目录
发现在处理数据时会遇到很多各种各样无法明确表达的需求,整理出来以供参考:
1stata 如何留下至少有连续5年的观测?
解决方法:
tsset stkcd year
xtpattern, gen(pp) // 记录每家公司的样本形态
gen p5 = strpos(pp, "11111")
drop if p5 == 0 // 仅保留连续五年有资料的公司
tsset, clear
2stata如何剔除13年及以后公司样本 python
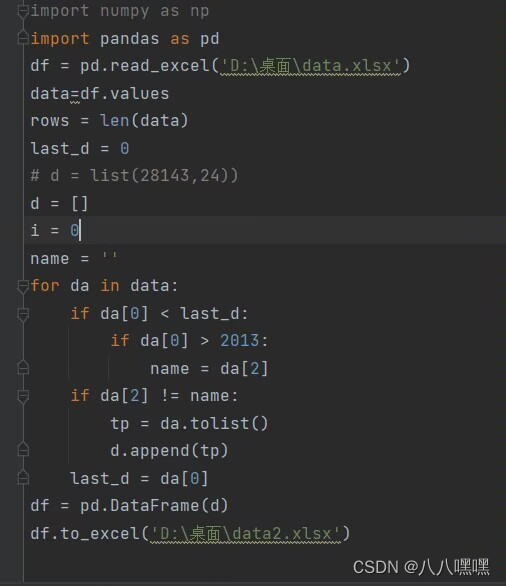
3stata如何根据文本数据生成新数据
参考stata中如何将字符型变量分类生成数值型新分类变量 - Stata专版 - 经管之家(原人大经济论坛)
可以用 strmatch
假如医疗机构的名称的变量是name,新变量叫new
gen new = .
replace new = 1 if strmatch(name, "*医院*")
replace new = 2 if strmatch(name, "*疾控*")
也可以直接使用
gen pol=.
replace pol = 2013 if 所属省份=="重庆市"如果表示属于北京省或安徽省
replace pol = 2014 if 所属省份=="北京市" | 所属省份=="安徽省"
|表示或
如果表示属于广东省但并不属于深圳市
replace pol = 2015 if 所属省份=="广东省" & var23 !="深圳市"4如何将季度数据处理为年度数据
参考文章:Stata如何删除季度数据,保留年末数据?我代码哪里不对 - Stata专版 - 经管之家(原人大经济论坛)
gen d = regexm(会计期间, "12-31")
keep if d == 1提取数据文章:Stata字符串函数:快捷提取字符信息_stata提取字符串中数字_celine0227的博客-CSDN博客
5如何根据分位数划分组别
参考:stata怎么将某一变量按大小分为三组 - Stata专版 - 经管之家(原人大经济论坛)
xtile fin3=fin1,nq(4)
6如何将省份划分为东中西部地区
参考:stata中如何根据省份名字,产生东中西变量 - Stata专版 - 经管之家(原人大经济论坛)
gen area=2 if province=="北京" | province=="福建省" | province=="广东省" | province=="广西壮族自治区" | province=="海南省" | province=="河北省" | province=="江苏省" | province=="辽宁省" | province=="山东省" | province=="上海" | province=="天津" | province=="浙江省"
replace area=1 if province=="安徽省" | province=="河南省" | province=="黑龙江省" | province=="湖北省" | province=="湖南省" | province=="吉林省" | province=="江西省" | province=="内蒙古自治区" | province=="山西省"
replace area=0 if province=="甘肃省" | province=="贵州省" | province=="宁夏回族自治区" | province=="青海省" | province=="陕西省" | province=="四川省" | province=="西藏自治区" | province=="新疆维吾尔自治区" | province=="云南省" | province=="重庆"7出现非唯一标识怎么快速查找
isid year code//检查是否是唯一值
unique year code
duplicates list year code
8将一组数据求均值
bysort x2:egen new=mean (x1)。 这是根据x2分组求x1的均值的命令,得到new变量,然后你把这个变量的值赋给m1