一、简述
工作中需要利用kettle开源ETL工具将MySQL数据库中表数据同步到elasticsearch集群中。为此特记录一下操作方式,留作记录和学习。
二、环境
kettle工具:kettle 9.2
elasticsearch集群:7.11.1
集群配置信息:
集群名称:my-application
集群节点:192.168.172.200(node-1)、192.168.172.201(node-2)、192.168.172.202(node-3)
集群用户:elastic/admin#110
数据库:MySQL 8.0.29
数据表:t_kdxx
三、配置同步工程
1、更新kettle中elasticsearch的插件。
(1)下载相关插件:
链接:https://pan.baidu.com/s/1QuuetvBC1y2dT0KTgXlTyQ
提取码:2ny3
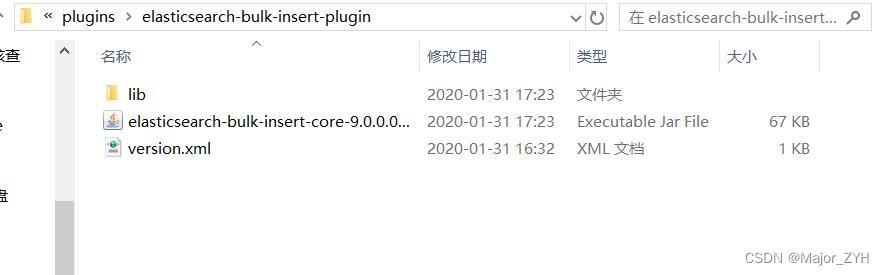
找到kettle安装目录下es插件的安装位置:D:\data-integration9.0\plugins\elasticsearch-bulk-insert-plugin。如下图所示,将插件下的文件全部删除或拷贝其他位置。
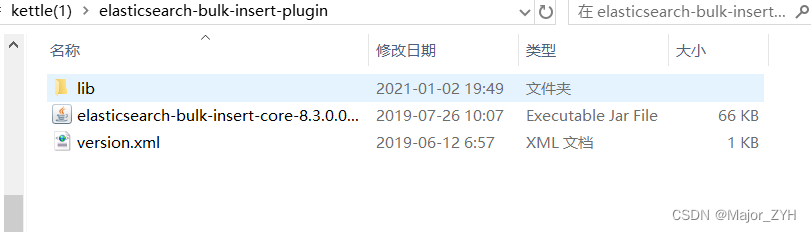
(2)将下载后的插件包elasticsearch-bulk-insert-plugin.zip解压,并将解压后文件复制到es插件安装目录下。
(3)替换完成后重启kettle即可完成插件更新。
2.创建kettle转换。
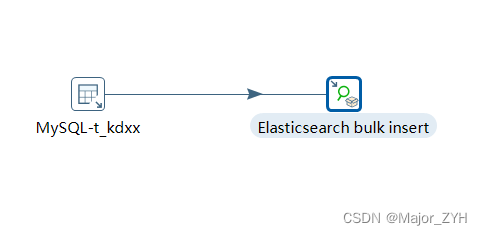
本次以全量同步为目的,只需要kettle中两个组件:表输入、Elasticsearch bulk insert。
如下图:
表输入连接MySQL没有特别需要配置的,不做介绍,主要介绍一下连接es的配置组件:
Elasticsearch bulk insert
(1)打开组件,首先是一般配置:
一般配置分为index和options两部分。
index: 需要填写es索引名称和索引类型type。索引必须提前在es中创建好,如果再等 “ Serves ” 和 “ Settings ”配置完后点击“Test Index”,连接成功通过会弹出提示框 “Index found ({0} shards)”。表示es配置成功。
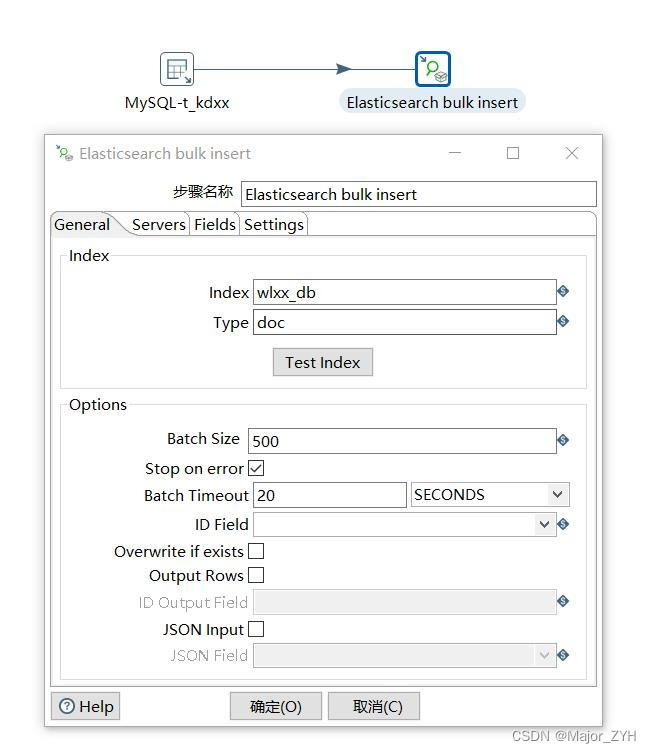
Option:
Batch Size —— 批量提交的大小;
Batch Timeout —— 超时时间;
ID Field —— 作为es中文档记录id的字段。注意:作为id的字段需要特别指定,单独取表主键列作为id更新,而且不能跟正常使用的字段读取数据。
OverWrite if exists —— 复写已存在的记录;
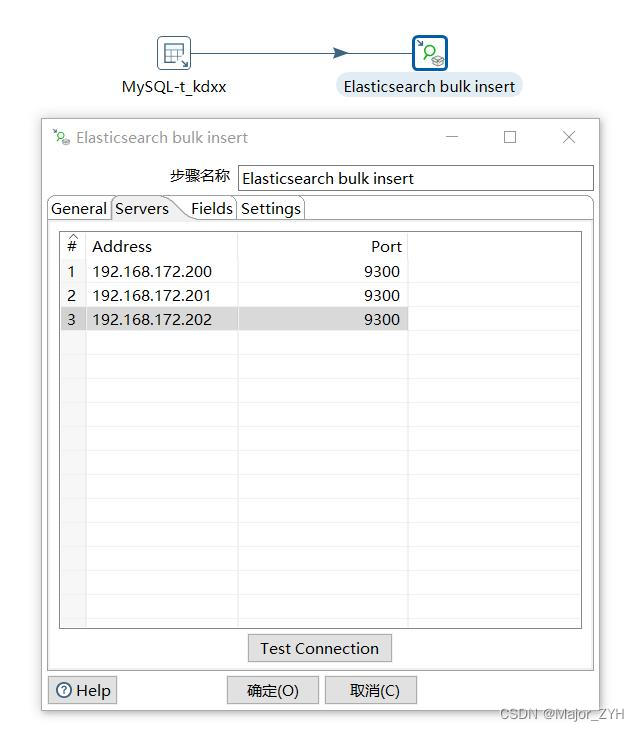
(2)Servers配置
填写es集群的三个节点的地址和端口号。可以用tcp协议端口的9200.
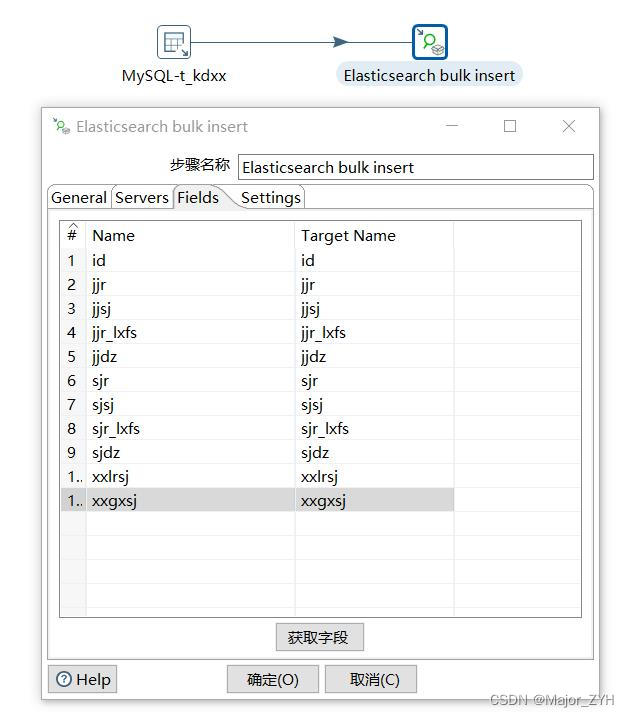
(3)Fileds 配置
如果不需要更改字段,则直接可以获取字段。
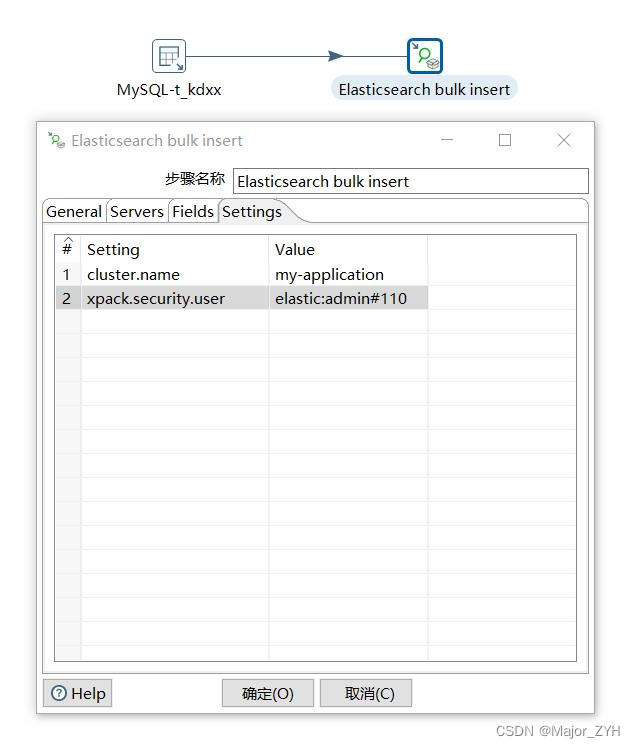
(4)Settings配置
输入es集群的集群名称,如果设置密码了需要配置用户和密码。
集群名称参数 —— cluster_name my-application
用户验证参数(用户和密码用冒号隔开) —— xpack.security.user elastic:admin#110
配置完成即可进行数据同步至es集群环境中。单实例es也可以参照进行配置。