的查询条件里是否对这个维表进行了过滤。如果有,那么就可以把条件提取出来对维表进行过滤,很多时候过滤之后的结果就可以装入内存了。
技巧二:如果维表可以装入内存,并且已经外键序号化,那么就不要先过滤维表。因为能装入内存时用序号化做外键关联是最快的。例子中就是对卖家信息表先做关联,然后再进行条件过滤。
总结
使用集算器解决JOIN运算性能问题时,可以按照这个流程来处理:首先判断JOIN运算类型;如果是外键表,就装入内存并做外键序号化,如果无法装入内存也要尽量先用条件过滤,有条件的尽量做外键序号化;如果是同维表或主子表,要判断是否有序,有序则可以直接做有序归并,如果无序的则要先进行排序。同时,如果几个表是同步分段的还可以通过并行来提高性能。